[Story Generation] Paper Review : A Corpus and Cloze Evaluation for Deeper Understanding of Commonsense Stories
Generation Study🐱👤

2016년 NAACL에 발표된 "A Corpus and Cloze Evaluation for Deeper Understanding of Commonsense Stories" 를 정리한 글입니다. 현 시점을 기준으로 107회 인용된 논문입니다.
정리
- 논문에서 등장하는 핵심 개념인 Commonsense와, 논문의 contribution인 Story Cloze Test와 ROCStories를 중심으로 읽자!
- 이 논문은 우리가 하고자 하는 Story Generation을 직접적으로 다루지는 않지만, generation의 전제인 Story Understanding을 이야기하고 있기 때문에, 저자들이 이야기하는 네러티브에서 꼭 필요한 Commonsense와, 이를 잘 반영하고 있는 데이터셋은 어떻게 만들었고, 이를 평가할 수 있는 테스트는 어떻게 구성을 했는지에 집중하여 보면 좋을 듯 합니다.
1. Commonsense
- commensense를 표현하고 학습하는 것은 deep-language understading에 있어서 기초적이면서도 중요하고, 또 어려운 문제!
- 논문에서 이야기하는 commensense는, 이벤트(events) 간의 인과관계 및 시간관계(causal and temporal relationships)을 의미한다고 보면 될 듯.
- 이러한 commensense의 이해는 NLP 커뮤니티에서 많은 주목을 받았지만, 적절한 evaluation framework의 부재로 인하여 연구가 많이 진행되지 않았음.
- 이러한 문제점에서 기인하여, 아래에서 소개할 논문의 두 가지 contributions이 등장하게 됨.
2. ROCStories
- 논문에서 제안하는 새로운 데이터셋!
- daily events 사이의 인과적, 시간적인 상식적인 관계(commonsense relations)를 포함
- story generation에도 사용할 수 있는 일상생활의 이야기
3. Story Cloze Test
- 논문에서 제안하는 새로운 평가 방식
- Story Cloze Test : story understanding과 script learning을 평가
- 네 문장의 스토리가 주어지면, 이어서 이야기의 올바른 결말을 선택하는지? 에 대한 평가
- 이를 위해 5 문장으로 구성된 50,000개의 상식적인 이야기 ROCStories 데이터셋을 제안

그러면 논문리딩! 해볼까요
Introduction
Story Understading
- Story를 이해한다는 것은 유구한 역사의, 어려운 태스크라고 할수 있습니다. 여기서 story라고 한다면, narrative를 갖는 텍스트를 의미합니다.
- Story Understading 혹은 generation에서 가장 큰 챌린지는 narrative events의 해석에 대한 commonsense knowledge를 갖는 것입니다.
- 그렇다면, 일상의 이벤트에 대한 commonsense knowledge를 model에 어떻게 부여할까? 하는 궁금증이 생기게 되죠.
- 이러한 Story Understading의 학습 과정에서 가장 중요한 것은, 학습 프로세스를 주도하는 Corpus라고 할 수 있습니다.
- 기존에 이루어졌던 Story Understading은 Script learning에 많은 비중을 두었습니다.
- script : 정형화된 이벤트에 대한 구조화된 knowledge 표현.
- 그러나, 스크립트를 매뉴얼하게 만드는 것은 time-consuming한 문제입니다.
- 따라서 저자들은 가장 먼저, 이벤트 간 시간적이고 인과적 관계, 즉 commensence를 갖는 코퍼스에 집중했습니다. -> commensence는 스토리의 coherence에 있어 중요한 요소이기 때문.
- 저자들은 이러한 코퍼스 구축을 위해 다양한 텍스트를 찾아보다가, 일상 블로그 포스팅이 commonsense causal information을 포함하고 있는 좋은 source라는 것을 발견했습니다.
- 그러나 블로그 포스팅은 noisy 하다는 문제점 有 (= 즉, 유용한 정보를 찾기 힘들다는 것.) 아래는 블로그 포스팅의 예시인데, 약간 의식의 흐름 같기도 합니다. 저자들은 이러한 서술을 noisy하다고 표현함.
