[Story Generation] AESOP: Abstract Encoding of Stories, Objects, and Pictures (ICCV, 2021)
Ravi, H., Kafle, K., Cohen, S., Brandt, J., & Kapadia, M. (2021). AESOP: Abstract Encoding of Stories, Objects, and Pictures. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 2052-2063).

"Examples are the best precept" - Aesop, The Two Crabs
CONTRIBUTION
- 새로운 visual storytelling 데이터셋 AESOP을 제안. (➕ 코드 및 데이터셋 모두 공개)
- 새로운 story comprehension 태스크 제안, a novel generalized story comprehension framework
다른 논문들과의 차별점 ?

이 논문의 차별점이자, 강점은 어떤 것이 있는지 먼저 살펴보고 넘어가려고 한다.
- 이 논문이 제안하고 있는 데이터셋은, 앞서 살펴본 두 논문과 달리 이미지 도메인이 클립아트이다. 위의 예시에서 확인해볼 수 있는데, 우리가 익히 보던 사진 Image Sequence가 아닌, 애니메이션과 같은 클립아트로 구성이 되어있다.
- 또한 앞서 살펴본 연구들은 이미지 인코더 -> 텍스트 디코더를 거쳐서 다음에 올 텍스트를 생성하는 태스크를 수행했지만, 이 논문은 텍스트와 이미지 모두 생성하는 태스크를 해결한다. 이는 이미지가 아닌 클립아트를 사용했기 때문에 이미지 생성이 수월하게 가능했던 것으로 보인다.
AESOP DATASET
principles
- Creativity Over Perception ➡️ 데이터셋을 생성할 때, visual과 textual part 모두 생성하도록 함.
- Causal and Coherent Narratives ➡️ 장르와 타이틀을 제약조건으로 사용
- Constrained World Knowledge ➡️ real-world image가 아닌 clip-art image (단순화) 사용
data acquisition setup
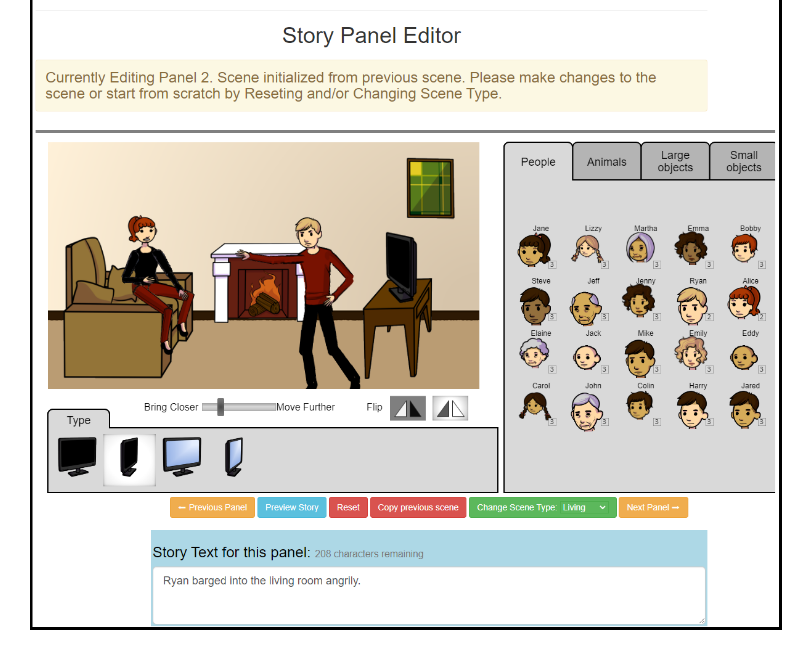
- 하나의 스토리는 대응하는 visual panel, text panel 쌍 3개로 이루어진다.
- VQA dataset 기반, drag and drop interface 사용. 바로 위에 예시가 있다.
- 그러나 VQA와 달리 오브젝트 수를 확장했으며 + 배경 종류를 추가했다. (부엌, 해변)
- 다양한 연령, 성별, 인종의 팔다리 변형 가능한 20명의 인간 캐릭터 + 움직이는 동물 9마리 + 고정포즈 동물 30마리
- 48개의 large object + 60개의 small object
- 인물은 고정된 이름 있음

- free title and theme (미리 정의된 후보군 중 선택)
- 7,062 stories ➡️ 21,186 abstract visual scenes, and text
최종적으로 구축한 데이터셋의 예시는 아래와 같다.


