REST API / RESTful API란?
REST API
REST API는 REST를 기반으로 API를 구현한 것이다.
그렇다면 REST는 무엇일까?
REST는 HTTP/1.0과 1.1 스펙 작성에 참여했고 아파치 HTTP 서버 프로젝트의 공동 설립자인 로이 필딩의 2000년 논문에서 처음 소개됐다. 발표 당시 웹이 HTTP를 제대로 사용하지 못하는 상황이었기 떄문에 HTTP의 장점을 최대한 활용할 수 있는 아키텍처로 REST를 소개한 것이다.
즉, REST는 HTTP를 기반으로 클라이언트가 서버의 리소스에 접근하는 방식을 규정한 아키텍처다.
REST는 REpresentational State Transfer의 약자다. 자원의 표현에 의해 상태를 전송하는 것을 의미한다. 자원은 서버가 클라이언트로 전송하는 모든 콘텐츠(비디오, 텍스트, 사진 등) 데이터다.
REST API의 기본 원칙 6가지를 알아보자.
REST API 원칙 6가지
1. Client-Server (클라이언트-서버 구조)
자원이 있는 쪽이 서버, 자원을 요청하는 쪽이 클라이언트로 나눠지는 구조를 말한다.
서버는 API를 제공하고 비즈니스 로직 처리 및 데이터 저장을 책임진다.
반면 클라이언트는 사용자 인터페이스에 대한 관심(사용자 인증 등)를 담당하여,
서버와 클라이언트 간 의존성을 줄이고 확장성을 개선할 수 있게 된다.
확장성이 높다는 것은 '분산 시스템'을 효율적으로 사용할 수 있다는 의미다.
2. Stateless (무상태성)
클라이언트에서 서버로 요청 시 이전과 이후에 대한 컨텍스트가 포함되지 않고, 각 요청에는 요청에 대한 모든 정보가 포함되어야 한다. 그렇기 때문에 하기에서 설명할 '자기 서술적인 메시지'가 지켜져야 한다.
3. Cachable (캐시 처리 가능)
요청에 대한 응답 내에 캐싱이 가능한지 여부에 대한 라벨링을 한다. HTTP Header의 cache-control 값에 따라 캐시 여부를 확인할 수 있다. 만약 캐싱이 가능하다고 응답이 오면 클라이언트는 동일한 요청에 대해 응답 데이터를 재사용할 수 있다.
4. Layered Sytem (계층화)
REST API 서버는 다중 계층에서 실행되도록 설계할 수 있다. 순수 비즈니스 로직을 수행하는 API 서버와 그 앞에서 사용자 인증, 암호화, 로드 밸런싱 등을 하는 계층을 추가해서 구조상의 유연성을 높일 수 있다. (ex. Reverse Proxy) 이러한 계층은 클라이언트에 보이지 않는 상태로 캡슐화된 상태로 구성된다.
위의 1~4번까지는 http 프로토콜을 사용하면 지켜지는 규칙이다.
5. Uniform Interface (★ 균일한 인터페이스, 가장 중요)
API를 사용하는 클라이언트에게 자원에 대한 균일한 API 인터페이스를 결정해야 한다. 그 원칙으로는 4가지가 있다. 이 원칙들이 가장 구현하기 어려우면서도 중요한 부분이다.
1) URI로 자원을 식별한다. 즉, 특정 자원은 오직 하나의 URL만 가져야 한다.
2) 표현을 통해 자원을 조작한다. 즉, 자원 자체를 전송하는 것이 아닌 자원의 표현을 전송한다.
3) 자기 서술적인 메시지여야 한다. 즉, 요청, 응답과 같은 메시지는, 메시지 그 자체만 보고 무슨 의미인지 파악할 수 있을 정도로 정보가 담겨있어야 한다.
4) HATEOAS (hypermedia as the engine of application state, 헤이티오스), 애플리케이션의 상태가 Hyperlink를 이용해 전이되어야 한다.
이 중에서 4번 헤이티오스가 직관적으로 이해가 가지 않아 좀 더 찾아봤다.
HATEOAS(헤이티오스)란 무엇일까?
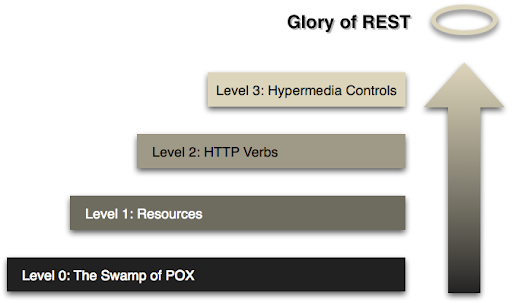
REST API도 구현 단계에 따라 등급이 있다. 이를 표현한 것이 Richardson 성숙도 모델이다.