“I had an interesting day in the studio today. It was so interesting that I took pictures along the way to describe it to you. Sometimes I like to read an autobiography/ biography to discover how someone got from there to here.....how they started, how they traveled in mind and spirit, what made them who they are now. Well, today, my work was a little like that.”
<복잡한 snippets의 corpus example>
- 그러나 블로그 포스팅은 noisy 하다는 문제점 有 (= 즉, 유용한 정보를 찾기 힘들다는 것.) 아래는 블로그 포스팅의 예시인데, 약간 의식의 흐름 같기도 합니다. 저자들은 이러한 서술을 noisy하다고 표현함.
- 이처럼 복잡하고 noisy한 코퍼스에서 commonsense knowledge를 얻는 것은 challenging language understanding.
-> 따라서, 이러한 내러티브의 단순화된 버전(simplified version)이 필요함.
- 저자들은 commonsense를 포함하고 있는 새로운 코퍼스를 제안
- 이벤트 간 스테레오타입의 인과관계 및 시간 관계를 포함하고 있는 50k high quality five-sentence stories를 수집
- careful prompt design & multiple phases of quality control
- application : (1) commonsense narrative schemas 학습 (2) story generation 모델 학습
- 또 다른 문제도 존재합니다. 바로 이러한 스크립트에 대한 evaluation framework가 부족하다는 것입니다.
- 기존 evaluation framework - Narrative Cloze Test는 일련의 이벤트가 주어지면, held-out 이벤트를 예측하는 시스템입니다.
-
예를 들어, missing event를 포함하고 있는 case를 가정해봅시다.
{X threw, pulled X, told X, ???, X completed} -
기존 연구는 이 특정 테스트에 최적화되어, commonsense를 학습하는 것이 아닌, 얕은 기술(shallow techniques)로 좋은 성능을 레포팅하는 것을 학습한다는 한계가 존재.
-
- 그래서 저자들은 Story Cloze Test를 제안했습니다.
- 이 테스트는, 다음의 이벤트를 예측하는 것이 아니라, 주어진 스토리를 완결하기 위하여 마지막 문장을 선택하는 태스크를 해결하게 됩니다.
- 또, Story Cloze Test를 다루기 위해서 다양한 실험을 진행했습니다.
- 실험 결과는 랜덤 혹은 constant-choose의 성능을 뛰어넘기 위해서는, 스토리의 풍부한 semantic representation과 깊은 수준의 semantic space 모델링이 필요하다는 것을 의미합니다.
A Corpus of Short Commonsense Stories
Goal of New Corpus
저자들이 제시하는 새로운 코퍼스의 목적은 아래와 같습니다.
- The corpus contains a variety of commonsense causal and temporal relations between everyday events. This enables learning narrative structure across a range of events, as opposed to a single domain or genre.
- The corpus is a high quality collection of non-fictional daily short life stories, which can be used for training rich coherent story-telling models
정리하자면,
- 코퍼스는 일상 이벤트 간의 인과와 시간적 관계의 commonsense를 포함해야 한다.
-> 하나의 도메인이나 장르에 국한되지 않고, 다양한 구조를 갖는 이벤트의 내러티브를 학습할 수 있음. - 코퍼스는 일상의 high quality 스토리를 포함한다.
-> 풍부하고 일관된 스토리텔링 모델을 훈련할 때 사용될 수 있음.
-
Definition of narrative or story : anything which is told in the form of a causally (logically) linked set of events involving some shared characters.
= 어떤 공통된 인물이 포함된, 인과적으로(혹은 논리적으로) 연결된 일련의 이벤트 형태로 이야기되는 모든 것. -
저자들은 드라마틱한 사건에 초점을 맞추는 것이 아니라, 일상에서 일어나는 인과적으로 의미가 있는 사건들에 주목하게 됩니다.
