[Capstone] LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation 실행
캡스톤디자인과창업프로젝트A | 2024-fall
LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
Colab으로 LGM 실행하기 Colab 링크
서론
우리팀은 연구 주제로 Single view 3D reconstruction을 잡았다. 현재 어떤 연구들이 있는지 찾아보고 직접 돌려보며 개선점을 파악했다.
먼저 DreamGaussian과 One-2-3-45를 돌려봤다. DreamGaussian은 3DGS 기반이고, One-2-3-45은 NeRF 기반이다. 결과적으로 3DGS 기반이 성능도 더 좋았고, 시간과 리소스 측면에서도 효율적임을 발견했다. 이후 3DGS 기반 모델을 찾아보다가, LGM이라는 논문을 발견했다.
LGM을 돌렸을 때, DreamGaussian에서는 이상했던 형태가 엄청나게 개선되어서 놀랐다. 그리고 texture와 geometry 측면에서 개선할 점을 발견했다. 자세한 설명은 실행 파트에서 설명하겠다.
논문 리뷰
간단하게만 LGM 논문을 정리하겠다.
Pipeline
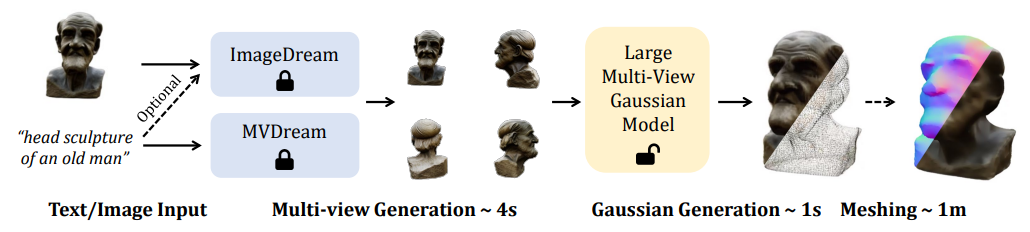
Image Input의 경우)
1. Single image 를 입력받아서, ImageDream을 통해 multi-view(4가지 카메라 위치) images를 생성한다.
2. Large Multi-View Gaussian Model을 통해 3D Gaussian을 생성한다
3. Mesh Extraction
Architecture
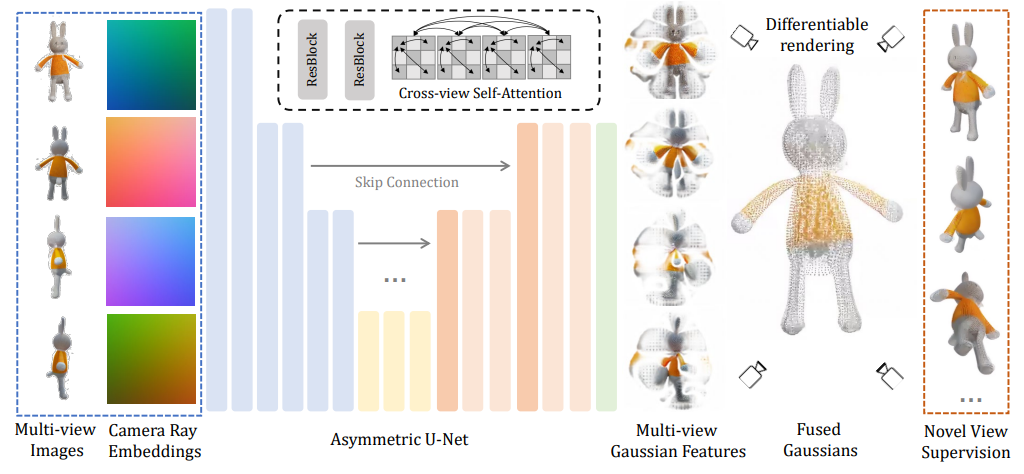
Assymetric U-Net
- Input
생성된 multi-view image들과 카메라 위치(Camera Ray Embeddings) - Output
4개의 feature map(Multi-view Gaussian Features)
Fusing
Assymetric U-Net의 output인 각 feature map은 Gaussian의 집합으로 transform된다.이 Gaussian들이 합쳐져 최종 3D Gaussian이 생성된다.
