Sequence to Sequence Learning with Neural Networks
Introduction
DNN(심층신경망)
-
음성 인식/시각적 객체 인식과 같은 어려운 문제에서 좋은 성능 보이는 머신 러닝 모델
-
몇 단계 거치지 않고도 병렬 연산(동시에 많은 계산을 수행) 수행 가능
-
복잡한 계산을 학습함
-
한계 : 입력과 목표가 고정된 차원의 벡터로 인코딩될 수 있는 문제에만 적용가능한데, 대부분의 중요한 문제는 길이를 미리 알 수 없는 시퀀스로 표현하는 것이 가장 효과적
LSTM 구조를 간단하게 적용하면 일반적인 sequence to sequence 문제 해결가능
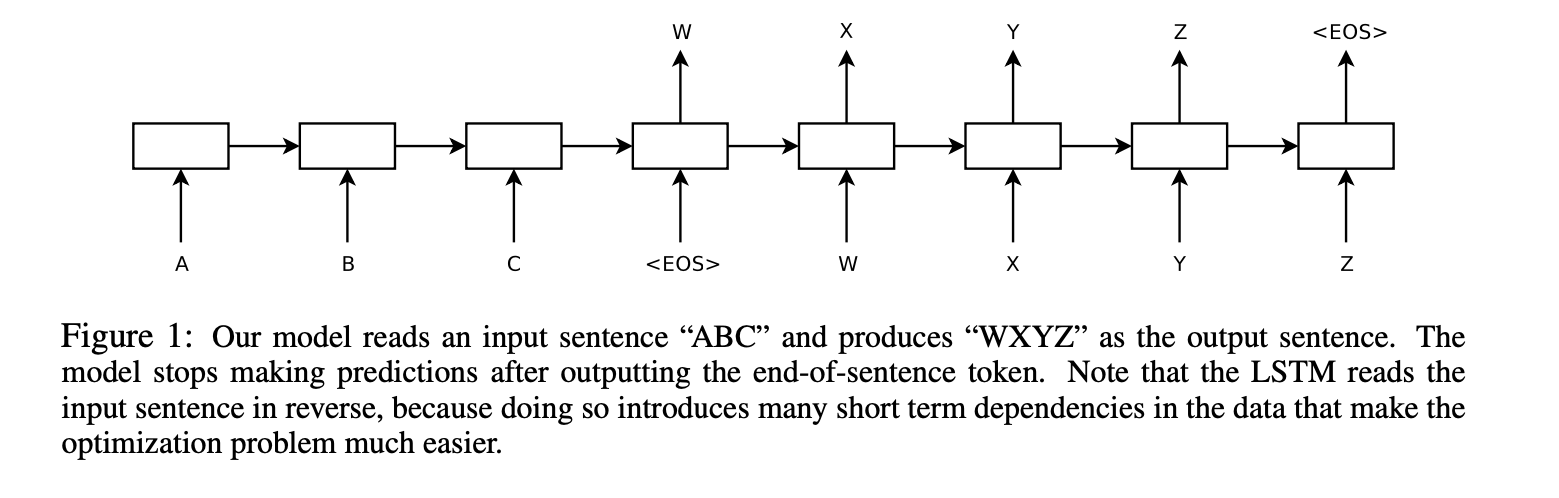
FIG 1
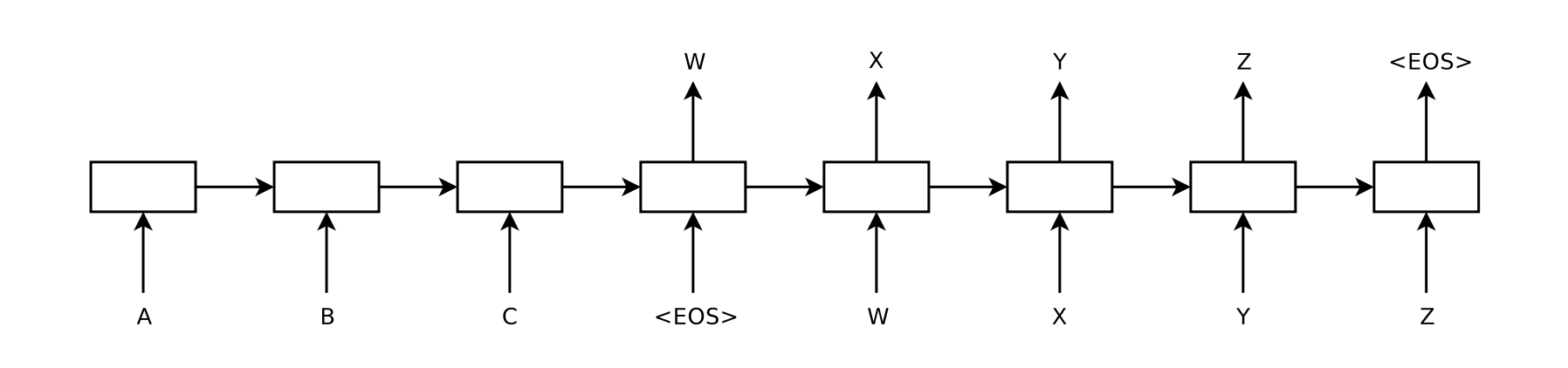
-
한 번에 한 타임스텝씩 입력 시퀀스(ABC)를 읽어 큰 고정 차원 벡터 표현을 얻은 다음, 다른 LSTM을 사용하여 해당 벡터에서 출력 시퀀스(WXYZ) 추출
-
두번째 LSTM은 입력 시퀀스에 따라 조건이 지정된다는 점을 제외하면 본질적으로 순환 신경망 언어 모델
-
EOS 출력 후 예측 중단함
-
LSTM이 장거리 시간 종속성이 있는 데이터 학습 가능한 이유: 입력과 해당 출력 사이에 상당한 시간 지연이 있기 때문에 자연스러운 선택이 됨.
주요 결과
- English to French 번역에서 BLEU score: 34.81 (기준: 33.30)
- left to right beam search decoder 사용한 5개의 심층 LSTM으로 구성된 앙상블
- 최적화x 신경망 구조가 SMT 시스템보다 더 나은 결과를 보임
💡 BLEU SCORE: 기계 번역 결과와 사람이 직접 번역한 결과가 얼마나 유사한지 비교하여 번역에 대한 성능을 측정하는 방법, 높을수록 성능이 더 좋음
-
LSTM은 훈련 및 테스트 세트에서 출력 문장이 아닌 입력 문장의 단어 순서를 뒤집음 —> 최적화 문제를 훨씬 단순하게 만드는 단기 종속성 도입함 -> SGD가 긴 문장에 문제 없는 LSTM 학습 가능 → 모델이 장기의존성 다루는 데 효과적
LSTM의 유용한 특성 : 길이의 변동이 심한 input 문장을 고정차원 벡터 표현으로 매핑하는 것을 학습함 -
번역은 의역할 수 있기에 LSTM이 의미를 포착하는 문장 표현을 찾도록 함
-
모델이 어순을 인식하고, 능동태/수동태에 꽤 변함없음을 보여줌
The model
RNN(Recurrent Neural Network)
