http://cislmu.org 와 학교 수업을 토대로 정리합니다.
1. Recap
- Inverted index
- Intersecting two postings lists
- Constructing the inverted index: Sort postings
- Westlaw: Example queries
- Does Google use the Boolean model?
2장의 핵심
- 기존 IR system의 기본 단위인 word와 document의 이해: document랑 term이 무엇인가
- Tokenization(토큰화): raw text에서 words(tokens)로 변환하기
- 더 복잡한 색인: 포인터와 구문 건너뛰기
2. Documents
Documents
1장에서 Boolean retrieval system을 배울 때, 아래 두 가지를 가정했었다.
- document가 뭔지 안다.
- 각 문서를 machine-read(기계 판독) 할 수 있다.
-> 그러나 현실에서는 복잡할 수 있다.
Parsing a document
각 문서의 format과 language를 처리해야 한다.
1. 어떤 형식인가? -> pdf word excel html ...
2. 어떤 언어인가?
3. 어떤 character set이 사용됐는가?
4. 이 각각은 분류 문제이며 IIR 13에서 다룬다.
5. 대안: 휴리스틱(heuristics) 사용
Format/Language: Complications
보통 하나의 인덱스에는 여러 언어들의 term이 포함되어 있다.
심하면 하나의 문서나 그것의 구성요소가 여러 언어/형식을 포함할 때도 있다.
ex) 스페인어 pdf가 첨부된 프랑스어 이메일
많은 질문이 생긴다.
- 인덱싱을 위한 문서의 단위는 무엇인가?
- 파일인가? 이메일인가?
- 첨부 파일이 5개씩 있는 이메일이면 어떡하는가?
- 파일 그룹이면? -- HTML 문서에 포함된 PPT나 LaTeX 파일
- 결론: "what is document"라는 질문에 대답하기 위해선 design decisions이 필요하다.
- 대안: XML => 인덱스 내에서 다양한 데이터 유형과 형식을 관리 및 구조화하는 데 사용될 수 있다.
🔔XML이란?
데이터를 정의하는 규칙을 제공하는 마크업 언어.
여러 특수한 목적을 갖는 마크업 언어를 만드는데 사용하도록 권장된다.
3. Terms
Definitions
- Word(단어): 구분 기호(아마 공백같은 거)로 구분된 문자열
- Term(용어): 정규화된 word(대소문자, 형태, 철자 등), word의 equivalence class
- Token(토큰): 문서에 나타나는 word나 term의 인스턴스
- Type(유형): 대부분의 경우 term과 동일, token의 equivalence class
부가 설명 (정확하지 않을 수 있음)
"The dog barked at the dogs"
Word: dog, dogs // 텍스트에서 문자 그대로의 형태에 초점 맞춤
Term: dog
Token: 첫 번째 토큰 dog, 두 번째 토큰 dogs // 텍스트 내에서 해당 word나 term이 나타나는 각각의 사례
Type: dog
Normalization
색인된 텍스트의 word와 쿼리 term를 동일한 형태로 정규화해야한다.
window, Window, windows, Windows를 모두 같은 equivalence class에 넣는 것이다.
정규화와 언어 감지(language detection)는 서로 상호작용한다.
- PETER WILL NICHT MIT. → MIT == mit
- He got his PhD from MIT. → MIT != mit
이 예시에서 첫 번째 MIT은 독일어 mit(=with)이기 때문에 mit으로 바꿔 일반적인 전치사로 처리해도 된다.
그러나 두 번째 MIT는 영어고, 특정 기관을 나타내는 고유명사이므로 mit로 변환해서는 안된다.
즉, 독일어인지 영어인지 인지를 해야 정확한 처리가 가능한 것이다.
