Introduction
Re-ID의 목표: 해당 인물이 다른 장소와 시간에 나타났는지 아닌지 결정하는 것, 사람 검색
-> image, video, text description 등으로 query를 준다.
1. Closed-world (Supervised Re-ID)
일반적으로 Re-ID는 다음과 같은 순서로 진행된다.
1) Raw Data Collection
2) Bounding Box Generation
3) Training Data Annotation
4) Model Training
5) Pedestrian Retrieval
하지만 여러 간극 때문에 open-world에서는 문제가 생긴다.
2. Open-world
1) need to process heterogeneous data: 적외선 이미지, sketches 등
2) Raw Images/Video: end-to-end person search
3) Unvailable/Limited Labels: unsupervised, semi-supervised Re-ID
4) Noisy Annotation: annotation error, imperfect detection/tracking results
5) Open-set: not query exists in gallery
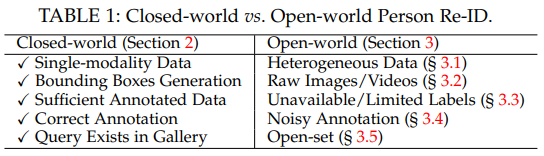
Closed-world Persion Re-Identification
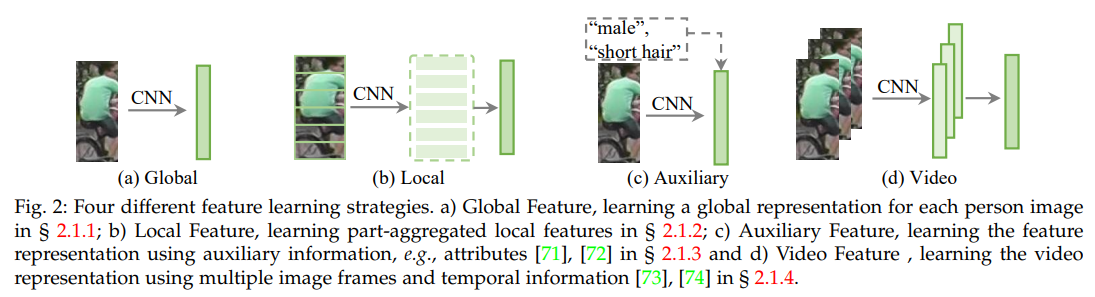
1. Feature learning strategies
a) Global feature
- single image representation: 개별 이미지를 독립적으로 분석
- cross image representation: 여러 이미지 간의 관계 분석
(1) Attention within the person image
pixel level attention, channel-wise feature response re-weighting, background suppressing -> misalignment/imperfect detection 강화
(2) Attention across multiple person images
context-aware attentive feature, 내부 시퀀스와 시퀀스간 attention, 일관적인 속성, group similarity 등에 집중 -> mining the relations across multiple images
b) Local feature
(1) Human parsing/pose estimation
human parsing/pose를 먼저 추출 -> 각 부분에서 feature를 뽑는다.
성능이 좋지만, 추가적인 detector가 필요하다. 또한 noisy pose detection이 생길 수 있다.
(2) Horizontal division
균일한 partition, more flexible, occlusions and background clutter에 취약하다.
c) Auxiliary feature
-> 추가적인 annotated information을 활용한다. Reinforce the feature representation
(1) Semantic attributes: "male", "short hair"와 같은 추가 정보 이용 (객체나 장면의 의미적 특징을 설명)
(2) Viewpoint information: 이미지나 비디오에서 어떤 시점이나 각도에서 관찰되었는지의 정보
(3) Domain information: adoptively mine the domain-sharable and domain specific neurons for multi-domain deep feature representation (각 카메라를 다른 도메인으로 취급하고 차이를 고려해서 globally optimal representation을 얻는 것)
(4) GAN generation: 생성된 GAN 이미지를 보조적 정보로 활용. 포즈의 변화, 카메라 환경 변화에도 robust한 학습이 가능
(5) Data Augmentation: random resize, cropping and horizontal flip, occluded samples, random erasing(무작위 nosie 추가), virtual human 생성
d) Video feature
video sequence를 이용한 방법
시각적 정보(apperance)와 시간적 정보(temporal)를 활용. Semantic attributes도 쓰인다.
