
드디어 웹 스크랩핑을 도전해보았다.
node.js와 찰떡이라는 구글에서 제공하는 라이브러리인 puppeteer(퍼펫티어)를 사용하였다.
퍼펫티어 설치 .. 등에 관련해서는 다른 벨로그들에 많이 나와있으니 스킵하고!
내가 이번에 스크래핑에 도전하면서 어려웠던 점 위주로 써보려고 한다.
먼저 내가 이번에 스크래핑에 도전한 데이터는 명품 가구 브랜드 FritzHansen의 조명 상품 정보였다.
처음에 만만하게 봤다가, 사이트가 아주 다이나믹하게 움직여서 ㅜ 나중엔 거의 울면서 계속 고치면서 했다.. (실제로 울지는 않음)
스크래핑 시 중요한 점
- 코드에 관해서는 2탄에 쓸 예정이고.. 스크래핑을 고민을 해야하는 것 3가지를 얘기해보고 싶다.
1. 내가 원하는 화면까지 가는 방법
- 사이트에 접속하게 되면 생각보다 쿠키동의, 언어 설정 등 나를 방해하는 것들이 많다.
- 이 것들을 초기에 올바르게 세팅해놔야 내가 원하는 정보가 정확하게 뜬다.
예를들어, 나는 상품의 가격이 EUR로 궁금한데
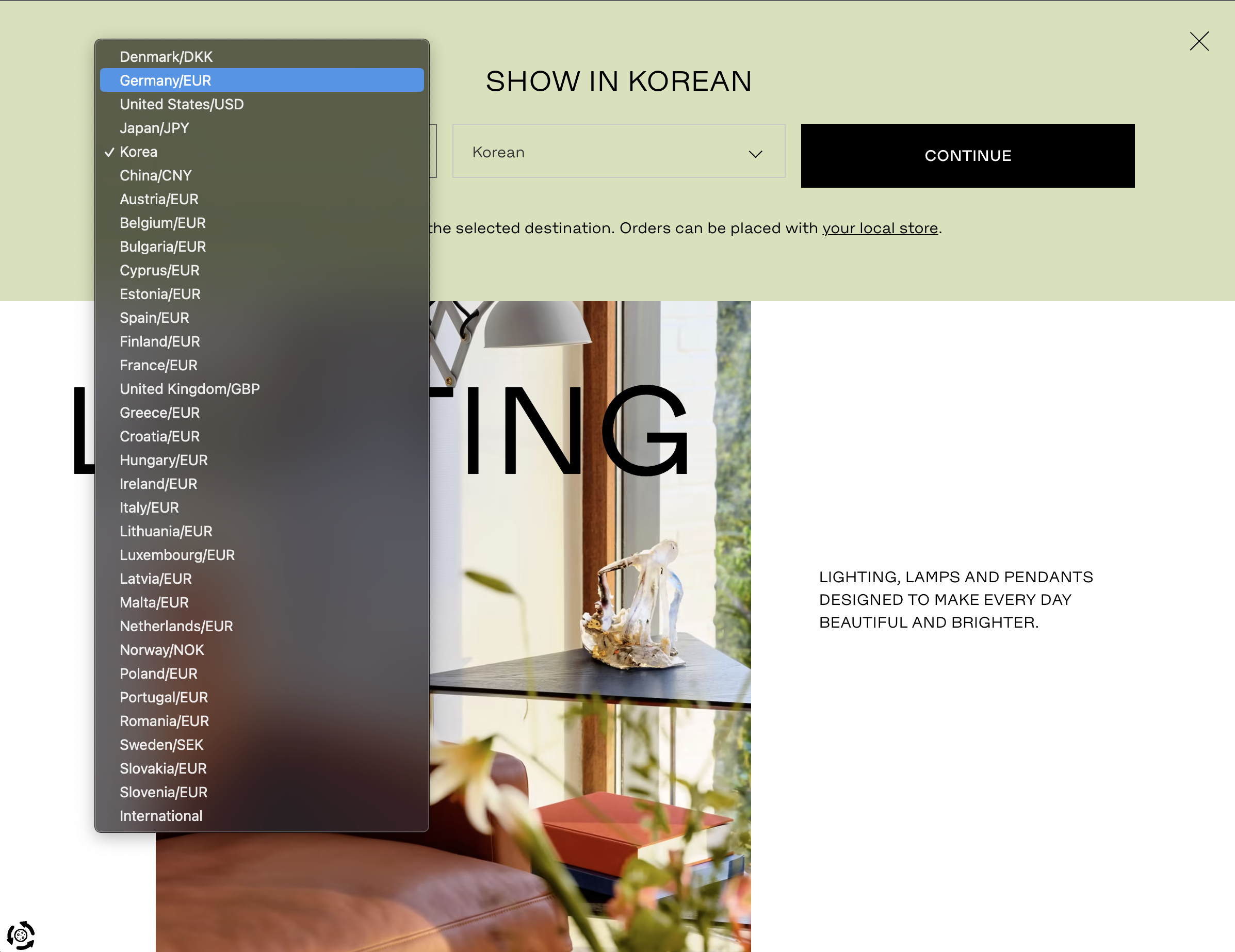
select - option을 EUR로 설정하지 않으면 가격이 뜨지 않았기 때문에, 이 조작 또한 필수 사항이었다.
- 그외에 본 사이트의 조작을 방해하는 팝업창 등등을 다 꺼줄 수 있어야 한다.
- 시크릿 모드에서 먼저 확인 해보는 것이 정확할 듯!
2. 사이트의 구조를 파악하기