Mesh Extraction Pipeline
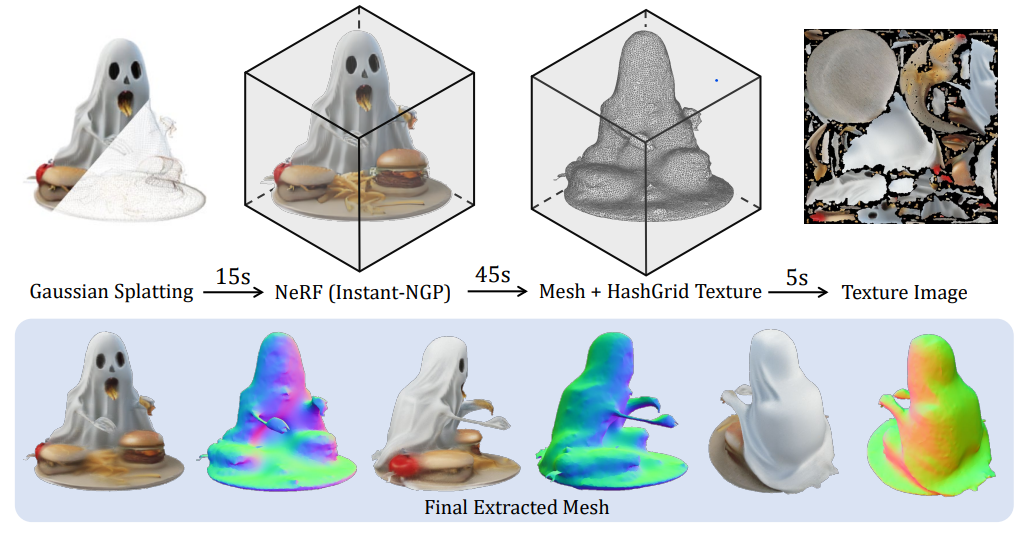
3D Gaussian -> Instant-NGP -> NeRF -> NeRF2Mesh -> Mesh
실행
github.com/3DTopia/LGM
github.com/camenduru/LGM-jupyter
위 깃허브 코드들을 참고해서 코랩을 만들어서 돌려봤다. -> Colab 링크
* 구글 드라이브 마운트 후 LGM/data_test에 입력 이미지 업로드(배경 제거 후 .png 형식)
* Xformer 페이지에 들어가서 버전 확인 후 torch와 cuda 버전 확인
Trouble Shooting
-
Xformer 설치
!pip install ./diff-gaussian-rasterization에서 오류가 계속 발생했다.
torch, cuda, xformer등의 버전이 맞지 않아서 생긴 오류였다. github 페이지대로 torch 버전을 설치하면, xformer가 제대로 설치되지 않는 것 같았다. 그래서 xformer 페이지에 들어가서 버전을 확인하고 재설치 후 해결됐다. -
pretrained weights 다운로드
깃헙 페이지대로 실행하면 저장한 pretrained 이름이 달라서 오류가 난다. 왜 model_fp16이 아닌 다른 파일명으로 해놨는지 이해가 안된다. 어쨌든 밑 코드를 보고model_fp16_fixrot->model_fp16로 수정해서 해결되었다. -
gradio
이걸 40분을 기다렸다.. ^^ app.py의 마지막 코드에서 share=True로 바꿔야 public url이 생기고, 거기로 접속해서 gradio에서 실행하는거다… gradio를 몰랐던 내 잘못.. 코랩이 일을 안하는데 계속 실행되면 항상 점검해보자... gradio보다는 직접 test하는게 정확할테니 이 코드는 그냥 빼버렸다. -
local gui
Colab에서 위의 local gui는 되지 않았다. 코랩에서는 실행이 불가능한 코드라 뺐다. 대신LGM/workspace_test에 저장되는 결과물을 다운받아서 확인하면 된다. -
mesh conversion
github에 제공된 코드로는 실행이 되지 않고 계속 에러가 뜬다. github issue와 Github - LGM-jupyter를 참고해보니,--force_cuda_rast옵션을 주면 해결된다.
실행 결과
여러 샘플을 입력했을 때, DreamGaussian보다 성능이 훨씬 좋았다. 지금부터 가장 차이가 컸던 샘플에 대한 DreamGaussian과 LGM의 결과를 비교해보겠다.
