Distinct
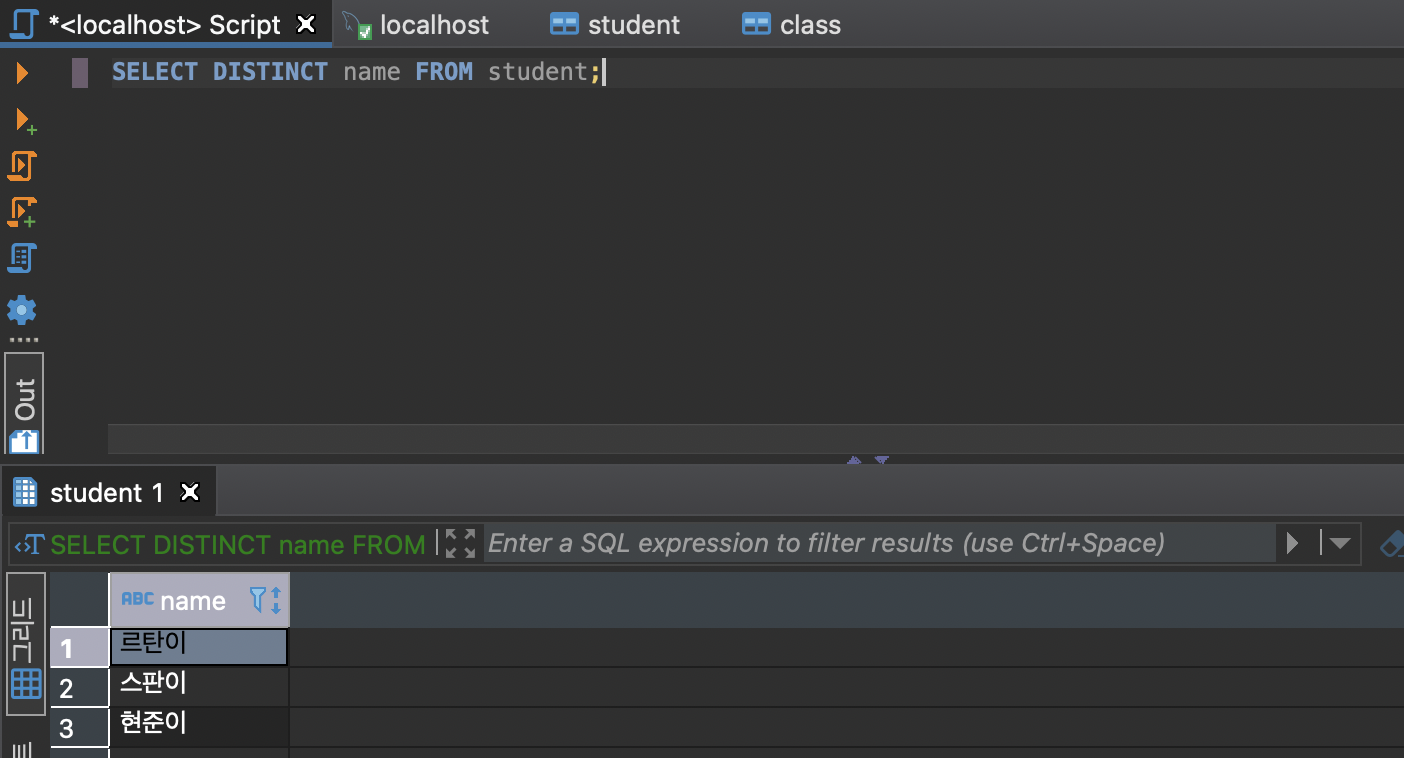
select distinct (column_name) from (table_name);중복되는 값 제거하는 방법

select distinct * from (table_name);*를 입력하면 일일이 다 나오는데
왜 그러냐면,
지금 각각의 칼럼들이 모두 다 개별적으로 다르기 때문에