기존 이미지 기반 데이터셋들은 기본적으로 존재하는 이미지에 텍스트를 덧입히는 것이기 때문에, "쿵푸마스터보이가 불량배들에게 일격을 가하는 상황"에 대한 이미지가 없다면 그러한 스토리를 생성할 수 없다.
그런데 이렇게 추상적인 클립아트로는 원하는 상황을 직접 생성할 수 있다. 이러한 점에 있어서 저자들은 creativity dataset이라고 강조한다.
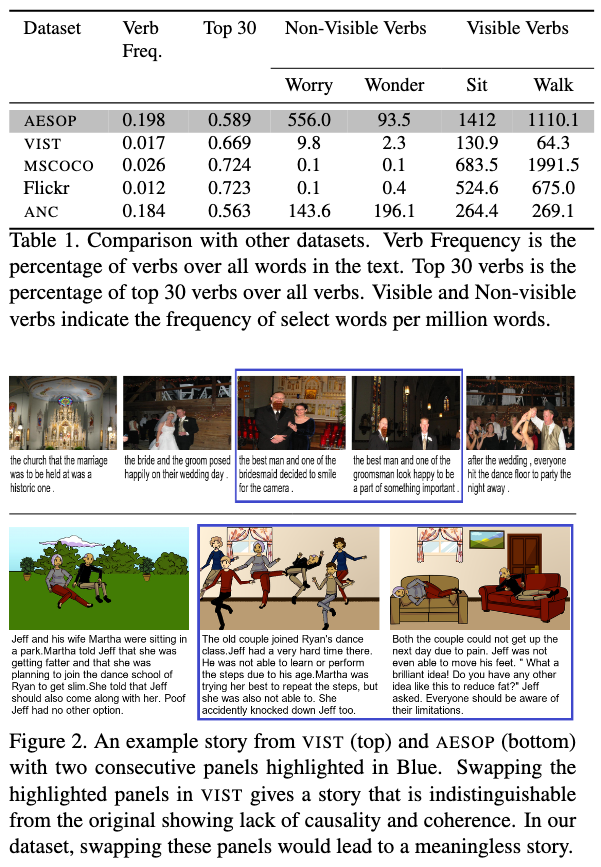
AESOP Vs. Others
저자들은 본인들이 제안하는 데이터셋이, 기존 데이터셋에 비하여 diversity & coherence and causality 측면에서 더 좋다고 주장한다.
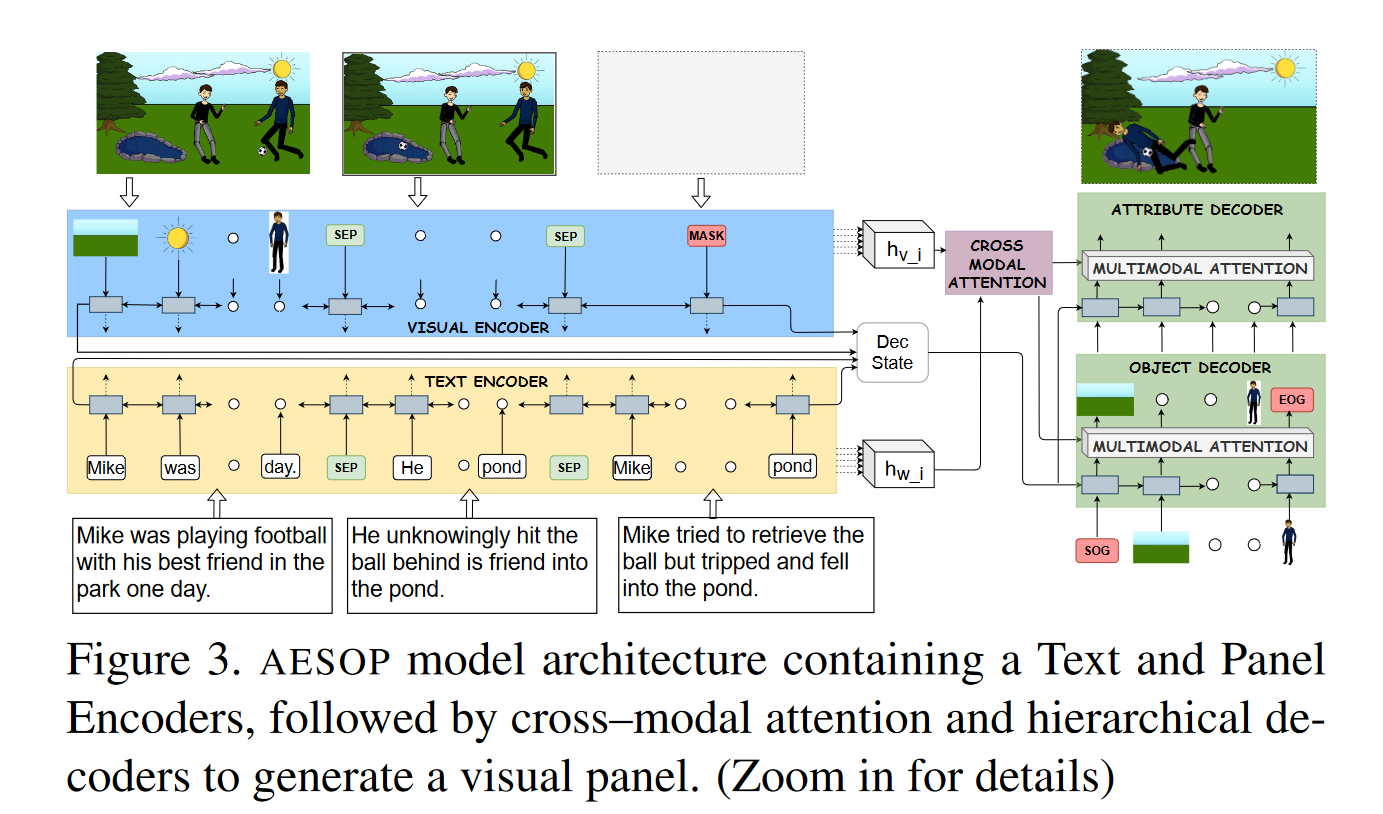
AESOP Model
이 모델이 이야기의 narrative를 잘 이해했는지를 어떻게 평가할까? 저자들은 이를 시작된 이야기를 계속하고, 끝낼 수 있는 능력으로 평가했다.
위의 능력을 갖춘 모델을 만들기 위해 저자들은 두 가지 타입의 Assistant를 제안했다.
- Assistant Illustrator : generating the missing visual panel.
- Assistant Writer : : generating the missing text panel.
이어서 각각의 Assistant를 구성하기 위한 Abstract Visual Representation, Encoder, Decoder를 자세하게 살펴보려고 한다.
1. Abstract Visual Representation
전술했듯, 이 연구는 기존 연구와 달리 클립아트 이미지를 사용했다. 따라서 이러한 점을 고려하여 저자들은 새로운 Representation을 제안하게 된다.
