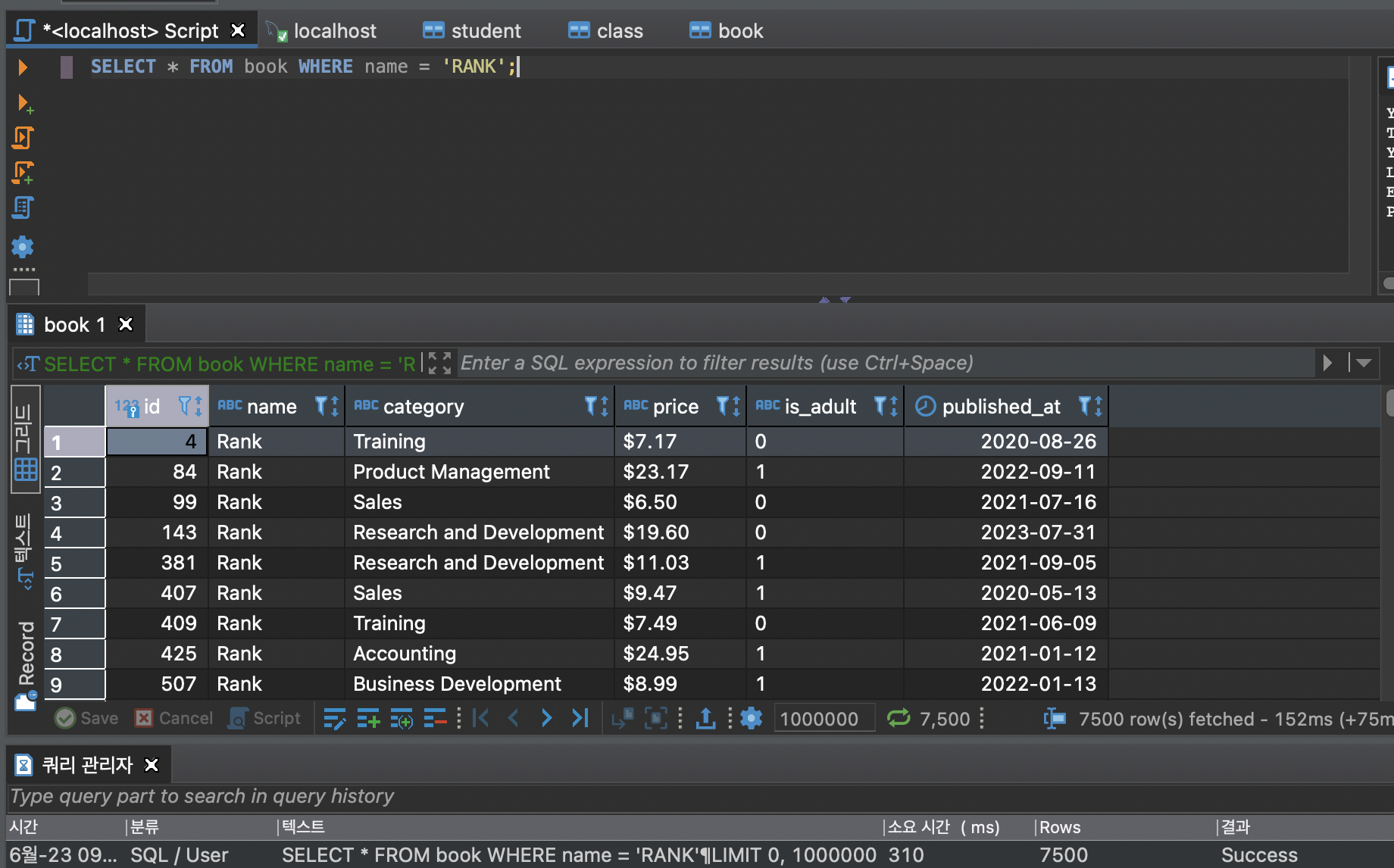
테이블의 전체 데이터를 모두 조회하는 것
-> full scan
하지 않는 편이 좋다.