레코드들이 유일하다고 판단 될 수 없어서 개별적으로 값이 나온다.라고 생각 할 것
Aggregate 그룹 함수
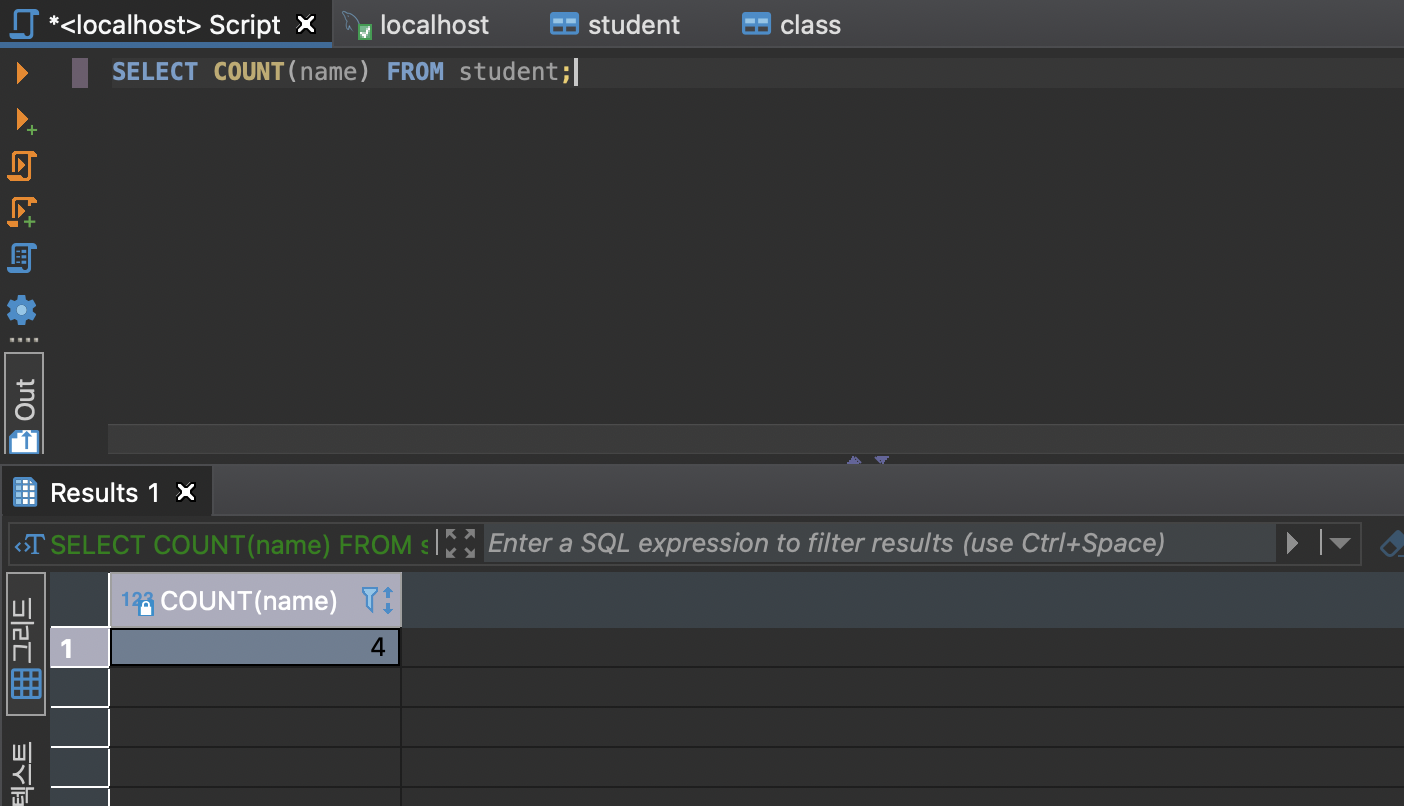
- count
안에 distinct를 쓰면 유일한 값들의 갯수를 구해와라. 라는 뜻
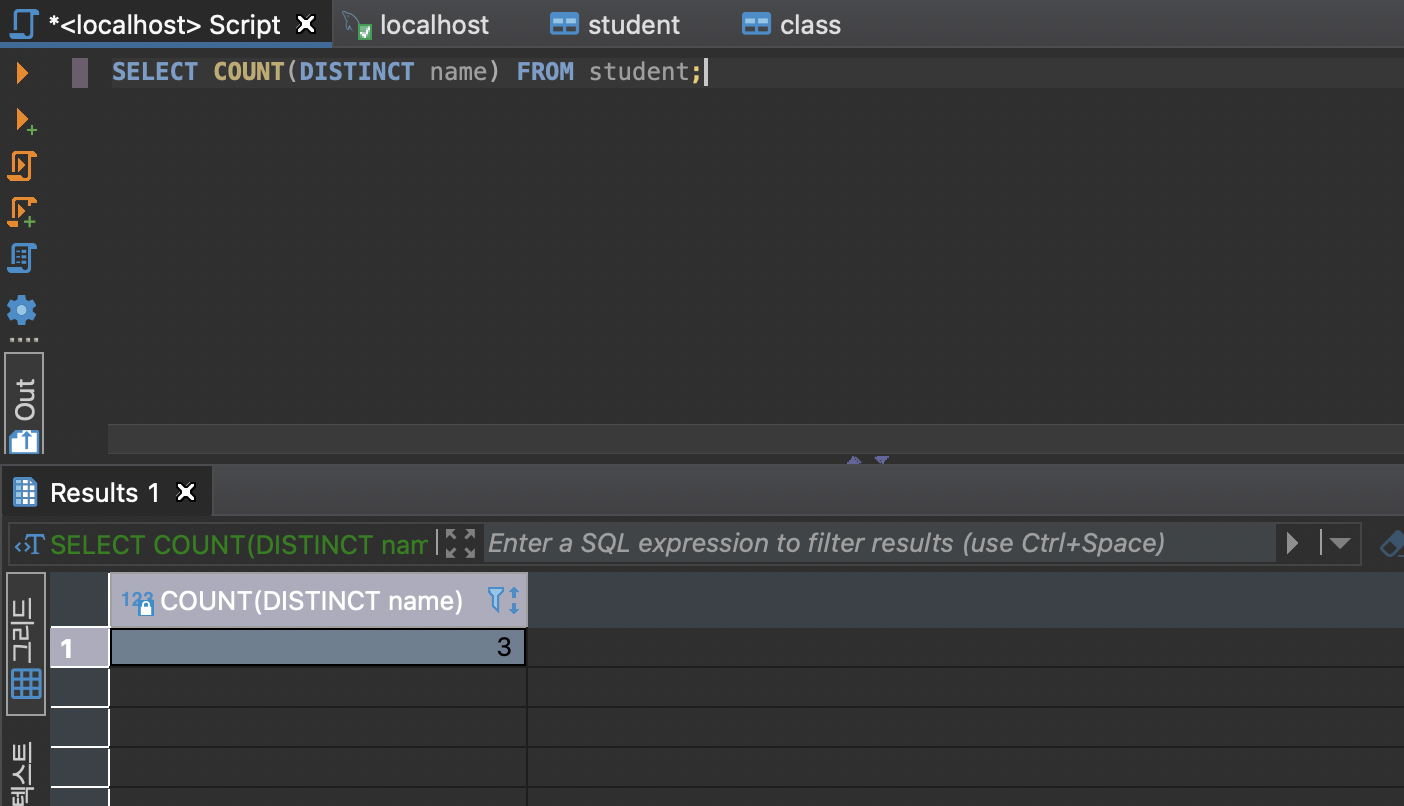