Input image

이 이케아 인형은 정면도 측면도 아닌 애매한 각도에서 찍어서 사실 제대로 reconstruction하기 어려울 것이다. 이 single image를 input으로 넣어서 돌려보았다.
DreamGaussian
.obj

Geometry
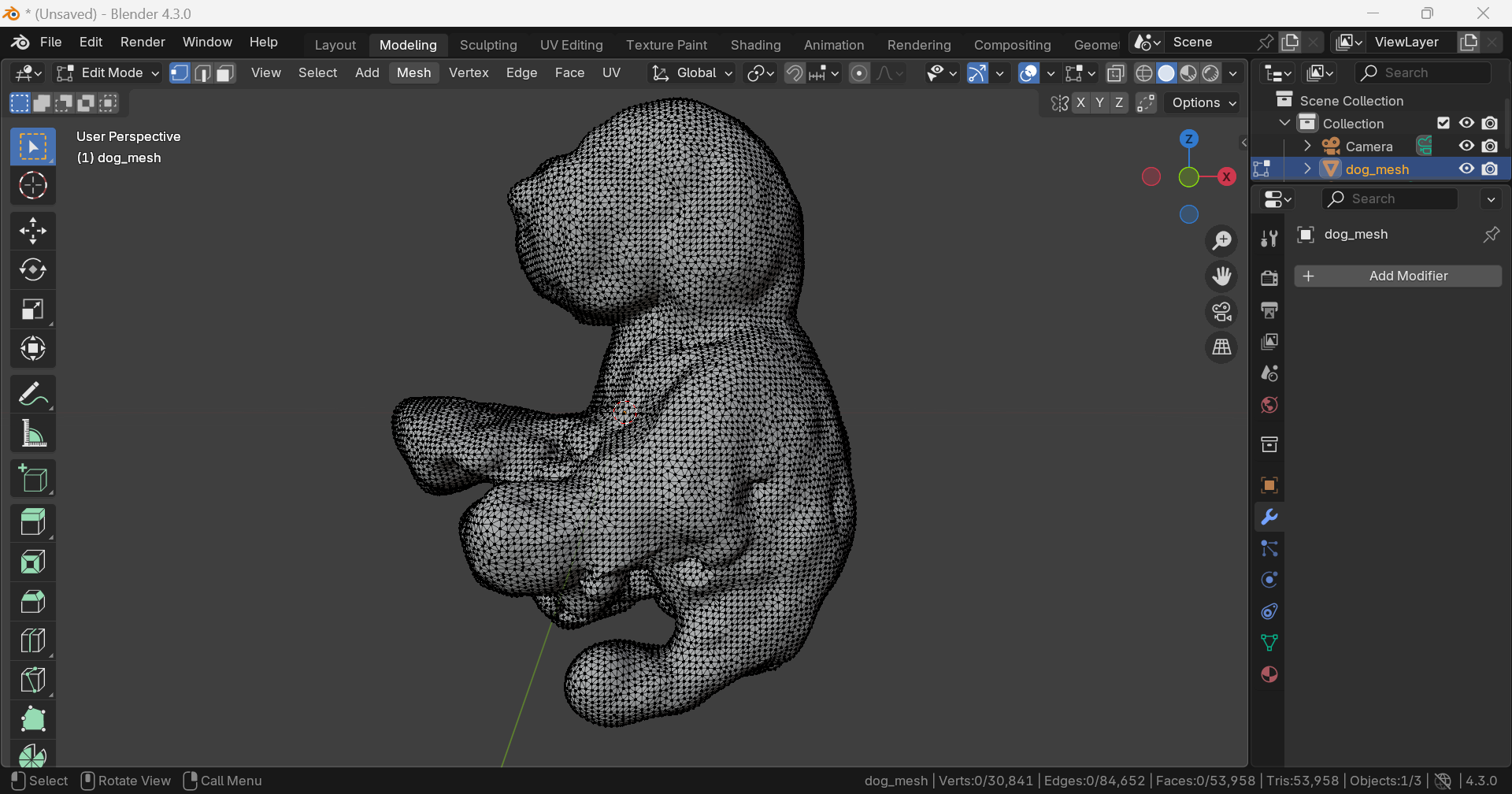
Vertex: 30,841, Edge: 84,652, Face: 53,958, Triangle: 53,958
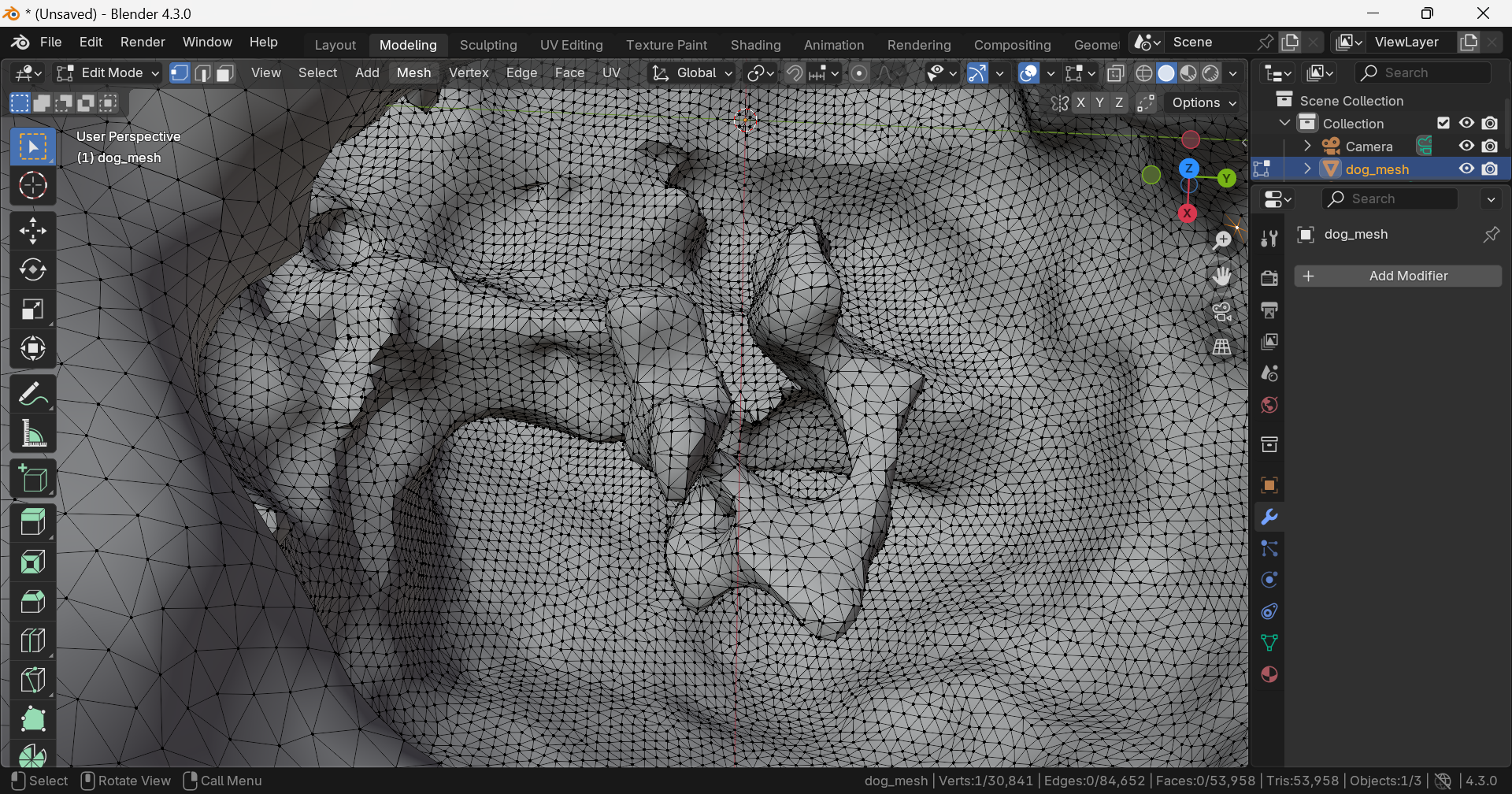
내부에 불필요한 geometry가 존재한다.
