참고한 블로그
지도학습 (supervised)
- 정답 label 레이블값을 컴퓨터에 미리 알려주고 데이터를 학습시키는 방법
- 분류 및 회귀 문제에서 적용될 수 있음
분류 문제
1. K-nearest neighbor k-최근접 이웃 방식
: 새로운 데이터를 받았을 때 기존 클러스터에서 모든 데이터와 인스턴트 기반 거리를 측정한 후 가장 많은 속성을 가진 클러스터에 할당하는 분류 알고리즘 방식, K값에 따라 분류 결과가 달라질 수 있음!
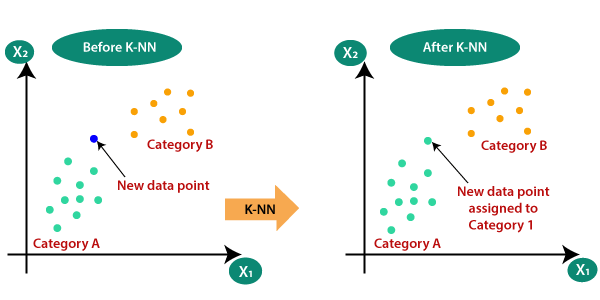
New data point가 카테고리로 묶이는 방식으로 분류한다.
2. SVM(Support Vector Machine) 방식
:기준선을 정의하는 모델인데 새로운 데이터가 나타나면 기준선의 어느 쪽에 속하는지 분류하는 모델이다.
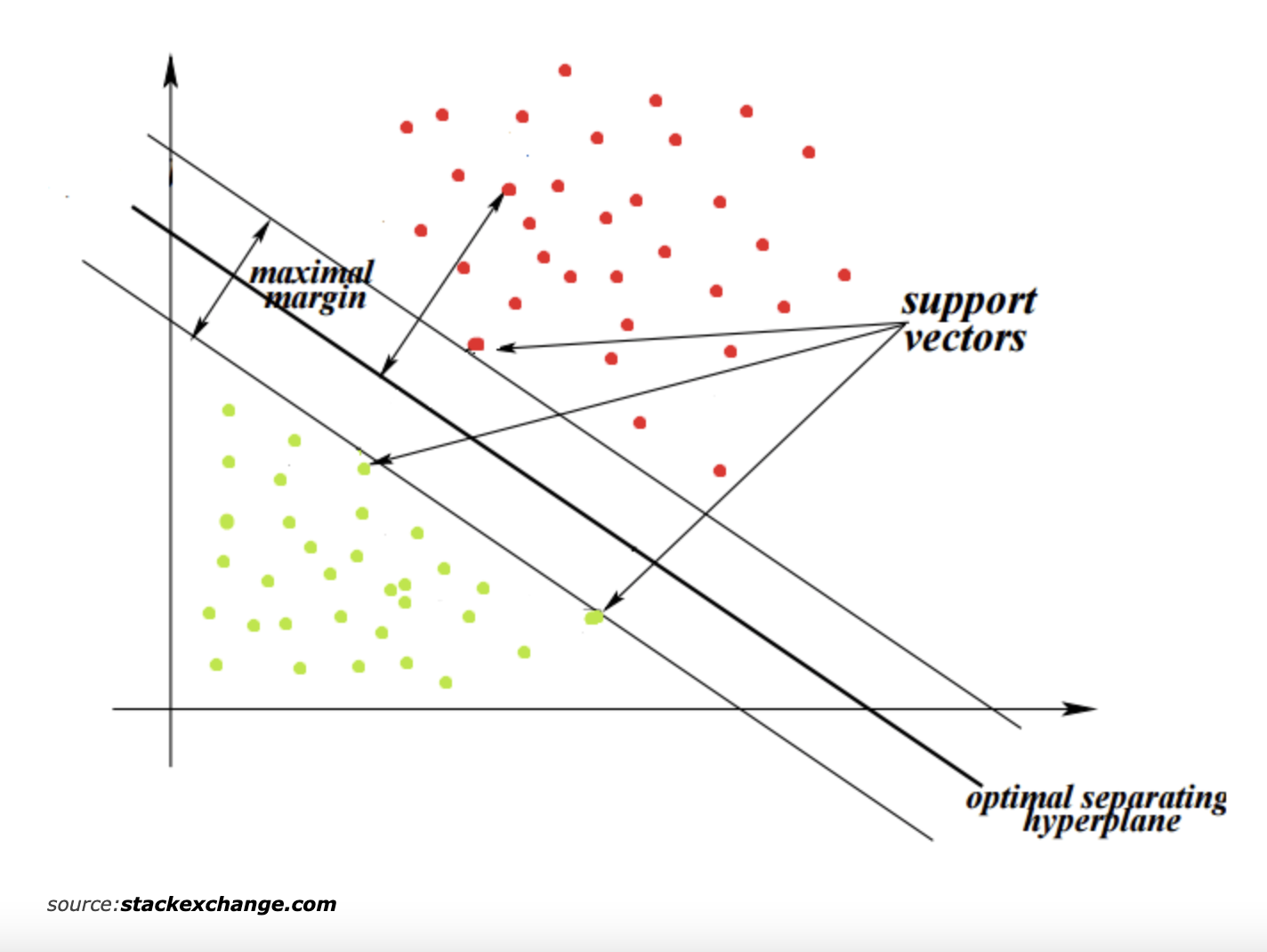
기준선과 서포트 벡터 사이의 거리를 Margin 마진이라고 하는데, 최적의 기준선은 마진이 최대일 때의 선을 말한다. 위 사진처럼 기준선이 세개인데 그 중 가운데 선이 제일 최적이라고 말할 수 있다. 결정 경계, 즉 기준선은 데이터가 분류된 클래스에서 최대한 멀리 떨어져 있을 때 성능이 좋다
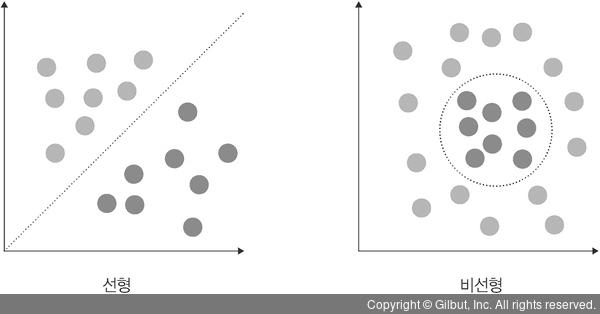
SVM은 선형과 비선형 분류를 지원하는데, 비선형 데이터를 처리하는 기본적인 방법은 저차원 데이터를 고차원으로 보내버린다 하지만 이것은 많은 수학적 계산이 필요. (비선형은 보통 고차원 수학 연산이 필요하다)
이러한 문제를 해결하고자 Kernel trick 커널 트릭을 이용하는데 선형 모델을 위한 커널은 선형 커널, 비선형 모델을 위한 비선형 커널은 가우시안 RBF 커널과 다항식 커널이 있다. 이 둘이 벡터 내적을 계산하고 고차원으로 보내는 방식으로 연산량을 줄인다.