-
feedforward 신경망을 시퀀스로 자연스럽게 일반화한 것
-
입력 sequence(X1, …,.XT)가 주어지면, 표준 RNN은 다음 식을 반복하여 출력 sequence(y1,…,yT) 계산
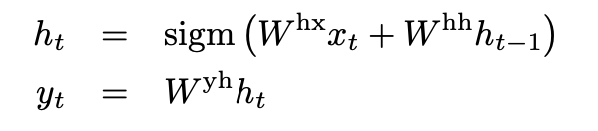
-
입력과 출력 사이의 정렬을 미리 알고 있는 경우 RNN은 시퀀스에 쉽게 매핑 가능
-
입력과 출력 시퀀스의 길이가 서로 다르고, 복잡한 문제에 RNN 적용하는 방법은 명확하지 않음
-
일반적인 시퀀스 학습은 하나의 RNN을 사용하여 입력 시퀀스를 고정된 크기의 벡터에 매핑한 다음 다른 RNN을 사용하여 벡터를 목표 sequence에 매핑하는 것(선행연구)
작동은 가능하나 장기 의존성 때문에 RNN 훈련 어려울 것
LSTM은 장거리 시간 의존성 문제를 학습하므로 이 설정에서 성공 가능함
LSTM 계산
- 목표는 조건부 확률 추정
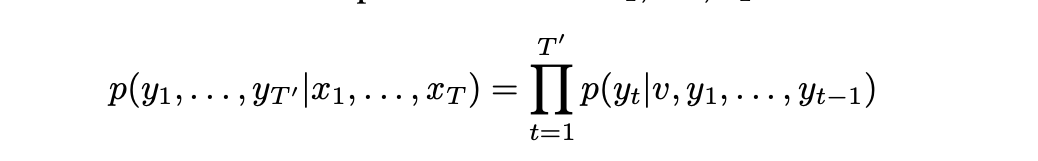
-
(x1, ..., xT)는 입력 시퀀스이고 y1, ..., yT'는 길이 T'가 T와 다를 수 있는 해당 출력 시퀀스
-
LSTM 모델을 사용하여 입력 시퀀스를 고정 차원 표현으로 변환하고, 이 표현을 초기 상태로 사용하여 LSTM-LM을 초기화함
-
그런 다음, LSTM-LM은 주어진 초기 상태에서 출력 시퀀스의 조건부 확률을 계산
-
이 방정식에서 각 p(yt|v, y1, . . . , yt−1) 분포는 모든 단어에 걸쳐 softmax로 표현됨
-
Graves의 LSTM 공식 사용함
-
EOS를 총해 문장이 끝났음을 알 수 있음
실제 모델과 설명의 차이점
-
입력 시퀀스와 출력 시퀀스에 사용한 LSTM이 다름 : LSTM 모델의 매개변수 수를 늘리고 여러 언어 쌍에 대한 훈련 데이터를 공유하여 성능 향상시키고자 함
-
심층 LSTM이 얕은 LSTM보다 더 뛰어나기에 4개 층 가진 LSTM 선택
-
입력 문장의 단어 순서 뒤집는 것이 매우 유용함 : 문장 a,b,c를 문장 α,β,γ에 매핑하는 것보다 단어 순서를 뒤집어서 c,b,a를 α,β,γ,에 매핑하면 a는 α에 가깝고, b는 β에 가깝기에 SGD가 입력과 출력 사이에 ‘소통’을 쉽게 설정할 수 있음 ("α, β, γ"는 각각 "a, b, c"의 번역된 결과)
Experiments
SMT 시스템 사용하지 않고 입력 문장을 직접 번역 & SMT 기준선의 n-best 목록을 재점수화 하는 방법 두가지 방법으로 적용함