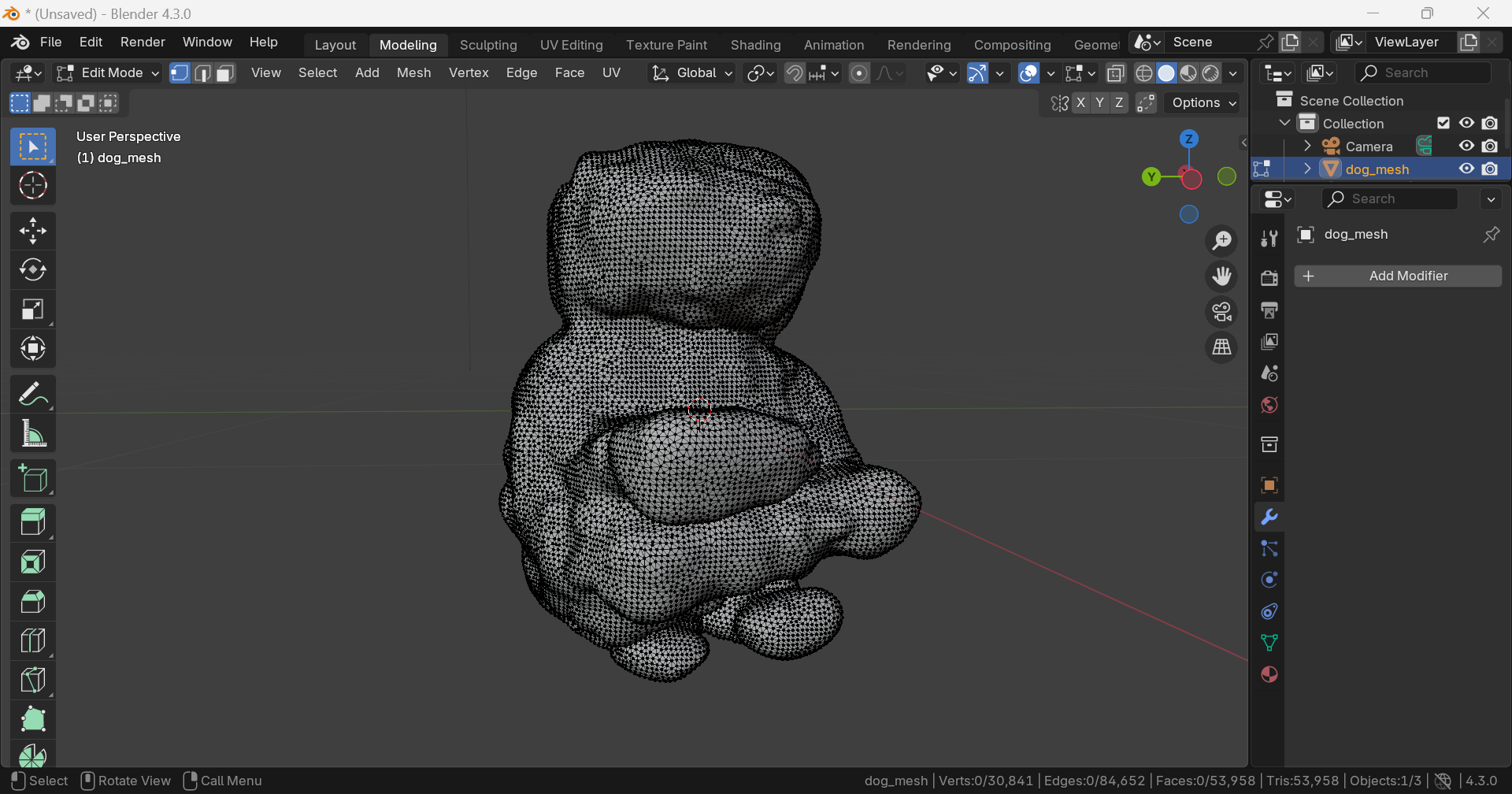
강아지 형태가 전혀 아니다.
LGM
.ply

.obj

Texture
edge를 바탕으로 텍스쳐를 예측하는 것인지, 예측한 뒷면의 텍스쳐의 색이 너무 어두웠다.