Data Collection Methodology
- 데이터셋 구축을 위해서 AMT(Amazon Mechanical Turk)를 통해 크라우드 소싱을 진행했습니다.
- 크라우드 소서들에게 총 5개의 novel five-sentence stories를 작성하도록 함.
- 다양성 및 규모 확보
- 이 때, 주제를 명시하는 것보다 크라우드 소서들이 생각하는 주제를 아무거나 택하여 스토리를 작성하도록 했을 때 더 좋은 결과를 얻음.
데이터셋의 instruction과 constraints에 대해서 이야기를 해보자면,
-
데이터셋의 key property는 다음과 같습니다. : the story should read like a coherent story, with a specific beginning and ending, where something happens in between.
-
또한, 스토리 생성 이후에 3명의 감독관들이 manual check를 통해, 일정 수준 이상의 (1) 일관성을 갖지 않거나, (2) 허구성을 띄거나, (3) 공격적인 스토리의 개수를 카운팅하게 됩니다.
- 이러한 기준에 의거하여, 3명의 감독관이 모두 동의한 경우만 스토리를 채택하게 됩니다.
구체적으로, 저자들이 crowd worker에게 제시한 instruction과 constraints는 아래와 같습니다.

- 추가로, 한 문장은 70자 이내로 제한
- 이야기의 제목도 따로 작성하도록 함
- 또, 인용문, 속어, 비속어 사용 금지 !
위의 instruction을 잘 준수한 문장은 아래와 같이 narrative chain을 형성하게 됩니다.
예시 문장) Bill thought he was a great basketball player. He challenged Sam to a friendly game. Sam agreed. Sam started to practice really hard. Eventually Sam beat Bill by 40 points.
narrative chain) X challenge Y ➯ Y agree play ➯ Y practice ➯ Y beat X
-
품질 검증을 위해서는 AMT의 qualification test를 이용했습니다.
-
데이터셋은 여기서 확인해볼 수 있습니다!
Statistics of New Corpus
다음은 수집한 데이터셋에 대한 통계 분석 파트입니다.
1. Number of Tokens
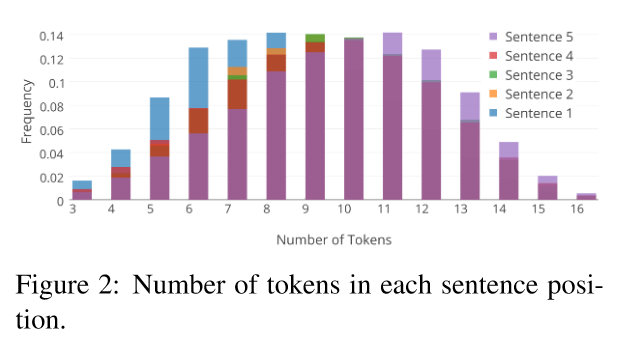
- 첫 문장은 캐릭터나 첫 설정을 소개하기 때문에 아무래도 짧은 경향이 있습니다.
- 마지막 문장일수록, 토큰의 길이가 커지는 경향성도 있습니다.
- 근데 이 보라색은 뭘까?
2. Crowdsourcing Effort

- crowdsourcing woker에 대한 통계 자료 입니다.
3. Distribution of the most frequent 50 events
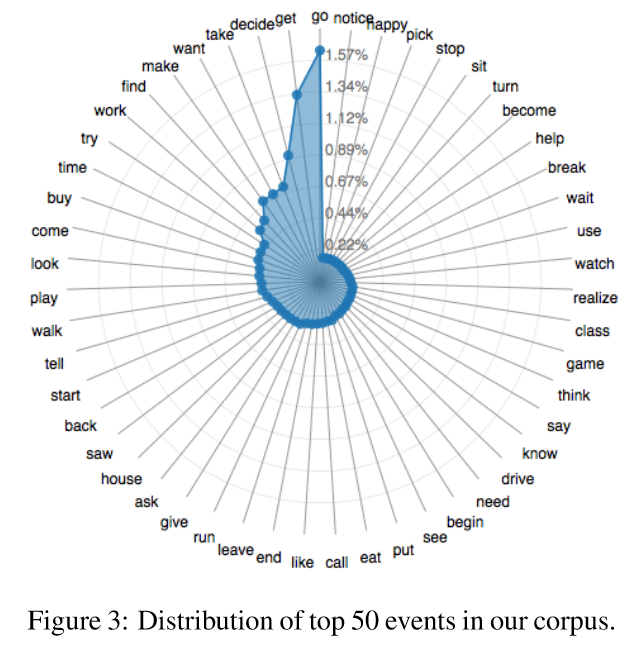
- event는 WordNet 에서 정의한 것을 가져와서 사용함.