- 자 상품 리스트 까지 어떻게 갔다고 치자! 그러면 페이지의 구조를 잘 파악해야 한다.
- 내가 도전한 사이트를 예시로 보면
-
상품 리스트에 모두 다 다르게 생긴 상품들이 있고
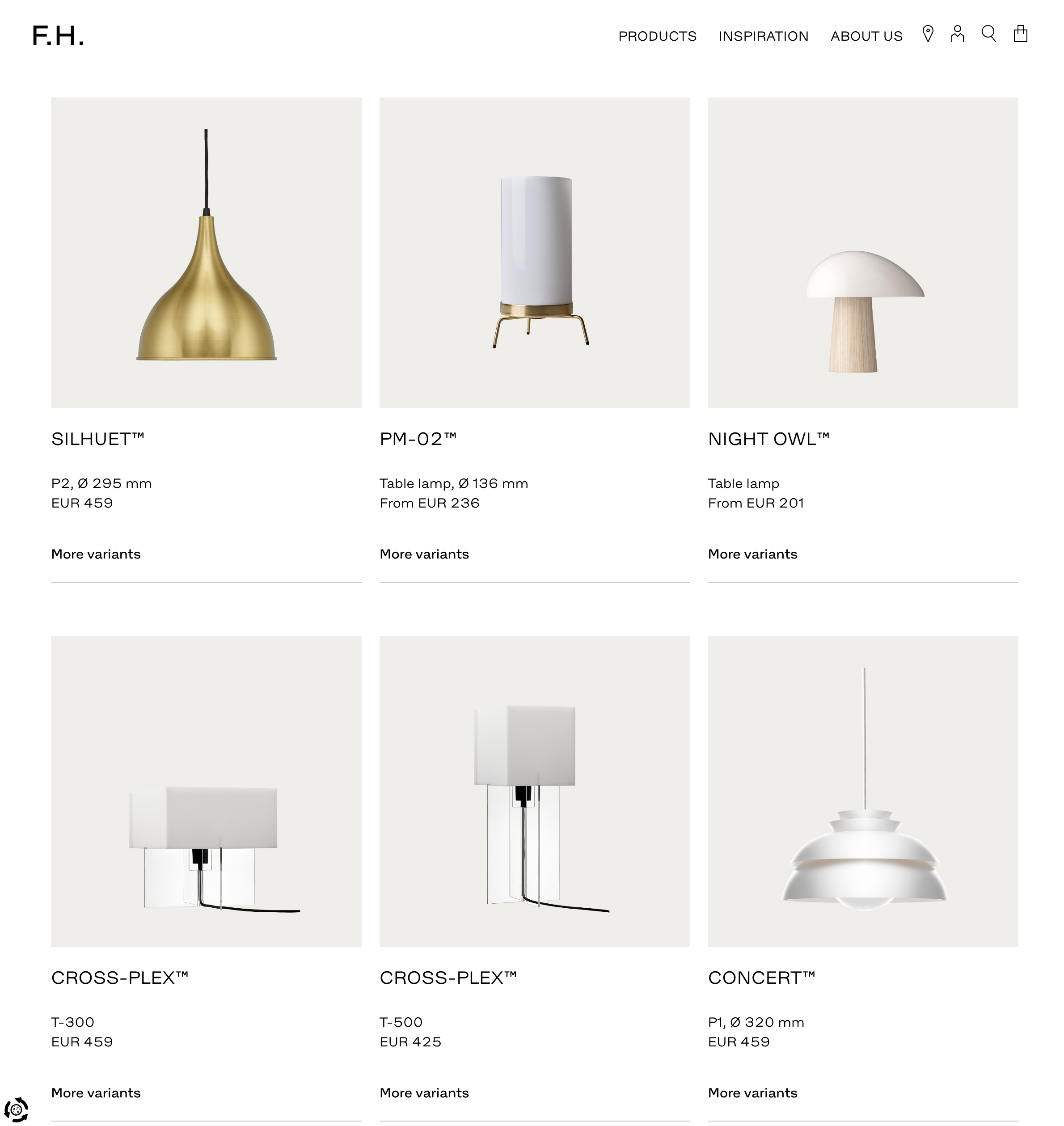
-
상품 카드를 선택하여 상세페이지에 들어가면 색상을 고를 수 있게 되어있다.
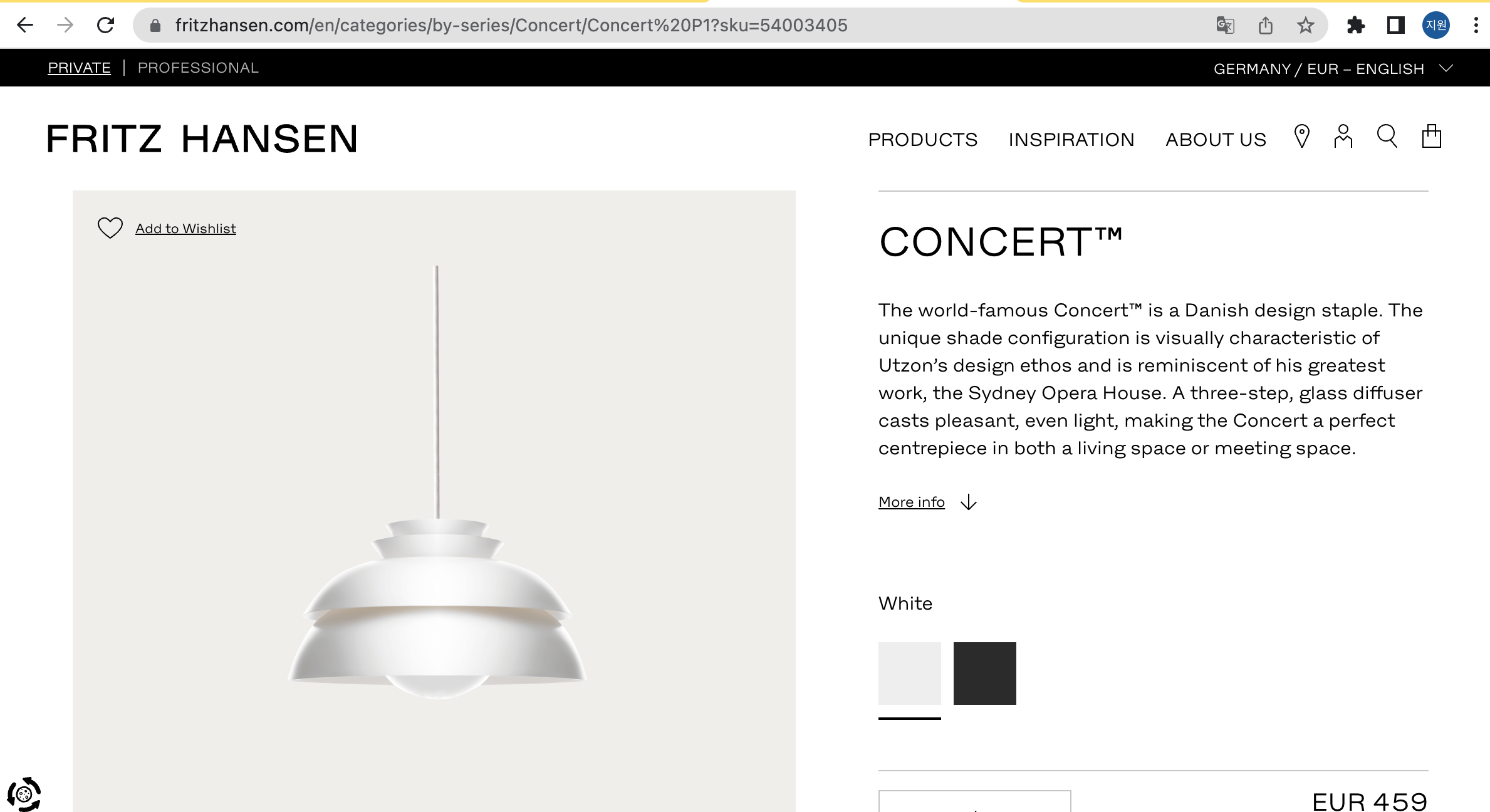
-