- 문제 1. Temporal informantion의 정확한 capture
-> 비디오는 연속된 프레임이기 때문에, 시간적 흐름을 잘 따져야 한다. - 문제 2. The unavoidable outlier tracking frames with in the videos
outlier frame -> 일반적 흐름과 다른 노이즈, 가려짐 (학습에 방해됨) - 문제 3. 다양한 길이의 video sequence 처리
비디오 sequence를 짧은 snippet으로 나눈다 (상위 snippet 집계 -> embedding)
clip 수준에서의 학습 방법 (공간적, 시간적 차원에서 attention 신호로 강력한 클립 수준 표현 생성)
확인해야할 것: Accuracy, Efficiency
최근 auto-maching learning에 대한 관심이 증가하면서, Auto-ReID 모델들이 제시되고 있다.
2. Deep Metric Learning
metric learning의 역할(거리 함수로 계산하는 방식, projection matrix(투영 행렬))이 loss function으로 대체되었다.
(투영 행렬: 데이터를 특정 공간에 투영하는데 사용)
a) Loss function design
identity loss: training process에서 다룬다. (image classification problem)
cross-entropy 기반으로 동작하며, softmax로 예측 확률을 계산한다.
학습과 hard sample을 mining 하는 것을 자동으로 한다.
label smoothing: 특정 클래스에 대해 높은 확률을 예측하는 것을 방지하기 위한 방법(overfitting 방지)
일반화 성능이 올라간다.
cross-entropy를 이용한 식이다.
n은 각 배치의 training sample의 개수이다.
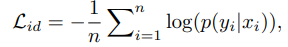
verification loss: 두 이미지가 동일한 클래스에 속하는지 여부를 학습하는 손실함수
identity loss와 결합해서 성능을 향상시킬 수 있다. (두 이미지 간의 관께를 학습하는 과정)
(1) contrastive loss: 두 샘플 간의 거리를 조정하여, 같은 클래스는 가까이 두고 다른 클래스는 일정거리(ρ) 이상으로 떨어지도록 한다. (두 샘플의 유사성 또는 차이점 학습)
(2) binary verification loss: fij = (fj − fj)^2를 입력받아서 이 쌍이 positive인지, negative인지 분류하는 클래스 (입력된 이미지 쌍이 동일한 클래스에 속하는지 아닌지 이진분류)cross-entropy를 이용한 verification loss 식

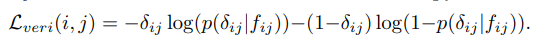
triplet loss: retrieval ranking problem을 다룬다. 같은 클래스는 더 가까이, 먼 클래스는 더 멀리 보낸다.
anchor, positive, negative로 나뉜다. (각각 i, j, k)
- 더 강화된 triplet loss: quadruplet deep network. negative가 2쌍이다.
combination of triplet loss and identity loss
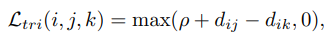
OIM loss (Online Instance Matching): memory bank scheme로 디자인 되었다.(instance features를 저장해둔다.)
vifi -> 임베딩 벡터 vi와 특징 벡터 fi 간의 내적을 계산 (=유사성 측정)
unlabelled identities가 존재한다. = unsupervised domain adaptive Re-ID에서 사용한다.
