KoBERT
Paper
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
- Pre-training
- Unlabeled Data
- Bidirectional
- MLM(Masked Language Modeling)
- NSP(Next Sentence Prediction)
효과적인 분야
- QA (Question Answering)
- Language Inference

Pre-training & Fine-tuning
- MLM
- BERT에서는 input sequence에 15%를 [Mask]를 씌우는 특징이 있음
- NSP
- Next Sentence Prediction, 두 개의 문장이 입력으로 들어오면 뒤 쪽에 오는 문장이 실제로 이어지는 문장인지 예측하는 과정
- Special Token
- BERT에서는 tokenization을 할 때 2개의 special token이 들어감
- CLS 토큰 = classification token
- SEP 토큰 = seperate 토큰
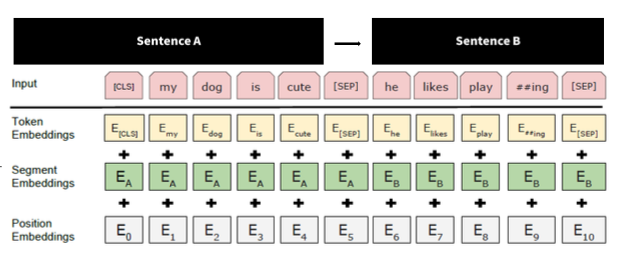
- Embedding Layer
- Transformer에서 Position Embedding만 사용하던 방식에서 몇 가지가 더 추가된 모습
Code 구현
1. Setting
# requirements : https://github.com/SKTBrain/KoBERT/blob/master/kobert_hf/requirements.txt !pip install -q gluonnlp pandas tqdm !pip install -q mxnet !pip install -q sentencepiece !pip install -q transformers !pip install -q torch
- KoBERT & Transformer
!pip install -q 'git+https://github.com/SKTBrain/KoBERT.git#egg=kobert_tokenizer&subdirectory=kobert_hf'
from kobert_tokenizer import KoBERTTokenizer from transformers import BertModel from transformers import AdamW from transformers.optimization import get_cosine_schedule_with_warmup
import torch from torch import nn import torch.nn.functional as F import torch.optim as optim from torch.utils.data import Dataset, DataLoader import gluonnlp as nlp import numpy as np from tqdm import tqdm, tqdm_notebook import pandas as pd
# GPU 설정 device = torch.device("cuda:0")
# BERT 모델, Vocabulary 불러오기 tokenizer = KoBERTTokenizer.from_pretrained('skt/kobert-base-v1') bertmodel = BertModel.from_pretrained('skt/kobert-base-v1', return_dict=False) vocab = nlp.vocab.BERTVocab.from_sentencepiece(tokenizer.vocab_file, padding_token='[PAD]')
2. Data
AI Hub 감정 분류를 위한 대화 음성 데이터셋
data = pd.read_csv("/content/5차년도_2차.csv", encoding='cp949')
3. Preprocessing
data.sample(n=5)
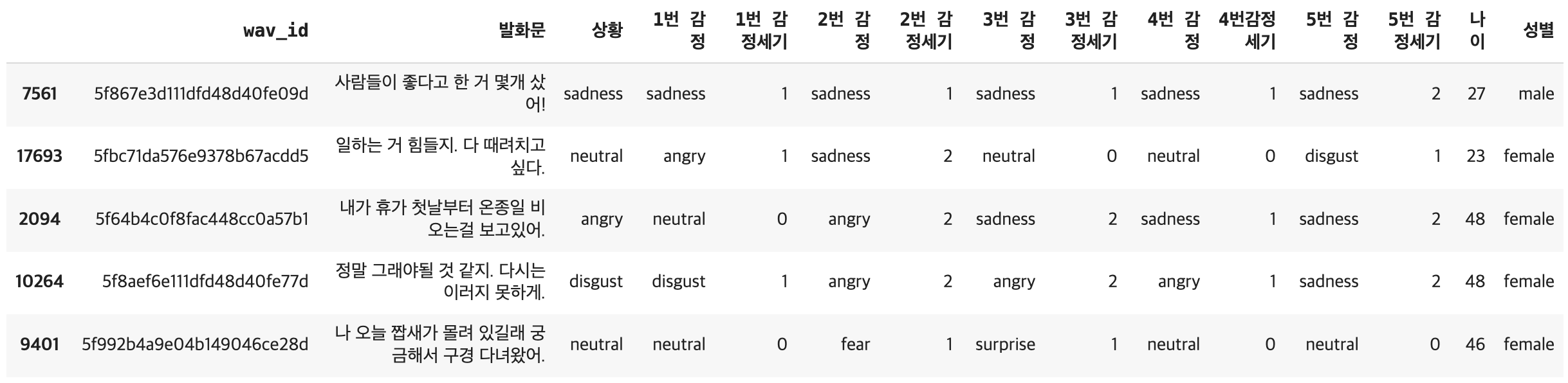
- (19374, 15)
- 'happiness', 'neutral', 'sadness', 'angry', 'surprise', 'disgust', 'fear' 7가지의 감정 존재
data.loc[(data['상황'] == "fear"), '상황'] = 0 # fear → 0 data.loc[(data['상황'] == "surprise"), '상황'] = 1 # surprise → 1 data.loc[(data['상황'] == "angry"), '상황'] = 2 # angry → 2 data.loc[(data['상황'] == "sadness"), '상황'] = 3 # sadness → 3 data.loc[(data['상황'] == "neutral"), '상황'] = 4 # neutral → 4 data.loc[(data['상황'] == "happiness"), '상황'] = 5 # happiness → 5 data.loc[(data['상황'] == "disgust"), '상황'] = 6 # disgust → 6
- 7개의 감정 class → 숫자로 바꿔줌
data_list = [] for ques, label in zip (data['발화문'], data['상황']): data = [] data.append(ques) data.append(str(label)) data_list.append(data)
- column ['발화문', '상황'] data_list 생성
3-1. Split train and test data
from sklearn.model_selection import train_test_split dataset_train, dataset_test = train_test_split(data_list, test_size = 0.2, shuffle = True, random_state = 32)
