Abstract
Market-1501: Person ReID 데이터셋
다른 데이터셋의 문제점
1) 크기(규모)가 한정되어 있다.
2) 손으로 그린 boxes로 구성됨 -> 현실적인 settings에서 사용 불가
3) 각 ID에 대해 1개의 실측 자료와 1개의 query 이미지만 있다.
Market-1501 dataset으로 해결
1) 본 논문이 쓰여진 시점에서 가장 큰 person ReID dataset
2) 이미지가 Deformable Part Model(DPM)을 사용하여 생산되었음
3) dataset이 개방된 시스템에서 수집되었고, 각 인물에 대해 여러 이미지가 있음
본 고에서는 unsupervised Bag-of-Words descriptor를 제안한다.
descriptor가 VIPeR, CUHK03 및 Market-1501 데이터셋에서 좋은 정확도를 보이고 대규모 데이터셋에서 확장 가능함을 보여준다.
Introduction
문제
Person ReID task에서 두 가지 측면의 문제가 있다.
1) 대부분의 기존 데이터셋은 데이터셋의 규모나 풍부함에서 결함이 있다. 인물의 수가 몇백명으로 한정되어 있고, 보통 동일한 인물을 기준으로 2대의 카메라로 촬영해서 query와 관련된 이미지 수가 매우 제한적이다.
또한 실제로 detector는 사람을 잘 정렬하지 못하거나 일부가 누락될 수 있다. 이상적인 dataset이라서 편향될 수 있고, 현실과 달라서 효과가 떨어질 수 있다.
2) 많이 쓰는 Brute-force feature-feature matching은 좋은 인식률을 달성하지만, 계산 효율이 낮아 large-scale application에서 잠재력이 제한된다.
제안
Market-1501 데이터셋
6대의 카메라로 수집된 1501명의 인물 data + 500000개의 distractor set + 3358개의 쿼리 이미지를 준다. (이때까지 가장 큰 person ReID dataset)
차별점: DPM으로 감지된 상자, distractor 이미지들이 포함됨, 각 인물에 대한 여러 query와 여러 참조 이미지
accuracy evaluation: 포괄적인 성능 평가를 위해 mean average precision(mAP)를 사용할 것을 제안한다.
Unsupervised BoW representation
training data에서 codebook을 생성하고, 각 보행자 이미지가 시각적 단어 histogram으로 표현된다.
빠른 응답 시간과 좋은 인식 정확도를 제공한다.
이전 연구
Discriminative model: SVM, Boosting을 많이 쓴다. 다중 view 변화의 영향을 줄이는 데 좋지만, 새로운 카메라가 시스템에 추가될 때 많은 annotation 작업이 필요하다.
Unsupervised model: 보행자의 신체 구조를 분석하여 특징을 추출하는 방법인 SDALF 방법과 local 정보를 전역적으로 표현할 수 있는 방법(global vector로 encoding)인 Fisher Vector를 제안했다.IDF와 유사한 아이디어인 희귀한 색상에 더 높은 가중치를 부여할 것이 제안되기도 했다.
이미지 검색의 발전
binary SIFT: SIFT 특징(이미지의 특징점 추출)을 이진화해서 역방향 파일에 삽입(효율적 검색 가능)
Bow model: local 특징의 공간적인 분포를 고려하지 않는다. -> 한계
공간적 제약 모델링(Zheng): 이미지 내의 공간 정보 encoding
검색 결과의 랭킹을 개선하기 위해 재정렬 단계가 중요하다.
one shot feed back optimization(Liu): 검색 결과를 빠르게 개선할 수 있는 피드백 방식 제안
assign weight 방식(Zheng): 다양한 특징에 적응적인 가중치를 할당
multi query: 여러 쿼리가 있을 때, 새로운 쿼리는 평균 또는 최대 연산으로 생성된다.
본 고에서는 몇가지 최신의 기술을 통합해서 경쟁력있는 person ReID system을 구축한다.
The Market-1501 Dataset
1501명의 인물에 대해 32668개의 바운딩 박스가 있고, 개방형 환경에서 거의 6대의 카메라로 데이터를 수집했다.
-
현재 대부분의 데이터셋은 hand-cropped bboxes이지만, market-1501은 DPM으로 바운딩 박스를 만들었다. 하지만 DPM의 정확도는 높지 않다는 문제가 있기 때문에, hand-cropped bboxes도 같이 제공해서 둘을 비교한다.
50% 이상: good
20% 미만: distractor
나머지: junk(영향을 주지 않는다.) -
또한 성능평가측면에서 query identity의 모든 인스턴스를 찾아낼 수 있어야 완벽한 방법이라고 할 수 있는데, 이 dataset에서는 개방된 시스템에서 적용된 방법을 위해 testbed를 제공한다.
-
market-1501 dataset에는 특이하게 500000개의 bbox가 포함된 Distractor dataset을 주는데, 이것까지 하면 이때까지는 가장 큰 dataset이다. 또한 distractor를 제공함으로써 더 효율적이고 안정된 분석을 하게 한다. 마지막으로, query 문제를 해결하기 위해 6대의 카메라로 특징을 추출했다.
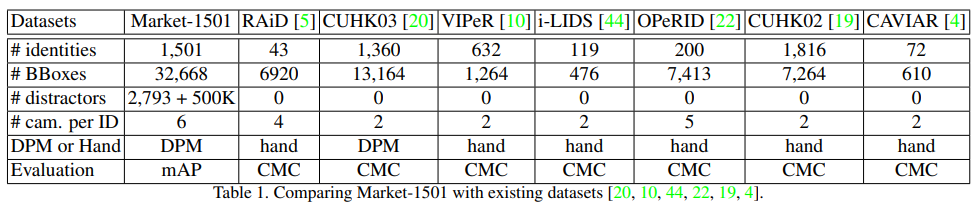
기존 dataset과 비교한 표이다.