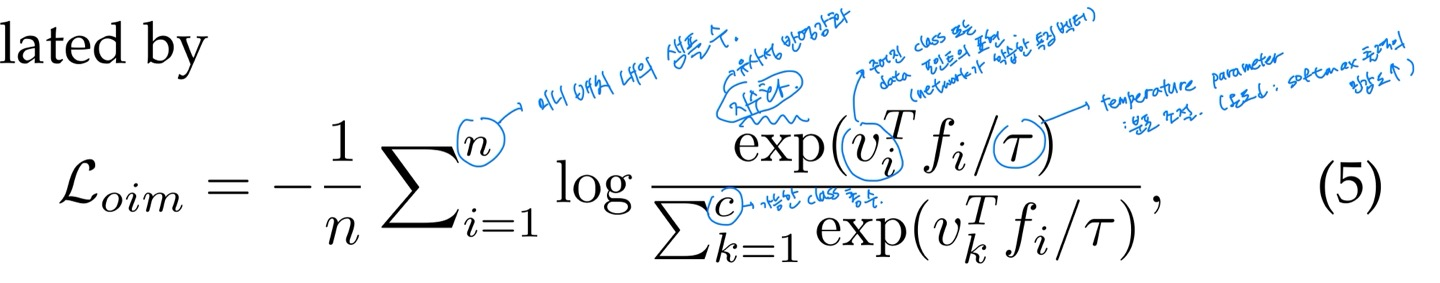
b) training strategy
문제: The severely imbalanced positive and negative sample pairs (데이터 불균형)
(1) identity sampling : 각 training batch에서 identities가 랜덤으로 select 된다. 그 후 각 몇 이미지가 각 선택된 identity로부터 샘플링된다.(여러 장의 이미지를 sampling)
=> informative positive and negative mining을 보장한다. (= 모델이 모든 신원에 대해 고르게 학습할 수 있도록 돕는다.)
(2) adaptive samping: positive and negative samples의 비율을 조정한다.
(3) sample re-weighting: sample의 중요도에 따라 가중치를 조정한다. sample weight을 조정하기 위해 sample distribution이나 similarity difference를 이용한다.
(4) reference constraint: sample 간의 유사성을 sample-to-reference 유사성으로 변환한다. (이상치에 강하다.)
(5) a multiloss dynamic training strategy: identity loss와 triplet loss를 동적으로 조합한다.
c) ranking optimization
testing stage에서 사용한다.
검색 성능 향상에 중요하다.
(1) gallery-to-gallery similarity mining: 초기 순위 목록을 최적화하는 자동화된 방법 중 하나
(2) human interaction: 사람이 개입해서 순위 조정
(3) rank/metric fusion: 여러 개의 순위 목록을 결합해 최종 순위를 도출한다.
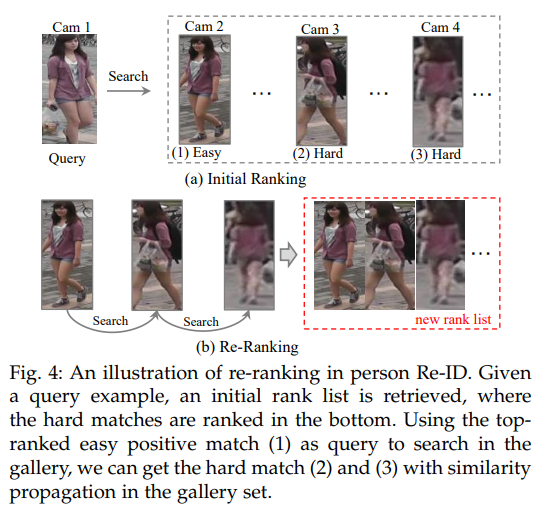
d) re-ranking
initial ranking list에 gallery-to-gallery similarity를 활용한다.
(1) top-ranked similarity pulling(상위 아이템의 유사성 강화) and bottom-ranked dissimilarity pushing(하위 아이템의 비유사성 강화)
(2) k-reciprocal re-ranking: 내용적인 정보를 활용해 최적화
(3) geometric structure of the underlying manifold: 검색 결과가 존재하는 공간(manifold)의 기하학적 관계를 분석해 순위 재조정
(4) expanded cross nuighborhood re-ranking: cross neighborhood distance를 통합해 순위를 조정
(5) local blurring re-ranking: 클러스터링 구조 사용 (클러스터링으로 유사한 아이템 그룹화)
(6) query adaptive retrieval strategy: 쿼리 특성에 맞게 검색 방식을 조정
(7) human interaction: 사람이 직접 ranking list feedback
e) rank fusion
다른 방법들로 muliple ranking lists를 얻어 활용한다.