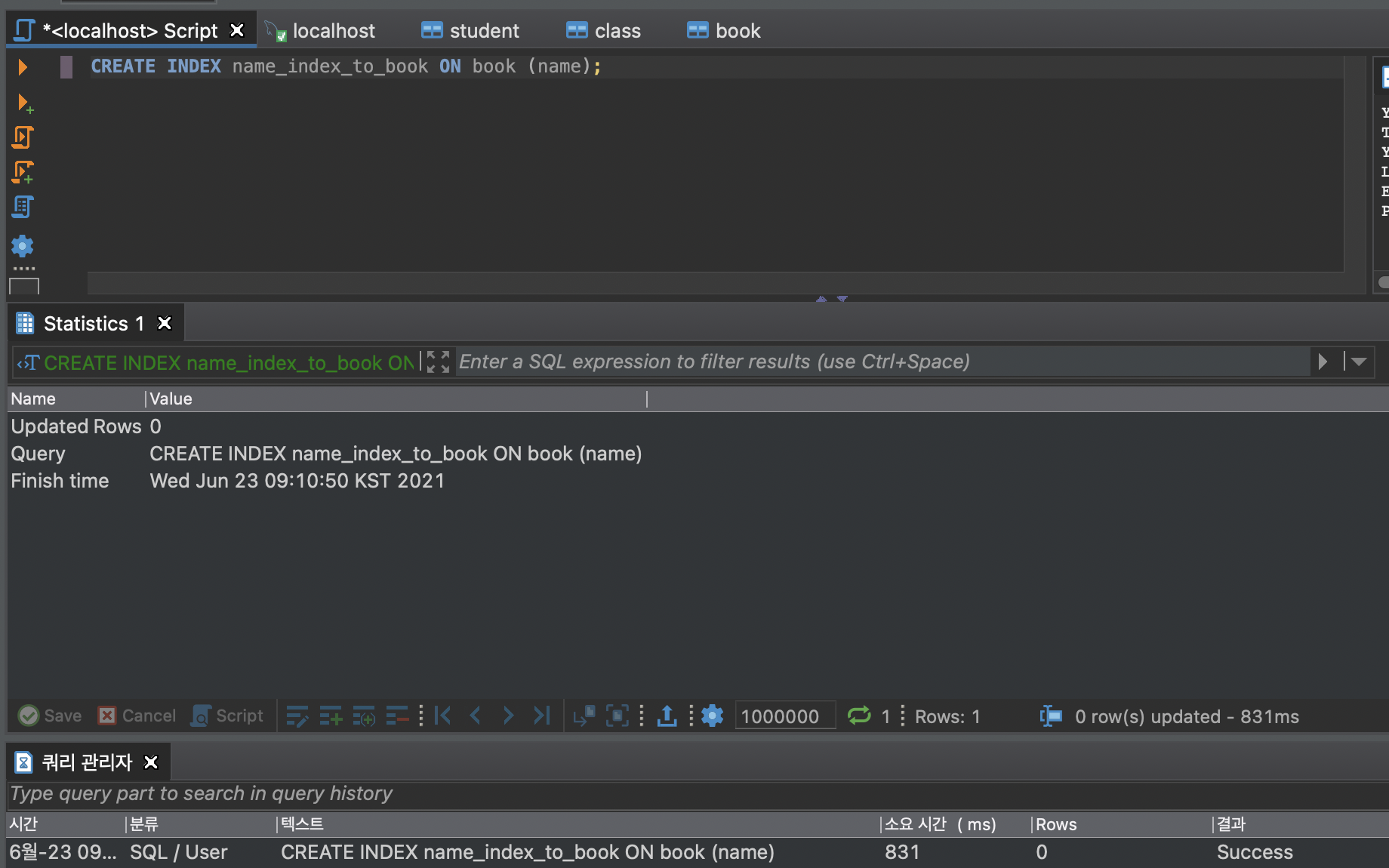
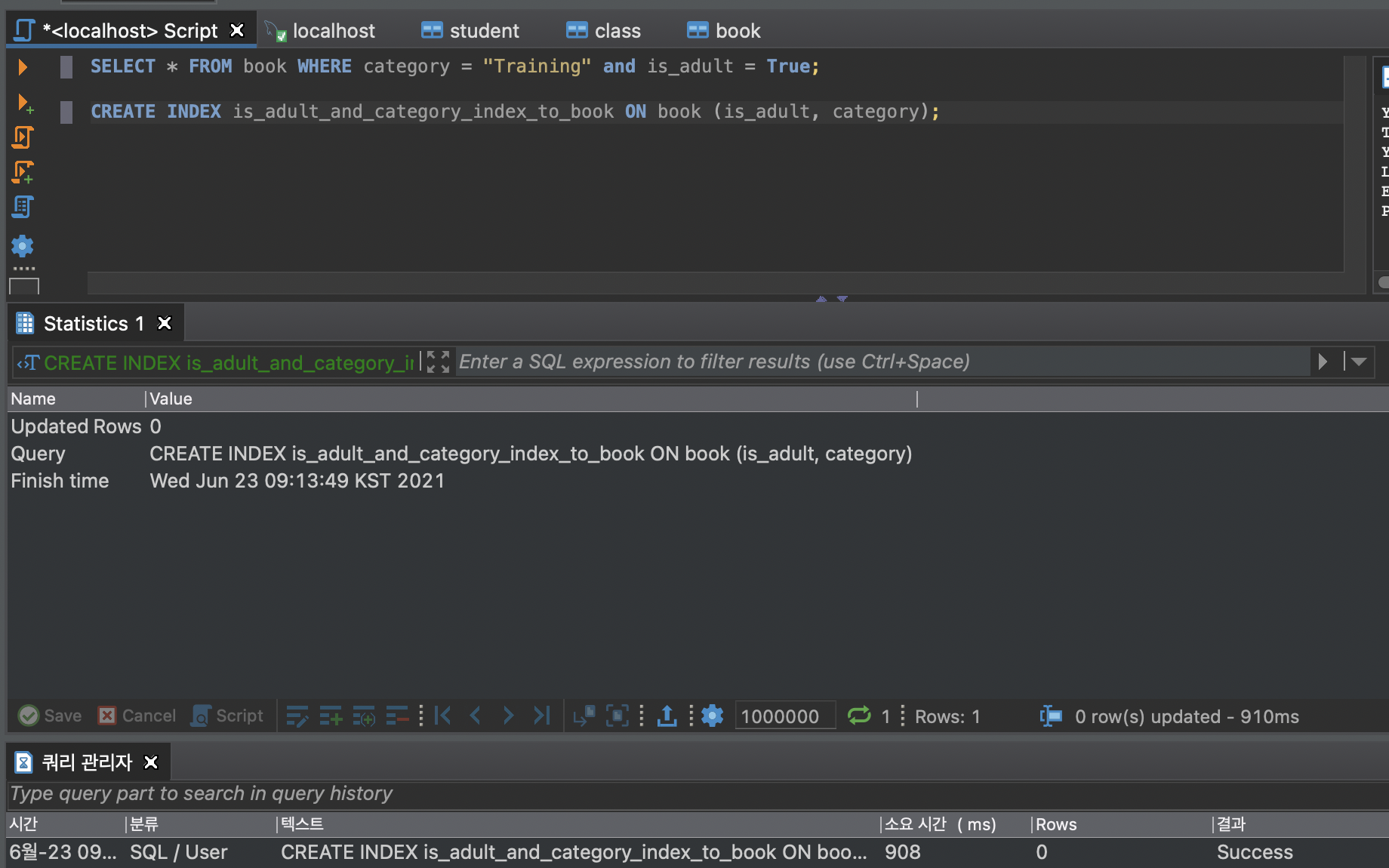
create index (index_name) on (table_name) (table_column_name);인덱스 생성 명령어
인덱스 생성 시 , 탐색 속도는 빠르지만 추가하는 속도는 느려진다.
