먼저 redis와 rdb를 선택하는데에 있어서 스토리지와 메모리의 특성을 이해하고있으면 어떤 기술을 선택해야하는지 방향성을 잡을 수 있다.
| 메모리(rem) | 용량이 적다 | 비쌈 | 휘발성 저장(임시저장) | 성능 빠름 |
|---|---|---|---|---|
| 스토리지 | 용량이 많다 | 저렴 | 영구저장 | 성능 느림 |
redis는 메모리 기반의 db이며 위 특성을 이해하면 쉬워진다.
데이터 주소 찾기와 해시 함수
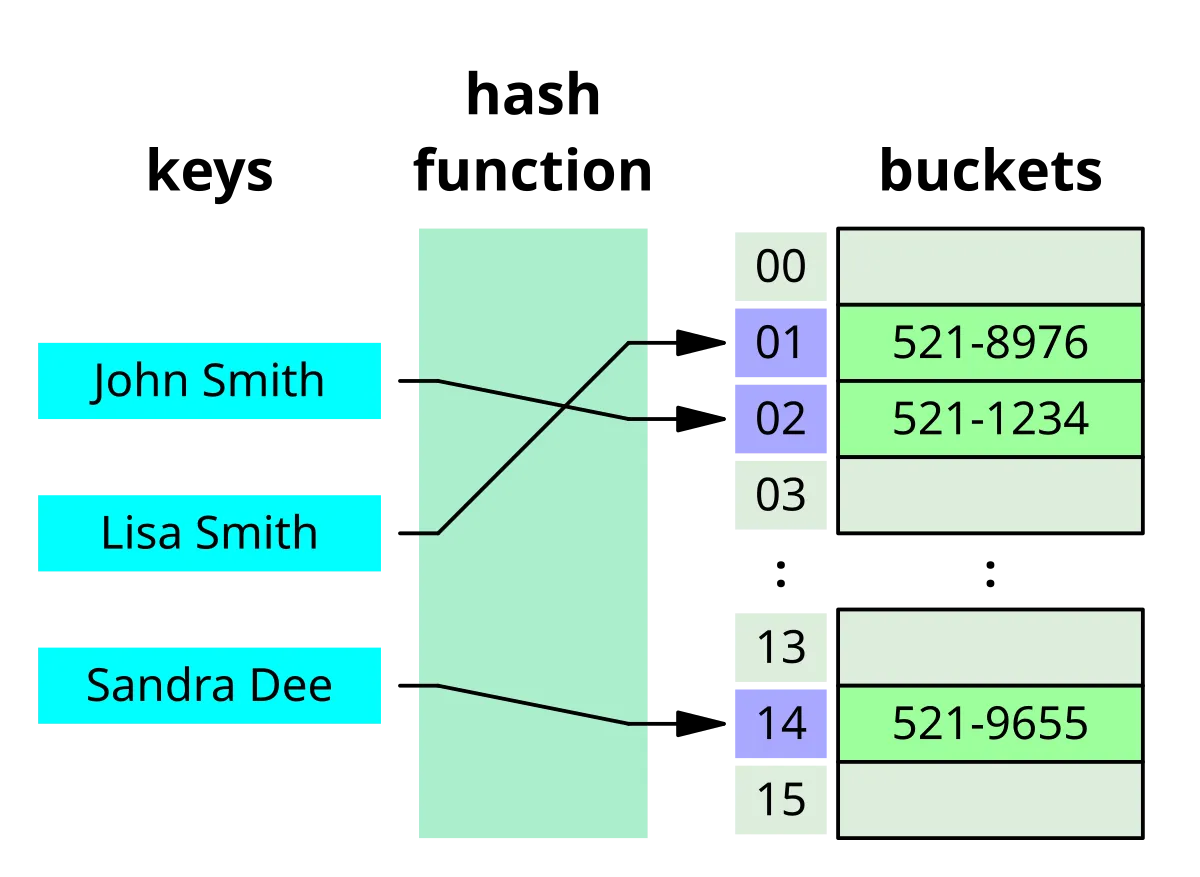
컴퓨터에서 데이터베이스에 있는 데이터 "주소" 찾으려면 보통 full scan을 해야 함. 즉, 모든 데이터를 일일이 훑어보는 O(n) 복잡도가 들어가서 시간이 오래 걸릴 수 있음. 반면, Redis는 key-value 구조로 해시테이블 사용해서 원하는 키값을 거의 O(1) 시간에 찾아옴. 실제로 어떤 값을 해시함수에 넣으면 난수 같은 주소가 나오고, 같은 입력값엔 항상 같은 결과값을 반환하는 게 해시 함수임. 덕분에 Redis는 특정 키를 순식간에 찾을 수 있음.
rdb(관계형 DB)에서 인덱스를 사용해 검색 속도를 높일 수 있지만, 해시 구조와 메모리 기반 연산의 Redis가 훨씬 빠르게 동작함. 이 원리는 비트코인이나 여러 서비스에도 쓰임.
