2022.12.27
딥러닝 파이토치 교과서 스터디
벨로그 첫 작성
벨로그-사용법-튜토리얼
https://velog.io/@coca970105/%ED%8C%8C%EC%9D%B4%ED%86%A0%EC%B9%98-%EC%BD%94%EB%93%9C-2.4
머신러닝과 딥러닝 비교
| 구분 | 머신러닝 | 딥러닝 |
|---|---|---|
| 동작원리 | 신경망 사용하여 데이터 특징 및 관계 해석(사람이 입력데이터 특징 추출 처리해줘야함) | 입력데이터에 알고리즘을 적용하고 예측 |
| 재사용 | 다양한 알고리즘 사용 & 데이터 분석을 위한 데이터 재사용 불가능 | 데이터 분석을 위해 재사용 |
| 데이터 | 수천개 데이터 필요 | 수백만 개 이상의 데이터 필요 |
| 훈련시간 | 단시간 | 장시간 |
| 결과 | 일반적으로 점수 또는 분류 등 숫자값 | 점수, 텍스트, 소리 어떤 것이든 가능 |
딥러닝
- 지도학습
1.CNN( 이미지 분류, 이미지 인식, 이미지 분할 )
2.시계열 데이터는 보통 순환 신경망 RNN으로 사용 -> 개선시켜서 LSTM 사용
- 비지도학습
1.워드임베딩 : 자연어 처리에서 주로 사용. 워드를 컴퓨터가 이해할 수 있도록 자연어로 변환하는 것이 필요. 따라서 단어를 벡터로 표현한다. Word2Vec, GloVe 많이 사용
2.군집: 아무런 정보가 없는 상태에서 데이터 분류하는 방법. 클러스터로 나눠서 사용
파이토치
- 텐서
import torch
print(torch.tensor([[1,2],[3,4]]))
print('------------------------')
print('------------------------')
print(torch.tensor([[1,2],[3,4]], dtype=torch.float64))
temp = torch.FloatTensor([1, 2, 3, 4, 5, 6, 7])
print(temp[0], temp[1], temp[-1])
print('------------------------')
print(temp[2:5], temp[4:-1])출력
tensor([[1, 2],
[3, 4]])
------------------------
------------------------
tensor([[1., 2.],
[3., 4.]], dtype=torch.float64)
tensor(1.) tensor(2.) tensor(7.)
------------------------
tensor([3., 4., 5.]) tensor([5., 6.])- 텐서 -1의 의미, 텐서 차원 조작
temp = torch.tensor([
[1, 2], [3, 4]
])
print(temp.shape)
print('------------------------')
print(temp.view(4,1))
print('------------------------')
print(temp.view(-1))
print('------------------------')
print(temp.view(1, -1))
print('------------------------')
print(temp.view(-1, 1))출력
torch.Size([2, 2])
------------------------
tensor([[1],
[2],
[3],
[4]])
------------------------
tensor([1, 2, 3, 4])
------------------------
tensor([[1, 2, 3, 4]])
------------------------
tensor([[1],
[2],
[3],
[4]])
-1은 ?와 같은 뜻도 된다. 해당 값을 유추하겠다는 건데, 4개 원소 가지고 (2,-1) 이러면은 (2,2) 만들어줌.
- torch.utils.data.DataLoader 객체는 학습에 사용될 데이터 전체를 보관했다가 학습때 배치 크기만큼 데이터를 꺼내 사용. 미리 자르는 것이 아니라 인덱스를 이용해서 배치 크기만큼 데이터를 반환하는 방식.
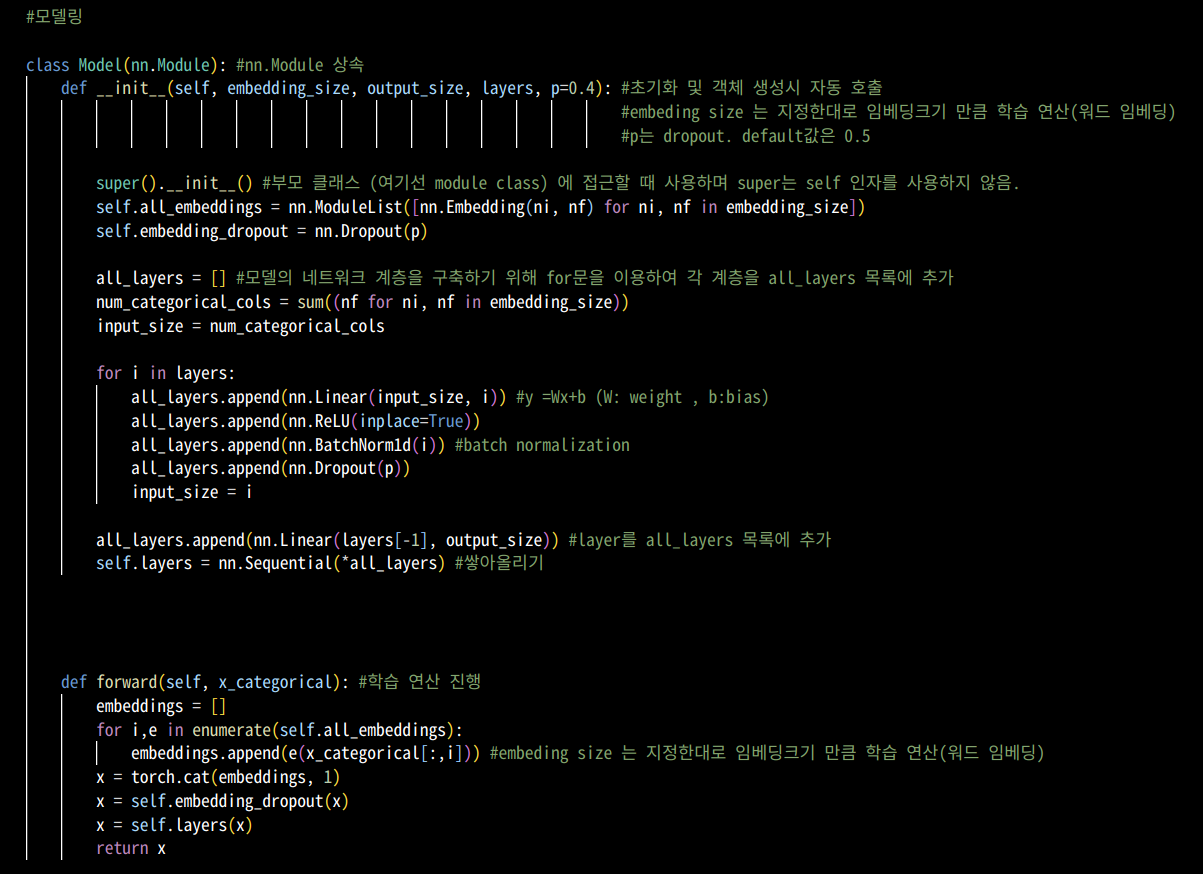