Tokenization: Recall construction of inverted index
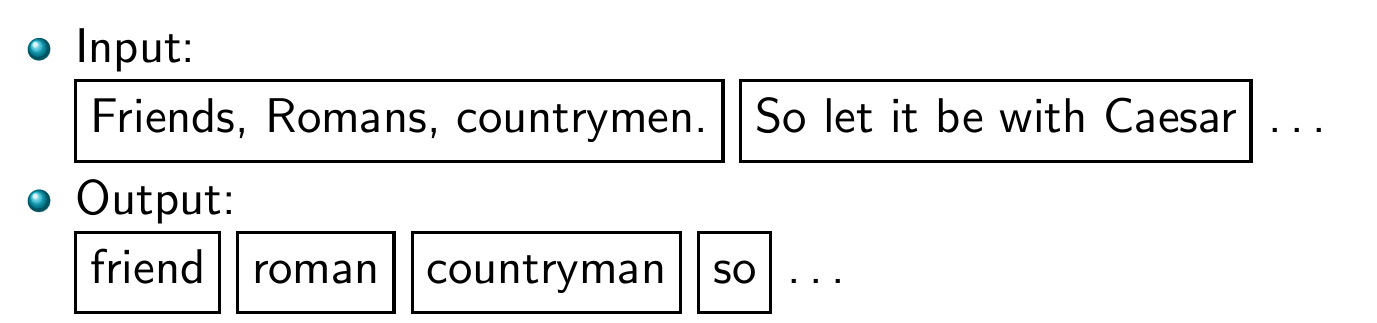
위 사진에서 각 토큰들은 Postings entry 후보이다.
실제로 선택될 토큰들은 정규화된 terms이다.
Exercises
"In June, the dog likes to chase the cat in the barn."
- word tokens는 몇 개인가? -> 13개 (,까지 포함)
- word types는 얼마나 있는가? -> 9개
여기까진 그래도 셀 수 있다.
"Mr. O'Neill thinks that the boys' stories about Chile's capital aren't amusing."
-> 슬슬 어려워진다.
Tokenization problems
참고 링크: https://m.blog.naver.com/bycho211/221799037714
토큰화를 할 땐 여러 문제가 발생한다.
- 한 단어? 두 단어?

이런 단어들은 한 word로 처리해야 하는 건지, 두 개로 처리해야 하는 건지 굉장히 애매하다.

숫자가 섞여있어도 마찬가지이다.
- 비언어권
-
중국어: 공백 문제

중국어는 띄어쓰기가 없다. -
중국어: 구분 문제

두 한자를 하나로 취급하면 수도승이라는 뜻이 되지만, 각각의 의미로 보게 되면 and, still의 뜻을 각각 가지게 된다. 이런 건 어떻게 처리할 것인가? -
공백 문제가 있는 다른 언어들

네덜란드어, 독일어, 스웨덴어 등에도 비슷한 문제가 있다. -
일본어: 여러 문자 혼용 문제

일본어는 텍스트에 히라가나, 가타카나, 한자를 모두 포함하고 있다.
- 공백도 없다.
거기다가 사용자가 자신이 원하는 검색어를 히라가나로만 입력할 수도 있다. 그러면 그걸 또 가타카나나 한자로 변환하는 문제도 고려해봐야 한다.
- 아랍어: 양방향성 문제
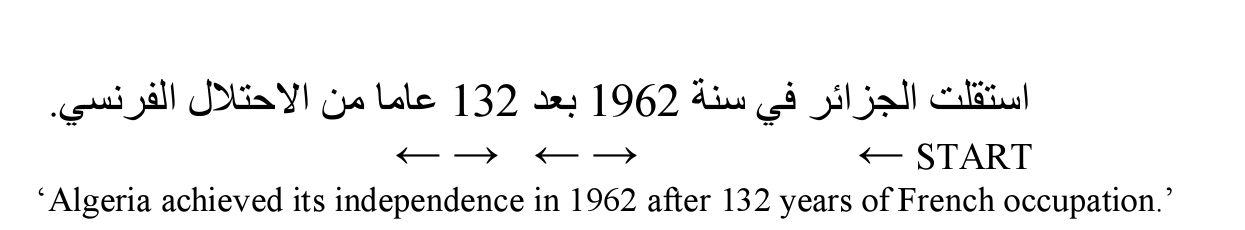
아랍어는 기본적으로는 오른쪽->왼쪽으로 읽으며, 숫자는 왼쪽->오른쪽으로 읽는다.
다만 텍스트가 Unicode로 인코딩되면 문제는 아니라고 한다.
- 악센트, 발음 등
r´esum´e 이런 단어들을 그냥 resume라고 사용자가 입력할 확률이 높다.
Universit¨ 이런 단어도 특수문자를 치기 귀찮아 Universitaet라고 대신 칠 수도 있다.
