Transformer
Abstract
- 기존: RNN과 CNN을 기반으로 sequence처리 + attention 메커니즘
- 논문 : attention만 이용한 transformer라는 모델을 도입
: RNN,CNN구조에서 탈피
⇒ 결과적으로, 품질이 우수하면서 병렬화 가능하고 훈련에도 훨씬 적은 시간이 소요됨
1. Introduction
- RNN
: 이전 시점의 hiddden state와 현재 위치의 Input을 이용하여 hidden state의 squence를 생성함
: 이러한 순차적 특성은 병렬화를 배제하기에 계산량과 메모리 이슈 발생
: Factorization trick과 conditional computation으로 해결했으나, 여전히 계산량 문제 존재
📌 Attention Mechanism
- Seq2Seq는 고정된 크기의 context vector를 사용하기에 주어진 문장을 전부 고정된 크기의 한 벡터에 압축해야함
- 이러한 성능적 한계점으로 Attention mechanism 등장 !
- RNN 사용하면서 장기의존성 문제 존재, RNN을 아예 사용하지 않고 Attention만 이용하면 더 좋은 성능
2. Background
- 이전에도 computation을 줄이기 위한 방법은 계속되었음
- ConvS2S, ByteNet, Extended Neural GPU가 그 예시 중 하나(전부 input과 output에 대해 병렬적으로 처리함) / 그러나 인풋과 아웃풋 아이에 거리에 비례해서 증가한다는 단점 존재
- ConvS2S는 선형적, ByteNet은 대수적으로 증가
멀리 떨어진 위치 사이의 종속성 학습하기 더 어려워짐
Transformer에서는 Multi-head Attention으로 계산 시간 감축
—> Multi-head Attention, Self-Attention을 사용
-
Self-Attention
- reading comprehension, abstractive summarization, textual entailment, learning task, independent sentence representations를 포함한 다양한 task에서 성공적으로 사용됨
- input 시퀀스의 각 요소가 다른 요소들과 어떤 정도로 관련되어 있는지를 나타내는 가중치를 계산
-
End-to-end memory network
- simple-language question answering 과 language modeling task에서 좋은 성능을 보임