구체적인 아이디어는, 이미지를 인코딩 할 때 기존의 방법들처럼 이미지를 픽셀 단위로 인식하는 것이 아니라, 오브젝트 단위로 인식하게 된다. 구체적인 과정은 아래와 같다.
-
각 visual token을 인코딩하는 과정에서 object state는 {what the object is, where it is placed, how it is placed}에 대한 정보를 담게 된다.
-
Visual panel은 다음과 같이 표현되며 , 패널을 구성하는 각 Object Representation은 : 로 표현된다.
-
구체적으로 오브젝트의 종류, 위치, 포즈 등의 정보는 아래와 같이 인코딩된다.
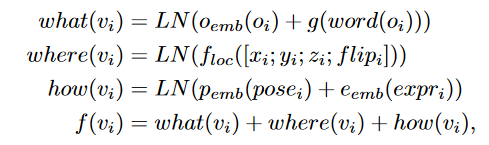
: object identifier
, : location of the center of the object in the panel
: size of the object
: whether the object is facing left or right
: pose
: one of the nine possible expressions for human clip-arts
2. Story Encoder
- : the sequence of visual panels
- : the sequence of text panels
위에서 정의한 각각의 패널, 그리고 패널간의 관계를 인코딩 하기 위해 총 세 개의 인코더를 사용한다.
- 즉, story encoder : (1) visual, (2) text, and (3) cross-modal encoder.
- visual and text encoder : Bidirectional GRUs.