그러니까 REST API의 천상계 레벨이 HATEOAS를 적용한 모델인 것이다.
위 표를 보면 그동안 내가 구현해온 REST API는 HTTP 메소드로 행위를 나타내고 URI로 자원의 상태를 표현하는 2 레벨에서 머물러 있었던 것 같다.
레벨 2에 헤이티오스를 적용한 것이 궁극의 3단계 REST API가 되는 것이다.

헤이티오스가 적용된 응답 예시를 자세히 살펴보자.
우선 헤이티오스가 적용되지 않은 응답 부분(Data Content)만 보면 '세르조 레오네'라는 영화 감독의 이름과 출생년도를 id와 함께 전달하고 있다. 여기에 헤이티오스가 적용된 부분을 보면 _links 부분에 객체가 전달되고 있는데, self, director_movies, directors까지 총 3개의 값에 대한 하이퍼링크도 전달되고 있다.
해당 url을 보면 self는 감독에 대한 정보를, director_movices는 감독의 영화 정보들을, directors는 전체 감독들의 목록을 확인할 수 있는 페이지라는 것을 유추할 수 있다.
즉, directors 하위의 연관된 링크까지 전달해서 애플리케이션이 어떤 서비스를 제공하는지 한눈에 알아볼 수 있게 하는 것이다.
이때 헤더의 Content Type에 application/hal+json으로 전달하면 클라이언트에서 _links 필드에 링크 정보가 담겨있다고 예상할 수 있다.
그럼 왜 HATEOAS를 사용해야 할까?
높은 수준에서 클라이언트와 서버를 분리시키고 의존성을 줄여서 클라이언트와 서버를 각각 독립적으로 개발하기 위해서다.
클라이언트 입장에서는 서버에서 url을 바꿔도 _links의 하이퍼링크들을 통해 리소스에 접근이 가능하다. 따라서 클라이언트, 서버가 각자 개발될 수 있는 것이다.
다만 전달되는 데이터가 많아지면 네트워크 오버헤드가 생길 수 있고, 링크가 많으면 복잡해진다는 단점이 있다.
6. code-on-demand (코드 온 디맨드, optional)
서버에서 코드를 클라이언트로 보내서 실행할 수 있어야 한다.
우리는 평소에 정적인 데이터를 json에 담아서 클라이언트로 보내고 클라이언트가 이것을 가공한다. 하지만 code on demand는 클라이언트에 데이털르 바로 실행 가능한 코드로 보내고, 클라이언트가 이를 실행하는 것을 말한다.
RESTful API
REST 원칙을 충실히 지켜서 설계된 API를 RESTful API라고 한다.
- REST API: REST를 기반으로 만들어진 API
- RESTful API: REST 원칙을 충실히 지켜서 설계된 API
글을 마치며
스터디를 하기 전에는 단순히 RESTful API의 특징을 크게 두 가지로 생각했다.
'HTTP 요청 메소드로는 자원의 행위만 나타내야 하고, URI는 자원의 상태만 나타내야 한다.'
하지만 자세히 조사해보니 그동안 내가 알고 있던 RESTful API에 대한 개념은 네이밍에 초점이 맞춰져 있었던 것 같다. 사실 위에서 소개한 원칙 6가지 중에서 4가지는 HTTP 프로토콜을 사용함으로서 자연스럽게 지켜진다. 그래서 HTTP 프로토콜을 사용함으로서 얻을 수 있는 이점은 놓쳤던 것이다.
또한 REST API 구현에는 단계가 있으며 궁극의 단계인 HATEOAS도 존재한다는 것을 알게 되었다.
- 참고 자료:
https://blog.naver.com/seek316/222072210416
https://jaeseongdev.github.io/development/2021/06/15/REST%EC%9D%98-%EA%B8%B0%EB%B3%B8-%EC%9B%90%EC%B9%99-6%EA%B0%80%EC%A7%80/
https://doitnow-man.tistory.com/96
http://amazingguni.github.io/blog/2016/03/REST%EC%97%90-%EB%8C%80%ED%95%9C-%EC%9D%B4%ED%95%B4-1)
https://zeroco.tistory.com/103