Transformer는 self-attention에만 의존한 최초의 transduction model
3. Model Architecture
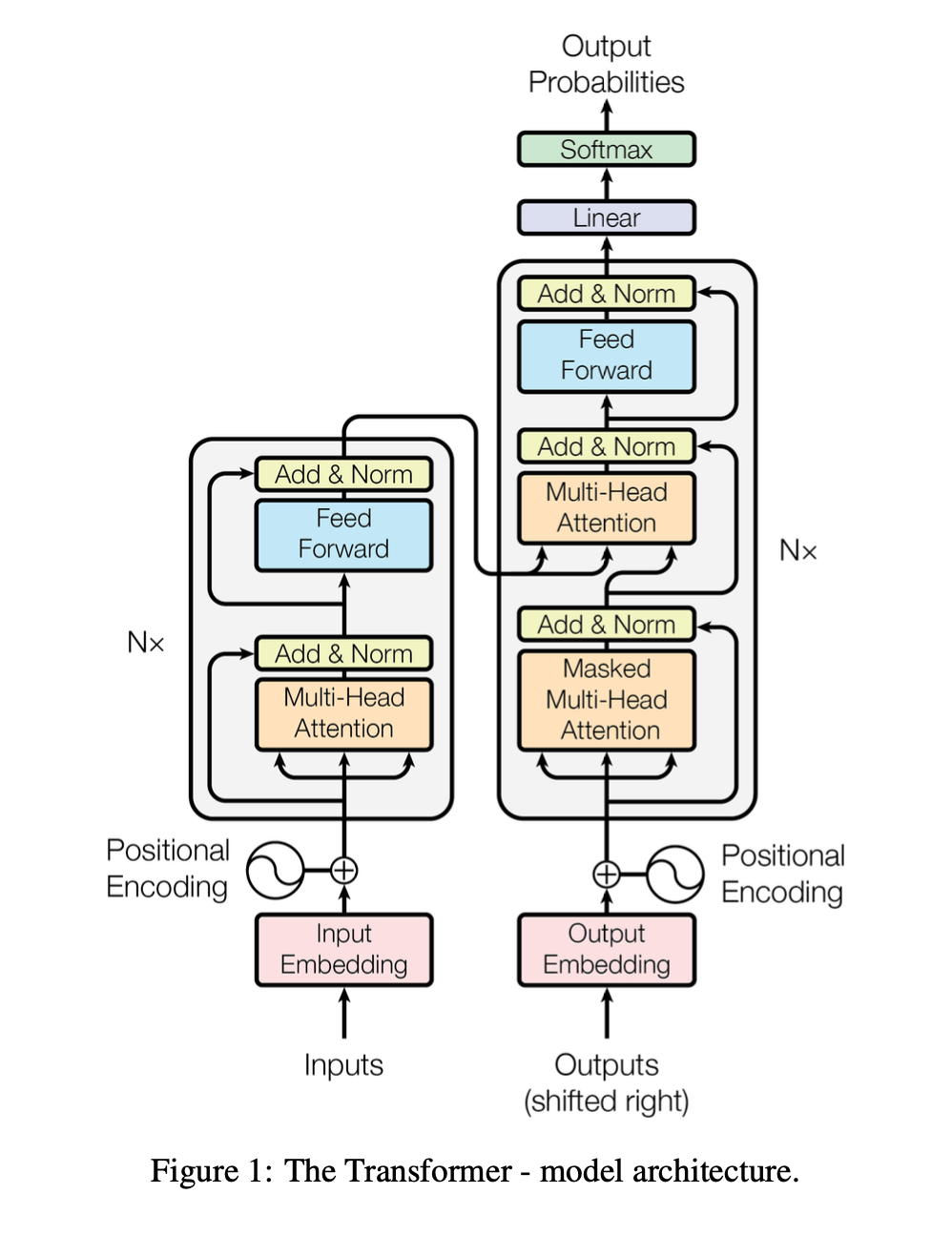
- 전체적인 구조: self+attention + point+wise, fully connected layers for both the encoder and decoder
3.1 Encoder and Decoder Stacks
- Encoder layer(2 sub layers)
: multi-head attention, feed-forward로 구성, 각 sub layers는 모두 add & LayerNormalization 진행- 즉 하나의 sub layer를 빠져나오면 LayerNorm(x+Sublayer(x))로 표현 가능함
- Decoder layer(3 sub layers)
: 인코더 스택의 출력에 대한 multi-head attention, multi-head attention, feed forward로 구성, encoder처럼 각 sub layer는 모두 add & LayerNormalization 진행- 디코더 스택의 self attention 하위 layer를 수정하여 포지션이 후속 포지션에 영향 주지 않도록 함. 이러한 마스킹은 출력 임베딩이 한 위치씩 오프셋된다는 사실과 결합하여 알려진 출력에만 의존할 수 있도록 하기 위함
3.2 Attention
- Attention Function은 query와 key-value 쌍 집합을 Output에 매핑하는 것 (모두 벡터)
- 출력은 가중치 합으로 계산됨 (가중치는 query와 해당 Key의 호환성 함수에 의해 계산)
3.2.1 Scaled Dot-Product Attention
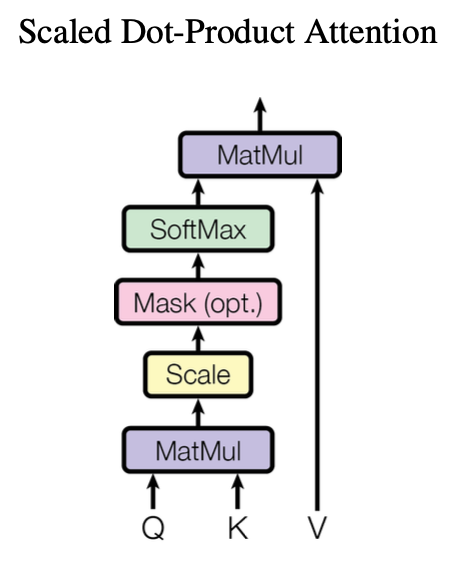
- Input: query, keys of dimension_k, and values of dimension_v
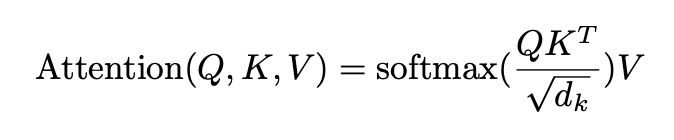
- d_k가 크면 dot product할 때 스케일이 엄청 큰데, 그러면 gradient vanishing 문제가 발생할 수 있으므로 1 / sqrt(d_k)로 스케일링 진행
- Q와 K를 행렬곱하고 스케일링, 마스크, 소프트맥스를 취해 어떤 단어와 가장 높은 연관성을 갖는지 비율을 구하고 그 확률값과 value 값을 곱해 가중치가 적용된 결과적인 attension value를 구할 수 있음. 값이 클수록 단어의 연관성이 높음