3. 결정 트리, 랜덤 포레스트 방식
: 데이터를 분류하거나 결괏값을 예측하는 분석 방식.
-
순도, 불순도, 불확실성, 정보 획득(information gain) 지표를 이용
-
Entropy 엔트로피는 확률 변수의 불확실성을 수치로 나타낸 것으로 높을수록 불확실성이 높다는 것. 순도가 최소라는 의미다. 우리의 목표는 순도를 높이고 불순도와 불확실성을 낮춰야 한다.
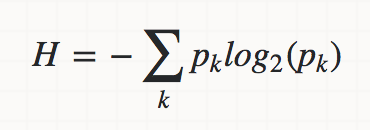
엔트로피 공식인데, image를 다룰 때 image의 entropy가 높을수록 image contents가 많다고 해석할 수 있다.
-
Gini index 지니 계수는 불순도를 측정하는 지표인데 데이터의 통계적 분산 정도를 정량화해서 표현
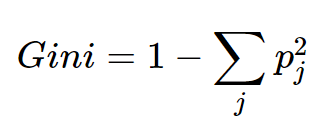
-
혼동 행렬을 통해 모델의 훈련도를 해석한다.

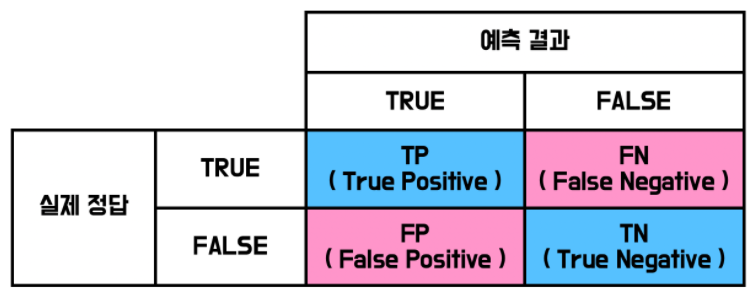
FP, FN보다 TP,TN이 높을수록 잘 훈련되었다고 판단. -
결정 트리를 여러 개 묶어놓은 것이 랜덤 포레스트 방식. Random forest 방식도 따로 게시글 정리하여 올릴 것
회귀 문제
1. 로지스틱 회귀
:로지스틱 회귀는 분석하고자 하는 대상들이 두 집단 혹은 그 이상의 집단으로 나눠질 때 어느 집단으로 분류될 수 있는지 분석, 예측하는 모델. 데이터에 대한 분류 결과에 확신이 없을 때 사용하면 유용
-
독립 변수(예측 변수)는 영향을 미칠 것으로 예상되는 변수로 보통 X input으로 간주된다. 종속 변수(기준 변수)는 영향을 받을 것으로 예상되는 변수로 보통 Y output으로 간주된다.
