A Character-Centric Neural Model for Automated Story Generation (AAAI, 2020)
Generation Study🐱👤
Liu, D., Li, J., Yu, M. H., Huang, Z., Liu, G., Zhao, D., & Yan, R. (2020, April). A character-centric neural model for automated story generation. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 02, pp. 1725-1732).
들어가기 전
제목에서도 알 수 있다! 이 논문의 핵심은, 스토리 생성에 있어서 캐릭터를 고려하는 것이다.
지금까지 읽었던 논문은, 기본적으로 프롬프트나 스토리라인등을 이용하여 스토리를 생성하는 그런 내용이었다. 이제부터 2주간 읽을 논문들은 거기에 어떠한 제약조건이 들어가게 된다고 한다. 내가 읽은 논문의 경우는 캐릭터가 바로 이 제약조건의 역할을 한다.

정말 세상에는 이렇게나 다양한 개성을 가진 캐릭터들이 무수히 많이 존재하는데, 캐릭터들을 조건으로 하여 스토리를 만들면 스토리 개연성이나, 입체성에 있어서 훨씬 더 좋은 스토리를 만들 수 있을 것 같다는 생각이 들었다. 그러면 캐릭터의 설정을 어떻게 잘 임베딩해서, 어떤 식으로 생성 과정에 포함시킬 수 있는지 중점으로 읽어보려고 했다.
Abstract
Story generation에 있어서의 맹점은, 일관된 캐릭터와 상관관계가 있는 연속적인 플롯으로 구성된 스토리를 만드는 것이며, 최근에는 variational autoencoder, generative adversarial network, convolutional sequence to sequence model 같은 다양한 최신 모델들을 기반으로 story generation이 이루어지고 있다.
그런데, 기존 모델은 설명가능성과 일관성(explainability and consistency)의 측면에서, 이야기 장르의 속성과 사전지식을 거의 고려하지 않았다. 따라서 저자들은 이러한 갭을 메우기 위해서, character-centric neural storytelling model을 제안한다. 즉, 캐릭터를 중심으로 이야기를 생성하겠다는 의미다.
그렇다면 이걸 어떻게 가능하게 하냐? 생성될 스토리의 각 부분을 주어진 (1)캐릭터와 (2)컨텍스트에 의해 결정하도록 했다.
한 마디로 요약하자면, 기존 스토리텔링 연구의 문제점은 설명가능성과 일관성이 부족했다는 것이고, 이를 캐릭터 정보와, 플롯과 캐릭터간의 관계(즉, 컨텍스트)를 명시적으로 캡처하여 해결하겠다는 의미이다.
Introduction
저자들은 Story generation task가 🔥new hotspot🔥이라고 이야기한다. 그러면서, Story generation은 예전의 hand-craft 방식에서 최근의 NN기반 방식까지, 모델링적인 측면에서 크게 발전하고 있으나 아직까지 해결하지 못한 두 가지의 문제점을 꼽는다. 바로, 설명가능성과 일관성(explainability and consistency)이다.
기존의 스토리 생성 방법은, 단순하게 long document를 생성하거나 혹은 long-range dependency를 해결해보고자 이 long document를 multi-stage로 분할하여 document를 생성하곤 했다.
아주 보편적인 프레임워크는 먼저 neural language model을 사용해서 키워드, 스켈레톤, 프롬프트 같은 intermediate representations을 생성하고, 이에 대한 문장을 생성하는 또 다른 neural language model을 사용하게 된다. 우리가 여태껏 읽어왔던 논문들이 이러한 맥락이었다. 이러한 접근 방식으로 train dataset으로 부터 구문이나 어휘는 잘 포착할 수 있다.
-
그러나🤔, 어떤 모델링 캐릭터나 플롯은 잘 학습할 수 없다. 이렇게 되면 생성되는 스토리 자체는 그럴 듯 하지만, 전혀 관련 없는 플롯과 캐릭터로 구성될 수 있는 위험이 있다. 왜 이런 스토리가 생성이 된거지? 왜 이 캐릭터가 이런 행동을 한거지?에 대한 해답을 찾기 어렵다는 의미같다.
-
또 다른 문제로는, 기존의 방식으로는 의미 수준의 일관성만을 보았다. 이 말인 즉슨, 주제의 일관성을 보거나, 문장 간의 일관성 만을 고려했다. 당연히 캐릭터 일관성 등은 고려하지 않았다.
이러한 문제를 저자들은 스토리 장르의 관점에서 해결하고자 한다. 바로바로 캐릭터의 등장이다.