(1) query adaptive late fusion: 쿼리 적응형 지연 융합
(2) consensus-based decision problem with graph theory: 순위 융합 과정에서 그래프 이론을 이용한다. (합의 기반의 의사 결정 문제)
Datasets and evaluation
closed-world setting으로 많이 활용되는 11개의 dataset을 소개한다.
-대표적인 Evaluation Metrics: CMC(Cumulative Matching Characteristics), mAP(mean Average Precision)
(1) CMC-k: 올바른 매칭 결과가 상위 k개에 포함될 확률
-> CMC는 쿼리당 정답이 1개일 때 좋다. 여러 개의 정답(ground truty)가 존재하면 별로 좋지 않다. 첫번째로 매칭된 결과만 고려하기 때문에 discriminablility가 충분히 나타나지 않는다.
(2) mAP는 multiple ground truths 측정이 가능하다. 모든 정답을 고려해 평가하기 때문이다. precision(정확도)과 recall(재현율)이 결합해 평균을 낸 것이다.
-> hard matches(첫 정답을 잘 찾아내도, 그 외의 정답에 대한 성능이 다를 때) 차이를 평가 가능하다.
(3) FLOPS, network parameter size: training과 testing 시 device의 효율성을 평가한다.
image-based Re-ID
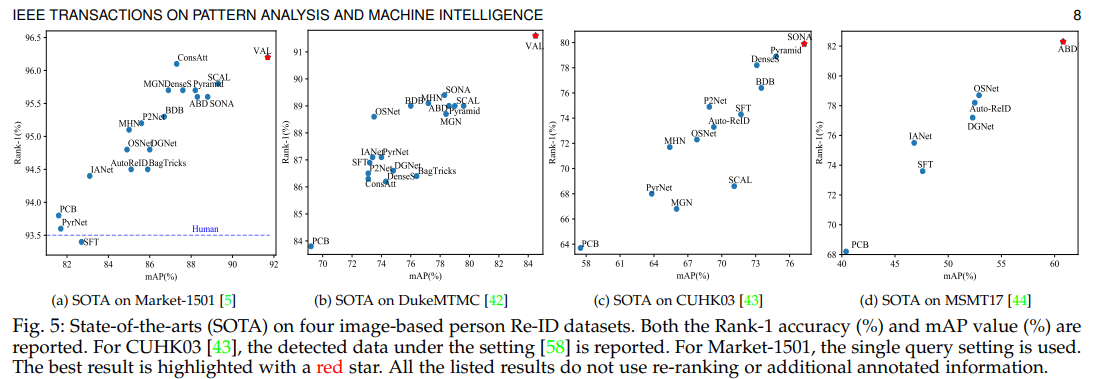
(1) 대부분의 모델이 사람보다 더 높은 정확도를 보였다. 특히 val모델은 viewpoint information을 효과적으로 활용해 높은 정확도를 달성했다. re-ranking과 metric fusion을 사용하면 추가적으로 향상될 수 있다.
(2) global feature learning보다 part-level feature learning이 더 좋다. 특히 large background clutter 또는 heavy occlusions인 상황에서는 부분 특징 learning이 더 효율적이다. (요즘은 두개를 합쳐 쓴다. global에서 전체적인 맥락을 잡고, part에서 세밀하게 정보를 수집한다.)
(3) attention: discriminatvie Re-ID에서 중요하다.(중요한 특징에 집중한다.)
conv channels 간의 관계(정교한 특징 학습), multiple feature maps 간의 관계(중요한 정보 추출), 계층적 layer 사이의 관계(이미지 구조 처리율 상승), different body parts 등이 있다.