select COUNT(DISTINCT column_name) from (table_name);-> 3 출력
- min / max

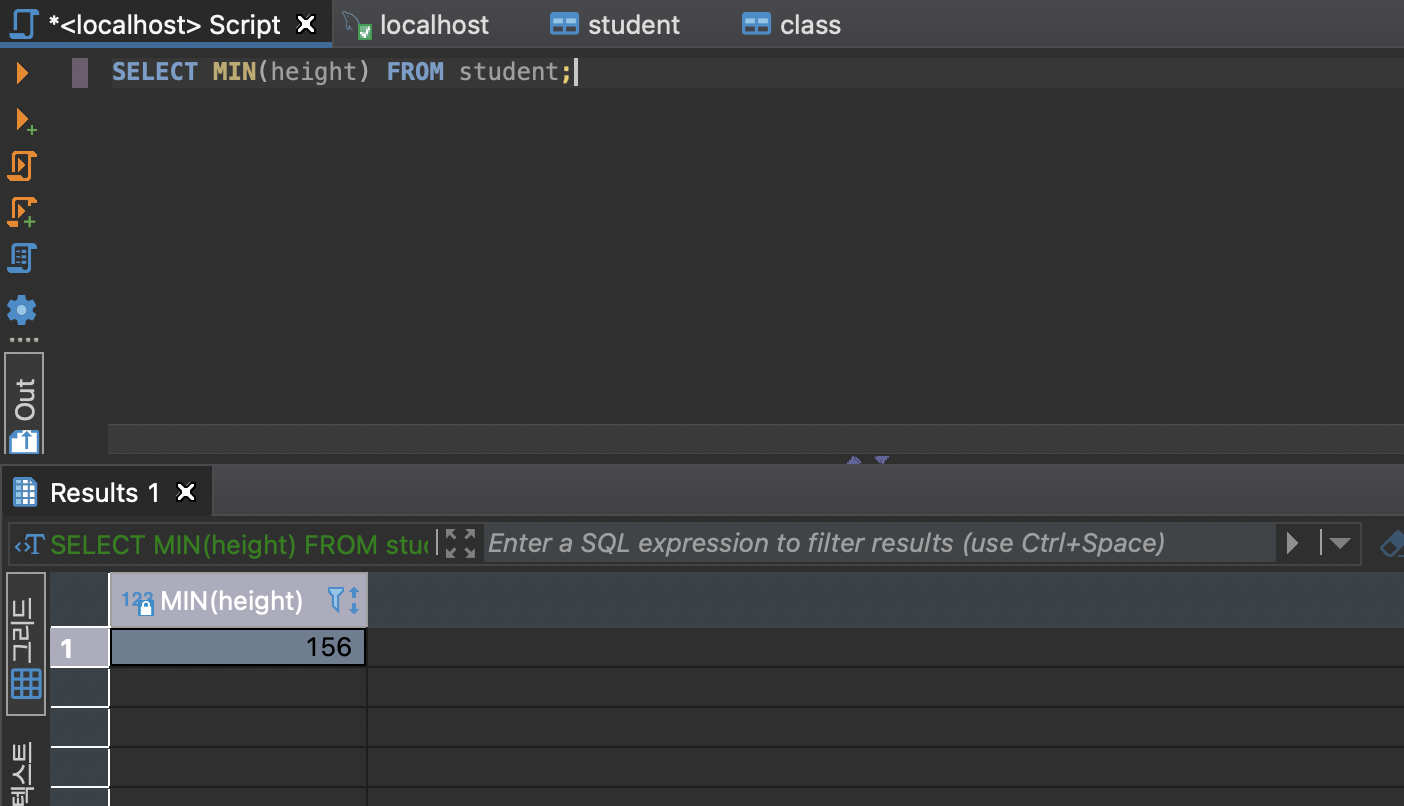
select MAX(column_name) from (table_name);select MIN(column_name) from (table_name);- avg

select avg(column_name) from (table_name);평균값.
집계하는 함수가 있다면 해당 집계함수 외에는 다른 값을 가져오지 못한다.
- sum
합계
Group by 절
레코드들을 특정 기준으로 묶어줄 때 사용.
특정 기준에 의해 그룹화한 결과 집합을 기준으로
쿼리를 구하고 싶은 경우가 있는데
이럴 때, Group by 절을 사용해서 하나의 그룹을 하나의 레코드로 압축해 사용할 수 있음.