스토리 생성에 캐릭터의 등장이라..
캐릭터의 신뢰도를 높이기 위해서는 캐릭터 모델링이 도움이 된다는 사전 연구가 있기 때문에, 저자들은 스토리 생성 네트워크를 캐릭터 모델링과 결합한다.
즉, 이야기에 어떤 일관된 캐릭터를 할당하게 된다. 그러면 스토리 생성 프로세스는 그러한 컨텍스트 환경에서 주어진 캐릭터의 일련의 행동을 선택하는 것으로 치환된다. 결과적으로 생성된 스토리는, 캐릭터와 컨텍스트를 명시적으로 연관시키기 때문에 전체 스토리의 설명성이 올라가게 된다. 추가로, 주어진 캐릭터는 스토리 생성 과정의 각 단계에서 액션 선택 작업을 안내하여 캐릭터의 일관성을 높인다.
앗. 혹시 멘탈헬스팀이신가요?추가적으로, 이러한 전략은 dialogue systems에서도 동일하게 성능(화자 일관성 향상)에 도움이 된다는 사전 연구 (Li et al. 2016) 가 있었다 . 자세히 보지는 않았지만, 대화 시스템에 페르소나 개념이 들어간 연구 같은데 인용수도 상당히 많아서... 이미 아실 것 같지만, 그래도 대화 시스템 연구하시는 분들께 참고하시라고 링크를 남긴다 케케.
이 논문에서는..
따라서 앞서 내용을 종합하여서, 본 논문에서는 character-centric neural storytelling model을 제안한다.
이 모델은 캐릭터 임베딩을 통해 캐릭터를 인코딩하여 이를 활용해 스토리를 생성의 가이드로 사용한다.
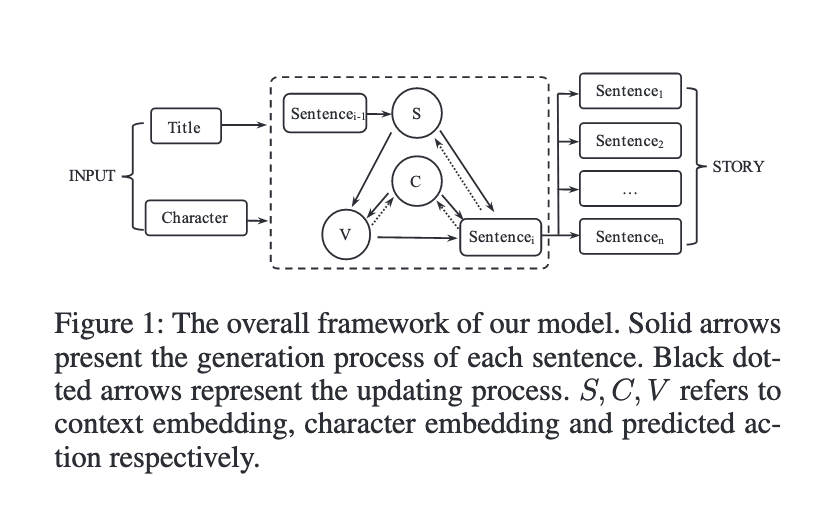
먼저 입력으로는, 타이틀과 캐릭터가 인풋으로 들어가게 된다. 모델에는 세 가지 구성요소가 포함되어있다. 바로 바로 character, situation, action이다. 정리해보면 다음과 같다.

Method
Overview를 보면 위와 같다. 그림을 보면 알 수 있듯 이 모델은 크게 두 단계로 구성되어있다.
- Action Prediction : 각 단계에서 현재 상황(Context)에 대한 캐릭터의 반응(Predicted Action)을 결정한다.
- Sentence Generation : 캐릭터 임베딩 + 예측 동작 + 상황 정보를 통합하여 완전한 문장(Generated Sentence)을 생성한다.
즉, 액션은 각 단계에서 주어진 캐릭터에 의해 결정되기 때문에, 이는 전반적으로 설명가능성과 일관성을 향상시킨다고 볼 수 있다. 저자들은 이러한 계층적인 generation framework을 통해 전 과정에서 fine-grained control을 가능하게 한다고 한다.
1. Problem formulation, notation
기본적으로 기존 storytelling models의 셋팅을 따랐다. sentence-by-sentence 방법으로 생성된다. (이전에 생성된 문장이 다음 문장을 위한 입력으로 들어간다.)