Geometry
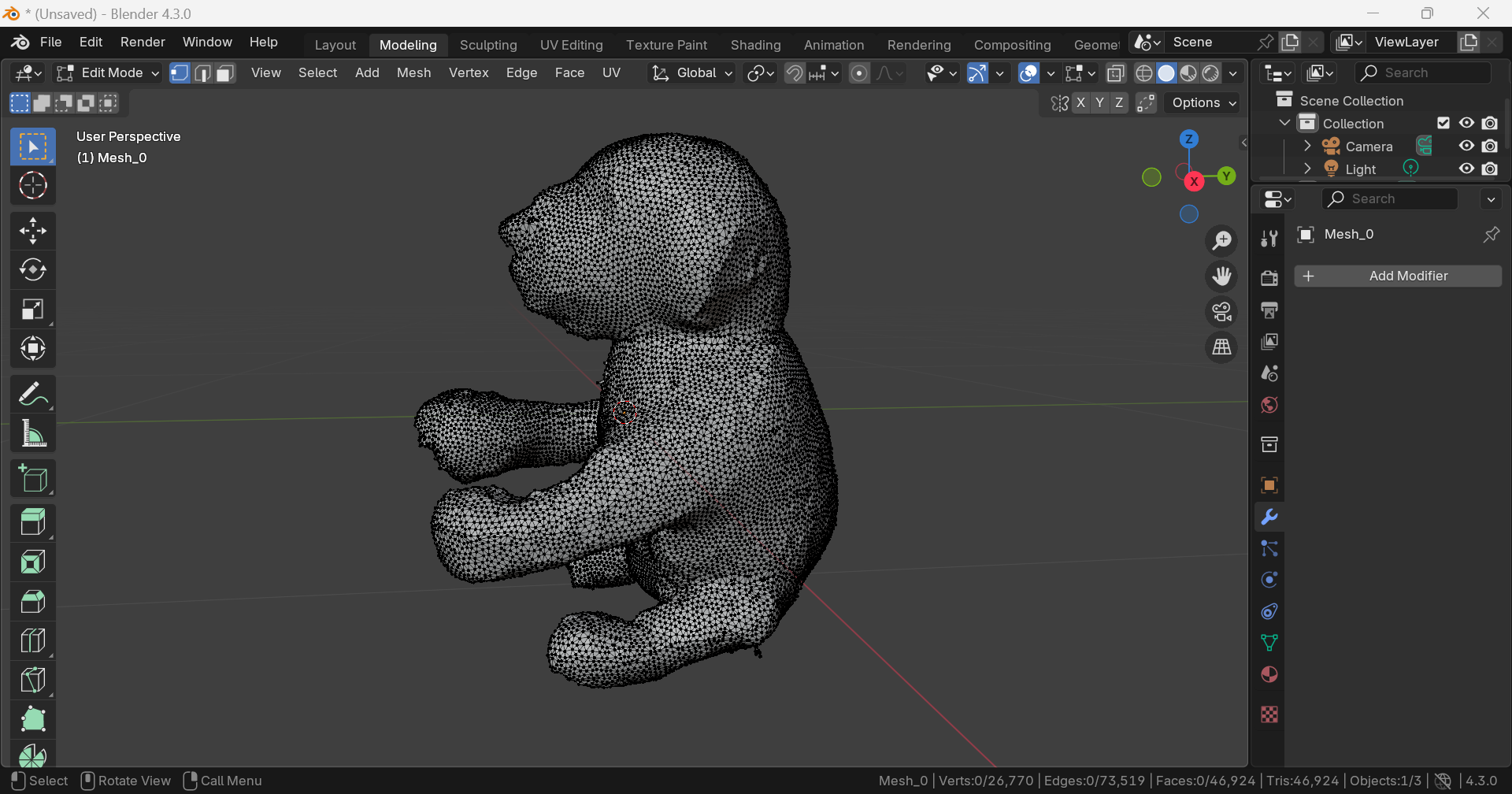
Vertex: 26,770, Edge: 73,519, Face: 46,924, Triangle: 46,924