3.2.2 Multi-Head Attention
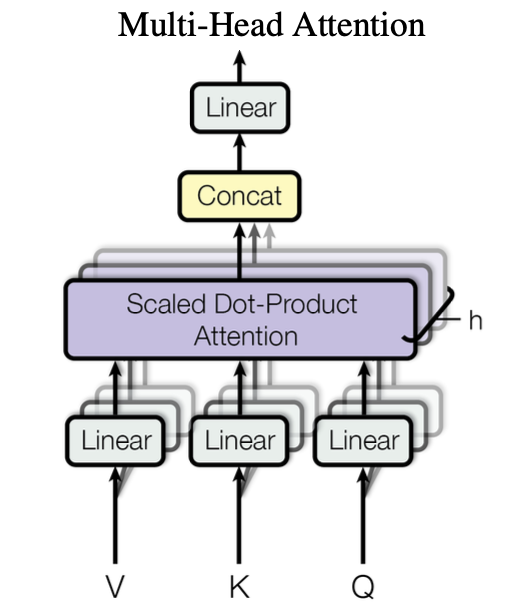
- Encoder와 Decoder는 Multi-Head Attention layer 수행
- Attention을 한 번 수행하는 것이 아닌, 병렬적으로 여러번 수행

- 큰 dimension을 h개로 쪼개서 각각 병렬적으로 처리한 후, 합침
- 본 논문에서는 h=8로 지정하며 기존 embedding vector 512로 지정했던 것을 64개로 쪼갬
- 이러한 병렬 처리 결과 Attention을 많이 해서 계산량이 많을 것 같지만, single-head attention과 비슷한 수치를 보임
3.2.3 Applications of Attention in our Model
Transformer는 Multi-head attention을 3가지 방식으로 사용함
- “Encoder-decoder attention” layer
- query는 이전 decoder 계층에서 나오고 memory key와 value는 Encoder의 output에서 나옴. 이를 통해 decoder의 모든 위치가 input sequence의 모든 위치에 대해 attention을 기울일 수 있음⇒ 각각의 출력 단어가 소스 문장에서의 어떤 단어와 연관성 있는지 구해줌
- seq2seq model의 전형적인 encoder-decoder attention mechanism 모방함⇒ 문맥 판단하기 위해 encoder의 모든 벡터 날렸던 것과 동일한 연산 진행
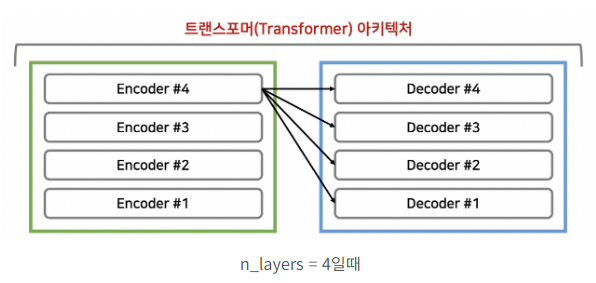
- 위 사진처럼 Encoder layer의 output이 모든 Decoder의 layer에 입력되어 출력 단어가 소스 문장의 어떤 단어와 연관성이 있는지 알 수 있음- Encoder Self-attention layer
- 같은 문장 내에서의 유사성 판단하는 연산 진행 => 연관성
- encoder의 각 위치는 encoder의 이전 layer에 있는 모든 위치에 액세스 가능
- 모든 key, value, query가 동일한 위치에서 나옴
- 현재 시점에서 encoding 해야하는 단어들에 대해서 그 문장에 대해서 attention 연산 진행
- Decoder Masked Self-Attention