- INPUT. 타이틀은 , 캐릭터 임베딩은 은 학습 단계에서 학습되며, 다음 스토리를 생성하기 위한 입력으로 모델에 들어가게 된다.
- OUTPUT. 스토리는 으로 모델의 아웃풋이며, 은 생성된 스토리의 n개의 문장 중에서 i번째 문장을 의미하며, 는 i번째 문장의 j번째 단어를 의미한다.
2. Character Embedding
각각의 캐릭터를 임베딩으로 표현하는 단계이다.
사전 연구 (Bamman, O’Connor, and Smith 2013)와 (De Marneffe and Manning 2008)에 기반해서, 각 캐릭터의 Related verbs(관련 동사)와, Attributes(속성)을 추출한다. Related verbs의 경우는 캐릭터가 에이전트인 경우 agent냐 patient에 따라 각각 agent verbs, patient verbs를 추출한다. Attributes의 경우, 형용사나 형용사 수식어이다.
이러한 word representation은, 평균값을 계산하여 single representation으로 표현되게 된다. 각 추출값의 평균을 계산했으므로, 이를 캐릭터 임베딩을 초기화하는 데 사용한다. 는 총 추출된 단어의 수를 의미한다.
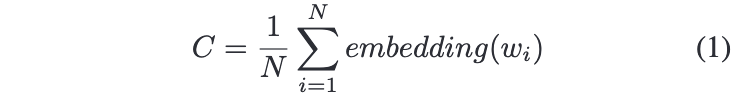
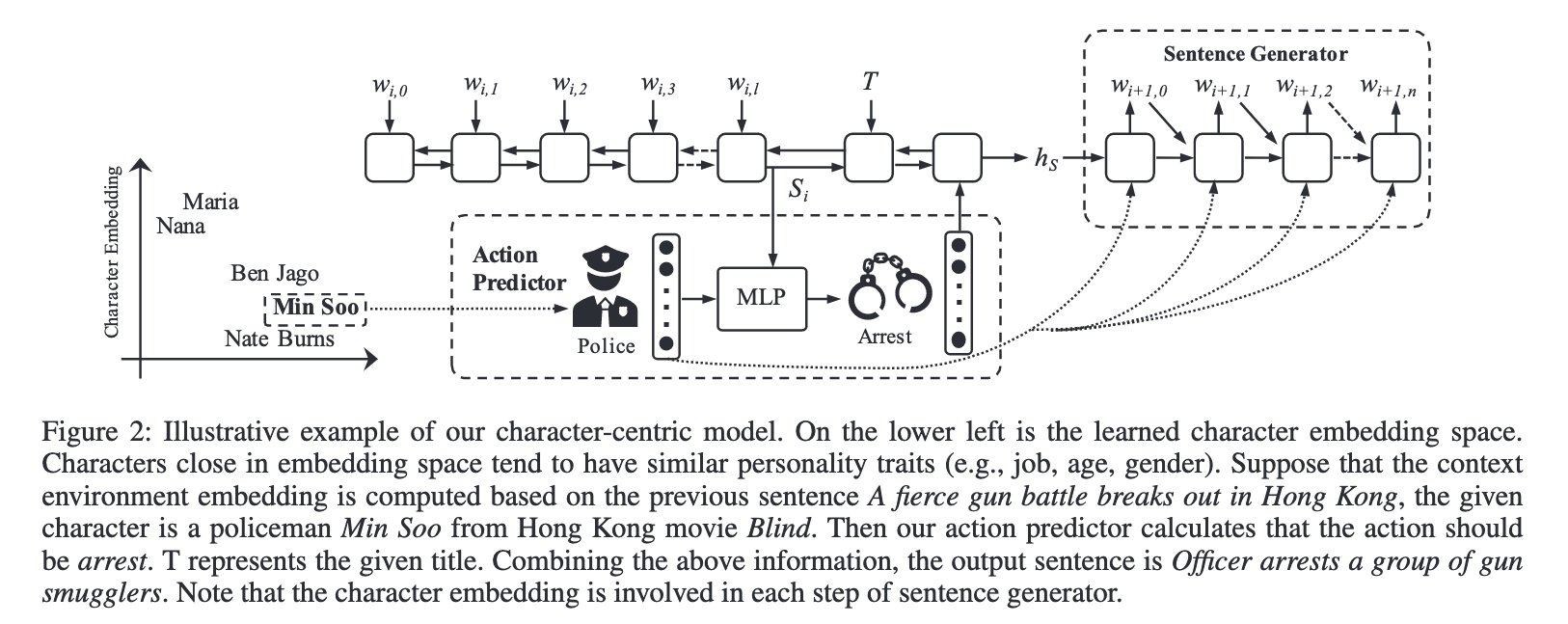
캐릭터 임베딩은, 캐릭터의 행동 결정에 영향을 미치는 캐릭터의 속성을 인코딩한다고 볼 수 있다. 이 때 캐릭터의 속성이란 그 캐릭터의 성격, 직업, 감정, 성별, 나이 등을 의미한다. 캐릭터 임베딩 는 이제 소개할 action predictor와 the sentence generator의 훈련 과정에서 모두 학습되게 된다.
