데이터베이스
1.관계형 데이터베이스 & DBeaver
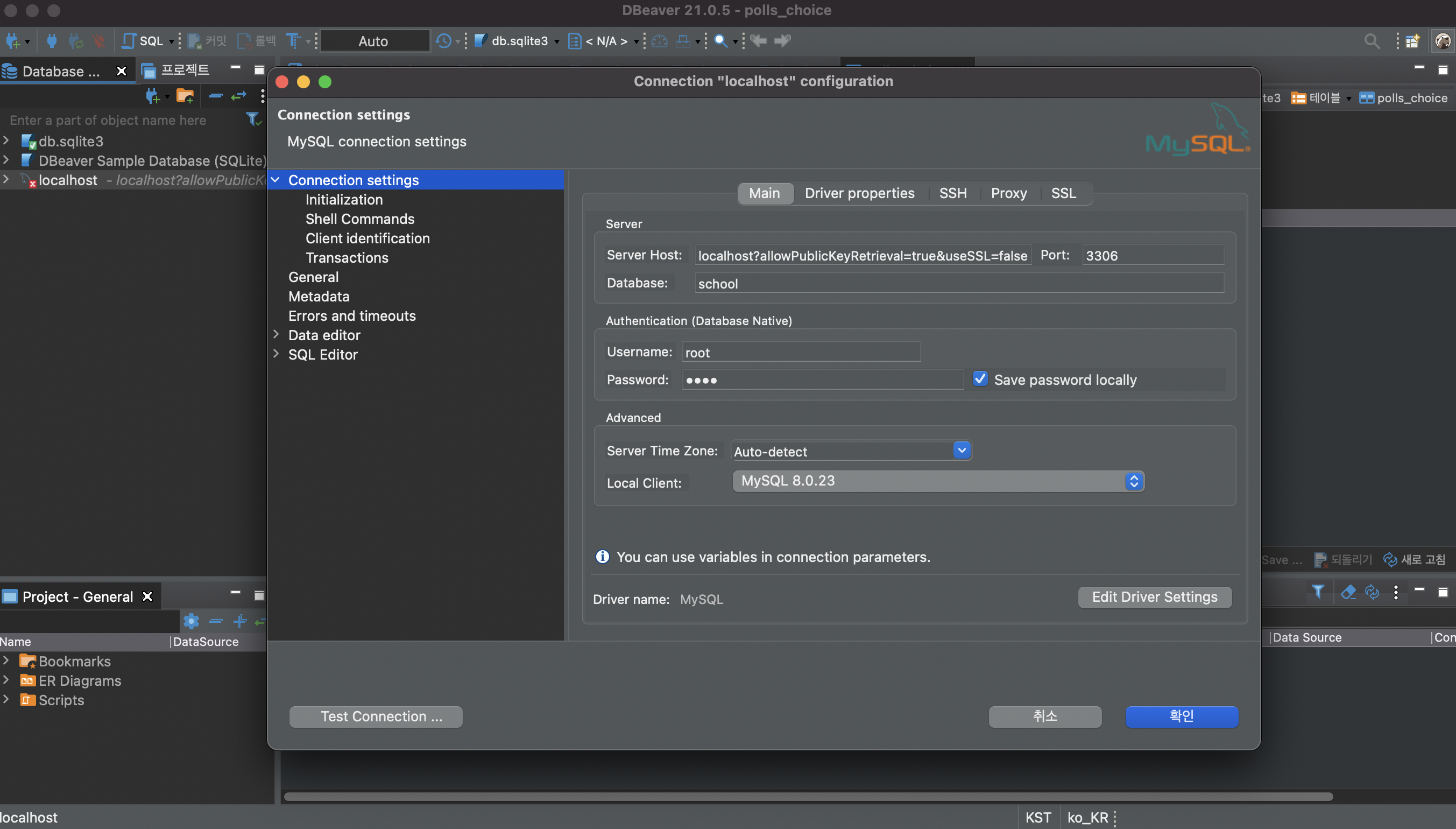
관계형 데이터베이스의 개념은 크게데이터베이스 - 테이블 - 레코드 로 구성되어 있고테이블은 데이터베이스의 명세서라고 보면 된다.관계형 데이터베이스는 정형화 되어있는 데이터( 정형화란 일정한 형식이나 틀로 고정됨을 뜻한다. )Relational DataBase (RDB)