attribution: discriminative, diverse, consistent, high-order(특징간의 관계를 이해(고차원 이해))
(4) multi-loss training: muti-view perspective
- dynamic multi-loss training strategy: identity loss와 triplet loss function 결합
- sample weighting strategy: imbalanced issue 해결책 (mining informative triplet)
video-based Re-ID
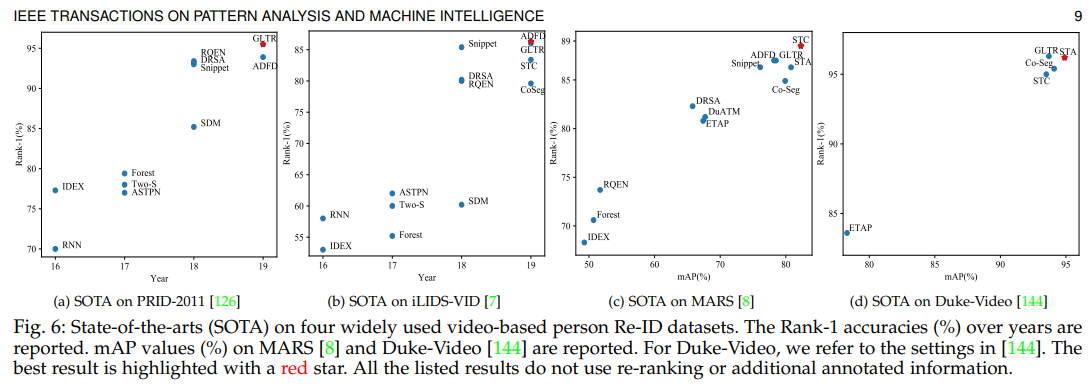
전체적으로 성능이 향상되고 있다.
spatial and temporal modeling이 discriminative video representation learning에 중요하다.
image가 base인 attention scheme across multiple frames가 판별력을 높인다.
muliple frames within the video sequence가 가려진 부분을 채워준다.
Open-world person re-identification
Heterogeneous Re-ID
depth-based Re-ID
Depth image는 몸의 형태와 뼈 정보를 capture한다. (옷이 바뀌는 것과 같은 환경에서 Re-ID 가능)
(1) recurrent attention-based model: CNN과 RNN이 결합 -> 작고, 차별적인 local regions를 찾을 수 있다.
CNN에서 이미지의 저수준(local) 특징을 추출한다.(신체의 shape, 질감 등)
RNN에서 반복 처리 -> 모델이 이미지의 여러 부분에서 중요한 정보를 단계적으로 찾아낸다.
(2) a split-rate RGB-to-Depth transfer method: RGB 데이터셋과 depth 이미지 간의 격차를 줄이기 위한 방법. temporal attention을 통합하는 방법을 사용한다. (옷이 바뀐 사람 식별에 좋다.)
Text-to-Image Re-ID
only text description이 주어질 때 필수적으로 사용한다.
text description과 RGB 이미지를 매칭한다.
text 설명과 person image 사이의 shared features를 학습 -> gated nural attention model(입력 data의 중요한 부분에 집중)
- cross projection learning method: image-text 매칭을 위해 서로 다른 데이터 유형 간의 매칭 가능 (shared space 학습)
Visible-Infrared Re-ID
daytime visible image(가시광선 이미지), night-time infrared image(적외선 이미지) -> low-lighting conditions에서 중요
(1) Deep zero-padding frame work: modality sharable features(가시광선 이미지와 적외선 이미지 간에 공통적으로 사용할 수 있는 특징) 학습
(2) GAN-Based techniques: GAN을 사용해 가시광선 이미지를 적외선 이미지로 바꾸거나 반대로 변환해 두 modality 간의 차이를 줄인다.
Cross-Resolution Re-ID
low-resolution image(저해상도 이미지)와 high-resoulution image(고해상도 이미지)간의 matching을 처리 -> 해상도가 많이 다른 이미지 간의 일치 problem 해결
- Cascaded SR-GAN: 저해상도-> 고해상도로 변환하는 GAN 기반 model
(Cascaded manner: 여러 단계로 구성된 계단식 방식(점진적으로 고해상도로 변환됨), 이때 identity information(신원 정보)를 포함시킨다.)
End-to-End Re-ID
bounding box 생성의 신뢰도를 올린다.
- Re-ID in Raw Images/Videos: person detection과 re-identifiaction을 동시에 수행해야한다.
(1) 사람을 탐지해야 하고 탐지된 사람을 재식별해 다른 이미지나 비디오에서 동일한 사람을 찾아낸다.
(2) end-to-end person search system은 단일 convolutional neural network를 사용한다.