추가로, 여기서는 언급되지 않았지만 이 캐릭터 임베딩의 행동에 대한 ground truth가 있다. 그런데 자세한 설명은 없다.😥 Related verbs(관련 동사)가 gt가 아닐까 추측..
3. Action Predictor
저자들이 제안하는 모델의 중심은 캐릭터이다. 따라서 이 논문에서 이야기하는 이야기의 전반적인 전개는, 현재의 상황(컨텍스트)를 기반으로, 캐릭터가 수행하는 건전하고, 믿을 만한 (sound and believable) 행동을 예측하는 것이라고 치환할 수 있다.
따라서 새로운 임베딩, 컨텍스트 임베딩이 등장하게 된다. 컨텍스트 임베딩은 스토리 세계에서 캐릭터를 둘러 싼 현재 환경 정보와 상황을 나타낸다. 각 타입 스텝 t에서, 컨텍스트 임베딩 는 현재 문장과, 전 타임스텝의 컨텍스트 임베딩 에 기반하여, bi-LSTM에 의해 계산된다.
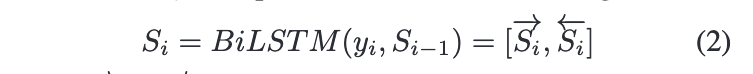
각각 ->와 <-는 포워드와 백워드 히든 벡터를 의미한다.
이렇게 컨텍스트 임베딩이 끝나면, 캐릭터는 다음 컨텍스트에서 어떤 행동을 하게 될지 결정하게 된다. 여기서 앞서 뽑았던 캐릭터 임베딩은 캐릭터가 이 상황에 대해 어떻게 행동할지에 대한 정보를 가져오게 된다.
최종적으로 캐릭터가 수행하게 될 행동에 대한 확률은 캐릭터 임베딩과 컨텍스트 임베딩의 컨캣을 multilayer perceptron (MLP)에 통과시켜서 결정된다. 바로 아래 수식이다.
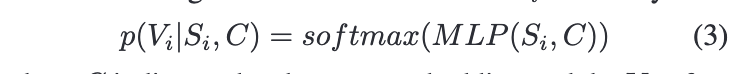
최종 확률 값인 가 바로 캐릭터가 다음 타임 스텝 i에서 어떠한 행동을 하게 될지를 나타내는 것이다.
학습 과정을 보자면, 시간 단계 i에 대하여 캐릭터 임베딩 C에 대한 ground truth 가 주어지기 때문에 negative log probability 를 최소화하는 방식으로 학습이 된다.
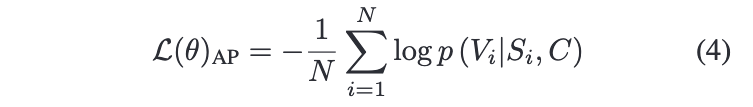
학습이 끝나면, 이제 이 모델은 다음 액션을 예측할 수 있게 된다. 또한 이러한 예측은 모든 캐릭터에 있어 일반화가 가능하다. 즉, 캐릭터가 훈련에 사용된 스토리 코퍼스에서 어떠한 상황을 한 번도 경험하지 못하더라도, 어떤 행동을 할 것인지 추론할 수 있다. 당연히 코퍼스에서 모든 캐릭터의 행동을 커버할 수 없기 때문에 이런 일반화 능력은 아주아주 중요하다. 구체적으로는 어떻게 하냐고 물어보신다면 대답해드리는게 인지상정.
이 모델은 어떤 특정 상황에 대한 행동 선택을 기반으로 캐릭터 representations을 학습해서, 유사한 행동 스타일을 보이는 캐릭터들은 임베딩 상에서 가까운 영역에 위치하도록 한다. 이렇게 되면 모델의 일반화 성능이 또 향상되게 된다.