1. Dataset details
-
WMT’14 영어-프랑스어 데이터 세트 사용
-
일반적인 신경 언어 모델은 각 단어에 대한 벡터 표현에 의존하기에 두 언어 모두 고정된 어휘 사용
-
어휘에서 벗어난 모든 단어는 ‘UNK’ token으로 대체
2. Decoding and Rescoring
- 핵심은 많은 문장 쌍에 큰 심층 LSTM을 훈련하는 것.
- 소스 문장 S가 주어졌을 때 올바른 번역 T의 로그 확률을 극대화하는 방식으로 훈련
훈련 목표
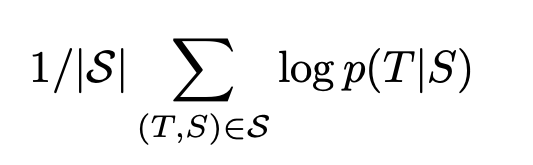
- S는 훈련세트
- 학습이 끝나면, LSTM에 따라 가장 가능성 높은 번역 찾아 번역 생성
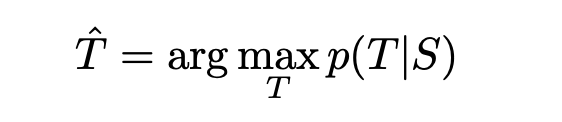
-
부분 가설은 일부 번역의 접두사이며, 소수의 부분 가설 B를 유지하는 간단한 left-to-right beam search decoder사용하여 가장 가능성 높은 번역 검색
-
각 시간 단계에서 빔(가설을 유지하는 크기)의 각 부분 가설을 어휘에서 모든 가능한 단어로 확장함
-
이는 가설의 수를 크게 증가하므로 모델의 로그 확률에 따라 가장 가능성 높은 B가설을 제외한 모든 가설 버림
-
EOS가 가설에 추가되자마자 beam에서 제거되어 완전한 가설 집합에 추가됨
=> 빔 서치 방법을 사용하여 다양한 부분 가설을 탐색하고, 모델의 로그 확률을 기반으로 최우수 가설을 선택하여 문장을 생성
3. Reversing the Source Sentences
-
source 문장만 반대로 바뀌었을 때 더 잘 학습함
-
LSTM 복잡성 감소/디코딩된 번역의 test BLEU는 증가
⇒ 완벽한 설명 x, 데이터셋에 단기 의존성이 많이 도입되어 발생한다고 생각
source 문장을 target 문장과 이으면 source 문장의 각각의 단어는 target 문장의 해당하는 단어와 거리가 멀어짐 ⇒ 최소 시간 지연 가짐
source 문장의 단어를 반대로 돌리면 source 언어와 target 언어에서 대응하는 단어들 사이의 평균 거리는 변하지 않음. 그러나 source 언어의 처음 몇 개의 단어는 target 언어의 처음 몇 개의 단어와 매우 가깝기에 문제인 최소 시간 지연이 크게 줄어듦. 따라서 역전파는 ‘의사소통 설정’ 시간이 더 쉬워지고, 이는 전반적인 성능을 향상시킴
reversed source 문장에 학습된 LSTM이 원래 source 문장에 대해 훈련된 LSTM보다 긴 문장에 대해 훨씬 더 나은 결과 나옴.