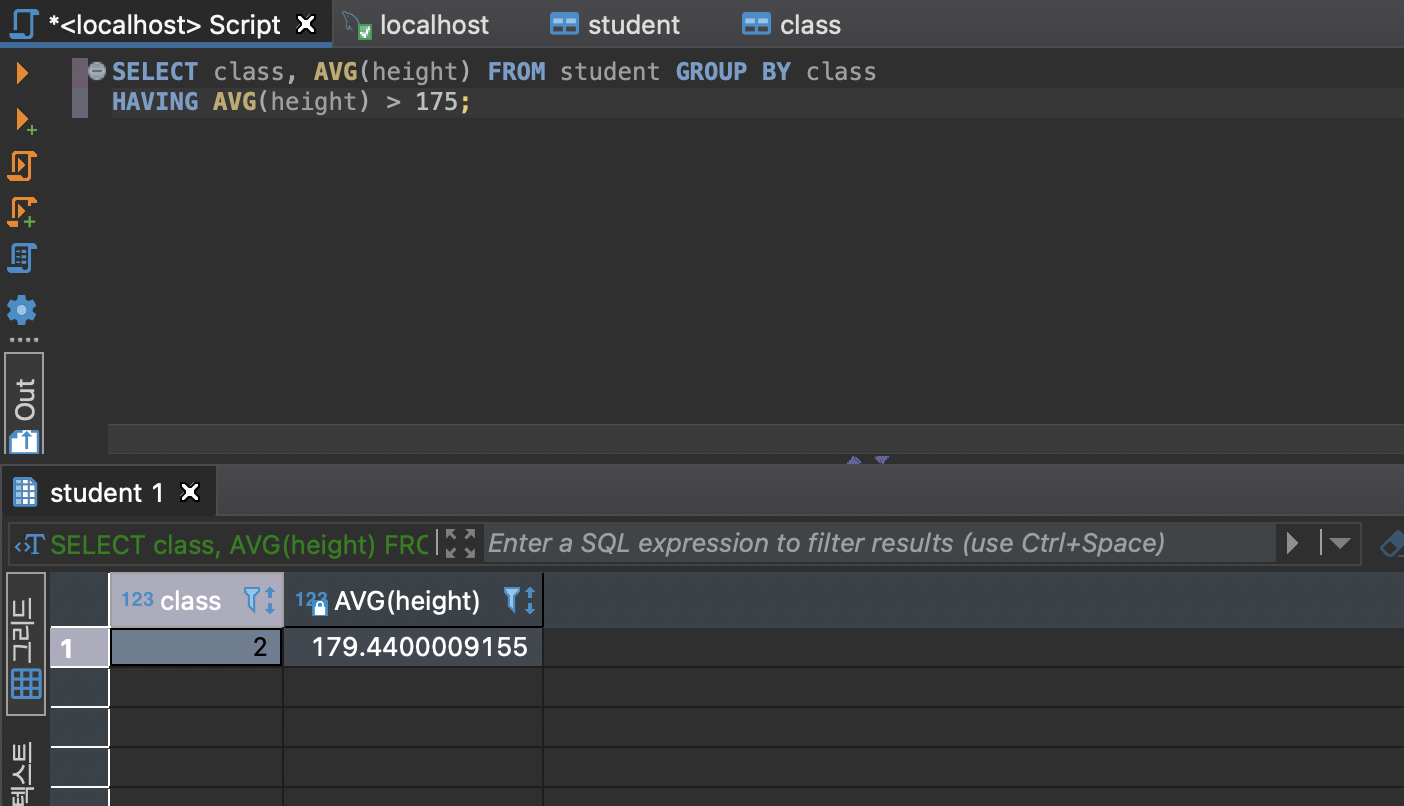
주의사항
Group by 를 사용할 때는 묶은 기준의 필드만 뽑아올 수 있음
Having은 where절과 같이 조건을 거는 것과 똑같다.