2.CRUD - 1
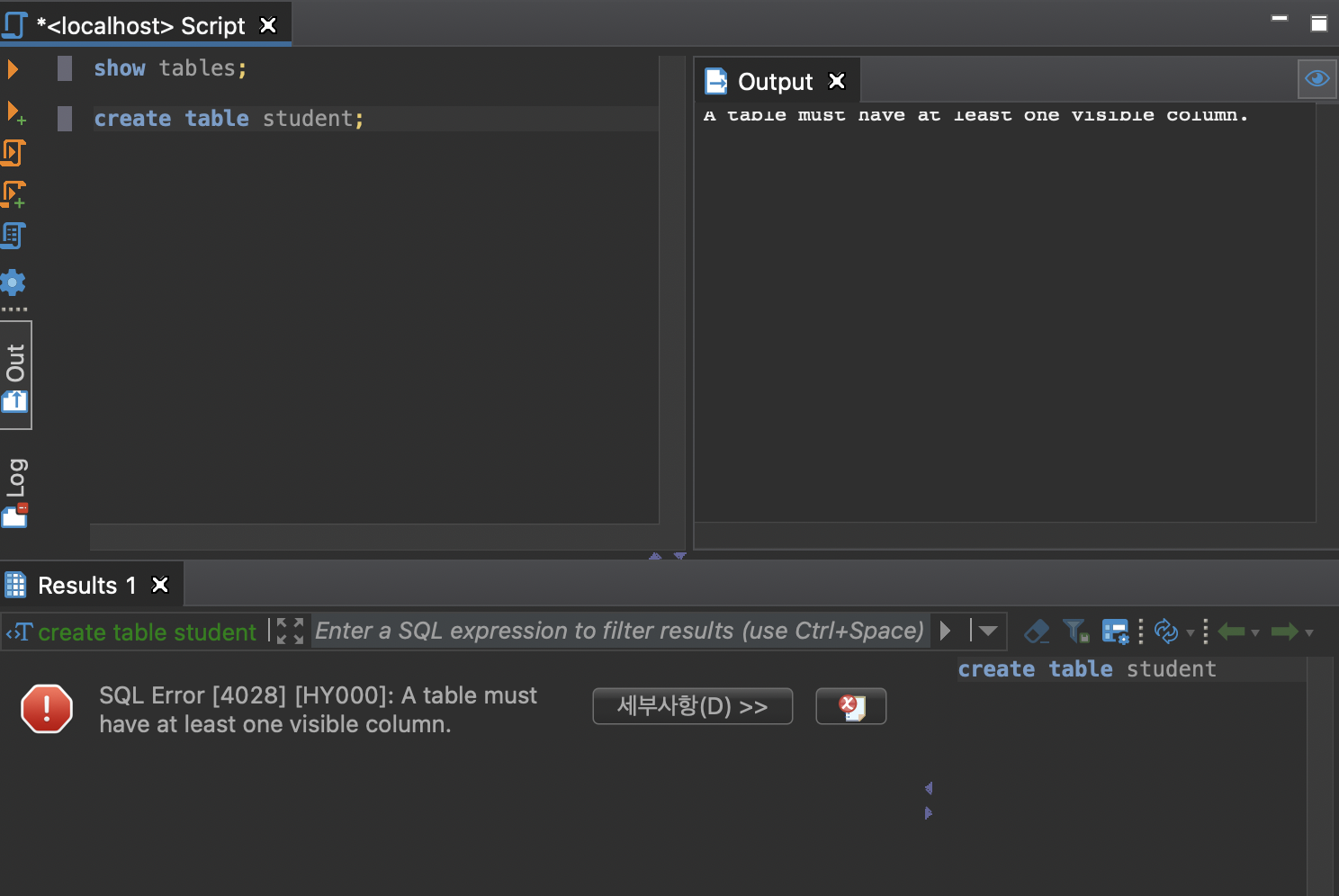
테이블은 데이터의 명세서로각각의 데이터가 어떤 이름으로 어떤 타입, 어떤 조건으로 입력되어야 되는지에 대해서미리 설정이 되어 있어야 한다.각각의 열은 유일한 이름을 가지고 있으며 자신만의 타입을 가지고 있을 수 있도록 설정이 되어 있어야 한다.따라서 각 테이블에 포함할