- 가장 많이 발생하는 이벤트인 go 와 get은 모두 전체 이벤트에서 1% 정도를 차지함 -> 따라서, 제안하는 데이터셋에서 발생하는 이벤트의 다양성을 확인할 수 있습니다.
4. n-gram of story titles
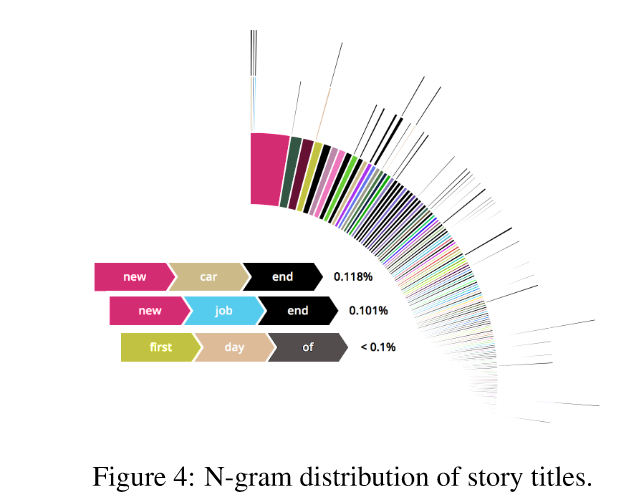
- radial path는 n-gram sequence를 의미.
- 토큰 개수의 평균은 9.8, 중간값은 10이며, n을 5로 설정했습니다.
- 데이터셋이 다양한 주제를 포함하고 있음을 확인할 수 있습니다.
- 풀 버전을 공개한다고 했는데, 알려준 사이트에 들어가보니 볼 수 없었다 ..
Temporal Analysis
- 저자들은 시간 분석을 강조하고 있습니다. 이벤트를 시간순으로 정렬한다는 것은, 즉 스토리에 대한 완벽한 서술적 이해의 전제이기 때문입니다.
- 저자들은 총 두 가지의 관점에서 이벤트의 시간순 정렬의 특성에 대하여 분석을 진행했습니다.
1. Shuffling Experiment
- Do the sentences follow the real-world temporal order of events? 라는 질문에서 시작하게 됩니다.
- 하나의 스토리에서 5개의 문장의 순서를 랜덤으로 섞고, 크라우드 소싱 참가자들에게 이를 시간순으로 배열하도록 했습니다.
- 데이터셋은 좋은 스토리를 포함하는 Good-Stories_50 과, 랜덤으로 선택된 Random-Stories_50, 두 가지 타입으로 구성됨.
-
결과는 아래와 같습니다. 1행의 경우, 5명의 crowdsourcing woker의 과반수 합의를 최종 결과로 본 경우. 2행은 크라우드 워커 각각의 결정을 최종 결과로 본 경우 (5*50 = 200).

-
Good-Stories_50 의 경우, 높은 정확도로 시간순 정렬이 되는 것을 확인할 수 있음.
-
전체 스토리 데이터셋에는, 사람들이 순서를 추론하는 데 도움이 되는 'first', 'then'과 같은 부사들이 거의 없었기 때문에 저자들은 성공적인 정렬 원인을 추가로 분석해봤습니다.