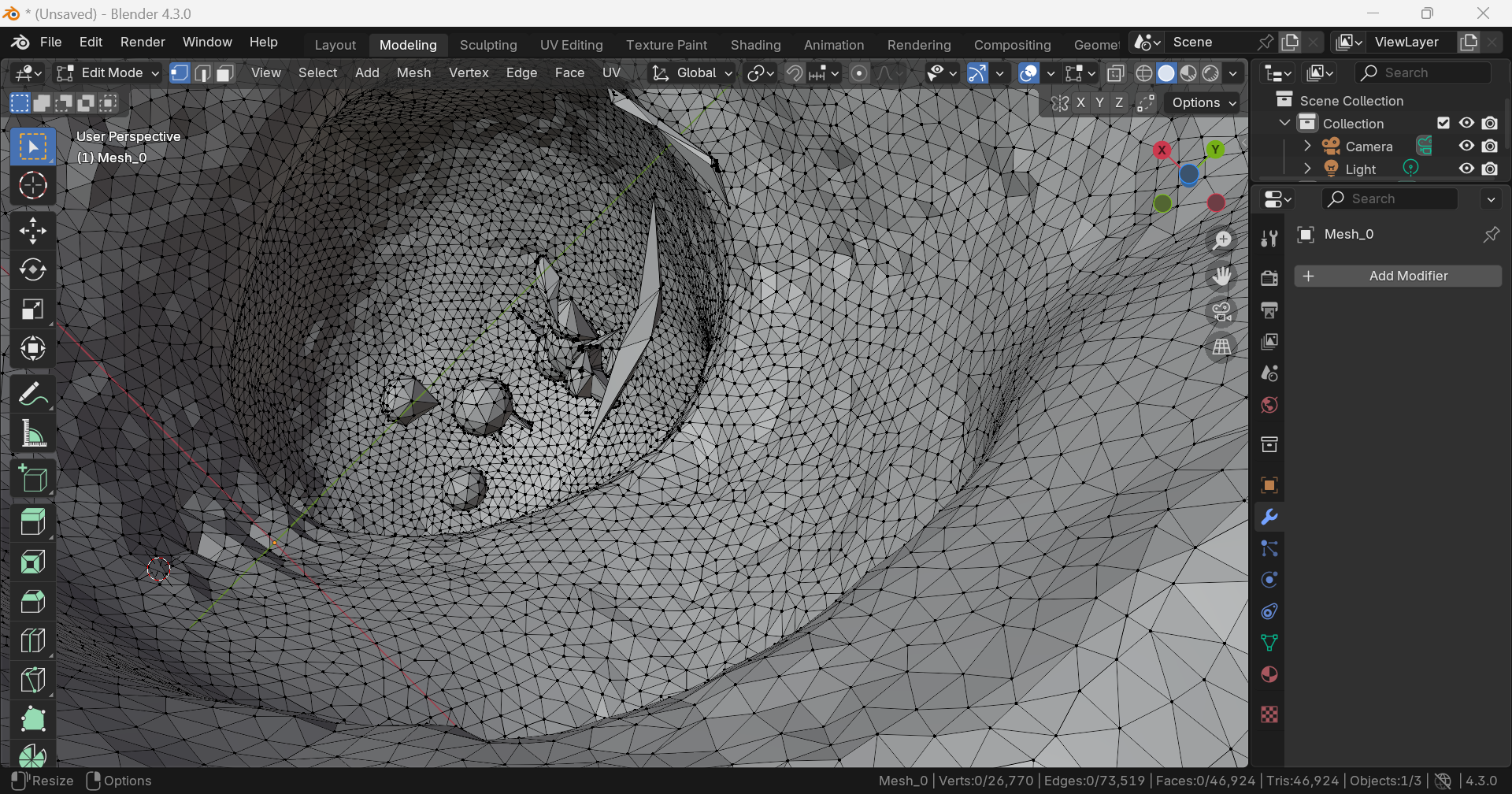
내부에 불필요한 geometry가 있지만, DreamGaussian보단 적고 작다.