- cross-modal encoder : encoded representation(text, visual) 간의 cross modal attention 수행
3. Panel Decoder
1. visual panel
- masked visual panel 을 생성하는 문제 ➡️ 다음 시퀀스 를 예측하는 문제
- 두 개의 GRU(for tracking seqeunce of object and state of the visual panel)를 사용했다.
- 각 GRU의 hidden state는 visual and text encoders의 final hidden states로 초기화
- 두 개의 GRU(for tracking seqeunce of object and state of the visual panel)를 사용했다.
-
각 타임스텝 t에서, object decoder는 {지금까지 예측된 object의 상태와, object에 대한 attention과, input의 word representations}을 결합하여, current object를 예측
-
그 후, object decoder가 예측한 object와 current state를 사용해서, current object의 attribute를 예측
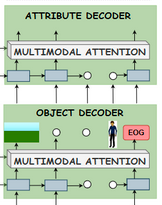
- Output : 33-dim vector(20 pose + 9 expression + , , , )
2. text panel
- 위의 첫 번째 단계에서 사용했던 object decoder와 동일한 구조의 디코더를 사용했다. vocabulary size 만 수정해서 사용했음.
- regular Maximum Likelihood objective를 사용하여 학습됨.
- inference는 nucleus sampling(Top-p)을 사용.
Baseline
저자들이 하고자 하는 태스크와 직접적으로 비교할 만한 기존 연구가 없었기 때문에, 아래의 방법이나 모델의 ablated version과 비교를 진행했다.
| baseline | 전략 | description |
|---|---|---|
| Repeat | 단순하게 반복하자! | Visual panel 생성에만 사용. 보통 visual panel sequence를 보게 되면, 배경이나 등장 인물 같은 major part는 거의 바뀌지 않는 반면, 인물의 표정이나 포즈 같은 아주 minor part만 변하게 된다. 이러한 점에서, 저자들은 그냥 전 단계의 패널을 그대로 가져오는 방법을 베이스라인으로 사용했다! 텍스트의 경우는 이미지와 다르게 크게 변하기 때문에, text panel에는 사용하지 않았다. |
| Unimodal | 우리가 일반적으로 생성하는 story generation model | Visual unimodal model. cross modal encoder와, text attention decoder 사용. (GPT-2 기반) |
| One-to-One | 하나의 modality만 보자! | story context없이, visual panel-> visualen panel, text panel -> text panel 생성. |
| Pixel Model | Abstract visual Representation 하지 말자! | visual representation을 Resnet-18 w/ visual attention module. |
| Human Baseline | 사람이 하자! |
Evaluation & Result
1. Automatic metric
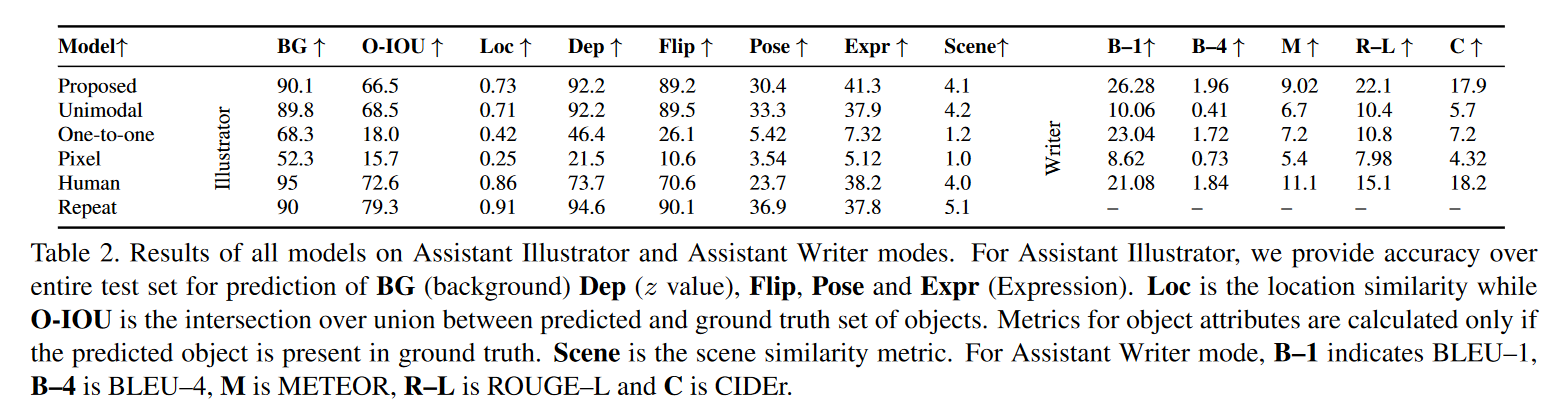
1. Assistant Illustration
- Repeat이 모든 모델, 심지어 사람보다도 더 좋은 성능을 보임.