- 상식적인 (commonsensical) 이벤트 사이의 시간 및 인과관계 (즉, 내러티브 스키마)
- 자연스러운 이야기 전개 방식. (예를 들면, 소개에서 시작하여 이야기를 종결하는 방식)
- 특히 이 이야기 전개 방식은, 첫 문장과 마지막 문장은 비교적 잘 정렬되는 것을 확인할 수 있는 표 4행의 결과로 뒷받침됨.
2. TimeML Annotation
- 왜 했나요? TimeML 기반 분석은, 코퍼스에 포함된 이벤트의 시간적 측면에 대한 통찰력을 제공해주기 때문입니다.
- TimeML은 뭔가요 ? 이벤트 및 시간 표현에 대한 마크업 언어.
- 저자들은 20개의 스토리 샘플을 추출하고, 단순화된 TimeML 기반 전문가 어노테이션 진행했습니다.
- 그 결과, 주석이 달린 모든 시간적 링크(TLINK)중 62%는 'before'이었고, 10%는 'simultaneous' 였음.
- 또한, 텍스트 순서가 실제 이벤트 순서를 반영하는지 확인하기 위해 문장 순서와 TimeML 순서를 비교해봄. 그 결과, 55%만 일치하였음.
- 즉, 이야기의 시간 및 인과관계에 대한 포괄적인 연구는, 이벤트 사이의 복잡한 commonsense를 잘 파악해야 한다는 것이겠죠..
A New Evaluation Framework
그래서, 저자들은 이 모델이 스토리의 commonsense를 잘 파악했는지를 판단할 수 있는 새로운 프레임워크를 제안하게 됩니다.
Background
- Cloze Test는 문장에서 임의의 단어를 제거하고 시스템이 공백을 채우도록 시도함으로써 언어 능력에 대한 시스템(또는 인간)을 평가하는 데 사용되는, 오래된 역사의 테스트입니다.
- 기존에도, Narrative Cloze Test라는 스크립트를 평가하기 위한 프레임워크가 존재했음
- 앞서 이야기했지만, 어떤 이벤트 시퀀스가 주어졌을 때 누락된 이벤트에 대한 랭크를 생성하는 시스템
- Goal : Narrative knowledge 평가
- 그러나, narrative knowledge learning이 잘 설명되지 않는다는 문제 발생
- 예를 들면, 단순한 빈도 기반의 예측이 가장 높은 성능을 보임.
- 따라서, 스토리의 이해를 평가할 수 있는 더 좋은 방법이 필요함!
Story Cloze Test
- 저자들이 제안하는 새로운 test입니다.
- 4개의 문장으로 구성된 context가 제공되고, 그 다음 두 개의 엔딩이 제시됨 -앞선 context를 entailing하는 right ending와, contradicting하는 wrong ending.
- 따라서 앞선 네 문장의 context를 보고, 이어서 등장하게 될 right ending를 선택하는 task. 예시는 아래와 같습니다.
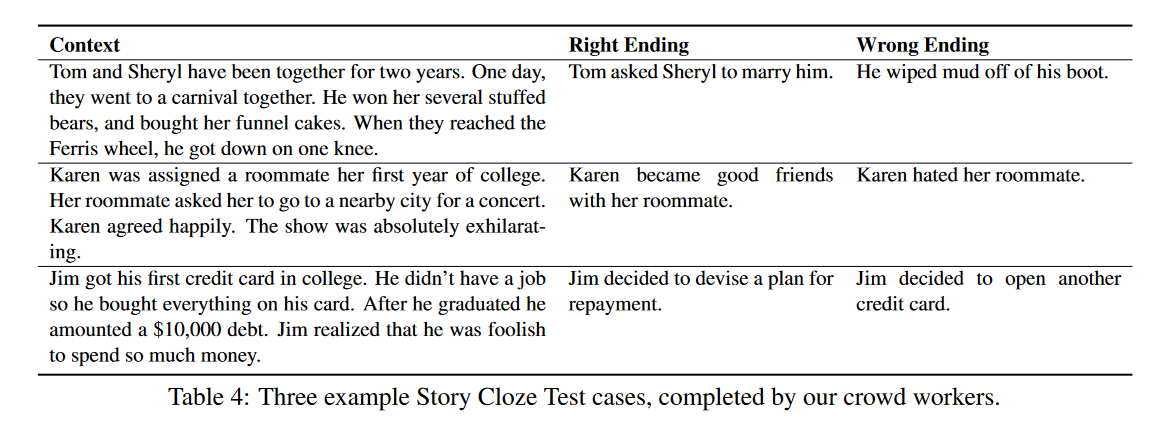
- 저자들은 이러한 test가 story understanding이 정말 잘 이루어졌는지 평가하는 프레임워크라고 이야기하며, 우리가 관심있는 story generation 등에도 응용할 수 있다고 이야기함.