예를 들어보자면, 직업이 경찰이고, 임베딩 공간에 가깝게 위치한 캐릭터 i,j를 가정해보자. 훈련데이터에는 이러한 스토리가 있었다.
경찰 i은 군중을 향해 총을 쏘는 남자가 있다는 무전을 받고 달려가서 그 남자를 체포했다.
그렇다면, j는 동일한 상황을 경험하지 않았더라도 i와 유사한 캐릭터 임베딩으로 인하여 j도 범인을 체포한다는 행동을 할 가능성이 높아지게 된다!
정리하자면, 캐릭터 임베딩의 일반화 능력으로 인해서, 캐릭터가 익숙하지 않은, 새로운 상황에서 자신의 특성에 맞는 행동을 할 수 있도록 도와준다.
4. Sentence Generator
전술했듯, 스토리는 sentence by sentence 방식으로 생성된다. 저자들은 이 스토리 생성 문제를, 수행할 행동 , 캐릭터 임베딩 , 컨텍스트 임베딩(현재 상황) 에 기반하여 문장을 생성하는 조건부 생성 문제로 포뮬레이션한다.
인코더와 디코더 모두 one-layer bi-LSTM networks를 사용한다. 먼저 field separator token < EOS > 와 < EOT > 사이에 , title , action 를 컨캣해서 넣고, 이를 bi-LSTM을 통해 저차원 벡터 로 인코딩한다.
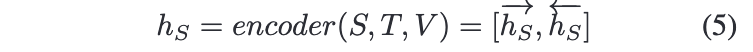
다음으로 디코더는 앞서 인코더의 출력인 와 캐릭터 임베딩 을 통해 sentence condition을 생성하게 된다. 디코더의 각 타임 스텝마다 hidden units을 얻게 되는데, 이는 이전 타임스텝의 hidden state 와, 현 타임스텝의 워드 임베딩 , 캐릭터 임베딩 를 통해 계산하게 된다.
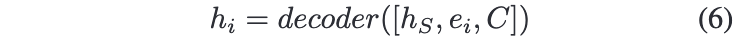
훈련 과정을 보게 되면, 타겟 문장 을 예측할 때, seq2seq 모델은 훈련셋에 있는 문장의 negative log probability 를 최소화하도록 훈련된다.
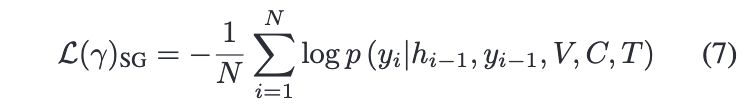
이 문장 생성 단계에서 캐릭터 임베딩을 통합하는 것도 중요하다. 왜냐하면, 액션 외에도 하나의 완전한 문장을 형성하기 위해서는 수많은 정보(형용사, 부사, 목적어...)가 필요하기 때문이다.
예를 들어서, 캐릭터 i가 농구선수이고, 예측된 액션은 play라고 하자. 캐릭터 임베딩을 고려하면, 우리 모델은 스팀게임이나, 비디오 같은 목적어 대신 농구를 목적어로 생성하게 된다.
또한, 캐릭터 임베딩은 논문에서 내내 강조하는 설명가능성과 일관성을 향상시킨다. 또 예를 들어 보자.
캐릭터 i는 신생아이고, 이 아이는 불행하게도 위험에 직면했을 때 우는(cry) 것 밖에는 할 수 없다.
Maximum Likelihood Estimation 기반의 기존 모델들은 스토리 코퍼스의 일반적인 패턴을 기억하는 경향이 있다. 즉, 스코리 코퍼스에서 위험한 상황에서 같이 자주 발생하는 "run away"같은 단어를 예측하게 된다. 그러나, 우리 모델은 캐릭터를 명시적으로 고려한다는 중요한 차이점이 있다. 따라서 모델은 캐릭터의 속성(나이, 성별, 성격...)과 일치하는 적절한 액션을 선택하도록 한다.
Training Strategy
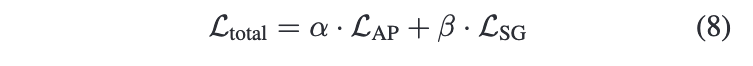
목적함수이다. 첫 번째 로스는 action predictor, 두 번째는 Sentence generator를 각각 표현한다. 앞에 하이퍼 파라미터로 중요도를 조절하게 된다. 논문 실험 셋팅에서는 각각 1과 0.8을 사용했다.
공식 implementation이 있다고 논문에 링크가 명시되어 있어서 들어가봤더니 이제 비공개다.. 속았다. 하지만 혹시 몰라 링크는 남겨둔다.