즉, 사용자가 저런 단어들에 대한 쿼리를 어떻게 작성할 가능성이 높은지에 대해 고려해보아야 한다.
English
여기서부터는 영어 텍스트만 고려한다.
Case folding
영어 텍스트는 모든 문자를 소문자로 변환해야 한다. (유저들이 대부분 대소문자를 구별하지 않고 검색하기 때문이다)
아까 나왔던 예시인 MIT, mit 이런 것도 일단은 소문자로 변환하고 본다.
Stop words
검색 쿼리에서 별로 도움이 되지 않는, 정보 가치가 상대적으로 낮은 common words
예시: a, an, and, are, as, at, be, by, for, from, has, he, in, is, it, its, of, on, that, the, to, was, were, will, with
- 과거의 IR 시스템들에서는 저장 공간과 처리 시간을 절약하기 위해 stop words(불용어)를 제거하는 것이 표준이었다.
- 그러나 phrase(구) 검색 쿼리에서 불용어는 필수적인 요소가 될 수 있다. -- 예: King of Denmark
- 현대 웹 검색 엔진들은 불용어 색인을 하고 있다.
🔔 phrase search query란?
사용자가 검색 엔진에 두 개 이상의 단어를 포함하는 정확한 순서와 조합으로 입력하는 검색 유형
대부분의 현대 검색 엔진들은 구 검색을 지원한다. 예를 들어 구글에서 "King of Denmark"라고 따옴표를 써서 검색하면, 따옴표 안에 있는 정확한 단어 조합을 포함하는 페이지만을 결과로 반환한다.
More equivalence classing
Soundex: phonetic equivalence, 발음에 기반하여 인코딩하는 알고리즘
- 예시: Muller = Mueller
Thesauri: semantic equivalence, 동의어를 기반으로 인코딩하는 알고리즘 - 예시: car = automobile
Lemmatization
inflectional/variant(굴절 / 변형) 형식을 base (기본) 양식으로 줄인다.
- 예시 1: am are is -> be
- 예시 2: car, cars, car's, cars' -> car
"the boy's cars are different colors"
이 문장에 Lemmatization을 적용하면, the boy car be different color 가 된다.
즉, 사전의 표제어 형태로 축약한다.
- Inflectional Morphology: 문법 때문에 바뀐 형태 되돌리기
- ex) cutting -> cut
- Derivational Morphology: 의미나 품사가 바뀌는 것
- ex) destruction -> destroy
Stemming
Stemming(어간화): Lemmatization에서 더 나아가서, 변형된 단어들을 아예 어간으로 되돌리는 것이다.
이 과정은 휴리스틱(경험적 규칙)에 기반하므로 때때로 오류를 일으키거나 단어의 비표준 형태를 생성할 수도 있따.
Stemming도 Lemmatization처럼 Inflectional하고 Derivational할 수 있다.
예시: automate, automatic, automation -> automat
Lemmatization에 비하면 덜 정확할 수 있지만, 빠른 결과를 필요로 할 때 유용하다.
※ Lemmatization은 단어의 형태학적 분석을 기반으로 정확한 기본형(lemma)를 찾는데, 이는 상당한 언어학적 지식과 자원이 필요하다.
★ Porter algorithm
영어를 Stemming할 때 가장 보편적으로 사용되는 알고리즘이다.
성능은 다른 stemming 옵션들과 비교하여 평균 이상이라고 한다.
규칙이 있는데, 5단계의 축소 과정을 순차적으로 거쳐 단어의 어간을 찾는다.
여기서 각 단계는 접미사를 제거하는 일련의 명령어로 구성된다고 한다.
ex) ement이라는 접미사가 단어의 끝에 있을 경우, 그리고 그 접미사를 제거한 후 남는 철자가 2개 이상이라면 ement를 삭제할 수 있다.
- replacement -> replac가 되므로 가능
- cement -> c가 되므로 불가능
규칙 적용 시의 convention(관례): 복합 명령에서 규칙을 적용할 때, 가장 긴 접미사에 적용되는 규칙을 선택한다.
Porter stemmer: A few rules

명령어 집합을 보고 단어에 porter algorithm을 적용하는 예시이다.
Three stemmers: A comparison
물론 stemmer에는 Porter algorithm말고도 다른 것들이 있다.