색상에 따라 url 주소의 sku= 이부분 뒤의 숫자가 바뀐다. 그렇다면 같은 종류의 상품의 경우 이 sku number로 색상 variation을 구분해야겠꾼. 이라고 생각할 수 있다.
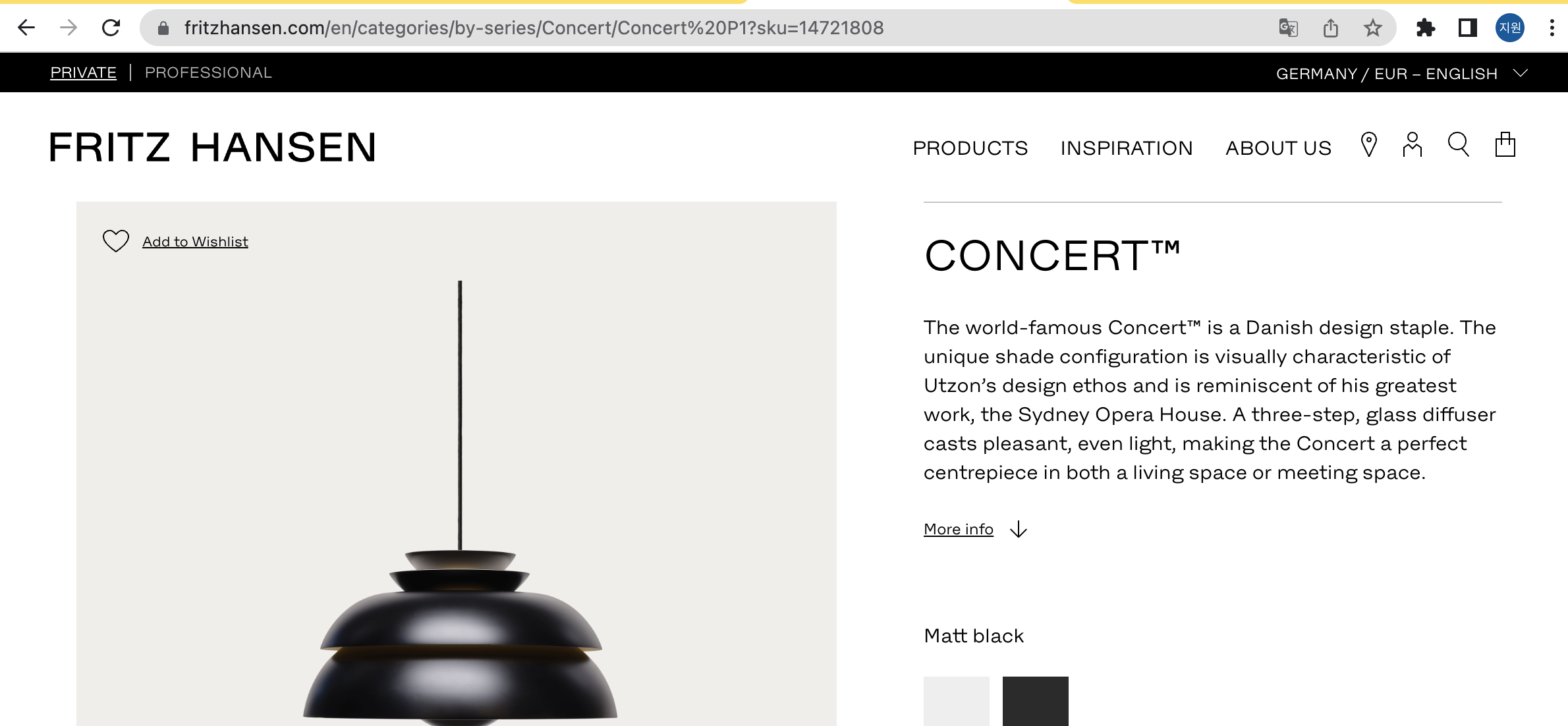
-
그리고 좀 아래로 내려보면 이러한 상세정보들이 있군! 쟤네 아코디언 메뉴들을 다~ 열어서 정보를 긁어봐야지
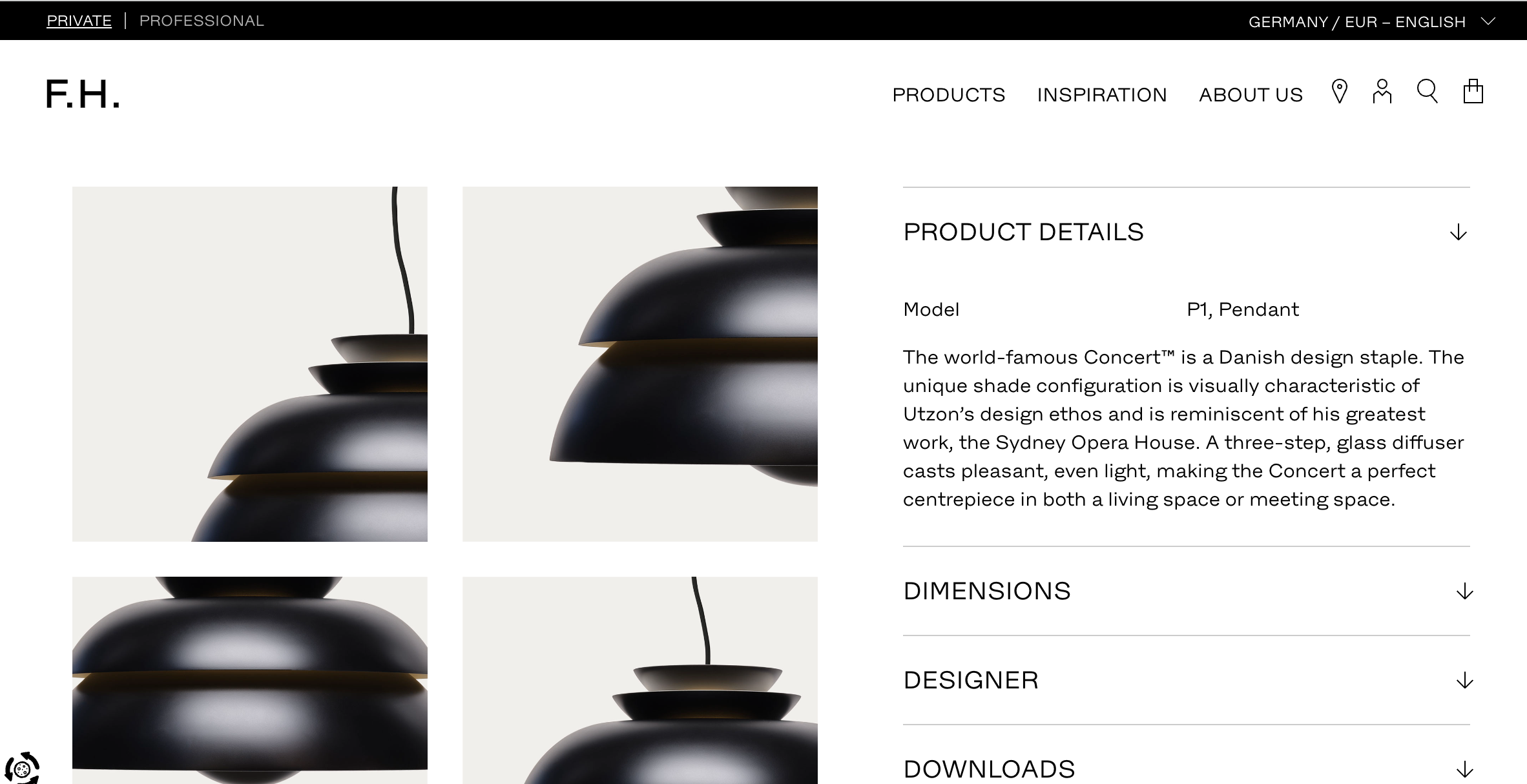
- 물론 정보를 다 긁어오는게 목적이지만, 이 정보들에 대한 데이터 구분은 그 브랜드가 한거고, 나는 이 각각의 정보를 어떻게 쓸지도 고민해봐야 한다.
3. 정확한 셀렉터를 사용하기
- 상품을 클릭할때 보통 셀렉터를 사용하여 클릭하게 되는데 그 셀렉터를 어떻게 쓰느냐에 따라 정확한 스크래핑이 되느냐 마느냐 차이가 생긴다!
- 나같은 경우에는 처음에는 nth-child 등을 사용하였는데..