(3) NPSM(Neural Person Search Machine)은 쿼리와 탐지된 후보 영역 간의 contextual 정보를 활용해 목표 인물을 정확하게 식별한다.
(4) contextual Instance Expansion module은 graph learning framework를 학습한다.
(5) Identity Discriminative Attention Reinforcement Learning(IDEAL): attention 강화 학습을 사용해 자동으로 생성된 bounding box 내에서 중요한 영역을 선택해 Re-ID 성능을 향상시킨다.
end-to-end person Re-ID는 multi-person과 multi-camera tracking과 밀접하게 연관되어 있다.
(1) 탐지된 각 사람을 가설로 취급해 이 가설들 간의 관계를 그래프로 모델링한다. (전체적인 body와 pose를 함께 고려한다.): graph-based formulation for multi-person tracking
(2) multi-target multi-camera tracking과 person Re-ID를 통합한다. 이때 어려운 sample을 탐색하고 triplet learning의 가중치를 조정한다.
Semi-supervised and Unsupervised Re-ID
a) unsupervised Re-ID
(1) 초기의 unsupervised Re-ID는 dictionary, metric, saliency등의 분변 요소를 학습하는 것에 집중했다. 이것은 여러 조건에서 일정한 성능을 유지할 수 있었지만, 판별력과 확장성에 제한이 있었다.
(2) 이후 Cross-Camera Label Estimation이 제안되었다. 여러 카메라에서 촬영된 이미지 간의 label을 추정하는 방법이다.
(3) part-level representation learning은 전체적인 이미지보다 local parts의 label 정보를 mining하는 것을 목적으로 제안되었다. (이미지의 특정 부분에서 discriminal한 특징을 학습한다.)
b) Semi-supervised Re-ID
(1) One-shot Metric learning: 제한된 label information을 사용해, deep texture 표현과 color metric을 결합한다.
(2) Stepwise One-shot learning (EUG): 비디오 기반의 Re-ID에서 점진적으로 몇 개의 후보를 선택해 labelled tracklet들을 많이 만든다.
(3) Multiple instance attention learning: 비디오 label을 이용해 representation을 학습한다. full annotation에 대한 의존성을 완화시킨다.
c) unsupervised domain adaptation
UDA: label이 있는 원본(source) 데이터를 label이 되지 않은 target dataset으로 전이시키는 방법이다. label이 없을 때 활용할 수 있다.
(1) target image generation
- GAN generation 사용: 원본 domain 이미지를 target domain의 스타일로 변환하는 방법이다.
- Person transfer generative adversarial network(PTGAN): 라벨이 있는 원본 데이터의 정보를 라벨이 없는 target 데이터로 옮긴다.
- Self-similarity and domain-dissimilarity(SPGAN): similarity 보존과 domain 차이 보존으로 target domain에서의 학습을 진행하는 GAN 기반의 모델이다. 생성된 이미지는 원래 이미지와의 유사성을 유지하면서, domain 간의 차이를 학습할 수 있다.
- Hetero-homogeneous learning(HHL): homogeneous learning(카메라 불변성)과 heterogeneous learning(domain 연결성)을 같이 고려해서 학습한다.
- Adaptive transfer network: 조명, 해상도 등의 환경에 따라 적응하는 과정을 분해한다. dataset 간의 성능을 향상시킨다.
- Background shift suppression: domain 차이를 최소화하기 위해 background shift를 억제한다.
- Pose disentanglement: 포즈를 분리하는 방법을 추가한다.
(2) target domain supervision mining
- Exemplar memory learning scheme: exemplar-invariance, camera-invariance, neighborhood-invariance 3개의 변하지 않는 cues를 supervision으로 사용한다.
- Camera view information: domain 간의 차이를 줄이기 위해 camera view 정보를 supervision으로 사용한다.
- Self-paced contrastive learning frmaework with hybrid memory: 동적으로 multi-level supervision signals를 생성해 대조 학습을 수행한다.
- spatio-temporal inforamtion도 활용되었다.
SOTA for unsupervised Re-ID
(1) 최근 unsupervised Re-ID의 성능이 크게 향상되었다.