3.CRUD - 2
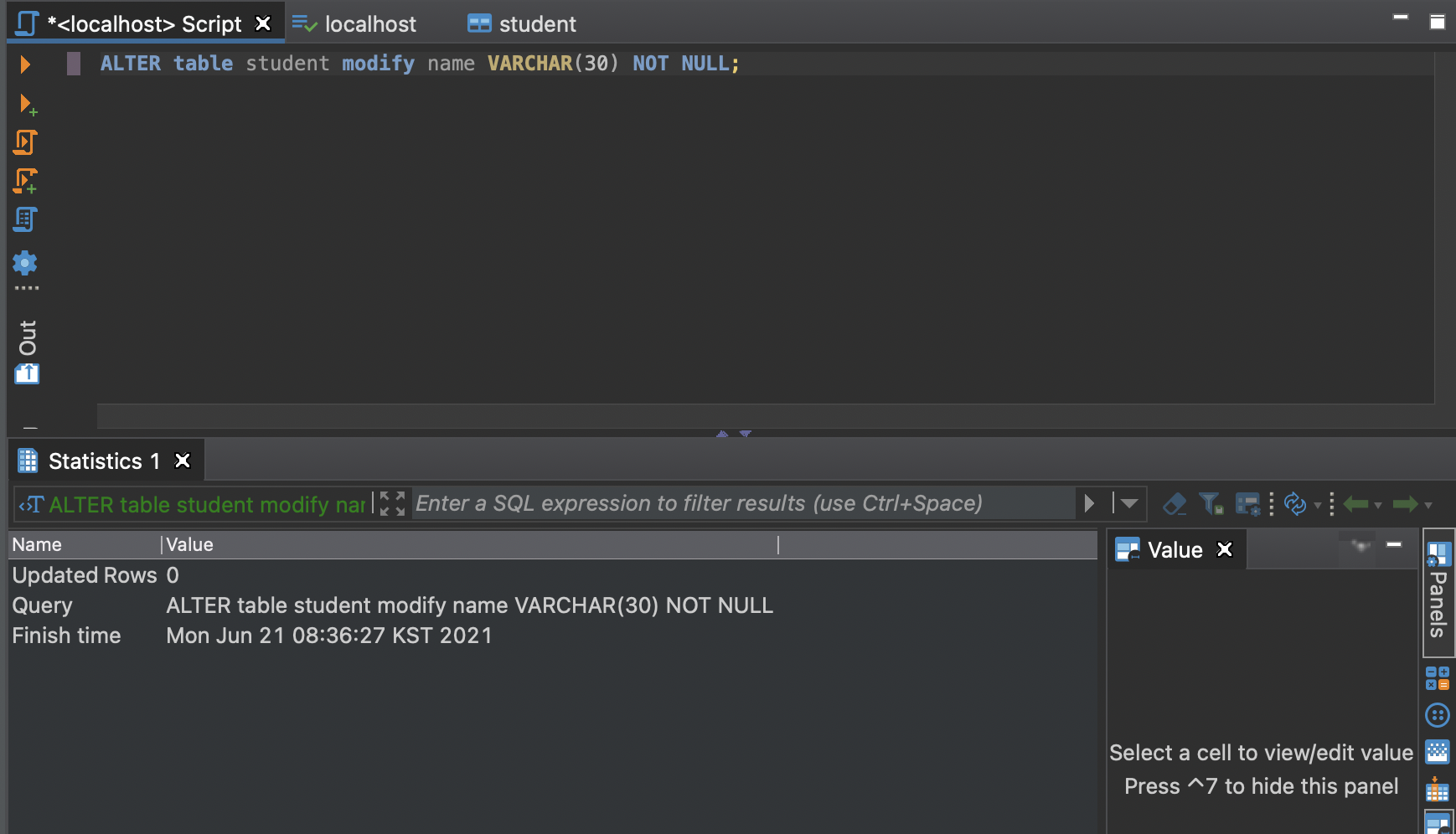
ALTER TABLEADD : 새로운 필드 추가DROP : 기존 필드 삭제MODIFY : 필드 타입 변경필드 타입이 바뀐걸 볼 수 있다.id나 number같은 필드는 자동으로 정수를 올려주면서 유일성을 보장해줘야 한다.따라서 인덱스(정수값)을 체크해서 자동으로 올려주는