- 예를 들면, 스토리 생성 모델이 생성한 두 개의 엔딩에 대한 log-likelihoods 계산을 통해 좋은 스토리를 생성할 수 있음.
Data Collection Methodology
- 위 테스트를 위해서는, 태스크에 적합한 데이터셋을 만들어 주는 작업이 선행되어야 합니다.
- 저자들은 앞서 구축한 ROCStories Corpus에서 랜덤으로 13,500개의 샘플을 추출하게 됩니다.
- 그 다음, AMT worker에게 앞선 4개의 문장만을 제시하고, 각각의 스토리마다 right ending과 wrong ending을 작성하도록 했습니다.
Quality Control
-
저자들은 생성한 데이터셋에 대한 2-step Quality Control을 진행
1. Qualification Test:
worker들은 ending writing 과정에서 두 개의 조건을 만족해야 했는데, (1) 엔딩에는 적어도 앞서 등장한 인물 한 명 이상을 공유해야 함. (2) 엔딩 문장은 그 문장 자체만으로도 현실적이여야 하고, 합리적이야 함. 모든 worker들은 이 두 가지 조건을 만족했는지 여부를 선택하도록 하는 qualification test를 진행했음.
2. Human Verification
2-1. 13,500샘플에 대한 2개의 엔딩을 만들었으므로, 13,500*2 = 27,000개의 full-five stories를 생성.
2-2. 하나의 문장마다, 3명의 crowd workers에게 다섯 개의 문장으로 구성된 스토리가 의미있고 일관됐는지에 대한 척도를 {-1,0,1}로 측정하도록 함.
2-3. 3명의 workers들이 만장일치로 1과 0의 레이팅을 준 케이스만 선정함.
-
최종적으로 3,742개의 테스트 케이스가 생성됨. 최종 테스트 케이스에 대한 통계는 아래에 있습니다.

Story Cloze Test Model
저자들이 제안한 Story Cloze Test는 네러티브에 대한 이해 없이, shallow한 접근 방식으로는 좋은 성능을 낼 수 없다고 합니다.
이를 뒷받침하기 위해, 섹션 5는 이러한 shallow 접근법에 대한 다양한 실험을 진행해보고, 결론적으로 결과가 좋지 않음을 이야기하는 내용입니다. 실험을 조금 많이 진행했습니다 ..
1. Frequency
- context를 고려하지 않은 baseline.
- 예를 들어 이러한 두 문장이 있다고 가정해보자.
He was mad after he won.
He was cheerful after he won. - 앞의 문장은 실제로 발생할 가능성이 적은 문장임.
- Frequency baseline은 문장에서 semantic roles과 함께 메인 이벤트인 동사의 구글의 검색 엔진 조회수가 더 높은 케이스를 선택하게 됩니다.
- semantic roles은 ‘I*poison(독을 주입?)*flowers’ vs ‘I*nourish(키우다)*flowers’ 이런 것을 의미한다고 합니다.
- TRIPS semantic parser 사용.
2. N-gram Overlap
- 간단하게, context와 더 많은 n-gram을 공유하는 엔딩을 선택.
