딥러닝
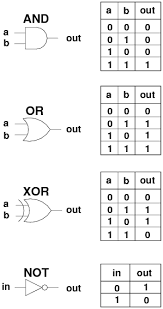
컴퓨터가 인식하는 논리 게이트인데 XOR 연산같은 경우는 학습이 불가능하다. 이를 극복하기 위해 hidden layer를 두어 비선형인 데이터 학습이 가능하도록 함. 다층 퍼셉트론 MLP을 고안하는데 hidden layer 여러개 두는 신경망을 딥러닝이라고 함.
- 딥러닝 장점 : 특징 추출과 빅데이터의 효율적 활용이라고 말할 수 있음
-특징 추출 : 데이터를 벡터로 변환하는 작업. 3장의 머신러닝과 다르게 딥러닝은 특성 추출과정이 포함됨.
-빅데이터의 효율적 활용 : 데이터가 많을수록 성능 향상을 기대할 수 있음
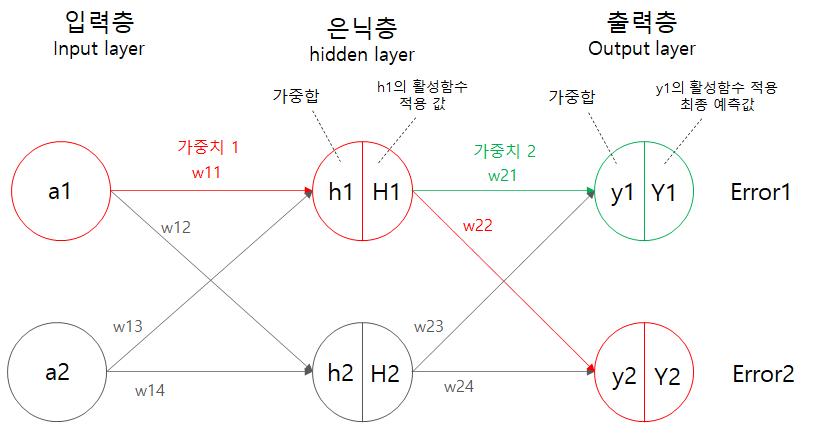
활성화 함수
: 전달 받은 값을 출력할 때 출력값을 변화시키는 비선형 함수임. 왜 필요하냐? 라고 생각할 수 있는데 선형적인 저차원 데이터를 고차원 비선형으로 변형하는데 기여를 하기 때문!! 선형함수는 선형끼리만 연결되므로 비선형 고차원을 표현하기 위해서는 활성화 함수가 필요함.
- 시그모이드 함수 --> Vanishing gradient problem
- 하이퍼볼릭 탄젠트 함수 --> Vanishing gradient problem
- 렐루 함수 --> Vanishing gradient problem >>solution<<, fast computation, No effect on gradient descent, If input value is negative, It always becomes zero.
- 리키 렐루 함수 --> 렐루의 발전된 함수(0으로 되는 문제 해결!)
- 소프트맥스 함수
손실 함수
: 경사하강법은 학습률과 손실 함수의 순간 기울기를 이용해서 가중치를 업데이트하는 방법. 미분의 기울기를 이용해서 오차를 비교하고 최소화하는 방향으로 이동시켜야 하는데 이때 오차를 비교하는 방법이 손실함수임.
- 평균 제곱 오차 MSE
- Cross Entropy error : 분류 문제에서 원핫인코딩했을 때만 사용.
딥러닝 과정
- forward 과정을 통해 입력값은 hidden layer의 전달 함수에 가중합이 되고 활성화 함수를 통해 다음 노드에 전달.