⇒ 이는 input 문장을 역전하면 메모리 활용도가 더 높은 LSTM이 생성됨을 보여줌
4. Training details
LSTM 모델은 훈련하기 쉬움
심층 LSTM이 얕은 LSTM을 크게 능가하는데, 이는 각 추가 계층이 훨씬 더 큰 숨겨진 상태로 인해 혼란을 거의 10% 감소시켰을 수 있음
각 출력에서 80,000단어 이상의 Naive softmax 사용함
결과적인 LSTM에는 380M의 parameter가 있으며, 그 중 64M은 순수 순환 연결(encoder, decoder 각각 32M)
input 어휘가 160,000개, output 어휘가 80,000개인 4개의 층과 1000차원 단어 임베딩이 있는 심층 LSTM을 사용함
- 모든 LSTM parameter를 -0.08과 0.08 사이의 균일한 분포로 초기화함
- 운동량 없는 SGD 사용, ir은 0.7로 고정. 5epoch 이후, 반 에포크마다 ir을 절반으로 줄임. 모델을 총 7.5 epoch동안 훈련시킴
- gradient는 128개의 sequence batch 사용하여 batch size로 나누었음 (128개)
- LSTM은 기울기 소멸 문제를 겪지 않지만, 기울기가 폭발할 수 있음. 기울기의 표준이 임계값을 초과할 때 크기 조정하여 기울기의 표준에 대한 엄격한 제약을 적용함
- 문장마다 길이가 다르기에, 임의로 선택한 128개의 training 문장의 미니 배치에는 짧은 문장이 많고 긴 문장이 거의 없으므로 결과적으로 미니 배치의 계산 중 많은 부분이 낭비됨. 이에, 미니 배치 내의 모든 문장의 길이가 대략 동일한지 확인했으며 이는 속도가 2배 증가됨
5. Parallelization
단일 GPU는 속도가 너무 느려서(초당 1,700단어의 속도) 8-GPU 머신을 사용해 모델을 병렬화했음
LSTM의 각 계층은 서로 다른 GPU에서 실행되었으며, 계산되자마자 다음 GPU에 활성화 전달4개의 LSTM 층이 존재하고, 각 층은 별도의 GPU에 상주함. 남은 4개의 GPU는 소프트맥스를 병렬화하는데 사용되었으므로 각 GPU는 1000*20000 행렬을 곱하는 역할 함