- auto-regressive property를 유지하려면 decoder에서 왼쪽으로 정보가 흐르는 것 방지 (decoder에는 미래 단어 반영 x)
- 디코더의 각 위치가 해당 위치까지 디코더의 모든 위치에 attention 할 수 있도록 함
- 마스크 값으로 음수 무한의 값을 넣어 softmax 함수의 출력이 0에 가까워지도록 함
- mask 행렬을 이용해 특정 단어는 무시할 수 있도록 함
3.3 Position-wise Feed-Forward Networks
- Encoder와 Decoder의 각 layer는 fully connected feed-forward network를 가짐
- 이는 각 위치에 따로따로, 동일하게 적용됨
- ReLu 활성화 함수를 포함한 두 개의 선형 변환이 포함됨
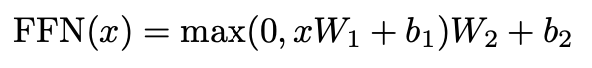
3.4 Embeddings and Softmax
- 다른 sequence transduction models처럼 학습된 Embedding 사용
- input 토큰과 output토큰을 d_model의 벡터로 변환하기 위함
- Decoder output을 예측한 뒤 토큰의 확률을 변환하기 위해서 선형변환과 Softmax함수를 사용함
- 두 개의 임베딩 layer와 pre-softmax선형 변환 간, weight들은 모두 동일
- 임베딩 layer에서는 weigth들에 sqrt(d_model)을 곱해줌
3.5 Positional Encoding
- 모델이 sequence 순서 활용하기 위해, sequence에서 토큰의 상태적 또는 절대적 위치에 대한 정보 필요하여 input embeddings에 ‘위치 인코딩’추가
⇒ 사인, 코사인 함수 사용 - 위치 인코딩은 input Embeddings와 같은 dimension을 가지므로 input embeddings와 positional encoding 둘은 합산 가능
- pos : 위치, i : 차원
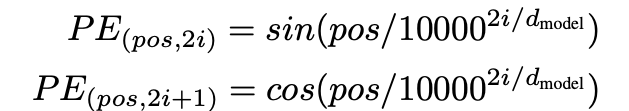
- pos : 위치, i : 차원
- sin, cos 사용한 이유
- PE(pos+k)가 PE(pos)의 linear function으로 매핑될 수 있다는 가설
- 실험했을 때, sinusoidal version의 성능 좋았기 때문
4. Why Self-Attention
3가지 측면에서 제시함
1. layer당 전체 계산 복잡도 감소
2. 연속적 병렬처리(sequential parallelize) 할 수 있도록 감소된 계산 양