4.인덱스
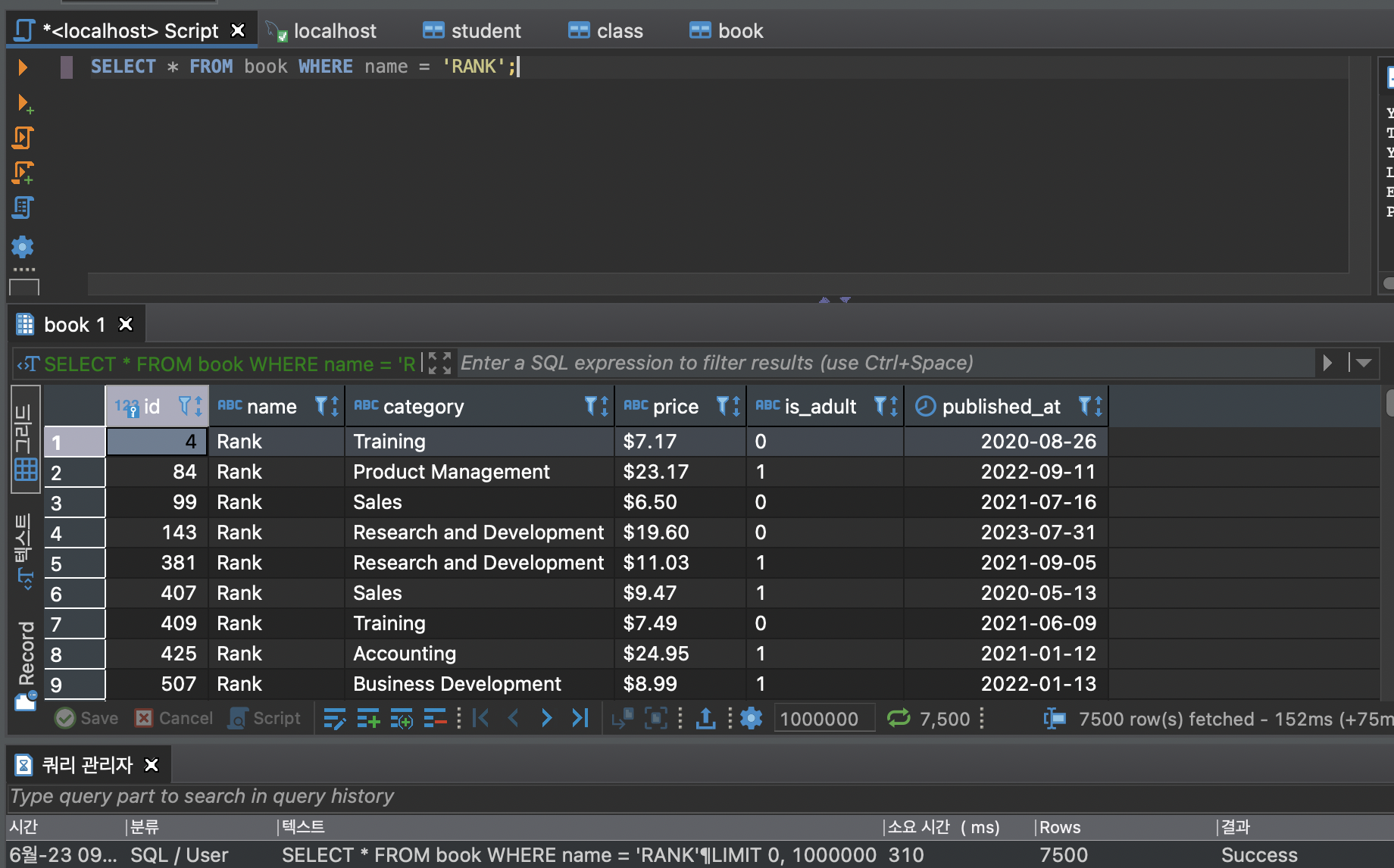
테이블의 전체 데이터를 모두 조회하는 것\-> full scan하지 않는 편이 좋다.인덱스 생성 명령어인덱스 생성 시 , 탐색 속도는 빠르지만 추가하는 속도는 느려진다.소요시간이 310 -> 136 으로 줄었다.두 가지 이상 칼럼을 대상으로 인덱스를 거는 것특별한 값의