- 이유를 분석해보니, 스토리의 80%는 배경이 바뀌지 않았다. 또한 오브젝트 포지션과 attribute도 바뀌지 않았기 때문.
2. Assistant Writer
- 👍 BLEU와 ROUGE-L에서 좋은 성능
- 누락된 캐릭터 없이 다 반영이 되었기 때문.
- 👎 반면, METEOR과 CIDEr에서 그닥인 성능...
- 그만큼 시각적 정보와 관련이 있으면서도, 일관된 내러티브 생성이 어렵다!
2. Human Evaluation
- Coherent : 생성된 콘텐츠가 이전의 콘텐츠와 일관성이 있는지?
- Relevant : 생성된 콘텐츠가 이전 콘텐츠와 관련이 있는지?
- Meaningful : 생성된 콘텐츠가 합리적인지?
1. Assistant Illustration
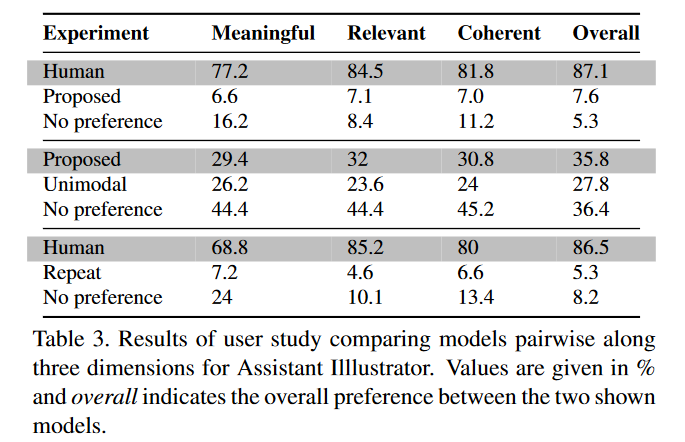
- 위의 auto-metric에서 좋은 성능을 보인 repeat보다, human-evaluation이 훨씬 좋은 스코어를 기록.
- 전반적으로, 인간 보다는 제안 모델의 성능이 좋지 않음을 알 수 있다.
- 🤔 그런데, 왜 proposed-repeat은 하지 않았을까? ... 사실 unimodal보다 성능이 좋았던 것은 repeat인데...
2. Assistant Writer
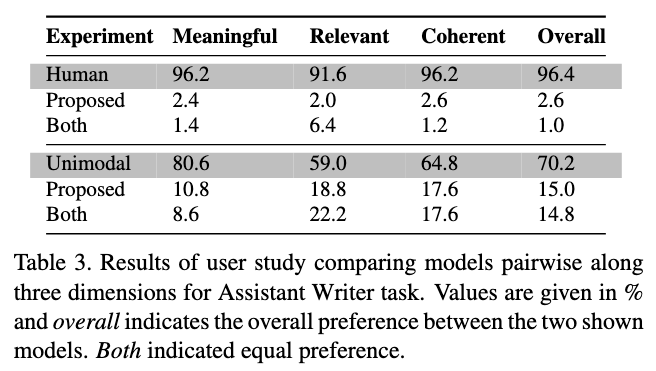
- Assistant Writer 모드에 대해서도 유저스터디를 진행했는데, 결과는 좋지 않았기 때문인지, 본문에는 없고 supplymentary에서만 확인할 수 있다.
- 결과적으로는, 인간과 GPT가 모두 제안 모델보다 훨씬! 성능이 좋았다.
- 상대적으로 작은 데이터 세트에서 처음부터 모델로 언어 모델링을 학습하는 것이 어렵기 때문이며, 또 제안 모델의 경우 문법적으로 잘못된 텍스트를 생성하여서 선호도가 떨어졌다고 이유를 분석했다.
Discussion & Remark
- Model Limitations and Future Work
- Inadequancies of Automatic Metric
- Complexity of AESOP
- Further possibilities w/ AESOP