아래는 그것들의 결과를 비교한 것이다.

세 스테머의 비교 (by chatGPT)
1. 포터 스테머(Porter stemmer): 이 알고리즘은 어간 추출에 있어서 가장 널리 사용되고 있으며, 어느 정도 보수적인 방법으로 접미사를 잘라냅니다. 결과는 원본 단어의 형태를 상당히 유지하면서도, 일반적인 접미사를 제거한 어간을 보여줍니다.
2. 로빈스 스테머(Lovins stemmer): 이 알고리즘은 포터 스테머보다 더 공격적으로 접미사를 잘라내며, 결과적으로 더 짧은 어간을 생성합니다. 때로는 원본 단어를 인식하기 어려운 형태로 바뀌기도 합니다.
3. 페이스 스테머(Paice stemmer): 이 알고리즘 역시 강력한 접미사 제거 규칙을 적용하고, 원본 단어에서 상당 부분을 줄여냅니다. 이는 텍스트에서 매우 간결한 어간을 생성하지만, 때때로 원본 단어의 인식 가능성을 감소시킬 수 있습니다.
Does stemming improve effectiveness?
stemming은 어떤 쿼리에서는 효율성을 증가시키고, 어떨 때는 오히려 떨어뜨리기도 한다.
-
예를 들어, [tartan sweaters], [sightseeing tour san francisco] 같은 텍스트에서는 도움이 된다.
-> equivalence classes: {sweater, sweaters}, {tour, tours} -
이런 경우에는 도움이 안 된다. [operational AND research], [operating AND system], [operative AND dentistry]
-> equivalence classes: {oper, operate, operating, operates, operation, operative, operatives, operational}
=> 이런 경우 단어 형태가 중요한 의미를 가지는데 stemming 때문에 정확도가 떨어질 수 있기 때문
Exercise: What does Google do?
그럼 구글은 저렇게 배운 것 중 어떤 것들을 적용해서 검색 엔진을 구성했을까?
아래와 같은 것들을 사용한다고 한다.
- Stop words
- Normalization
- Tokenization
- Lowercasing
- Stemming
- Non-latin alphabets
- Umlauts: 독일어처럼 일부 언어에서 사용되는 발음 구별 기호가 있는 모음 처리
- Compounds: 복합 명사 하나로 처리
- Numbers: two thousand twenty-four 같은 거 2024로 처리
4. Skip pointers
Recall basic intersection algorithm
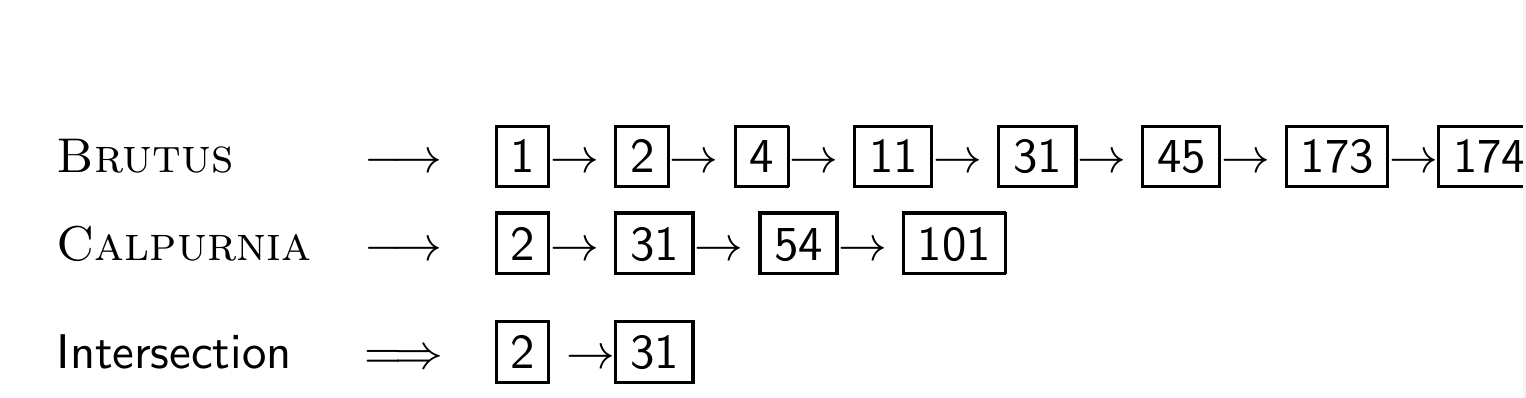
1장에서 intersection 알고리즘에 대해 배운 바 있다.