Experiment
Dataset
Wikipedia에서 추출한 영화 줄거리 요약 코퍼스를 사용했다. 영화는 아니지만, 대 인기 만화 겸 애니메이션 JoJo's Bizarre Adventure의 위키피디아 Plot 항목에 가보면 이러한 설명이 있다.
In late 19th-century England, Jonathan Joestar, the young son of a wealthy landowner, meets his new adopted brother Dio Brando, who loathes him and plans to usurp him as heir to the Joestar family. When Dio's attempts are thwarted, he transforms himself into a vampire using an ancient Stone Mask and destroys the Joestar estate. Jonathan embarks on a journey, meets new allies, and masters the Hamon (波紋, "Ripple") martial arts technique to stop Dio, who has made world domination his new goal.
Dio같은 인물, young son 같은 연령과 성별 정보, embarks나 masters같은 action등의 인물에 대한 암시적인 설명과, 전체적인 스토리의 사건에 대한 간결한 요약이 포함되어있다.
저자들이 사용한 데이터셋으로 돌아와서, 데이터셋은 42,306개의 스토리를 포함한다. 스토리 길이의 중간값과 평균은 각각 176단어와 310단어이다. 각 문장에는 평균 16개의 단어가 있다. 토큰화를 위해 모든 문자를 소문자로 변환하여 사용했다. vocabulary 구성은, 50,000개로 설정했으며 포함되지 못한 2.06%의 단어는 < unk > 로 대체하였다. 스토리의 제목은 각 영화의 제목을 사용하였다.

데이터셋의 예시는 다음과같다. 전처리는 수행하기 전 raw 데이터같다.
코퍼스에서 구조와 implicit 정보를 뽑아내기 위해서 Stanford CoreNLP library를 사용했다. 문장 분할이나 pruning은 (Martin et al. 2018)의 연구를 참고하였다(세정님 첫 번째 발표). 전치사구는 제거하고, 접속사를 기준으로 문장을 분리했다. 코퍼스를 모델의 입력으로 사용하기 위해, related verbs attributes을 추출했다.
Baseline
베이스라인으로는 non-character-based model을 사용했다.
- Conditional Language Model(C-LM)
- Seq2Seq with Attention(Vanilla-Seq2Seq)
- Incremental Seq2Seq with Attention(Incre-Seq2Seq)
- Plan-and-write (민지님이 지난 주 발표해주신 논문)
- Event Representation (세정님이 두 번째로 발표해주신 논문)
- Hierarchical Convolution Sequence Model (Hierarchi-cal) (이 논문은 강지원님께서 발표해주셨던 논문의 저자들의 바로 전 논문)
Evaluation
저자들이 사용한 메트릭은 다음과 같다.
- BLEU
- Perplexity
- Human Evaluation : 세 가지 측면으로 평가하였다. (1) explainability, (2)character-believability, (3) fluency
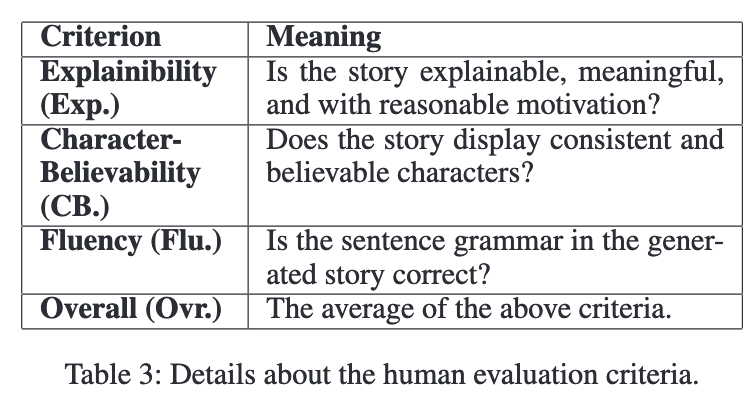
5명의 평가자가 1부터 4까지 스코어링을 진행했다. 각 모델이 생성한 100개의 스토리를 랜덤으로 선정하여 실험을 진행했다. 마지막으로 평가 항목 3개의 평균을 계산하여 마지막 overall performance를 계산하였다.