(2) powerful attention scheme, target domain image generation, using the annotated source data(학습 과정에서)의 부족이 있다. 3가지의 측면에서 개선이 필요하다.
(3) supervised Re-ID에 비해, unsupervised Re-ID의 격차는 크게 떨어져있다. 최근 연구에서 label이 없는 대규모의 training data를 사용한 unsupervised learning이 여러 작업에서 supervised learning을 뛰어넘는 것을 볼 수 있다.
Noise-robust Re-ID
partial Re-ID
heavy occlusions에 의해 human body의 일부분만 보이는 상황을 해결하는 것이다.
(1) fully convolutional network(FCN): 불완전한 사람 이미지에서 고정되노 크기의 spatial feature map을 생성해, 부분적으로 보이는 이미지를 처리한다.
(2) deep spatial feature reconstruction(DSR): 명시적 정렬을 피하기 위해 reconstructing error를 활용해 공간적인 특징을 재구성하는 방법이다.
(3) visibility-aware part model(VPM): 가시성에 민감한 부분 모델을 설계한다. 이를 통해 sharable한 region-level feature를 추출해 공간적 불일치를 줄인다.
several partial misalignment, unpredictable visible regions, distracting unshared body region 문제가 여전히 있고 다른 query에 대해 적응적으로 matching model을 조정하는 방법도 연구가 필요하다.
Re-ID with sample noise
족한 detection/부정확한 tracking 결과로 인한 outlying regions/frames가 포함된 이미지나 비디오 문제를 말한다.
pose estimation cues, attention cues를 활용하면 이미지 내의 불필요한 영역이나 배경 혼잡을 억제할 수 있다.
비디오 sequence에서 noisy한 frame의 영향을 줄이는 것이 기본 방법이다.
이를 위해 set-level feature learning과 frame level re-weighting이 있다.
domain별 특화된 sample noise handling이 개발되어야 한다.
Re-ID with label noise
annotation error로 인한 피할 수 없는 문제를 label noise라 한다.
(1) label smoothing technique는 label overfitting 문제를 피하기 위한 방법이다.
(2) distribution net(DNet): feature uncertainty는 더 강력한 model 학습을 위해 제안되었다.
한정된 training samples와 unknown new identities가 증가하는 문제가 있다.
Open-set Re-ID and Beyond
open-set Re-ID
person verification 문제로 다뤄진다. 두 개의 이미지가 동일한 사람인지 아닌지를 구별하는 것을 목표로 한다.
이미지 간의 유사성이 학습된 임계값 τ를 초과하는 지의 여부가 중요하다.
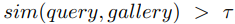
(1) 초기: 주로 handcrafted systems를 사용했다.
(2) Adversarial PersonNet(APN): GAN과 Re-ID의 feature extractor를 함께 사용한다. (생성된 이미지에 대해 특징 추출기를 보완한다.)
(3) feature 블확실성을 modeling하는 연구도 진행됐다. 높은 정확도와 낮은 false target recognition rate를 유지하는 것이 연구되고 있다.
group Re-ID
개인보다 그룹 안의 사람들을 할당하는 것에 목표를 둔다.
(1) 초기 연구: sparse dictionary learning(데이터를 희소하게 표현)과 covariance descriptor aggregation(여러 특징 간의 관계를 나타내는 묘사: covariance descriptor-행렬로 나타냄)을 사용해서 group의 표현을 추출하는데 집중했다.
(2) multi-grain information: 그룹의 특성들을 fully capture하여 통합하는 방법이다.
(2) graph convolutional network (GCN): group를 그래프로 표현하고 그룹의 similarity를 계산한다. end-to-end person search와 individual Re-ID에서 accuarcy를 높이기 위해 사용된다. 하지만 개별 인물보다 더 복잡한 그룹의 변화를 찾아내야한다.
dynamic multi-camera network
새로운 카메라나 probe에 대해 모델을 적응시키는 문제를 다룬다.
(1) human in-the-loop incremental learning: 사람이 개입하는 학습 방법이다. 다른 probe gallery에 맞게 업데이트 시킨다.
(2) active learning: multi-camera network에서 지속적인 Re-ID를 위해 능동적인 학습을 적용한다.