이 알고리즘은 postings lists의 길이에 따라 선형적인 시간복잡도를 가진다.
-> 여기서 더 좋게 하려면 어떻게 해야 할까?
Skip pointers
Skip pointer를 사용해서 검색 결과에 나타나지 않는 posting은 건너뛸 수 있다.
이렇게 하면 intersecting posting lists를 더 효율적으로 만들 수 있다.
posting lists가 수백 만개의 entry들을 포함할 수 있는데, 이 때는 아무리 시간복잡도가 선형이라고 해도 효율성에 문제가 생길 수 있다.
그러면 질문이 생긴다.
-> skip pointer를 어디에 배치하는가?
-> 검색 결과가 정확한지 어떻게 확인하는가?
Basic idea
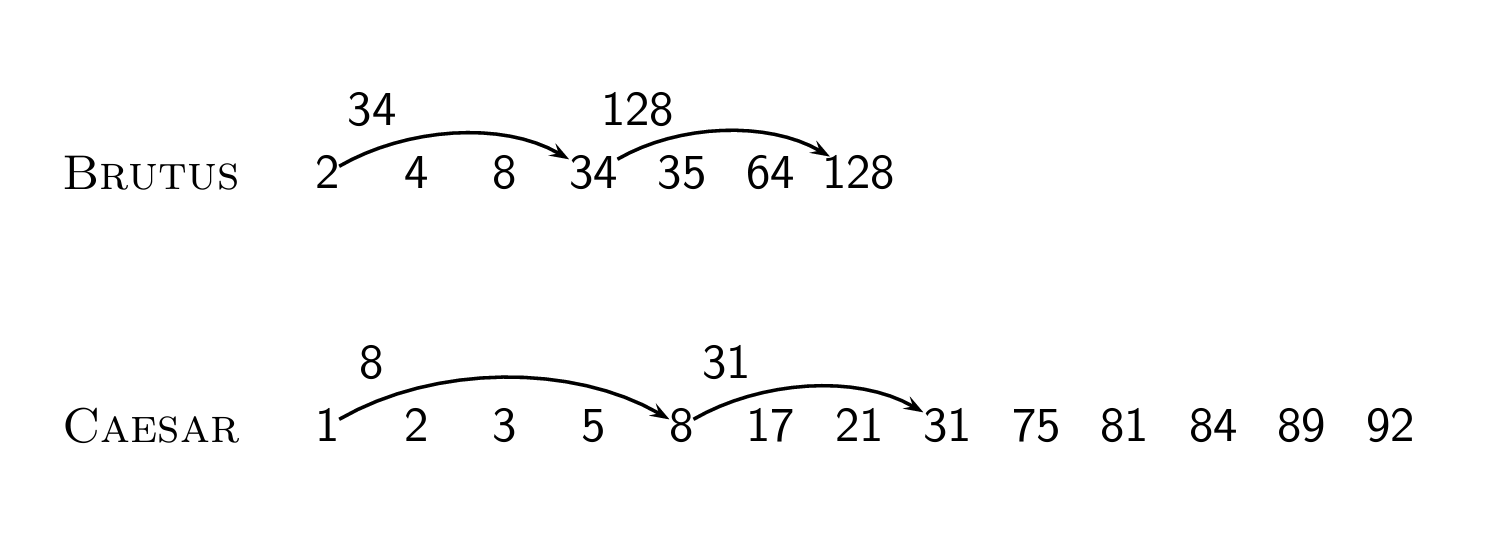
이런 식으로 문서들의 특정 ID에 skip pointer가 있고, 그 특정 ID에 도달했을 때 어떠한 조건(아래 알고리즘 참고)을 달성하면 스킵 포인터를 사용할 수 있다.