- 여기서는 4-gram overlap을 계산하는 Smoothed-BLEU Score를 사용.
3. GenSim: Average Word2Vec
- Context의 word2vec 임베딩과 각 엔딩의 임베딩을 계산하여, 임베딩이 더 가까운 문장을 선택.
- 이 베이스라인은 semantic similarity을 고려하기 때문에, 위의 n-gram overlap보다 조금 더 좋은 베이스라인임.
4. Sentiment-Full
- Context의 average sentiment와 일치하는 엔딩을 선택하였음.
- 이 당시 SOTA였던 Manning의 모델을 사용함. (감정을 1~5의 digit으로 표현)
5. Sentiment-Last
- 위와 동일하게 sentiment digit을 사용했지만, context 전체가 아니라 Last context의 average sentiment와 일치하는 엔딩을 선택하였음.
6. Skip-thoughts Model
- 3번과 비슷한데, 임베딩 방식이 달라짐. 임베딩으로는 Skip-thougts' Sentence2Vec 임베딩(Kiros et al.,2015)을 사용했음.
- Skip-thougts' Sentence2Vec : 11,000권 이상의 book corpus로 학슴됨.
7. Narrative Chains-AP
- Chambers and Jurafsky(2008)의 사전 연구를 기반으로 하는, 일련의 내러티브 이벤트 학습에 대한 표준 접근 방식.
- 이 모델에서 이벤트는 a verb and a typed dependency로 표현됨. coreferring entity를 기준으로 최소 2번이상 발생하는 이벤트 페어에 대한 PMI 계산. PMI 점수를 기준으로 높은 엔딩을 결과로 선택하게 됨.
- 이벤트 페어는 Associate Press (AP) portion of the English Gigaword Corpus를 기준으로 학습됨.
Pointwise mutual information (PMI) : a real-number score produced by a pointwise mutual information measure (that ranks the statistical dependence between two random variables). 값이 0이면 상호 영향을 미치지 않는, 독립 관계
8. Narrative Chains-Stories
- 위와 동일하지만, ROCStories에서 학습됨.
9. Deep Structured Semantic Model
- Huang et al., (2013)의 연구에서 제안된 모델을 사용.
- 두 개의 임베딩을 사용 : 1) context로만 구성 2) context와 다섯 번째 문장으로 구성.
- 따라서, 각각의 임베딩을 학습하기 위한 두 개의 개별 뉴럴 네트워크를 구성.
- 각각 두개의 레이어로 구성, 히든 레이어의 차원은 1000, 임베딩 벡터 차원은 300.
- 코사인 유사도를 기준으로, 가장 가까운 엔딩을 선택!
이 외에도 추가적으로 그냥 랜덤으로 선택하는 경우와, 사람이 평가한 결과를 추가하여 총 11번의 실험을 진행했다.
결과!

-
NN을 사용한 DSMM의 Test 성능이 가장 좋다. 그러나 랜덤으로 선택한 경우보다 겨우 7.2%만 높은 것을 확인할 수 있음.
-
이러한 결과는, 이벤트 기반의 언어 모델들은 이러한 태스크에 충분하지 않음을 의미.
-
예를 들면, 종종 스토리의 마지막 엔딩은 ‘Bill was highly unprepared’ or ‘He had to go to a homeless shelter’ 등이 있을 수 있음.
- 그런데 이런 경우, 이벤트 기반 언어 모델은, 'was-object'나, 'go-to'와 같은 동사나 구문 관계만 봄.
- 즉, going to a homeless shelter와, same as going to the beach는 같은 경우로 판단됨.
-
결론적으로, 이는 내러티브에서는 이벤트에 대한 더 풍부한 의미론적 표현의 해석이 필요함을 시사함. 따라서 저자들은 많은 연구자들이 이 테스트에 참여해보는 것을 권장하며 이 섹션을 마무리하고 있다..
그렇다면 실제로 Story Cloze Test는 진행되고 있나요?
네! 진행되고 있습니다!
