1. Scikit-learn 이란?
파이썬에서 가장 많이 사용되는 머신러닝 라이브러리이다.
다양한 분류, 회귀, 군집 알고리즘을 제공하며, 문서화가 매우 잘 되어 있어 입문자가 학습하기 좋음
설치
pip install scikit-learn2. 머신러닝 학습 방법 분류 (with Scikit-learn)
사이킷런은 데이터의 형태(정답 유무)와 목적에 따라 다양한 알고리즘을 지원한다.
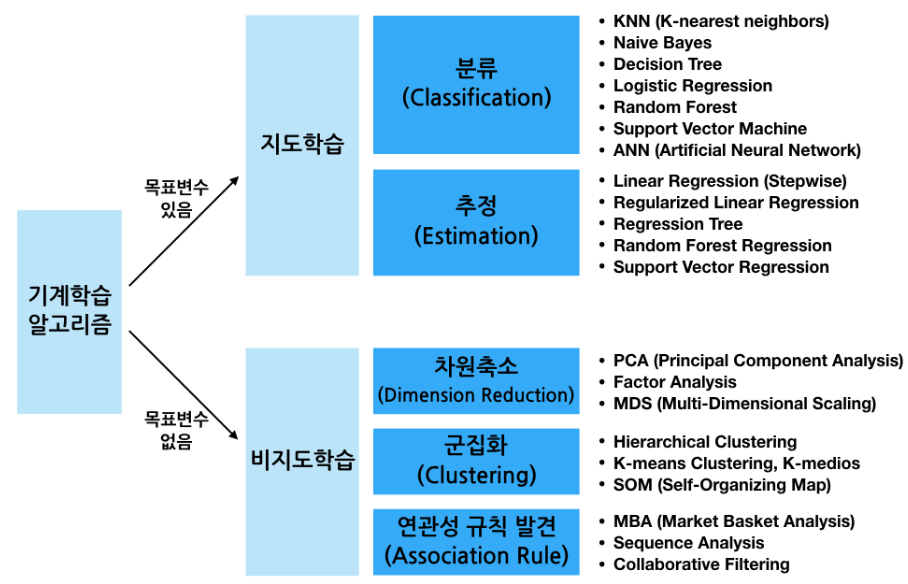
지도 학습 (Supervised Learning)
- 목표 변수(정답)이 있는 경우
1) 분류(Classification)
- 데이터가 어떤 범주(Class)에 속하는지 예측
- Ex) 공부 시간, 출석 일수에 따른 합격/불합격 여부, 학점(A/B) 예측
- 주요 알고리즘: KNN, Naive Bayes(통계적 확률 기반), 로지스틱 회귀, 의사결정나무(Decision Tree), Random Forest, SVM
2) 회귀(Regression/Estimation)
- 데이터의 특징을 바탕으로 연속된 수치(값)를 추정
- Ex) 공부 시간, 출석 일수에 따른 '시험 점수' 예측
- 주요 알고리즘: 선형 회귀(Linear Regression), 릿지(Ridge), 라쏘(Lasso)
비지도학습(Unsupervised Learning)
- 목표 변수(정답)이 없는 경우
- 차원 축소: 데이터의 복잡성을 줄임 (PCA)
- 군집화: 데이터를 비슷한 그룹으로 묶음 (K-means)
- 연관 규칙: 데이터 간의 연관성 발견 (장바구니 분석)
- Tip: 텍스트나 이미지 같은 비정형 데이터는 최근 LLM(거대언어모델)이나 딥러닝을 주로 활용하는 추세.
3. Scikit-learn 주요 모듈 정리
| 모듈 | 설명 |
|---|---|
datasets | 연습용 내장 예제 데이터 세트 (Iris, Boston 등) |
preprocessing | 데이터 전처리 (정규화, 스케일링, 인코딩 등) |
feature_selection | 의미 있는 특징(Feature)만 선택하는 기능 |
feature_extraction | Feature 추출 |
decomposition | 차원 축소 (PCA 등) |
model_selection | 학습/테스트 데이터 분리(train_test_split), 교차 검증, 그리드 서치 등 |
metrics | 모델 성능 평가 (Accuracy, RMSE, ROC-AUC 등) |
pipeline | 전처리 + 모델링 묶어서 실행 |
linear_model | 선형 회귀, 로지스틱 회귀, SGD 등 알고리즘 |
svm | SVM |
neighbors | KNN |
naive_bayes | NB 모델 |
tree | 의사결정나무 알고리즘 |
ensemble | 앙상블 알고리즘 (Random Forest 등) |
cluster | 비지도 군집 알고리즘 (K-Means 등) |
4. 선형회귀 (Linear Regression)
예제 : 자동차의 속도(speed)에 따른 제동 거리(dist)를 예측하는 모델을 만들어보자
1) 데이터 준비
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
# 한글 폰터 설정(Windows 기준)
matplotlib.rcParams['font.family']='Malgun Gothic'
matplotlib.rcParams['axes.unicode_minus'] = False
# 선형 회귀 모델 임포트
# SGDRegressor는 경사하강법을 사용하는 모델, 이번엔 일반 LinearRegression 사용
from sklearn.linear_model import LinearRegression, SGDRegressor
# 데이터 로드
carDF = pd.read_csv('cars.csv', index_col='Unnamed: 0')
carDF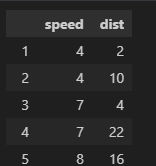
2) 데이터 전처리 (중요: 2차원 배열 변환)
Scikit-learn의 모델들은 입력 데이터()로 2차원 배열(행렬)을 기대
따라서 Series나 1차원 리스트를 DataFrame 형태([[ ]]) 혹은.reshape(-1, 1)을 통해 변환해주어야 한다.