- 모든 계산이 완료되면 예측값은 최종 출력층에 도달 --> 손실함수를 이용해 예측값과 실제값의 차이를 추정
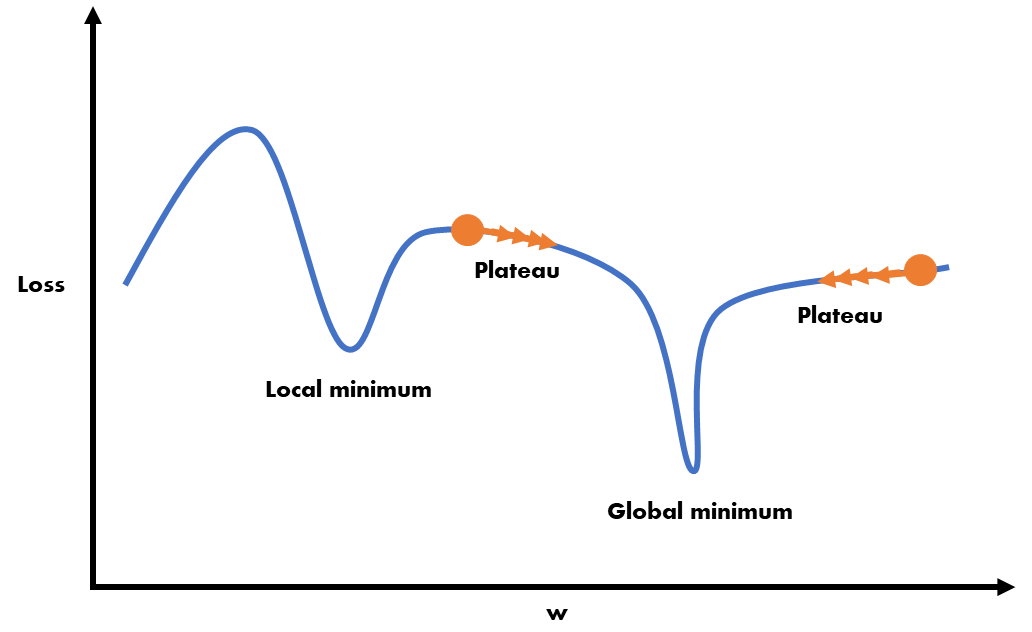
손실함수가 그려질텐데 손실 loss는 최소화가 되어야 함. 극소값을 찾아줘야 하는데 local minimum이 아닌 global minimum을 찾아줘야 함!! 극소값을 찾기 위해서 보통 기울기가 0인 지점을 찾는 함수를 쓰게 되는데 local minimum에 빠지지 않도록 해야됨. --> 옵티마이저 성능 좋은 것을 요구.
- backward(or backpropagation)과정을 통해 역으로 전파(output layer -> hidden layer -> input layer) 가중치를 update를 함.
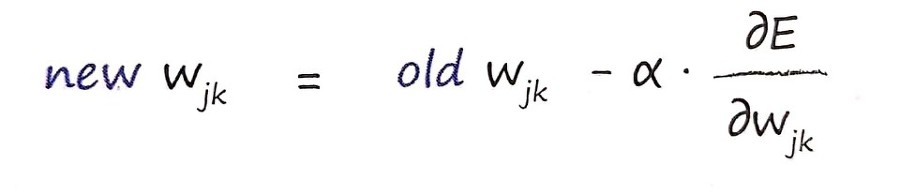
알파는 learning rate(step size), 편미분은 direction 역할을 한다. 이때 가중치 업데이트는 optimizer 종류에 따라 다름!!
- 배치 경사 하강법(Batch Gradient Descent, BGD)
- 확률적 경사 하강법(Stochastic Gradient DEscent, SGD)
- 미니 배치 경사 하강법(mini-batch gradient gradient descent)
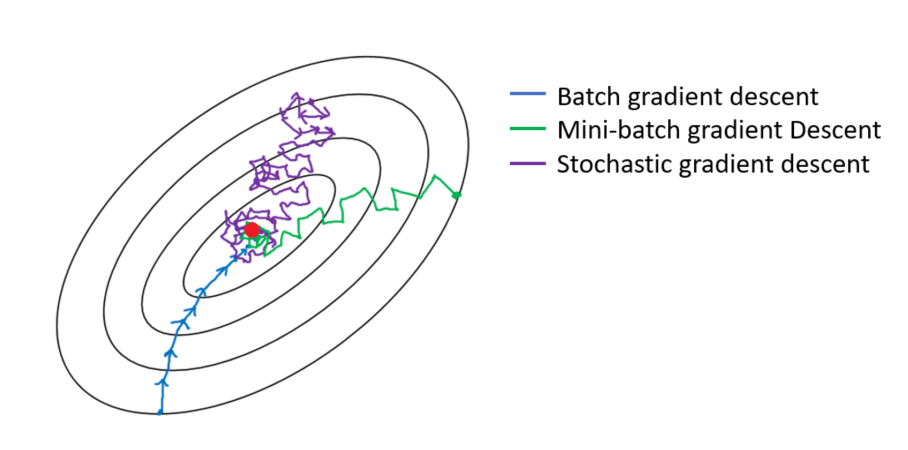