최근까지도 활발하게 많은 연구 팀들이 evaluation에 참가하고 있고, 결과는 여기 리더보드에서 확인해볼 수 있다.
The End is Never임을 알 수 있다 ...
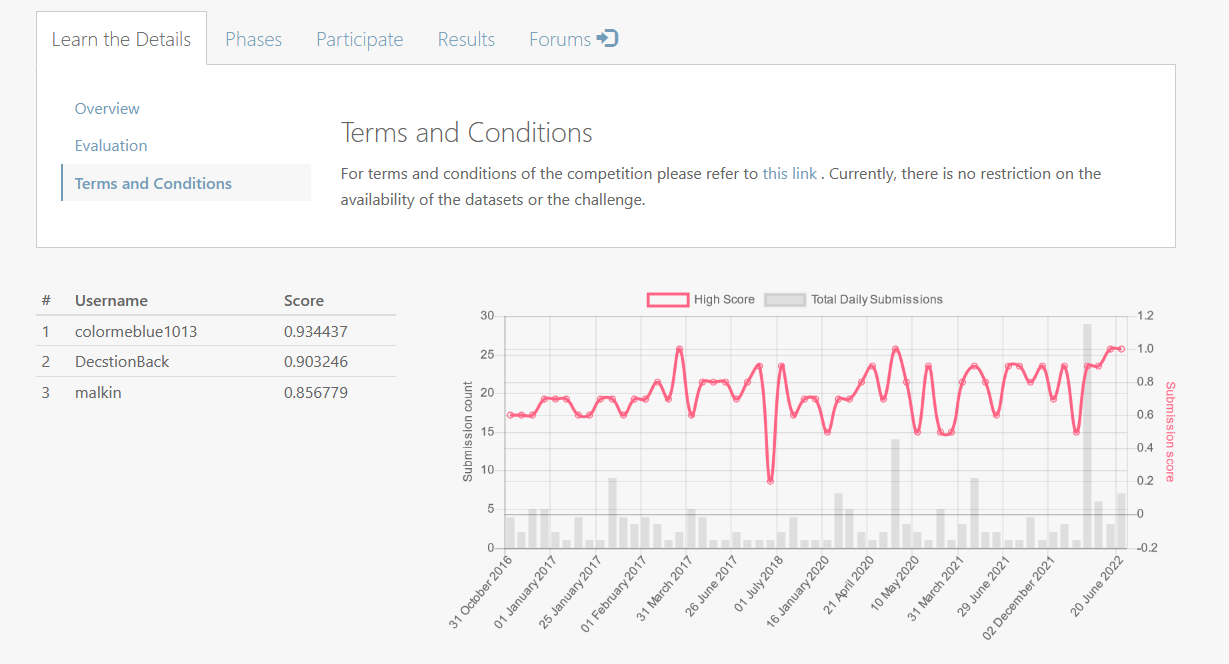
실제로 테스트에 참가하고 있는 팀들의 결과도 확인할 수 있으며, 회색 바를 통해 지금까지도 꾸준히 submissions이 이루어지고 있는 것을 확인할 수 있다.
심지어! 2022년 6월에는 타이기록이 달성되었음을 확인할 수도 있다. 우리도 로그인 후 competition에 참여할 수도 있지만, 자세히 보지는 않았다. 관심 있는 분들은 자세하게 살펴보시길..
후기
- 돈이 꽤나 많이 들었겠다 .
- 2016년 논문인데, Competition이나 test set도 비교적 유지관리가 잘 되고 있는 듯 하다.
- ROC 어쩌고 데이터셋 만들 때 일상의 데이터셋이 목적이라고 했는데.. 실제 데이터셋 만들 때 그런 제약조건이 있었나? 누가 막 중세시대 이야기 하고 이런거는 필터링됐을까 ..??..
- 2저자가 미국 해군사관학교 소속이다. 어라 탑..건..?
Reference
Paper : https://arxiv.org/pdf/1604.01696.pdf
https://competitions.codalab.org/competitions/15333