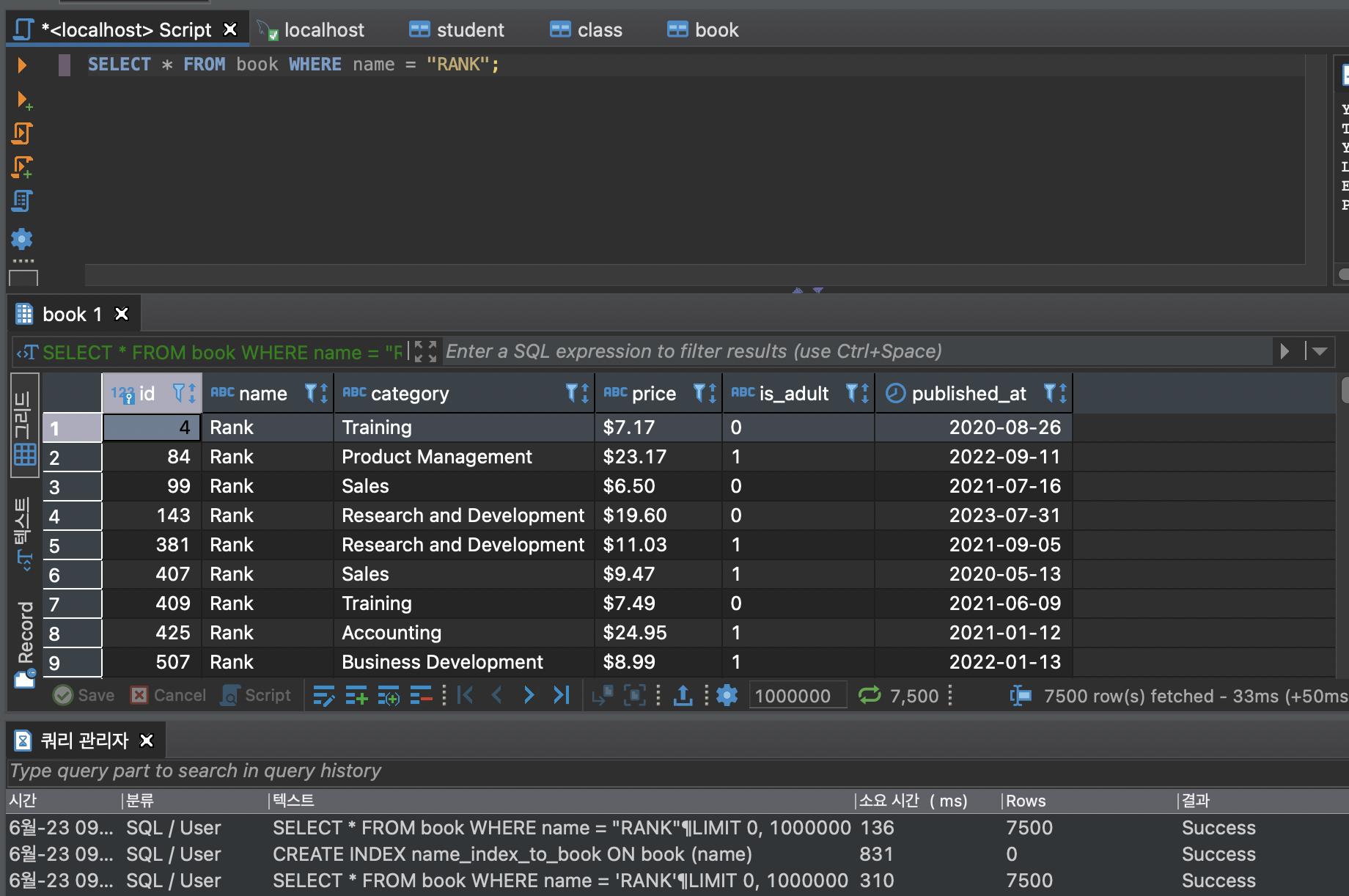
소요시간이 310 -> 136 으로 줄었다.
복합 인덱스
두 가지 이상 칼럼을 대상으로 인덱스를 거는 것
특별한 값의 종류가 많은 칼럼을 우선으로 복합 인덱스를 세워야
빠른 데이터 탐색이 가능하다
create index (index_name) on (table_name) (table_column_name1, table_column_name2);특별한 값의 종류를 전문 용어로 Cardinality(카디널리티)라고 한다.
