범주형 데이터 전처리: 라벨 인코딩 vs 원-핫 인코딩
머신러닝 모델은 '글자'를 이해하지 못하기 때문에 문자로 된 범주형 데이터를 반드시 숫자로 변환해줘야 한다(Ex. "사과", "바나나" Error!)
이 작업을 인코딩(Encoding)라고 하는데 대표적인 두 가지 방식을 알아보자. 🔠 🔢
1. 두 가지 인코딩 방식 비교
- 데이터에 '서열(순서)'이 있느냐 없느냐가 선택의 기준
1) 라벨 인코딩 (Label/Ordinal Encoding)
- 범주형 값을 고유한 정수(Integer)로 1:1 매핑
- 방식: A 0, B 1, C 2특징:순서(Order)가 부여됨: 0 < 1 < 2 라는 수학적 크기가 생긴다.
- 권장 대상: 실제 서열이 존재하는 데이터 (학점 A/B/C, 등급 1급/2급/3급)
- 추천 모델: 트리 기반 모델 (Decision Tree, Random Forest, XGBoost 등)
주의: 순서가 없는 데이터(사과, 배)에 적용하면 모델이 "배(1)가 사과(0)보다 크다"고 잘못 학습할 수 있다.
2) 원-핫 인코딩 (One-Hot Encoding)
- 각 범주를 독립적인 이진(Binary) 특성(컬럼)으로 변환
- 방식: 남
[1, 0]
여[0, 1] - 특징:
1) 순서 관계 제거: 모든 범주가 평등해집니다.
2) 차원의 저주: 범주 종류가 1,000개면 컬럼이 1,000개 생깁니다. (메모리 부족 주의)
3) 권장 대상: 명목형 데이터 (성별, 지역, 색상 등 순서 없는 데이터)
4) 추천 모델: 거리를 계산하는 모델 (Linear/Logistic Regression, KNN, Neural Network)
2. 실습 데이터 준비 (혼합형 데이터)
- 실제 데이터에는 숫자형 컬럼과 범주형 컬럼이 섞여 있는 경우가 많습니다.
ColumnTransformer를 사용하면 이를 한 번에 처리할 수 있다.
import pandas as pd
import numpy as np
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder, OrdinalEncoder
# 데이터 생성
data = {
'수치형_특징': [10, 20, 30, 40, 50], # 변환 X (그대로 둘 예정)
'범주형_특징': ['A', 'B', 'A', 'C', 'B'], # 변환 O (인코딩 필요)
'그대로_유지': [1, 0, 1, 0, 1] # 변환 X
}
df = pd.DataFrame(data)
print(df)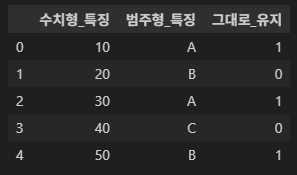
3. 실습 1: Ordinal Encoding (순서가 있을 때)
- Scikit-learn의
OrdinalEncoder를 사용하여 범주형_특징 컬럼만 숫자로 바꿈
# ColumnTransformer 정의
preprocessor = ColumnTransformer(
transformers=[
# (이름, 변환기 객체, [적용할 컬럼명 리스트])
('cat', OrdinalEncoder(), ['범주형_특징'])
],
remainder='passthrough' # 중요! 지정하지 않은 나머지 컬럼은 버리지 말고 통과시켜라
)
print(preprocessor)
# 변환 수행
X_transformed = preprocessor.fit_transform(df)
print(X_transformed)
# 결과 해석
# [[ 0. 10. 1.] -> A는 0으로 변환
# [ 1. 20. 0.] -> B는 1로 변환
# [ 0. 30. 1.] -> A는 0
# [ 2. 40. 0.] -> C는 2로 변환
# [ 1. 50. 1.]]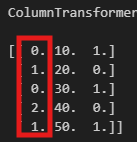
4. 실습 2: One-Hot Encoding (순서가 없을 때)
- 가장 보편적으로 사용되는 방식.
범주형_특징컬럼이 A, B, C 3가지 값을 가지므로 3개의 새로운 컬럼으로 쪼개진다.
from sklearn.preprocessing import OneHotEncoder
# OneHotEncoder로 변경
preprocessor = ColumnTransformer(
transformers=[
('cat', OneHotEncoder(), ['범주형_특징'])
],
remainder='passthrough'
)
X_transformed = preprocessor.fit_transform(df)
print(X_transformed)
# 결과 해석
# [[ 1. 0. 0. 10. 1.] -> A: [1, 0, 0]
# [ 0. 1. 0. 20. 0.] -> B: [0, 1, 0]
# [ 1. 0. 0. 30. 1.] -> A: [1, 0, 0]
# [ 0. 0. 1. 40. 0.] -> C: [0, 0, 1]
# [ 0. 1. 0. 50. 1.]]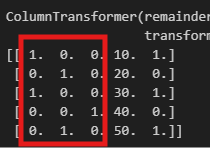
결과 분석
앞의 3개 컬럼(1. 0. 0.)은 OneHotEncoder가 만든 A, B, C 여부를 나타내는 컬럼이다.
뒤의 2개 컬럼(10. 1.)은 passthrough로 통과된 원래의 수치형 데이터이다.
차원 증가: 원래 3개였던 컬럼이 총 5개(원핫 3개 + 수치 2개)로 늘어남.
요약
| 특징 | Label (Ordinal) Encoding | One-Hot Encoding |
|---|---|---|
| 변환 방식 | A → 1, B → 2 (정수 변환) | A → [1,0], B → [0,1] (벡터 변환) |
| 장점 | 차원이 증가하지 않음 | 순서 왜곡 없음 |
| 단점 | 숫자의 크기(순서)가 모델에 영향을 미침 | 컬럼 수 증가(메모리 부담) |
| 사용처 | 서열 데이터(등급, 학점), 트리 모델(Random Forest, XGBoost) | 명목 데이터(성별, 지역), 선형 모델(Regression, SVM) |
소금에 절인 생선, 몸을 뒤척이다 🐟