Skip lists: Larger example
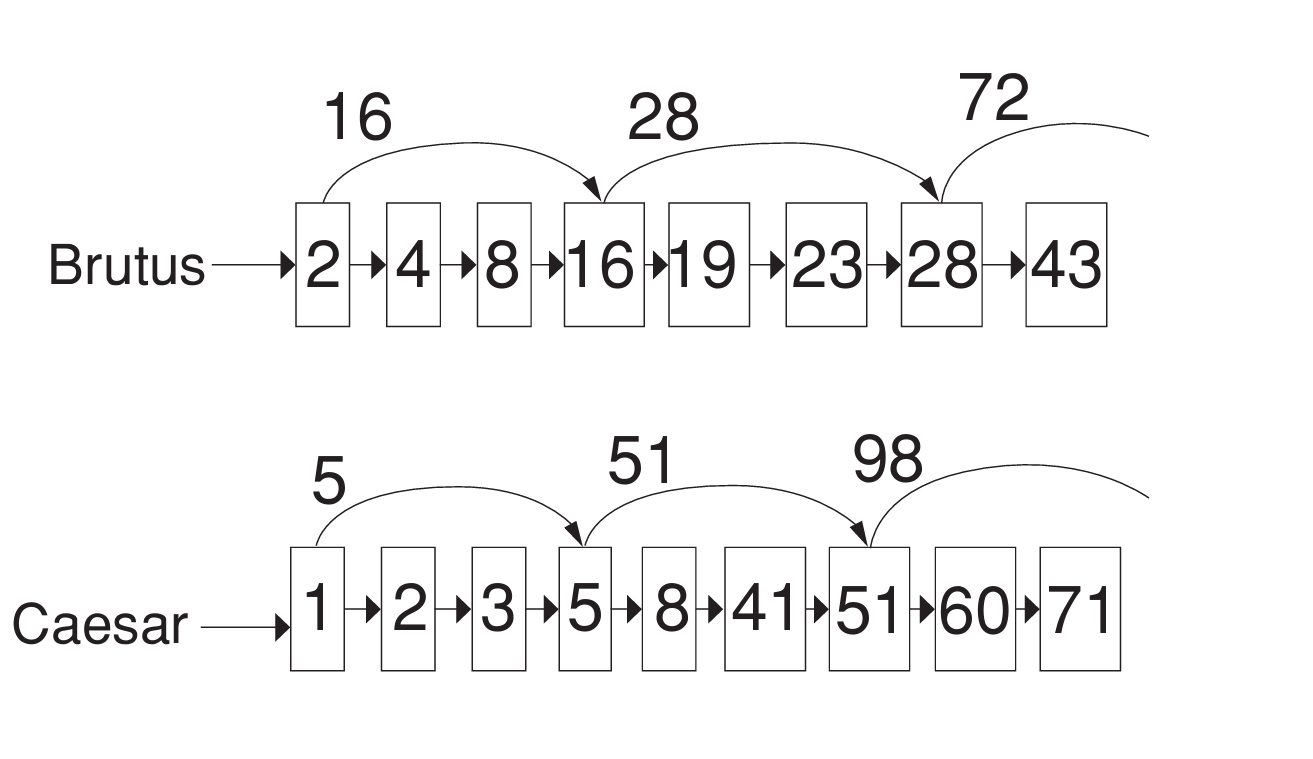
스킵 포인터의 또다른 예제이다.
Intersecting with skip pointers

skip pointer를 추가한 intersect 알고리즘이다.
추가 설명
p1과 p2의 ID가 같다면 answer에 그 아이디를 추가한다. (이전 알고리즘과 동일)
else if docID(p1) < docID(p2): p1의 문서 ID가 p2의 문서 ID보다 작은 경우,
then if hasSkip(p1) and (docID(skip(p1)) ≤ docID(p2)): p1에 skip pointer가 있고, skip(p1)으로 이동했을 때 도달하는 문서 ID가 p2의 문서 ID 이하인 경우,
while hasSkip(p1) and (docID(skip(p1)) ≤ docID(p2)) do: 위 조건이 참인 동안,
p1 ← skip(p1): p1을 skip pointer로 이동시킵니다.
else p1 ← next(p1): 그렇지 않다면 p1을 다음 문서 ID로 이동시킵니다.
else if hasSkip(p2) and (docID(skip(p2)) ≤ docID(p1)): p2에 대해서도 비슷한 조건으로 검사합니다.
while hasSkip(p2) and (docID(skip(p2)) ≤ docID(p1)) do: 위 조건이 참인 동안,
p2 ← skip(p2): p2를 skip pointer로 이동시킵니다.
else p2 ← next(p2): 그렇지 않다면 p2를 다음 문서 ID로 이동시킵니다.
return answer: 교집합을 담고 있는 결과 리스트를 반환합니다.