fit(x, y)는 반드시 행렬(2D) 형태 필요
# 특성 데이터(X)와 라벨(y) 분리
# .values를 사용하여 numpy array로 변환하고,
# 대괄호를 두 번[[ ]] 써서 2차원 구조 유지
x = carDF[['speed']].values # (n_samples, n_features) 형태
y = carDF[['dist']].values # (n_samples, n_targets) 형태
print(x.shape) # 결과 예: (50, 1) -> 2차원 확인 필수!3) 모델 학습 (Fit)
fit(x, y)메서드는 데이터를 통해 모델(직선의 방정식)의 기울기()와 절편()을 학습
model = LinearRegression()
model.fit(x, y) # 학습 시작
4) 학습 결과 확인 (기울기와 절편)
학습된 모델이 찾은 최적의 직선 식:
print('기울기:', model.coef_)
print('절편:', model.intercept_)
# 결과
기울기 [[3.93240876]]
절편 [-17.57909489] 즉, 이 모델은 dist = 3.93 * speed - 17.57 이라는 공식을 도출했다.
5) 예측 (Predict)
새로운 데이터에 대해 결과를 예측해보기.
학습 때와 마찬가지로 입력값은 2차원 배열이어야 한다.
# Case 1: 수식으로 직접 계산 (비권장)
# 결과는 나오지만, 모델 객체를 활용하는 것이 좋음
val = 10 * float(model.coef_) + float(model.intercept_)
print(val) # 21.74...
# Case 2: predict 메서드 사용 (권장) 👍
# 2차원 배열로 입력해야 함에 주의! [[10]]
print(model.predict([[10]]))
# array([[21.7449927]])
# 여러 개의 값 동시 예측
print(model.predict([[10], [15]]))
# array([[21.7449927],
# [41.4070365]])6) 시각화
# 1. 실제 데이터 (산점도)
plt.scatter(x, y, label='실제값')
# 2. 예측 데이터 (선 그래프)
# 예측선 그리기 위해 x의 최소~최대 범위 생성
pred = model.predict(x)
plt.plot(x, pred, 'r--', label='예측선')
plt.show()[이미지 삽입]
5. 왜 데이터를 '행렬'로 주어야 할까?
- 사이킷런이 입력 데이터를 행렬(Matrix) 형태로 요구하는 근본적인 이유는 연산 효율성 때문이다.
행렬 곱(Matrix Multiplication)의 원리
-
컴퓨터는 루프(Loop)를 돌며 하나씩 계산하는 것보다, 행렬 연산을 통해 한 번에 계산하는 것이 훨씬 빠르기 때문에 선형 회귀의 예측 공식은 이다.
-
데이터가 많아지면 이를 행렬식 로 표현하여 처리한다. 이때 행렬 곱이 성립하려면 앞 행렬의 열 개수와 뒤 행렬의 행 개수가 같아야 한다(주의!)
Numpy 실습
import numpy as np
# A 행렬 (2 x 2)
a = np.array([[1, 2], [3, 4]])
# B 행렬 (2 x 3)
b = np.array([[1, 2, 3], [3, 4, 5]])
# 행렬 곱 연산
# 방법 1: np.matmul
print(np.matmul(a, b))
# 방법 2: @ 연산자 (파이썬 추천)
print(a @ b)
# 결과 (2 x 3 행렬이 나옴)
# array([[ 7, 10, 13],
# [15, 22, 29]])- 결론:
우리가 model.predict(X)를 호출할 때, 내부적으로는 위와 같은 행렬 곱 연산이 일어나며 수만 개의 데이터도 순식간에 예측값을 내놓을 수 있게된다.
요약
- Scikit-learn은 파이썬 머신러닝의 표준 라이브러리
- 지도 학습의 회귀 문제를 풀기 위해
LinearRegression을 사용 fit→ weight/coef 학습(coef= 기울기,intercept= y절편)- 모델 학습(
fit)과 예측(predict) 시 데이터는 반드시 2차원 행렬(Array) 형태여야 한다. - 그 이유는 내부적으로 행렬 곱(@) 연산을 수행하여 효율을 높이기 때문