5.트랜잭션
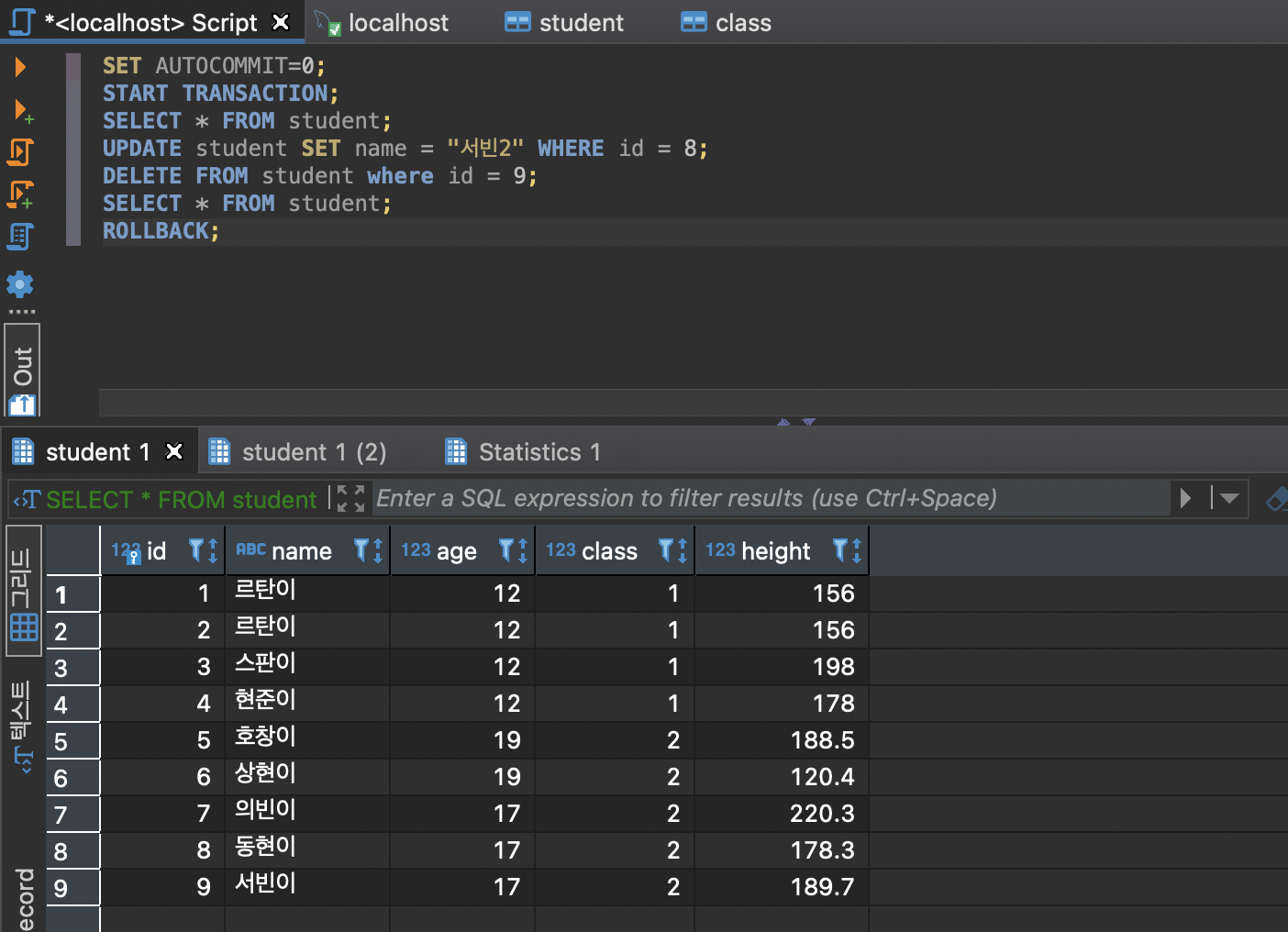
데이터베이스에 삽입, 수정, 삭제 등의 작업을 할 때여러 개의 작업들을 하나의 단위로 진행해야 하는 경우가 있다.개별적으로 수행되는 것이 아니라 묶어서 연산을 진행하고 싶은 겨웅에트랜잭션 사용.DBMS에서 데이터를 다루는 논리적인 작업의 단위(작업 단위를 여러개로 묶어