- 더 발전된 optimizer 종류와 성능
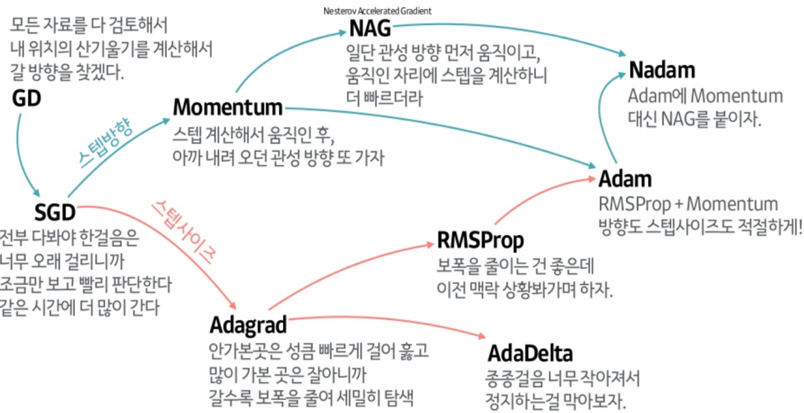
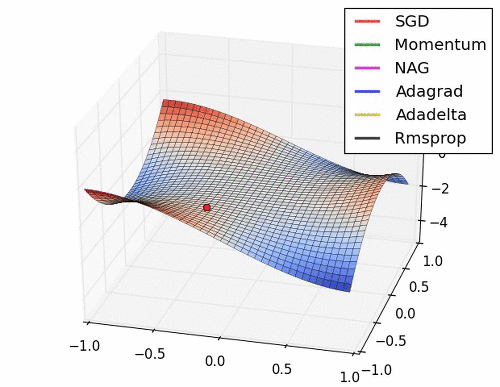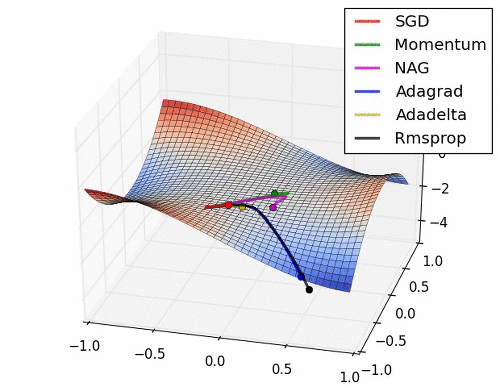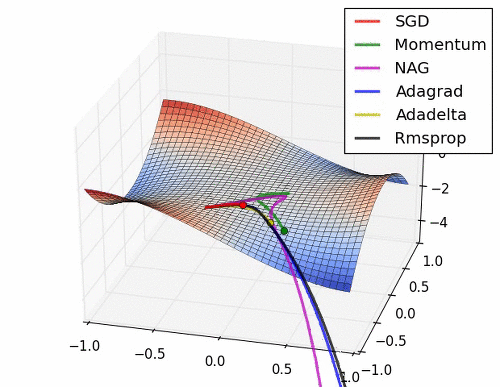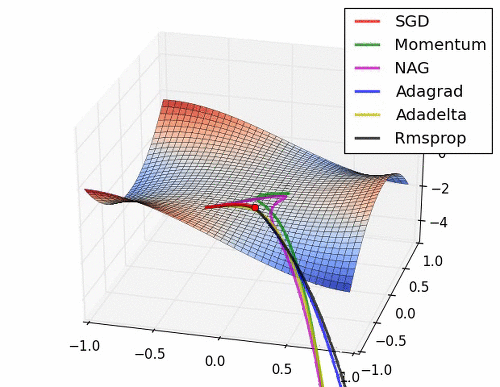
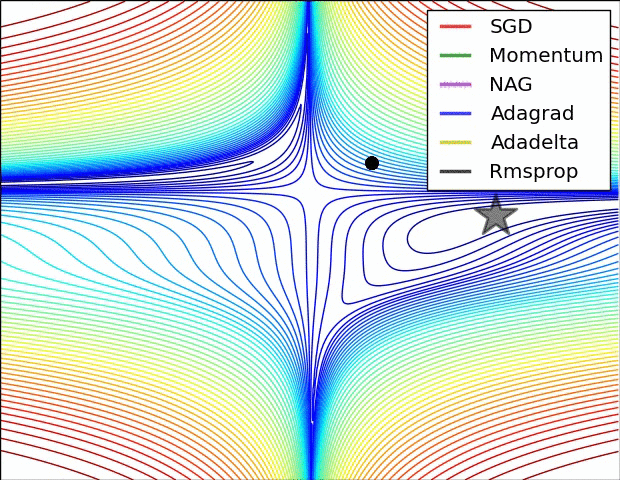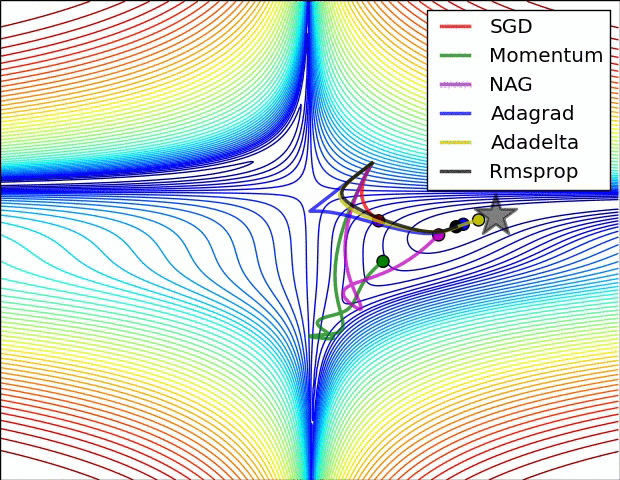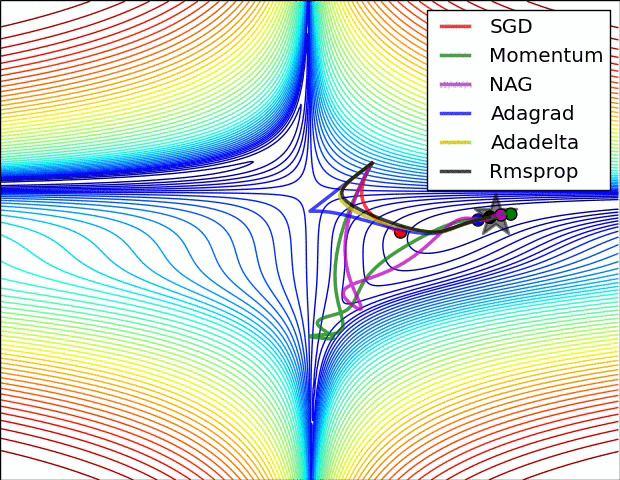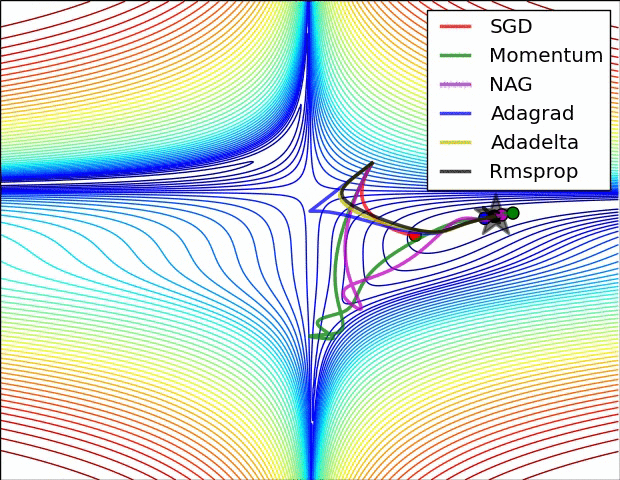
-
업데이트된 가중치로 loss가 최소화가 될 때까지 다시 학습 1~4번 반복
-
hidden layer가 많을수록 표현력이 증가. 전달되는 오차가 크게 줄은 경우 마냥 좋은 것은 아님. vanishing gradient문제가 발생하므로 이는 렐루를 이용해서 해결. overfitting을 방지하기 위해 dropout 등을 이용.
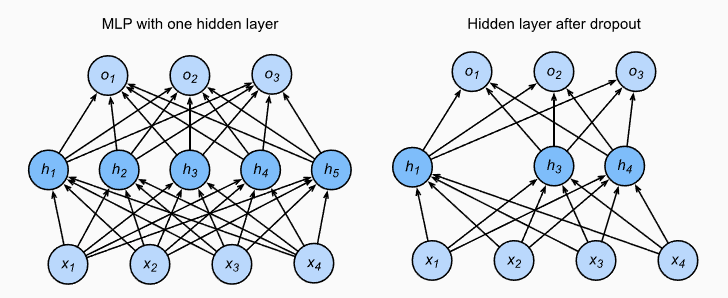
class Net(nn.Module):
def __init__(self, input_shape=(3,32,32)):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3)
self.conv2 = nn.Conv2d(32, 64, 3)
self.conv3 = nn.Conv2d(64, 128, 3)
self.pool = nn.MaxPool2d(2,2)
n_size = self._get_conv_output(input_shape)
self.fc1 = nn.Linear(n_size, 512)
self.fc2 = nn.Linear(512, 10)
# Define proportion or neurons to dropout
self.dropout = nn.Dropout(0.25) #25%의 노드를 무작위로 선택해서 사용하지 않겠다.
def forward(self, x):
x = self._forward_features(x)
x = x.view(x.size(0), -1)
x = self.dropout(x)
x = F.relu(self.fc1(x))
# Apply dropout
x = self.dropout(x)
x = self.fc2(x)
return x
딥러닝 종류
- 심층 신경망 DNN
- 합성곱 신경망 CNN
- 순환 신경망 RNN --> LSTM (시계열 데이터를 학습시키는데 유리)
- 볼츠만 머신 Boltzmann Machine
- 심층 신뢰 신경망 Deep Belif Network, DBN
등등