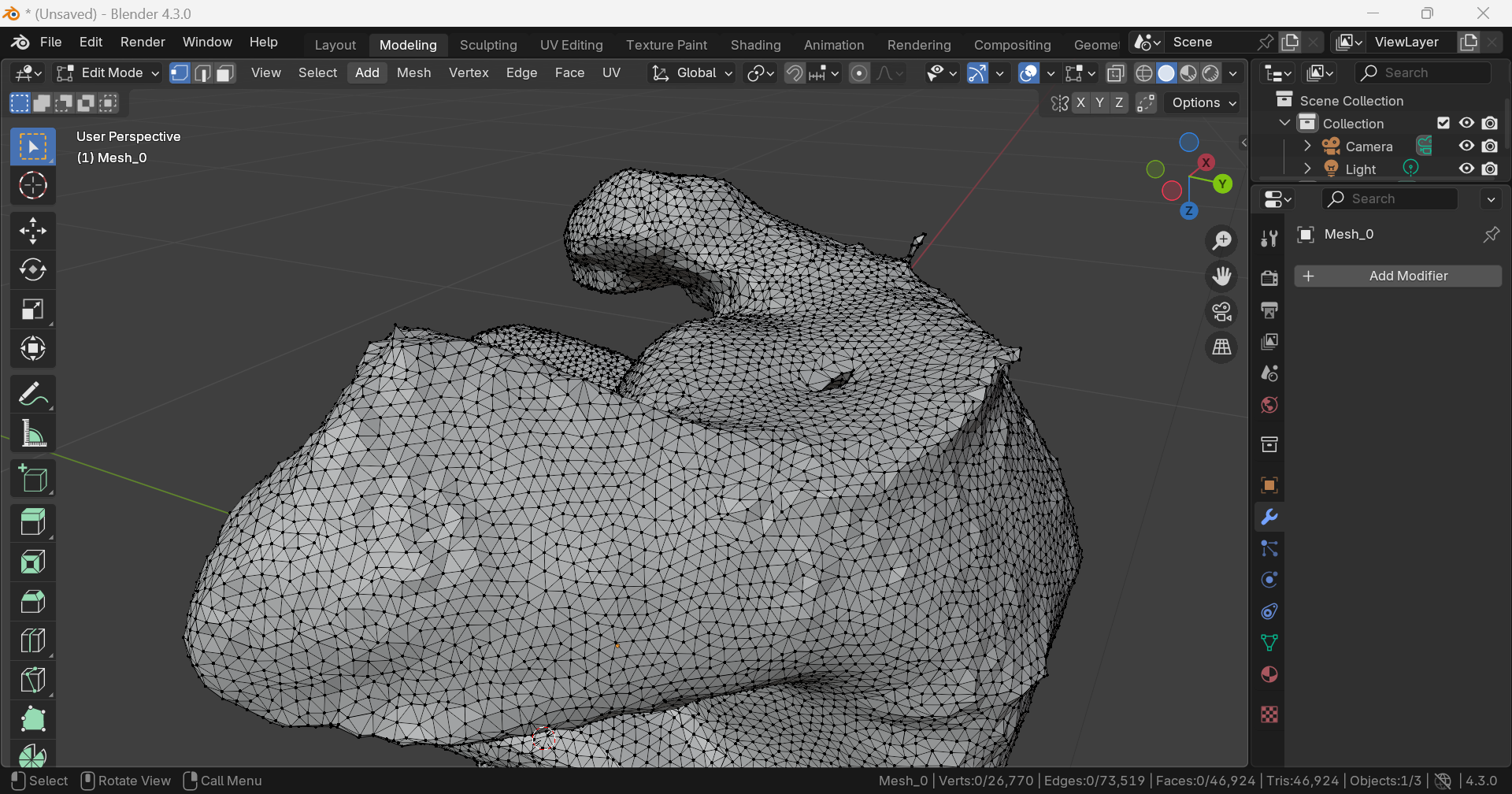
아래쪽에 hole이 있다.전체적으로 표면이 울퉁불퉁하다.
결과 분석
두 모델을 비교해서 정리해보면,
LGM이 전체적인 형태를 훨씬 잘 예측했다.- Geometry 측면에서는
LGM의 Vertex 수가 적었다.- Texture 측면에서는
DreamGaussian이 잘 예측했다.
DreamGaussian과 LGM의 방식은 굉장히 다르다. 이 둘을 결합하여 장점만 가져올 수 있을지 궁금하다.
부록
귀여워서 huggingface demo로 돌려본 햄스터


demo로 하면 직접 돌렸을때보다 결과가 안좋긴 한데, 감안해도 말도 안되는 결과가 나왔다. 어이가 없다. 화질이 안좋아서 그런가...