6.select 활용
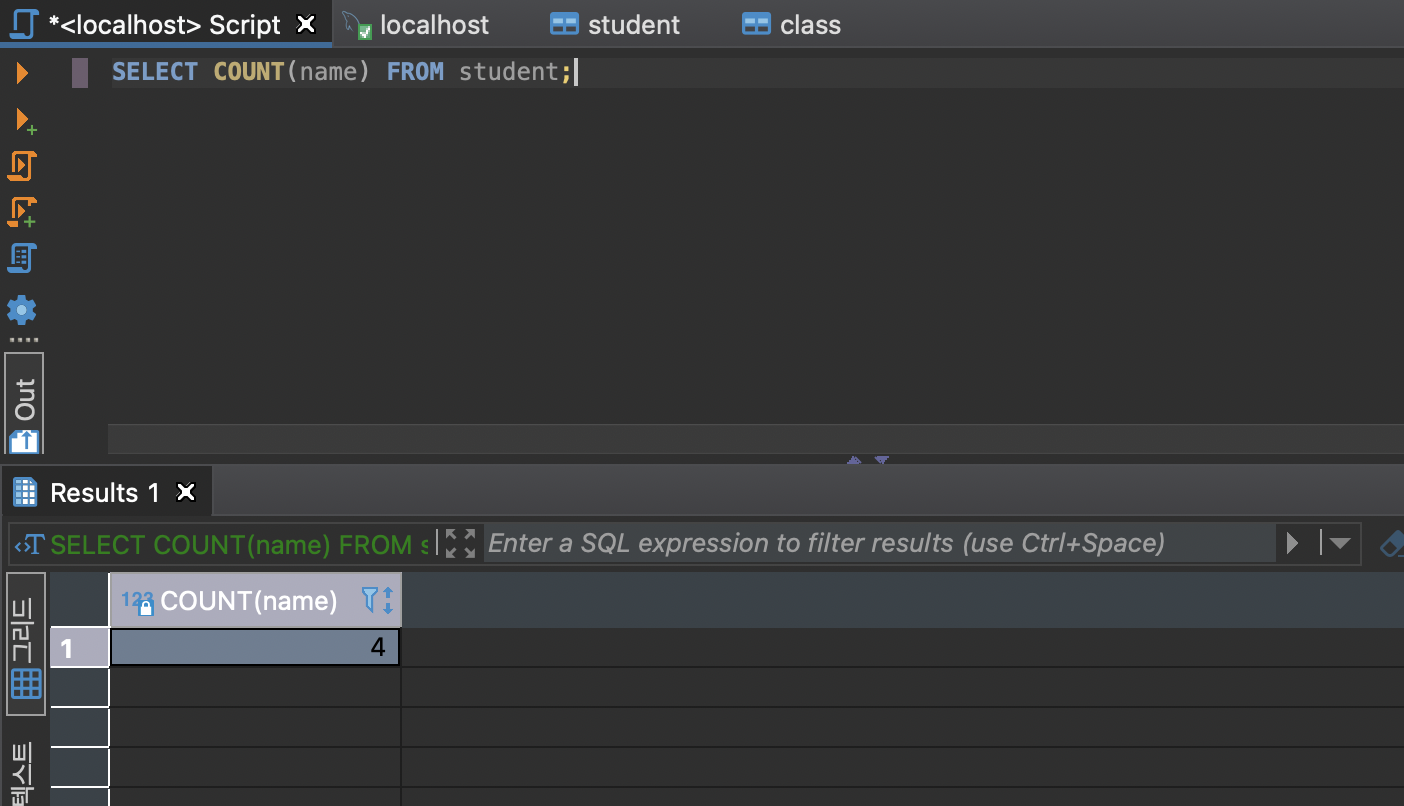
Distinct 중복되는 값 제거하는 방법 *를 입력하면 일일이 다 나오는데 왜 그러냐면, 지금 각각의 칼럼들이 모두 다 개별적으로 다르기 때문에 레코드들이 유일하다고 판단 될 수 없어서 개별적으로 값이 나온다.라고 생각 할 것 Aggregate 그룹 함수 co