Evaluation Protocol
Cumulated Matching Characteristics(CMC) curve의 한계: 단순하게 첫 번째 정답 매칭만을 평가해서 실제로 검색된 모든 결과의 정확도나 오답의 비율을 반영하지 못한다.
(예시에서는 CMC 값은 1로 동일하게 나오지만, rank list의 quality를 정확히 반영하지 못했다.)
AP : precision과 recall을 결합한 측정 방법. 목록의 전반적인 품질을 평가하는 데 사용된다. 정답의 위치와, 오답의 비율도 고려해서 전체적인 성능을 평가하는 것이 가능하다.
mAP: precision-recall curve 아래의 면적을 계산한 것. (평균정밀도)
The Bag-of-Words Model
채택 이유
1) 이전 연구들에서 효과적인 것으로 나온 local features를 잘 수용한다.
2) 모든 특징을 비교하는 방식이 아니라 빠른 전역 특징 매칭을 가능하게 한다.
3) 비슷한 local descriptor를 동일한 시각적 단어로 양자화시켜서 조명이나 시점과 같은 변화에 대해서 어느정도의 불변성을 달성할 수 있다.
Feature Extraction
Color Names (CN) descriptor를 사용
Codebook
Market-1501 dataset:training set에서 생성
다른 dataset: 독립적인 TUD-Brussels dataset에서 생성
size: k
Quantization
Eiclidean distance에서 가까운 neighbors를 찾기 우해 Multiple Assignment(MA)를 사용
MA = 10으로 설정 (하나의 특징이 10개의 시각적 단어의 인덱스로 표현)
TF-IDF
histogram에서 TF-IDF 방식으로 가중치가 부여됨
TF: 시각적 단어의 발생 횟수 encoding
IDF: N이 갤러리에 있는 이미지 수, ni: 시각적 단어 i를 포함하는 이미지의 수
=> log(N/ni)
Burstiness
CN 설명자는 SIFT에 비해 구별력이 낮아 Burstiness가 더 많이 발생할 수 있음
=> histogram의 모든 항목은 TF의 제곱근으로 나눈다.
Negative Evidence
training set에서 mean feature vector를 계산한다. 그리고 mean vector를 모든 테스트 특징에서 뺀다.
Similarity Function
query image Q와 gallery image G에 대해서, 두 특징 벡터 간의 내적을 계산한다. (내적 = 유클리드 거리)
Improvements
Weak Geometric Constraints
Adjacency Constrained Search(ACS)는 공간적 제약을 통합하는데 좋지만, 계산 비용이 높다. ACS와 BoW 모델을 통합하면, 각 query 특징에 대해 patch 거리를 계산하는 데 드는 비용을 낮출 수 있다.
Background Suppression
problem: negative impact of background distraction
이전의 해결책: Farenzena
separate the foreground pedestrian from background by segmentation
Farenzena의 문제: process of generating a mask for each image가 시간이 소모되고 불안정하다.
[본 논문에서의 해결책]
image에 2D Gaussian template을 적용하여 해결한다.
(µx, µy)를 이미지 중심에 설정하고, (σx, σy) = (1, 1)로 설정 (사람이 이미지 중심에 위치한다고 가정)
Multiple Queries
multiple queries의 사용은 image search와 person re-id에 좋다.
각 인물에 대해서 하나의 카메라에서 여러 쿼리 이미지가 있을 때, multi-multi matching 대신에 single query로 병합한다. 이때 average pooling과 max pooling을 사용한다.
Reranking
재정렬은 초기 검색 결과의 순위를 다시 정렬해서 최종 검색 결과의 품질을 개선하는 과정이다.
본 논문에서 사용한 재정렬 알고리즘은 초기 랭크 목록의 상위 T개의 이미지를 쿼리로 선택해서 gallery를 다시 검색하는 reranking 방법을 사용한다.
각 새로운 query imgae Ri에 대해서 gallery image G와의 유사도 점수 S(Ri, G)를 계산하여 유사도를 구한다.
최종 점수 S^(Q,G)를 계산한다. (G 이미지가 Q 쿼리에 얼마나 유사한지를 나타낸다)
Evaluation
BoW model and improvements
1) 기본 BoW 벡터는 낮은 정확도를 나타낸다.
2) stripe matching에 의한 기하학적 제약을 통합하면 정확도가 향상된다.
3) Gaussian mask는 좋은 결과를 보였다. -> pedestrian이 대략적으로 이미지의 중앙에 위치한다는 사전 정보가 통계적으로 합당하다.
4) 다중 쿼리의 사용이 인식 정확도를 더 향상시킨다.
5) reranking을 하면 mAP가 더 높아진다. 하지만 reranking은 초기 랭크 목록의 품질에 대한 민감성이라는 문제가 계속 발생한다.
이전 연구들에서는 일반적으로 사람만 포함된 good bounding boxes에 집중했고, detector errors에 대해서는 거의 연구하지 않았다.
복잡한 배경이나 신체 부위에서 DPM에 의해 탐지된 distractor가 re-id accuracy에 많은 영향을 미친다.
또한 대규모 데이터셋에서의 re-id 성능은 db가 커질수록 accuarcy가 떨어진다. 또한 ANN을 사용하면 reid accuarcy가 약간 떨어지지만, 속도가 향상된다는 장점이 크다.
Conclusion
- Market-1501 (+500k) 소개
- person re-id와 image search 사이의 격차를 줄이기 위한 BoW descriptor 제안