Result
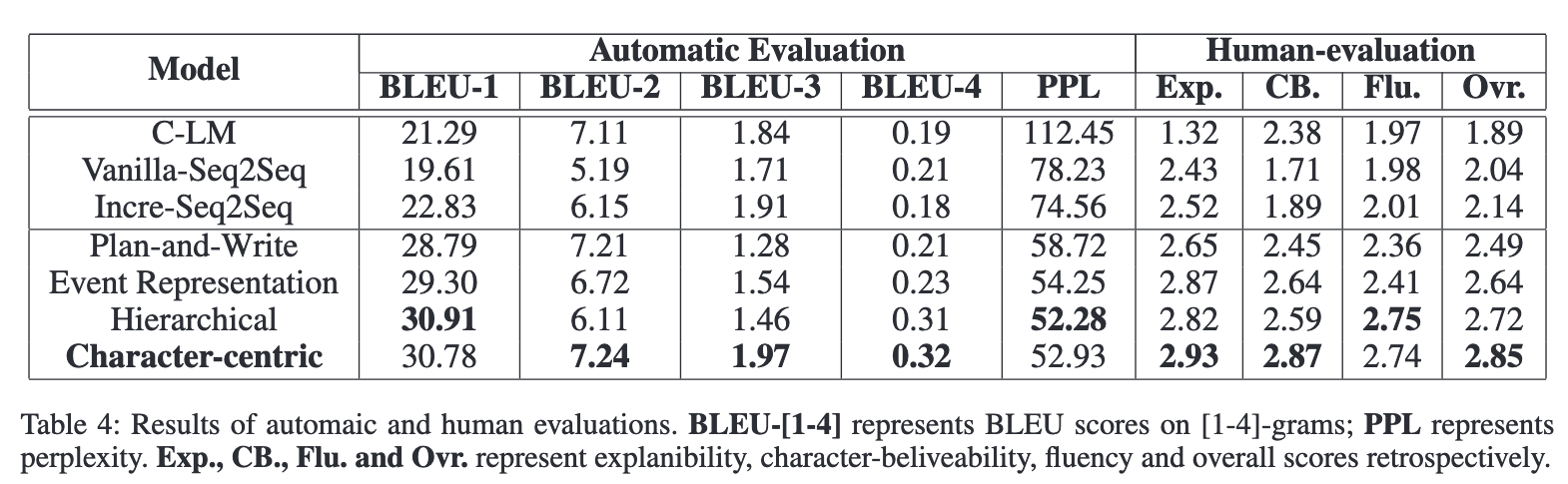
전반적으로 다른 state-of-the-art story generation method보다, 제안하는 Character-centric의 성능이 좋다.
- 먼저 C-LM를 보면, Perplexity가 상당히 높다. 이는 RNN 기반의 모델이 처리하기에 코퍼스 길이가 너무 길었기 때문이라고 분석했다.
- 바로 그 아래 seq2seq 모델과 비교해보면, Character-centric은 모든 seq2seq 모델보다도 성능이 좋다. 이는 캐릭터 임베딩과 액션 프레딕션의 효과라고 하는데, 아래 ablation study에서 자세히 볼 예정이다.
- 그 아래 Plan-and-write 같은 경우는, 키워드 시퀀스를 조건으로 하는 언어 모델을 사용해서 단어간 로컬 관계에 초점을 맞추는데, 키워드 보다 캐릭터에 초점을 맞추는 편이 모든 메트릭에서 더 좋았다.
- Event representation 모델은 이벤트 시퀀스를 생성하고 이벤트를 자연어 문장으로 변환하기 때문에 이벤트와 문장 간의 글로벌 정보를 더 잘 캡처할 수 있다.
Event representation 모델과 우리 모델은 성능에 아주 큰 차이는 없지만, 우리 모델은 캐릭터 관점에서 이야기를 생성하는 반면 Event 모델은 semantic intermediate representations에 중점을 둔다는 차이점이 있다. - 마지막으로, Hierarchical 모델은 long-range dependencies를 캡처할 수 있는 모델 퓨전과, 셀프 어텐션을 사용한다. 결과를 보면, Hierarchical 모델이 BLEU-1, perplexity와 fluency에서 가장 성능이 좋다 ...!
human evaluation의 경우, Character-centric 모델은 consistency and character believability 항목에서 최고 점수를 받았다.
Ablation Study
The Effect of Character Embedding
캐릭터 임베딩의 효과를 보기 위해 non-character model에 대한 실험을 수행했다.