테이블의 행 수에 상대적인 테이블 열의 고유 값 수를 의미.
즉, 값의 중복이 적으면 카디널리티가 높다.
(고유한 것들이 많아져서)
반대로 중복이 많으면 카디널리티가 낮다.
-> 카디널리티가 높을 수록 인덱스 설정에 좋은 컬럼
(중복 정도가 낮을 수록 분류하기 좋아서)
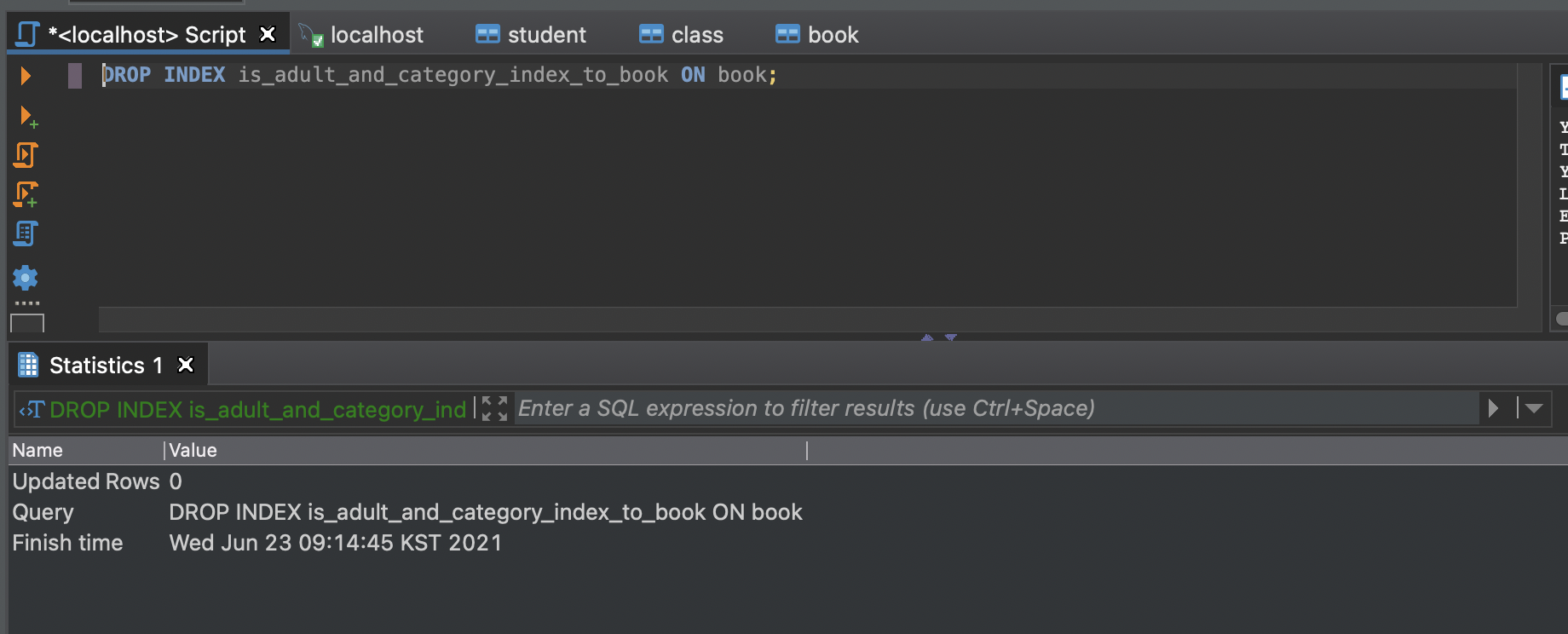