Where do we place skips?
원리는 알겠는데, 그럼 스킵할 위치를 어떻게 선정해야 할까?
건너뛰는 항목 수 vs 건너뛰는 빈도 간의 Trade off가 있다.
- more skips: 한 번에 건너뛰는 수가 적지만 대신 skip pointer를 자주 사용할 수 있다.
- fewer skips: 한 번에 건너뛰는 수가 많지만 자주 사용하지는 못 한다.
휴리스틱에 의해, 보통 길이가 P인 글 목록의 경우 √P 간격으로 skip pointer를 사용한다.
- 쿼리 용어의 분포는 무시한다.
- index가 정적일 때 사용하기 쉽다.
- 업데이트가 잦은 동적 환경에서는 사용하기 어렵다.
- Skip pointer는 에전에는 많은 도움이 되었으나 오늘날은 CPU가 빠르기 때문에 별 의미가 없다.
5. Phrase queries
Phrase queries
만약 standford university => 라는 구문 자체를 검색해서 답변을 얻고 싶다면 어떻게 해야 할까?
예를 들어, "The inventor Stanford Ovshinsky never went to university"라는 문장은 stanford와 university를 둘 다 포함하고 있지만 구문 그 자체는 아니므로 검색 결과로 뜨면 안 된다.
유저들이 받아들이기에도 쉬운 개념이고, 실제로 웹 쿼리의 상당 부분이 구문 쿼리이다.
그러므로, 이제 inverted index처럼 문서의 ID를 postings lists에 저장하는 것만으로는 충분하지 않고, 확장해야 한다.
확장하는 것엔 두 가지 방법이 있다.
- biword index
- positional index
Biword indexes
그냥 단순하게 연속되는 모든 term 쌍을 구문으로 index하는 것이다.
ex) Friends, Romans, Countrymen: 두 개의 biwords
- friends romans
- romans countrymen
각각의 biwords는 vocabulary term에 들어있다.
즉, 두 단어로 된 구문은 이제 쉽게 답을 구할 수 있게 되었다.
Longer phrase queries
두 단어 이상의 구문을 찾으려면 어떻게 해야 할까?
예를 들어, stanford university palo alto는 아래와 같은 Boolean query로 표현될 수 있다.
=> "STANFORD UNIVERSITY" AND "UNIVERSITY PALO" AND "PALO ALTO"
검색 결과에서 이 4단어로 된 구문을 실제로 포함하고 있는 부분집합을 식별하기 위해, 검색 결과에 대한 post-filtering(후처리)가 필요하다.
그러니까 즉, 각 단어 조합이 포함된 문서들을 먼저 찾고, 그 중에서 해당 구를 정확하게 포함하는 문서를 저 불리언 쿼리를 이용해서 식별해야 한다는 뜻이다.
Issues with biword indexes
저런 단순무식한 방법은 당연하게도 문제가 생긴다.
우선 실제로 그 구문을 포함하고 있지 않은 데도 결과가 나와 따로 후처리를 해줘야 하고,
매우 큰 term vocabulary 때문에 색인도 폭증한다.
Positional indexes
Positional indexes로 biword indexes의 문제점을 해결할 수 있다.
기존의 posting들은 그냥 문서 ID에 불과했다. 즉, Postings lists는 nonpositional하게 index됐다.
그러나 Positional indexes를 사용하면 각각의 posting들은 문서 ID에 더해, position의 목록도 포함하게 된다.
Positional indexes: Example

위 사진만 보면 혼란이 오니까 아래 설명을 보자.
(강의 참고: https://www.youtube.com/watch?v=QVVvx_Csd2I)
Positional index를 할 때, 아래같은 형태로 적는다.

즉 term이 TO인 경우, 문서 컬렉션에서 TO가 나타나는 빈도는 총 993427번이고, doc1같은 경우 <7, 18, 33, 72, 86, 231> 자리에 to가 들어가며 이며 doc2같은 경우 <1, 17...
이런 식으로 해석할 수 있는 것이다.