3. network에서 long-range dependency 사이의 length of path 감소
: length of path는 번역 단어와 실제 단어간 거리를 의미. 이 거리가 짧으면 짧을수록 Long term dependencies를 더 잘 학습시킬 수 있다고 함

- RNN은 O(n) 시간을 소요하는데, 계산복잡도 면에서 self attention layer가 n < d이면 RNN보다 훨씬 빠르게 됨(대부분의 machine translation task는 n < d)
5. Training
5.1 Training Data and Batching
- 데이터: standard WMT English-German dataset (4.5M)과 Larger WMT 2014 English-French dataset (36M)
- 문장 쌍들은 대략적인 시퀀스 길이에 따라 배치 되었고, 각 training 배치는 약 25,000개의 소스 토큰과 25,000개의 타겟 토큰이 포함된 문장 쌍 세트가 포함됨
5.2 Hardware and Schedule
- 8 NVIDIA P1000 GPU 사용
- Base Model : Hyperparameter 한 에포크당 0.4초 걸림, 총 100,000번 (12시간) 학습
- Big Model : 한 에포크당 1.0초 걸림, 총 300,000번 (3.5일) 학습
5.3 Optimizer
- Adam 옵티마이저 사용
- learning rate를 공식에 따라 다양하게 변경함
- 처음 warmup_step에서는 선형적으로 증가하다가, 어느정도 지나면 감소시키는 방법
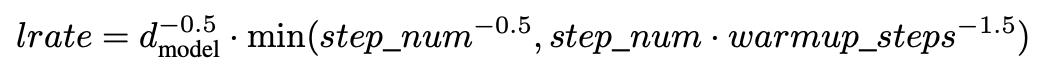
5.4 Regularization
- Residual Dropout (과적합 방지)
- 각 sub layer의 output에 dropout 적용한 후, sub layer의 input에 추가하고 정규화함
- word embedding 통해 나온 결과를 positional encoding 할 때도 적용함
- Label Smoothing
- 모델이 확실하지 않은 것을 학습해 혼란스러워지지만, 성능 평가 결과 정확도와 BLEU score이 향상됨
6. Results
6.1 Machine Translation
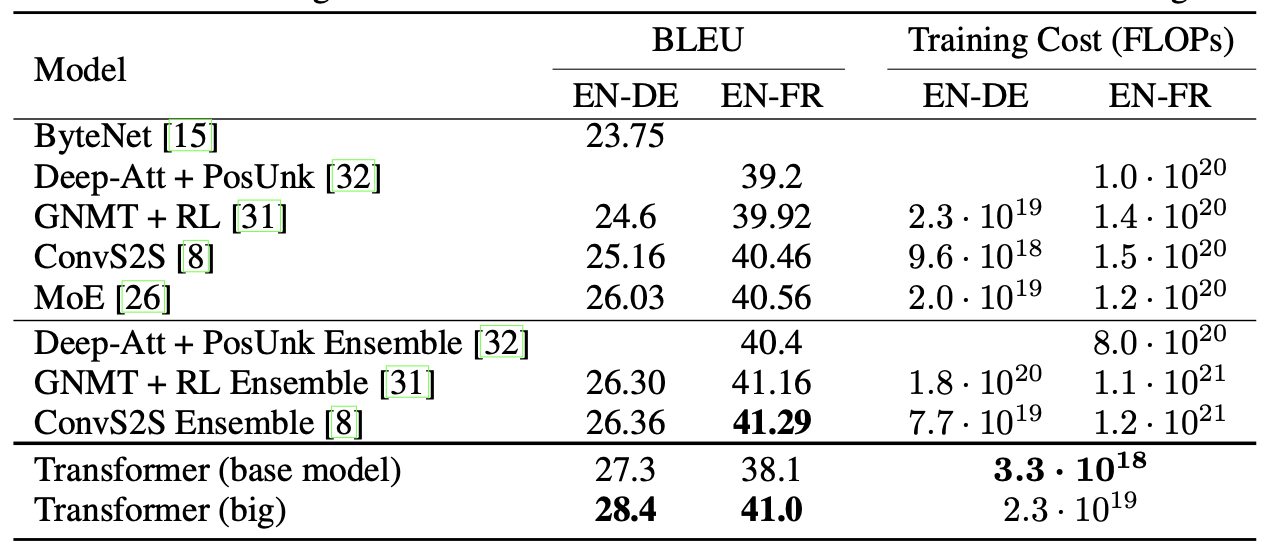
- 위 표에서 볼 수 있듯이 Large Model의 경우 BLEU Score에서 SOTA 달성(2.0 BLEU 이상 향상).