(반환되는 결과조건 집합의 조건을 설정 가능)
Alias (별칭)
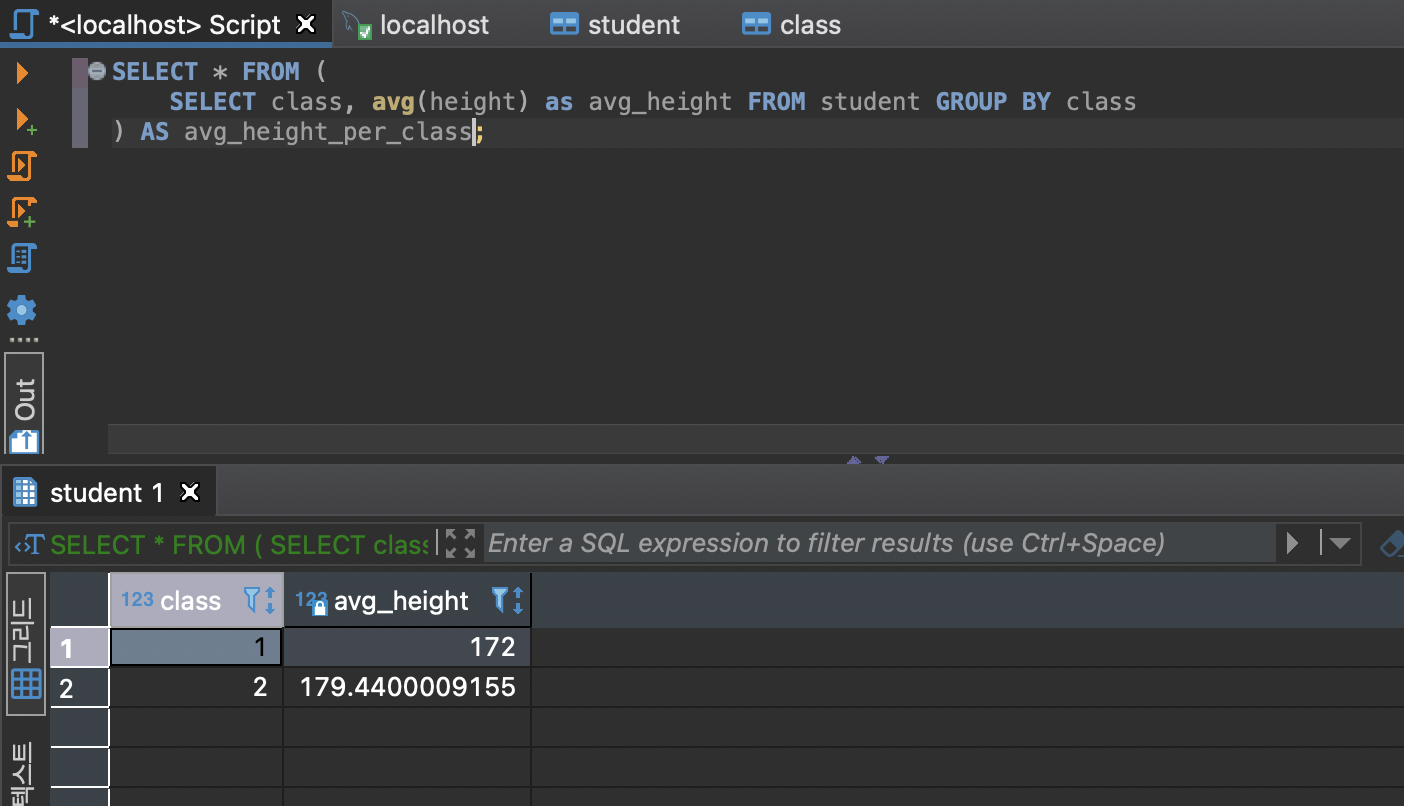
복잡한 테이블 이름이나 필드의 이름을 좀 더 읽기 쉽도록 해줌.
select (field_name) as (alias_name) from (table_name);select (field_name) from (table_name) as (alias_name);서브쿼리 (SubQuery)
한 쿼리에 다른 쿼리를 포함해 사용하는 것을 서브쿼리(Sub Query)라고 한다.
서브쿼리를 포함하고 있는 쿼리를 외부쿼리(Outer Query)라고 부르며 서브쿼리는 내부쿼리(Inner Query)라고 부르기도 한다.
join을 사용하지 못하는 경우에 서브 쿼리를 사용하는 것이 좋다.