drop index (index_name) on (table_name);인덱스 삭제 명령어
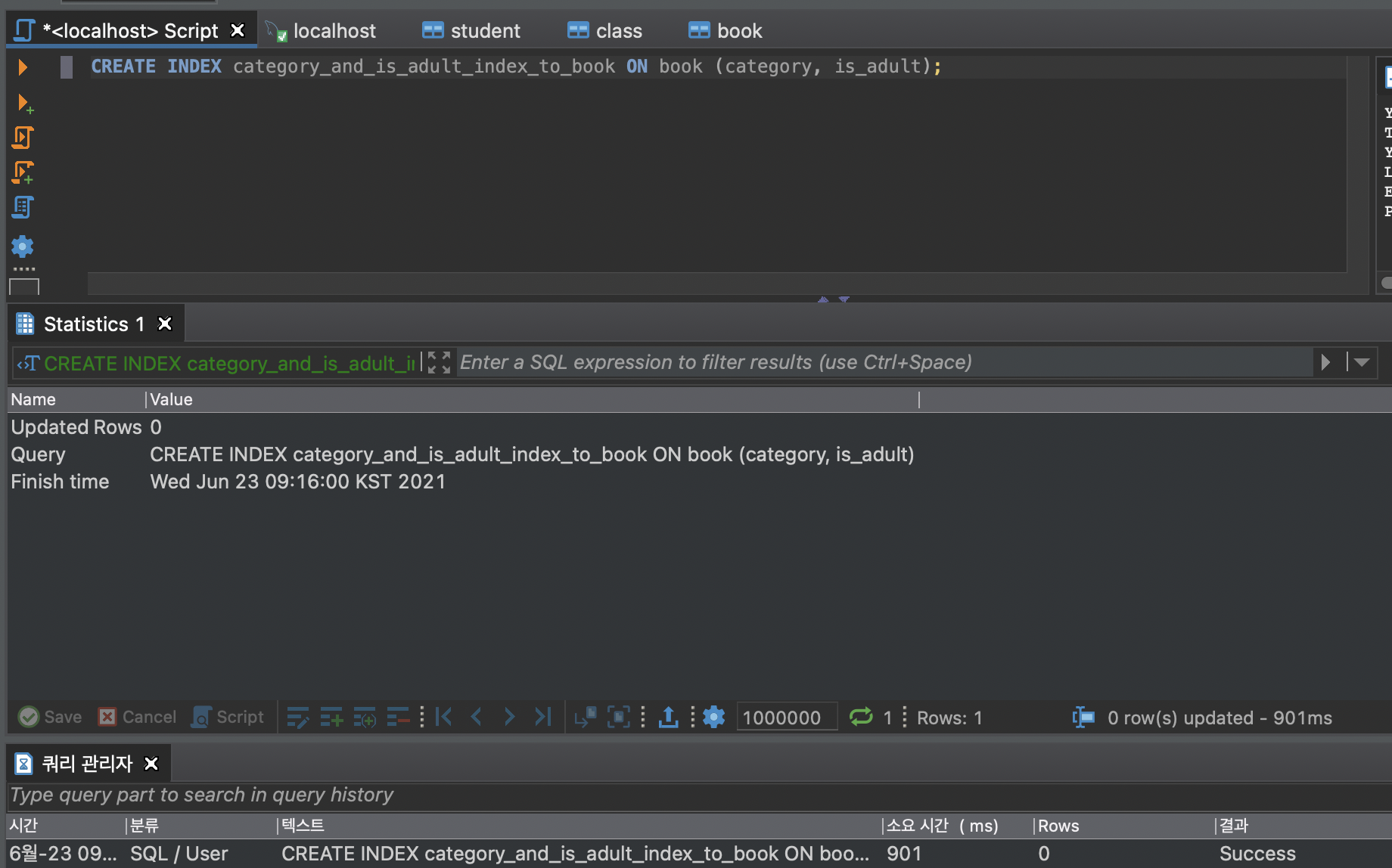
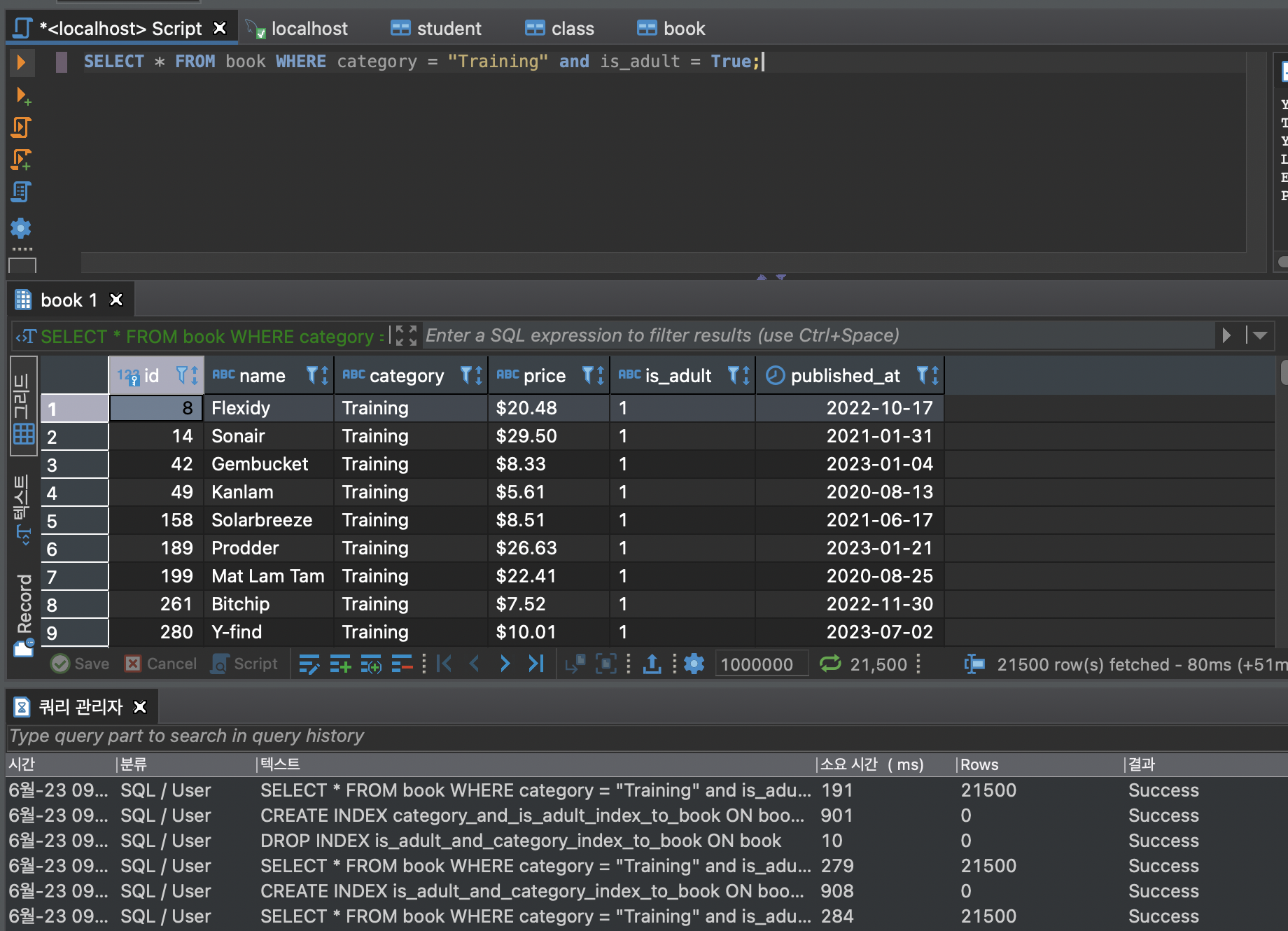
소요시간이 줄었음을 확인할 수 있다.
인덱스의 실제 구현은 대게 B-Tree 계열 인덱스를 사용하고
데이터 포인터를 리프(Leaf) 노드에 저장한다.
- B-Tree : 다수의 키를 가진 노드로 구성되어 다방향 탐색이 가능한 트리.
( 이진 트리가 자식 노드가 최대 2개인 노드를 말하는 것이라면 B-Tree는 자식 노드의 개수가 2개 이상인 트리를 말한다. )
- 리프노드(Leaf Node) : 자식이 없는 노드. 잎이라고도 한다.

과연 나는 ?