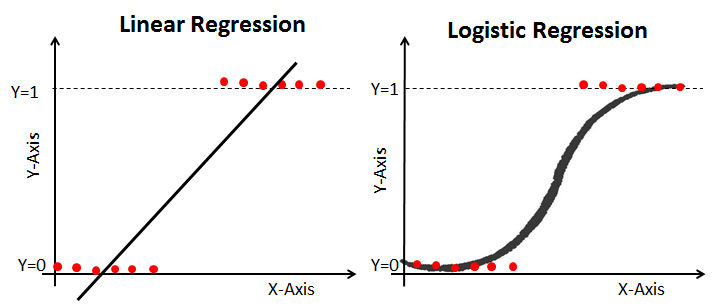
선형 회귀의 경우는 y=100x y가 1000인 경우 x는 10 과 같이 변수 값을 추정할 수 있는데다 y값이 0~1 범위를 초과할 수 있지만, 로지스틱 회귀는 집단에 속하는 확률의 추정치를 예측한다. cut-off(분류 기준값)을 정해놓고 그 미만이면 집단 0, 그 이상이면 집단 1로 분류한다.
-
MSE 평균제곱법, RMSE 루트 평균제곱법 공식을 이용해서 성능 판단.
2. 경사 하강법
3. Bias and Variance Trade-off
4. 로지스틱 말고도 Linaer and Nonlinear Regression
앙상블 학습
1. Bagging
2. Boosting
비지도학습 (unsupervised)
- 레이블이 필요하지 않으며 정답 없는 상태에서 훈련시키는 방식. 군집, 차원축소 방식이 있음.
군집화
1. K-means clustering K- 평균 군집화
: 레이블이 없는 데이터를 입력받아 각 데이터에 레이블 할당해서 군집화 실행
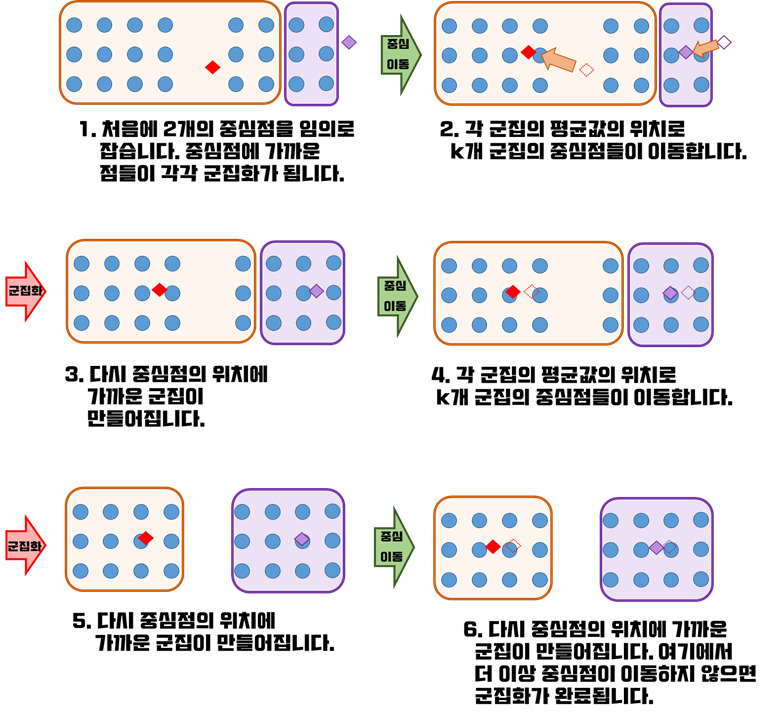
상황에 따라 데이터 분류가 원하는 결과와 다르게 발생할 수 있으므로 데이터가 비선형인 경우는 비추천한다.
-
스케일링(Scaling) 은 연속형 데이터의 모든 특성에 동일하게 중요성을 부여하기 위해 사용. 데이터가 일정한 범위를 유지하도록 함. (이상치를 확인 할 수 있음)
-
거리 제곱의 합(Sum of Squared Distances , SSD)을 통해서 최적의 K값을 찾아볼 수 있음. K값은 클러스터의 중심점 갱신 반복 횟수를 의미하며 SSD에서의 K값이 증가할 수록 SSD가 0이 되기 때문에 0에 가까워지기 직전의 k값을 고르는 것이 좋다. SSD 이외에도 엘보우 기법, 실루엣 기법 등으로 최적의 k값을 찾는다.