- nn.Sequential(parameter)은 파라미터 넣어서 모델을 쌓아올리는 방식. Sequential 외에도 함수로 정의하는 경우가 있다. 아래 차이를 확인해보자
Seqential 사용 코드
class MyNeuralNetwork(nn.Module):
def __init__(self):
super(MyNeuralNetwork, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=5),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
)
self.layer2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=30, kernel_size=5),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
)
self.layer3 = nn.Sequential(
nn.Linear(in_features=30*5*5, out_features=128, bias=True),
nn.ReLU(inplace=True)
)
self.layer4 = nn.Sequential(
nn.Linear(in_features=128, out_features=10, bias=True),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = x.view(x.shape[0], -1)
x = self.layer3(x)
x = self.layer4(x)
return x함수 사용 코드
class MyNeuralNetwork(nn.Module):
def __init__(self):
super(MyNeuralNetwork, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=64, out_channels=30, kernel_size=5)
self.fc1 = nn.Linear(in_features=30*5*5, out_features=128, bias=True)
self.fc2 = nn.Linear(in_features=128, out_features=10, bias=True)
def forward(self, x):
x = F.relu(self.conv1(x), inplace=True)
x = F.max_pool2d(x, (2, 2))
x = F.relu(self.conv2(x), inplace=True)
x = F.max_pool2d(x, (2, 2))
x = x.view(x.shape[0], -1)
x = F.relu(self.fc1(x), inplace=True)
x = F.relu(self.fc2(x), inplace=True)
return x
-
loss function을 이용해서 실제값과 예측 값 차이를 수치화를 함. 이때 오차가 적은 것을 목적으로 하기 때문에 값을 최소화하는 가중치와 bias값이 중요(Wx+b) --> 옵티마이저를 이용해 모델의 가중치 업데이트 방법을 결정! global minimum을 찾고자 한다.
-
backward train을 통해 가중치를 update하는데 이때 배치 사이즈만큼 가중치를 업데이트 한다. 예를 들어 100개 데이터, 배치 20이면 20개 마다 모델 가중치를 업데이트하고 총 5번을 업데이트. 에포크가 10번이면 50번 가중치가 업데이트 됨.
-
backward 할 때, optimizer.zero_grad() 를 수반. 오차가 중첩적으로 쌓이지 않도록 초기화를 해줘야 함. train 예시 볼 것.(57p) 검증 과정에서는 with torch.no_grad()를 사용한다. 테스트는 역전파가 필요하지 않아서 기울기 값 저장할 필요가 없기 때문.
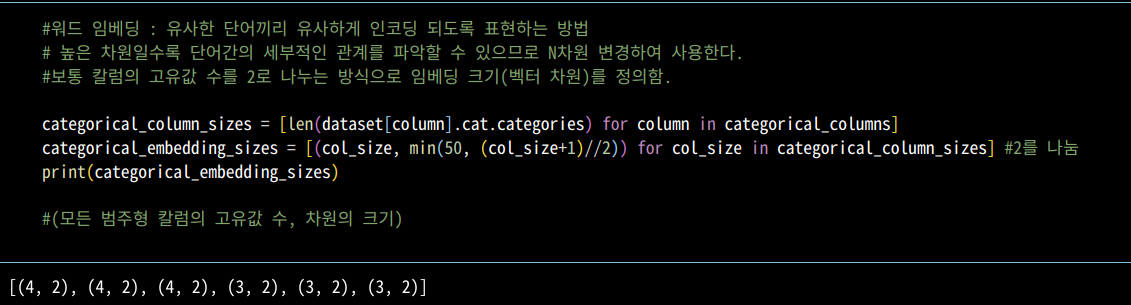
1. 데이터 전처리 (임베딩 과정 필요)
1_2. 범주형 데이터 -> 넘파이 배열 -> 텐서변환 및 차원 조작 -> 임베딩
2. 모델링
3. 임베딩 크기 할당(보통 칼럼 개수/2 크기로 함)
4. 테스트/트레인 데이터 분리 후 모델 학습 및 검정
5. 손실함수 -> 옵티마이저 -> 역전파 -> 가중치 수정
6. 추론
7. 정확도, 재현율, 정밀도, f1-score 등을 통해 정확도 수치를 표현