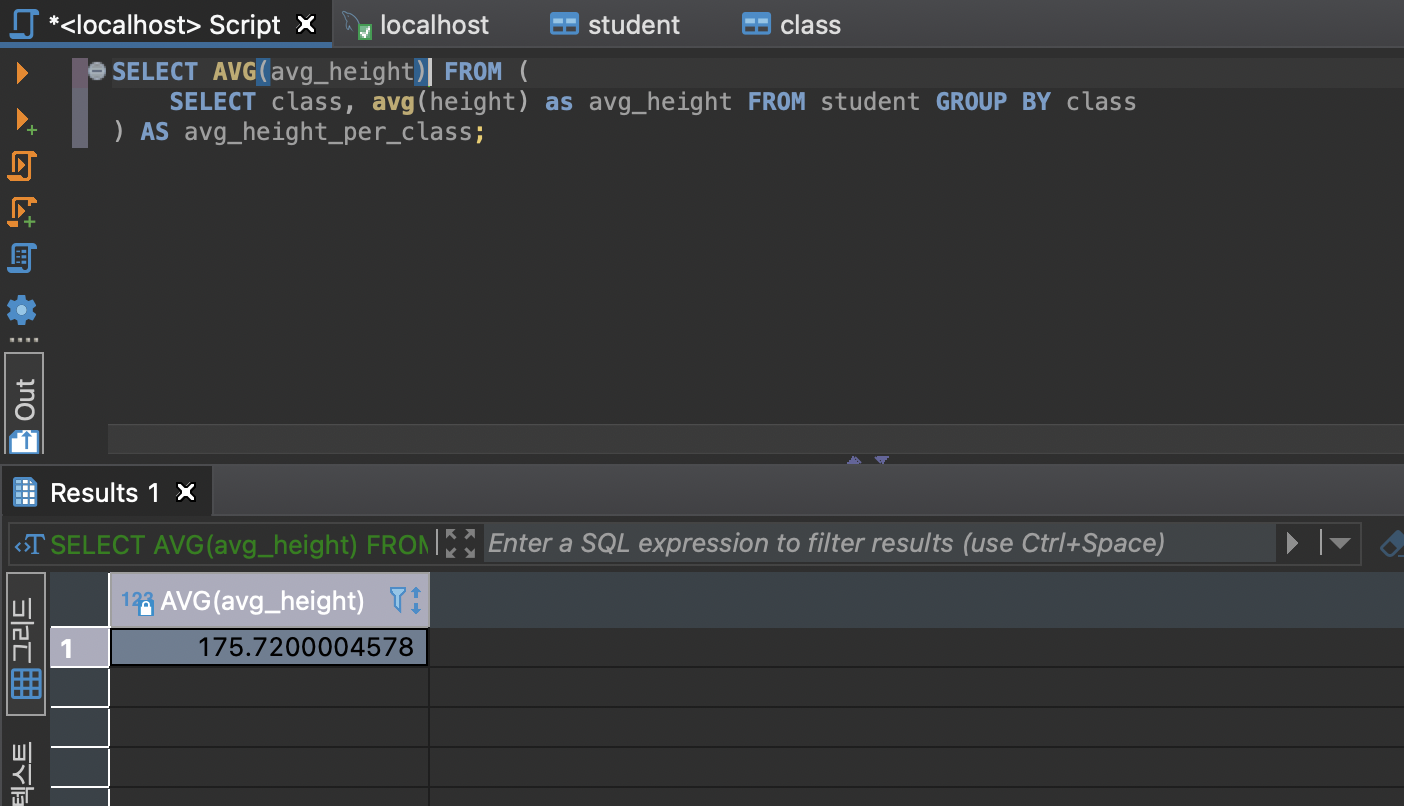
굳이 서브쿼리를 사용하지 않고 join을 사용하는 것이 성능상 이점이 있다.
서브쿼리로 생긴 테이블을 파생 테이블이라고 하는데
쿼리 안에 넣어서 사용할 때는 파생 테이블을 alias로 별칭을 붙여 사용해야 한다.
이런 가상 테이블들은 비용이 많이 든다고..!
서브쿼리를 이용해서 평균의 평균도 구할 수 있다.
Order by 절
정렬시키고 싶을 때 사용
어느 순서대로 정렬할 것인지
Limit
Order by에 조건 사용 ( 몇 개를 뽑아올 것인지 )
문법작성 순서
SELECT -> DISTINCT -> FROM -> JOIN -> ON -> GROUP BY
-> HAVING -> ORDER BY -> LIMIT
실행결과 순서
FROM -> ON -> JOIN -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT -> ORDER BY