저 예시에서는 문서를 하나씩 넘겨보다가 4번 문서가 매치됨을 확인할 수 있다.
이유: 429번 자리에 to, 430번 자리에 be, 433번 자리에 다시 to, 434 자리에 다시 be가 나타남으로써 쿼리를 충족하기 때문이다.
Proximity search
구문 검색에 위처럼 positional index를 사용할 수 있다는 걸 알았다.
이 방법을 활용해서 proximity search(근접 검색) 도 가능할까? -> 가능하다.
ex) employment /4 place
-> employment와 place가 4단어 이내에 포함된 모든 문서를 찾는다는 뜻이다.
- Employment agencies that place healthcare workers are seeing growth: (o)
- Employment agencies that have learned to adapt now place healthcare workers: (x)
여기서도 똑같이 positional index를 사용한다.
가장 간단한 알고리즘은, EMPLOYMENT와 PLACE의 문서 내 position의 교차 결과물을 보는 것이다.
이는 stop word 등의 빈도가 높은 단어에서는 정말 비효율적일 수 있다.
그리고 단순 문서의 목록이 아니라, 실제로 일치하는 위치를 반환해야 한다.
"Proximity" intersection

positionalintersect 알고리즘은 위와 같다.
추가 설명
then l ← []: p1과 k 이내의 거리에 있는 p2의 position을 임시로 저장하는 곳
6-14 코드: 위치를 비교하고 l에 저장
while l ≠ [] and |l[0]−pos(pp1)| > k: l에서 더 이상 현재 p1의 위치 pos(pp1)와 거리 k 이내에 있지 않은 위치를 제거합니다.
16-22. (코드 생략): 반복 루프 종료 및 유효한 위치 조합을 answer 리스트에 추가하는 것을 가정합니다.
for each ps ∈ l do Add(answer, docID(p1), pos(pp1), ps) : l에 있는 각 위치 ps가 유효하면, 튜플 (docID(p1), pos(pp1), ps)을 answer에 추가합니다.
pp1 ← next(pp1): p1의 포스팅 리스트에서 다음 위치로 이동합니다.
p1 ← next(p1): p1의 포스팅 리스트에서 다음 문서로 이동합니다.
p2 ← next(p2): p2의 포스팅 리스트에서 다음 문서로 이동합니다.
else if docID(p1) < docID(p2): p1의 문서 ID가 p2의 문서 ID보다 작으면, p1을 다음 문서로 이동합니다.
else p2 ← next(p2): 그렇지 않으면 p2를 다음 문서로 이동합니다.
return answer: 기준을 충족하는 모든 위치 쌍을 포함하는 answer 리스트를 반환합니다.
Combination scheme
사실 biword index에 문제가 있다고는 했지만, positional index와 적절히 섞어서 사용할 수 있다.
예를 들어 Michael Jackson, Britney Spears같은 바이워드는 positional postings intersection과 비교해 속도가 매우 빠르다.
그럼 어떤 식으로 두 방법을 조합하는 걸까?
-> 빈번한 biword만 index에 vocabulary term으로서 포함시킨다.
다른 모든 구문은 positional intersection으로 수행한다.
이러한 조합 방법은 단순히 위치 인덱스를 쓰는 것보다 훨씬 빠르지만, 인덱스를 위한 공간이 26% 정도 더 필요하다고 한다.
"Positional" queries on Google
웹 검색 엔진의 경우, positional query는 일반 부울 쿼리보다 훨씬 더 expensive하다.
왜 부울 쿼리보다 비용이 비싼지, 그리고 그 이유를 Google에서 입증할 수 있는지에 대해 생각해보아야 한다.
Take-away
오늘의 핵심은 words와 documents를 잘 이해하는 것이다.
Tokenization, skip pointers, phrases에 대해서도 잘 이해해야 한다.
※ 추가로 공부할 점
- Skip opinter 추가한 Intersect 알고리즘 공부
- 위 알고리즘과 기존 알고리즘 비교
- RULES 보고 stemming 해보기 실습
- word, term, token, type 확실히 비교
- 스킵 포인터 예제 2개 과정 직접 그려가며 공부
- Tokenization 직접 해보기
- positional index 이해
- proximity intersection 알고리즘 공부
- byte-pair에 대해 공부