- train data: 15,499
- test data: 3,875
3-2. 데이터셋 토큰화
tok = nlp.data.BERTSPTokenizer(tokenizer, vocab, lower = False)
class BERTDataset(Dataset): def __init__(self, dataset, sent_idx, label_idx, bert_tokenizer, vocab, max_len, pad, pair): transform = nlp.data.BERTSentenceTransform( bert_tokenizer, max_seq_length=max_len,vocab = vocab, pad = pad, pair = pair) self.sentences = [transform([i[sent_idx]]) for i in dataset] self.labels = [np.int32(i[label_idx]) for i in dataset] def __getitem__(self, i): return (self.sentences[i] + (self.labels[i], )) def __len__(self): return (len(self.labels))
3-3. Setting parameters
max_len = 64
batch_size = 64
warmup_ratio = 0.1
num_epochs = 5
max_grad_norm = 1
log_interval = 200
learning_rate = 5e-5
3-4. Data tokenization, int encoding, padding
tok = tokenizer.tokenize
data_train = BERTDataset(dataset_train, 0, 1, tok, vocab, max_len, True, False)
data_test = BERTDataset(dataset_test, 0, 1, tok, vocab, max_len, True, False)# torch 형식의 dataset을 만들어 입력 데이터셋의 전처리 마무리
train_dataloader = torch.utils.data.DataLoader(data_train, batch_size = batch_size, num_workers = 5)
test_dataloader = torch.utils.data.DataLoader(data_test, batch_size = batch_size, num_workers = 5)4. KoBERT Model
KoBERT 오픈소스 내 예제코드 참고
https://github.com/SKTBrain/KoBERT/blob/master/scripts/NSMC/naver_review_classifications_pytorch_kobert.ipynb
class BERTClassifier(nn.Module):
def __init__(self,
bert,
hidden_size = 768,
num_classes = 7, # 감정 클래스 수로 조정
dr_rate = None,
params = None):
super(BERTClassifier, self).__init__()
self.bert = bert
self.dr_rate = dr_rate
self.classifier = nn.Linear(hidden_size , num_classes)
if dr_rate:
self.dropout = nn.Dropout(p = dr_rate)
def gen_attention_mask(self, token_ids, valid_length):
attention_mask = torch.zeros_like(token_ids)
for i, v in enumerate(valid_length):
attention_mask[i][:v] = 1
return attention_mask.float()
def forward(self, token_ids, valid_length, segment_ids):
attention_mask = self.gen_attention_mask(token_ids, valid_length)
_, pooler = self.bert(input_ids = token_ids, token_type_ids = segment_ids.long(), attention_mask = attention_mask.float().to(token_ids.device),return_dict = False)
if self.dr_rate:
out = self.dropout(pooler)
return self.classifier(out)model = BERTClassifier(bertmodel, dr_rate = 0.5).to(device)no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr = learning_rate)
loss_fn = nn.CrossEntropyLoss() # 다중분류를 위한 loss function
t_total = len(train_dataloader) * num_epochs
warmup_step = int(t_total * warmup_ratio)
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps = warmup_step, num_training_steps = t_total)def calc_accuracy(X,Y):
max_vals, max_indices = torch.max(X, 1)
train_acc = (max_indices == Y).sum().data.cpu().numpy()/max_indices.size()[0]
return train_acc
train_dataloader- 정확도 측정
5. Train