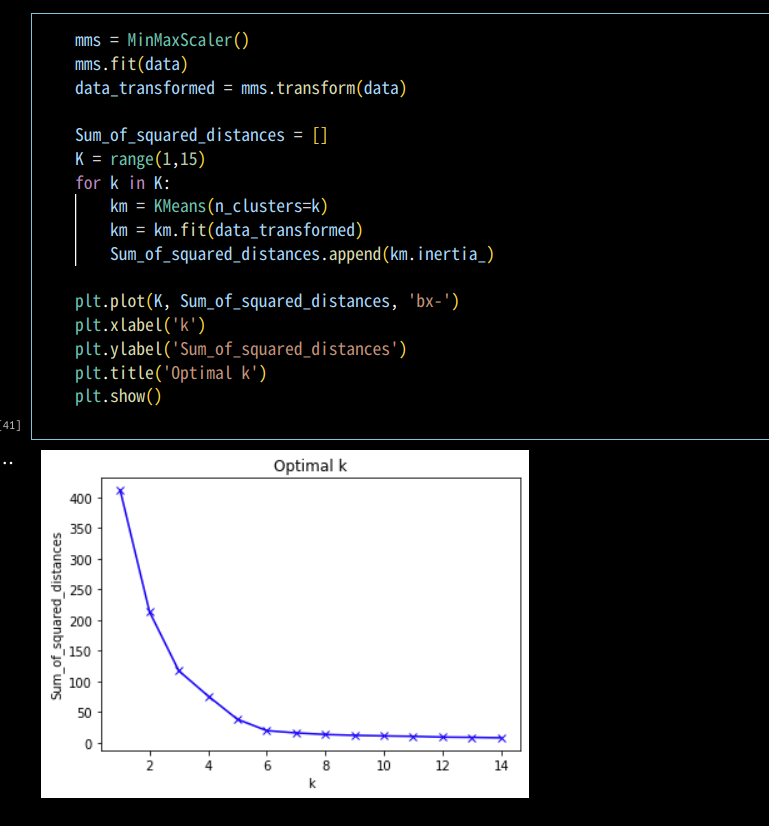
최적의 K값 찾기
2. DBSCAN 밀도 기반 군집 분석
:Density-Based Spatial Clustering of Applications with Noise DBSCAN은 일정 밀도 이상을 가진 데이터를 기준으로 군집을 형성하는 방법. 노이즈에 영향을 받지 않고 연산량은 많지만 오목하거나 볼록한 부분을 처리하는 데 유용
- K 평균 군집화는 크게 군집 잡아서 구체화 시키는 느낌이었다면 밀도 기반은 작게 시작해서 군집을 확대하는 방향이다. 중심점을 설정할 때 '만약 이 point의 주변 노드가 3개 이상이어야 중심점을 할 수 있다'의 조건을 달아서 군집을 설정할 수 있다.
-클러스터링 해당 링크 참고할 것
3. Mean Shift
4. Gaussian Mixture Model
차원 축소
5. PCA 주성분 분석
:Principal Component Analysis PCA는 data selection할 때 필요하다. 분석할 때도 필요. 고차원 데이터는 처리해야 할 데이터 양이 많아지므로 고차원 데이터를 저차원으로 축소시켜 데이터가 가진 대표 특성만 추출한다면 성능은 좋아지고 작업도 간편해짐. 차원 축소 알고리즘
- 개인적으로 정형 데이터 셀렉션 할 때 PCA를 정교하게 했느냐에 따라 성능 차이가 났던 것 같다. 책 예시는 되게 쉽게 함수로 진행했지만 실제로 데이콘 같은 대회에서는 직접 중요도 분석, 상관관계 분석을 해서 대표 특성을 뽑아내는 것 같다.
6. Singular Value Decomposition(SVD)
+추가적인 것들
-자료유형
| 데이터 형태 | 설명 | 예시 |
|---|---|---|
| 수치형 | 관측된 값이 수치로 측정되는 자료 | 키, 몸무게, 시험 성적 |
| 연속형 | 값이 연속적 | 키, 몸무게 |
| 이산형 | 셀 수 있는 자료 | 자동차 사고 |
| 범주형 | 관측 결과가 항목 또는 몇 개의 범주로 나타나는 자료 | 성별, 선호도 |
| 순위형 | 범주 간에 순서 의미가 있는 자료 | 매우 좋다, 좋다, 싫다, 매우 싫다 |
| 명목형 | 범주 간에 순서 의미가 없는 자료 | 혈액형 |
-파이토치 함수
1. df.fillna(method='ffill') : 윗 셀의 값을 가져옴. 윗 셀의 값이 없거나 셀이 없는 경우 0으로 표기함
2. x.fit_transform(X) : 평균이 0, 표준편차가 1이 되도록 데이터 크기를 조정함
3. normalize(x) : 데이터가 가우스 분포를 따르도록 정규화