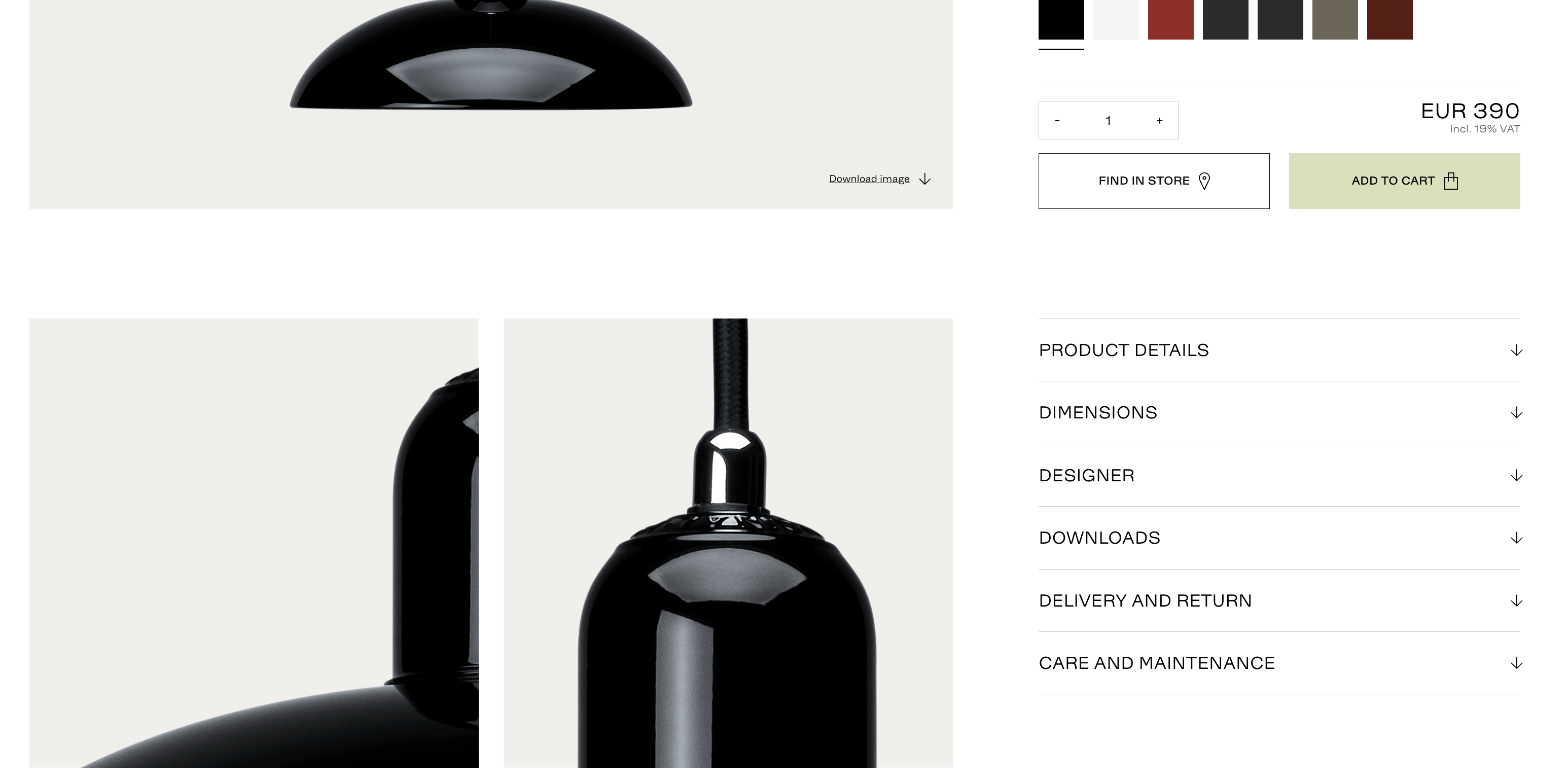
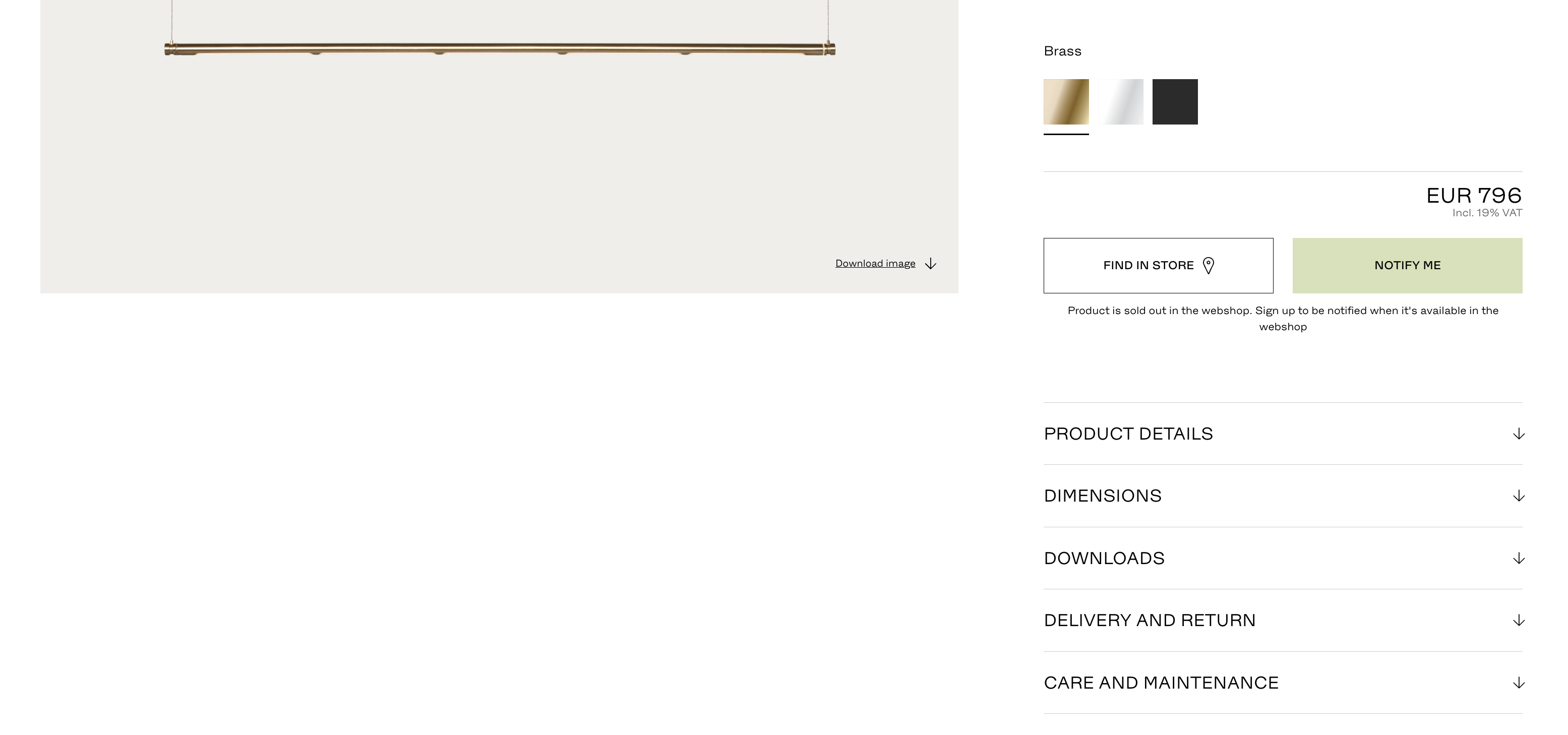
- 두 상세정보 메뉴들을 보면, 아래의 것은 designer 메뉴가 없다. 동일한 nth-child를 클릭하게 되면 아래 상품은 downloads가 열리게 되어 순서가 꼬이기 시작한다.
- 이럴때에는 nth-child를 사용하면 안되고, "designer"라는 text를 포함하는 tag를 선택하는 방식이 좋다.
- 그래서 상세정보를 다룰 땐 xpath를 사용하였다!
스크래핑 시작 전 사이트를 이해하는 방법에 대해서 써봤다.
처음 도전해본 스크래핑이라 시행착오가 많았던 터라 시간은 오래걸렸지만, 그래도 진짜 자바스크립트의 정석.. 을 다시 경험하는 느낌이었고 나중에 성공했을 때는 매우 뿌듯+기쁨!!!
스크래핑 시 자주 사용하는 method!
에 대해서는 2탄에 이어서 쓰겠습니다 ! 😏😏😏