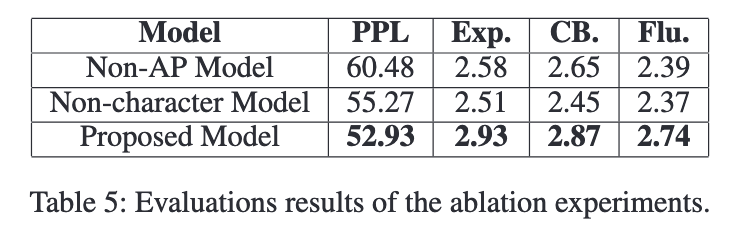
Character embeddings improves character-consistency in generated stories.
캐릭터 중심 모델이, 비 캐릭터 모델보다 낮은 ppl score를 보인다. human evaluation에서는 제안한 모델은 character-belivebality 에서 성능이 더 좋다. 즉, 캐릭터 임베딩은 캐릭터 일관성을 향상시킬 수 있다.
Character embeddings enhances the explainability of stories.
설명 가능성은 캐릭터 일관성과 상관관계가 있을 수 밖에 없다. 일관된 캐릭터는 이야기를 합리적으로 만들기 때문이다. 표를 보면 제안 모델의 explainability가 높다. 즉, character-guided stories는 더 좋은 설명 가능성을 갖는다!
Characters are clustered along some of there traits in the embedding space.
전술했듯, 캐릭터 임베딩은 스토리 생성에서 행동을 예측하며 학습되기 때문에, 행동 스타일을 포착할 수 잇다. 그래서 훈련 후 캐릭터 임베딩을 찍어보면 앞서 나온 그림을 다시 보면 되는데...
유사한 캐릭터는 유사한 임베딩을 갖는다!. 하지만 이 예시가 전부고, 진짜로 훈련 이후 임베딩에 대한 피겨는 없다😅
The Effect of Action Prediction
두 번째 ablation study~. 이 모델은 2 stage이므로 Action Prediction 모듈을 빼고 진행해서 이 AP 모듈의 성능을 확인해보았다. 성능 표를 보면 전반적으로 이 액션 예측 모듈이 성능에 기여하는 것을 확인할 수 있다.
Action predictor reduces the difficulty of sentence generation.
AP 모듈의 유무에 따라 perplexity가 크게 변하는 것을 확인할 수 있다. 즉, 주어진 캐릭터의 향후 액션을 예측하는 것이 상당히 도움이 되는 유용한 정보이고, 문장 생성을 더 유창하고 정확하게 만든다는 것을 의미한다.
Action predictor explicitly gives character guidance to story generation process.
explanibility을 보면 확인할 수 있다. 이러한 explicit action prediction을 통해서, 이 모델은 이야기 생성을 변화하는 컨텍스트에 대한 캐릭터의 생각과 반응으로 간주하여, 이야기에 합리적인 동기를 부여한다.
Case Study

➡️ (1) 폴리스맨 chan의 냉철 냉혹 리벤지 스토리, (2) 마이클이 힘든 일을 겪다가 결국 이혼하는 이야기.
읽어보면, 좀 급전개에 말이 안되는 부분이 있지만 적어도 캐릭터의 행동에 대한 부분은 자연스럽다. 타이틀과 전반적인 스토리도 잘 매칭이 된다.

이 예시는 bad case이다. 제목은 너무 재밌어보이는데 안타깝다.
읽어보면 내용을 제대로 파악할 수 없을 뿐더러, 이야기를 이끄는 주 캐릭터가 없다. Kota인지 Prabhakaran인지, 혹은 교사인지, 누가 주인공인지 알 수가 없다. 더 심각한 점은, 스토리가 진행될수록 에러가 누적되어서 더 스토리가 이상해진다. 이러한 문제를 해결하기 위해서 저자들은 multi-character action module을 도입할 수 있다고 이야기한다. 이러면 캐릭터간의 상호 액션을 컨트롤 할 수 있게 된다.
마무리하며
지금까지 캐릭터에, 캐릭터에 의한, 캐릭터를 위한, Character-centric model에 대해 살펴보았다.
모델은 크게 action prediction과 sentence generation 단계로 진행되며, 캐릭터 임베딩을 학습하며 컨텍스트와 캐릭터에 기반하여 스토리를 생성하게 된다. 이러한 모델은 이 당시 스토리 생성 SOTA 모델과 비교하여 경쟁력있는 성능을 보여주었다.
다만 코드를 볼 수 없으니 훈련 과정이나 데이터 형태들이 아주 명확하게 이해되지는 않는다 😭 ...
Reference
https://ojs.aaai.org/index.php/AAAI/article/download/5536/5392
https://en.wikipedia.org/wiki/JoJo%27s_Bizarre_Adventure