train_history = []
test_history = []
loss_history = []
for e in range(num_epochs):
train_acc = 0.0
test_acc = 0.0
model.train()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm_notebook(train_dataloader)):
optimizer.zero_grad()
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
# print(label.shape, out.shape)
loss = loss_fn(out, label)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
train_acc += calc_accuracy(out, label)
if batch_id % log_interval == 0:
print("epoch {} batch id {} loss {} train acc {}".format(e+1, batch_id+1, loss.data.cpu().numpy(), train_acc / (batch_id+1)))
train_history.append(train_acc / (batch_id+1))
loss_history.append(loss.data.cpu().numpy())
print("epoch {} train acc {}".format(e+1, train_acc / (batch_id+1)))
# train_history.append(train_acc / (batch_id+1))
# .eval() : nn.Module에서 train time과 eval time에서 수행하는 다른 작업을 수행할 수 있도록 switching 하는 함수
# 즉, model이 Dropout이나 BatNorm2d를 사용하는 경우, train 시에는 사용하지만 evaluation을 할 때에는 사용하지 않도록 설정해주는 함수
model.eval()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm_notebook(test_dataloader)):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length = valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
test_acc += calc_accuracy(out, label)
print("epoch {} test acc {}".format(e+1, test_acc / (batch_id+1)))
test_history.append(test_acc / (batch_id+1))
epoch 5 train acc : 0.9793595679012346
epoch 5 test acc : 0.9215822599531616
6. Test
# predict : 학습 모델을 활용하여 다중 분류된 클래스를 출력해주는 함수
# 코드 출처 : https://hoit1302.tistory.com/159
def predict(predict_sentence): # input = 감정분류하고자 하는 sentence
data = [predict_sentence, '0']
dataset_another = [data]
another_test = BERTDataset(dataset_another, 0, 1, tok, vocab, max_len, True, False) # 토큰화한 문장
test_dataloader = torch.utils.data.DataLoader(another_test, batch_size = batch_size, num_workers = 5) # torch 형식 변환
model.eval()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(test_dataloader):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length = valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
test_eval = []
for i in out: # out = model(token_ids, valid_length, segment_ids)
logits = i
logits = logits.detach().cpu().numpy()
if np.argmax(logits) == 0:
test_eval.append("공포가")
elif np.argmax(logits) == 1:
test_eval.append("놀람이")
elif np.argmax(logits) == 2:
test_eval.append("분노가")
elif np.argmax(logits) == 3:
test_eval.append("슬픔이")
elif np.argmax(logits) == 4:
test_eval.append("중립이")
elif np.argmax(logits) == 5:
test_eval.append("행복이")
elif np.argmax(logits) == 6:
test_eval.append("혐오가")
print(">> 입력하신 내용에서 " + test_eval[0] + " 느껴집니다.")end = 1
while end == 1 :
sentence = input("하고싶은 말을 입력해주세요 : ")
if sentence == "0" :
break
predict(sentence)
print("\n")- 질문에 0 입력 시 종료

7. Conclusion
- KoBERT를 활용해 7개의 감정분류 task를 수행해본 결과 준수한 성능 확인 가능
- 텍스트로만 분석하기엔 한계 존재