⇒ 결과적으로 초당 6,300단어(영어와 프랑스어 모두)의 속도와 128개의 미니배치를 달성함
⇒ 훈련은 총 10일 정도 소요됨
6. Experimental Results
번역의 품질 평가하기 위해 BLEU 점수 사용함
토큰화된 예측과 실측 결과에 대해 multi-bleu.pl1을 사용해 BLEU 점수 계산함
최상의 결과는 무작위 초기화와 미니 배치의 무작위 순서가 다른 LSTM 앙상블로 얻어짐
어휘 외 단어를 처리할 수 없음
LSTM은 기준 시스템의 1000-베스트 목록을 재작성함으로써 이전 최신 기술의 0.5 BLEU 포인트 이내에 존재
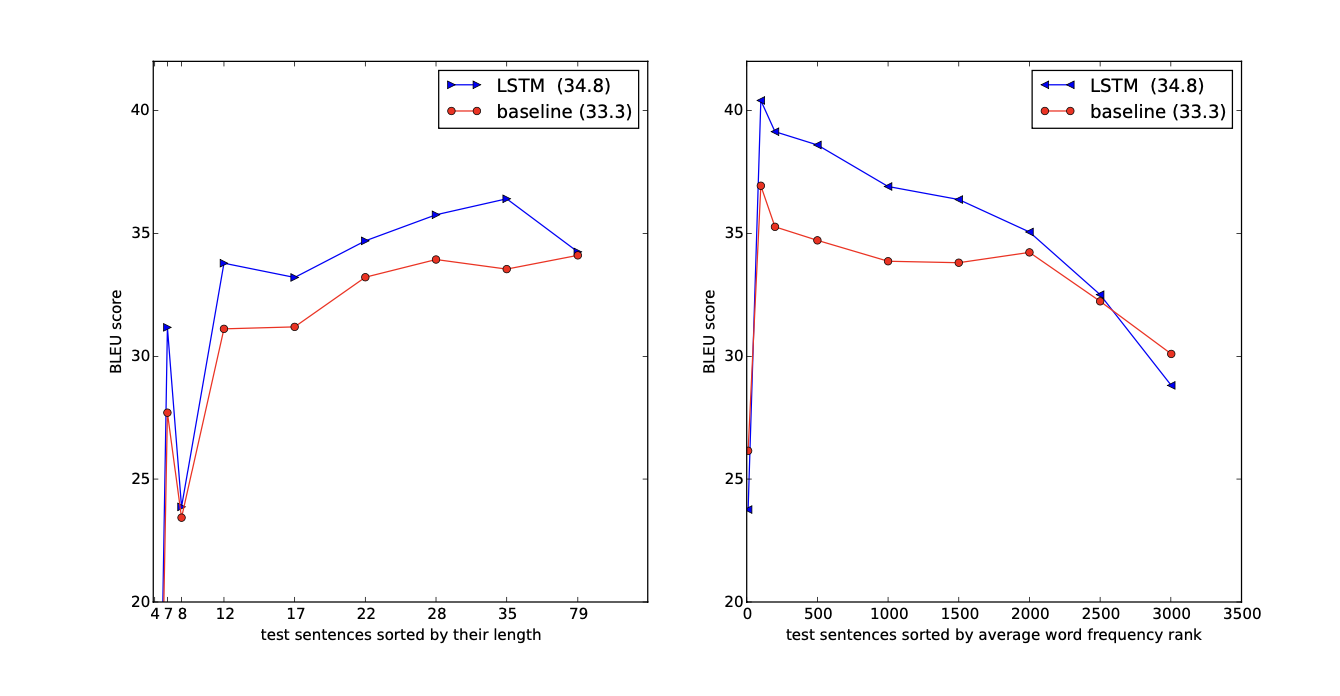
7. Performance on long sentences
Fig3에서 보이는 것처럼 LSTM은 정량적으로 나타낸 긴 문장에서 좋은 결과 보임
8. Model Analysis
단어의 sequence를 고정된 차원의 벡터로 바꾸는 능력이 이 모델에서 가장 매력적임
Fig2는 학습된 표현의 일부를 시각화한 것 ⇒ 표현이 단어의 순서에 민감한 반면, 능동적인 목소리를 수동적인 목소리로 대체하는 것에는 상당히 무감각하다는 것을 보여줌
Conclusion
이 연구에서 제한된 어휘를 가진 큰 심층 LSTM이 대규모 MT 작업에서 어휘가 무제한인 표준 SMT 기반 시스템보다 뛰어남을 보여줌
MT에 대한 간단한 LSTM 기반 접근 방식의 성공은 충분한 훈련 데이터가 있다면 다른 많은 시퀀스 학습 문제에서 잘 수행해야 함을 시사합니다.
source 문장의 단어를 뒤집어서 얻은 개선 정도는 학습 문제를 훨씬 단순하게 만들기 때문에 단기 의존성이 가장 많은 문제 인코딩을 찾는 것이 중요함
LSTM은 reversed dataset에서 매우 긴 문장을 정확히 번역 가능함
가장 중요한 것은 향후 작업을 통해 번역 정확도가 더욱 높아질 수 있다는 것
이러한 결과는 접근 방식이 까다로운 다른 sequence to sequence에서 성공할 가능성이 높다는 것을 의미함