- Base Model의 경우에 training cost 측면에서 SOTA 달성 (훈련에 3.5일 소요)
- Large Model의 경우, 이전의 single model보다 1/4 적은 계산량으로 SOTA 달성함
- Base Model은 마지막 5개를 checkpoint를 average하여 얻은 단일 모델 사용하고, Big model은 마지막 20개의 checkpoint를 average하여 구축함 / 이러한 파라미터는 실험한 후 선택
6.2 Model Variations
-
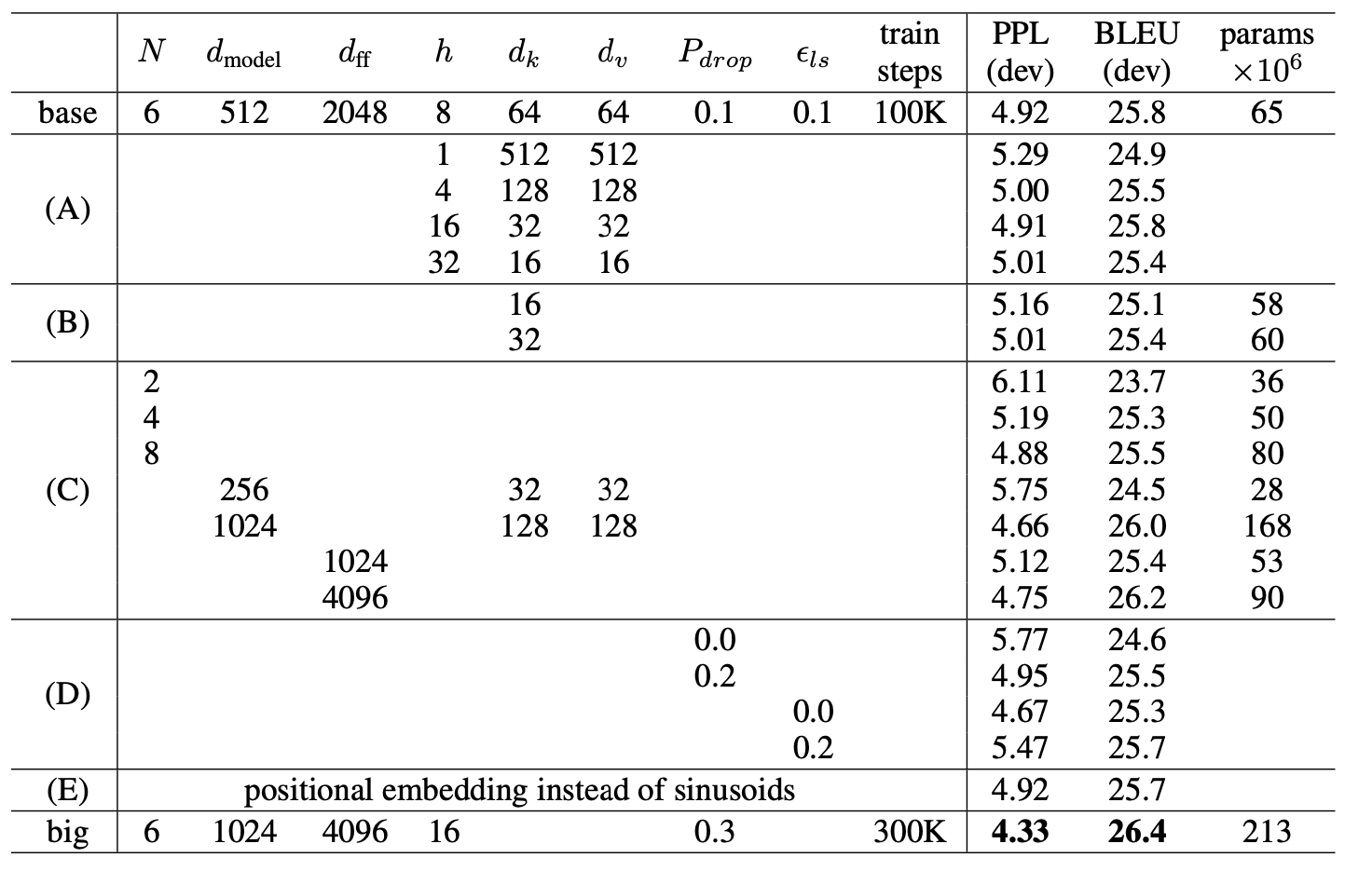
하이퍼 파라미터 변동시키며 어떤 파라미터가 가장 좋은지 계속 실험
-
(A행) 계산량 일정하게 유지하면서 attention key,value 차원 변경함
⇒ 최상의 설정보다 0.9 BLEU 나쁨. head 수가 너무 많으면 품질도 떨어짐 -
(B행) attention key 크기 줄이면 모델 품질 저하함
-
(C행),(D행) 예상대로 모델이 클수록 좋으면, dropout이 과적합 방지에 효과적
7. Conclusion
- 적은 학습 시간으로도 SOTA 달성했다는 점. 특히 Attention Mechanism만 사용해서 만든 모델이라는 점이 인상적