- https://www.convertstring.com/ko/Hash/SHA256
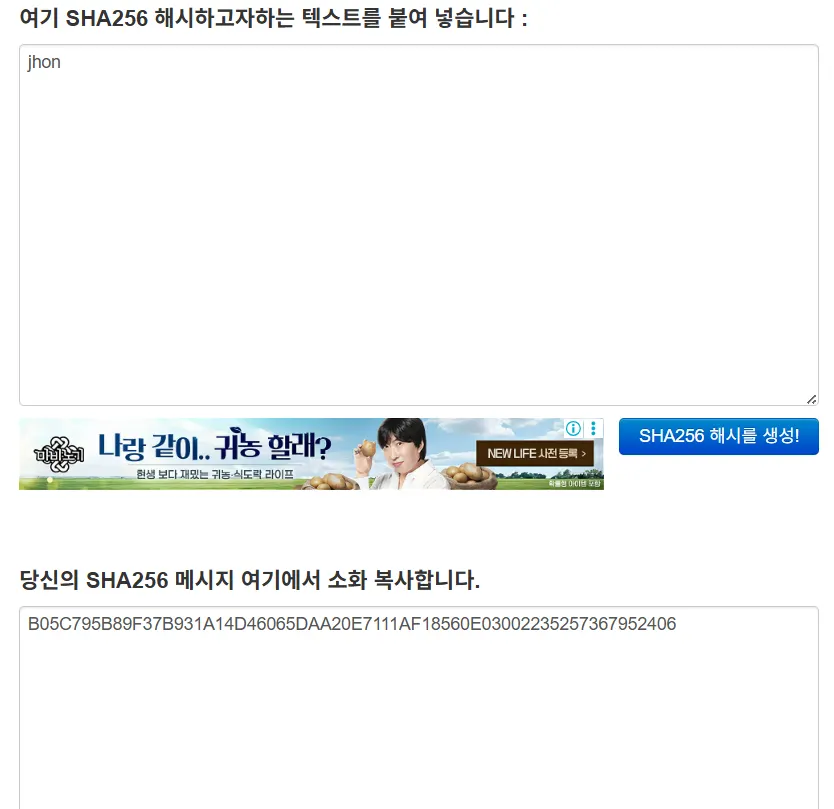
- 새로고침을 하더라도 jhon이라는 key는 항상 같은 난수를 뱉어내고 있다
redis의 주요 특징
- 고성능의 키-값(key-value) 저장소로, 거대한 맵(Map) 데이터 저장소형태를 가지고 데이터를 메모리에 저장하여 빠른 읽기와 쓰기를 지원
- 주로 캐싱, 인증 관리, DB동시성 제어 등에서 다양한 목적으로 사용
- key-value로 구성된 단순화된 데이터 구조로 sql 쿼리 사용 불필요
- 빠른 성능 ⭐⭐⭐
- 인메모리 NoSQL 데이터베이스로서 빠른 성능
- rdb는 기본적으로 disk에 저장이고 필요시에 메모리에 캐싱하는 것이므로, rdb보다 훨씬 빠른 성능
- redis의 메모리상의 데이터는 주기적으로 스냅샷 disk에 저장
- key-value는 구조적으로 해시 테이블을 사용함으로서 매우 빠른 속도로 데이터 검색 가능
- 인메모리 NoSQL 데이터베이스로서 빠른 성능
- Single Thread 구조로 동시성 이슈 발생X ⭐⭐⭐
- 윈도우 서버에서는 지원하지 않고, linux서버 및 macOS등에서 사용 가능
Docker 기반 Redis 설치 및 접속법
윈도우에 직접 Redis 설치는 잘 안 되므로 주로 Docker로 띄우는 방식임.
docker run --name redis-container -d -p 6379:6379 redis명령으로 docker에 Redis 컨테이너 생성.docker ps로 컨테이너 목록 확인 가능함.- 접속하려면,
docker exec -it [컨테이너ID] redis-cli로 컨테이너 안에서 redis-cli 실행해야 함.
Redis 자료구조 정리
- string: 기본 key-value 저장. set, get, del 등등 사용. nx/ex 옵션으로 조건부/유효기간 지정 가능.
- list: lpush, rpush로 값 추가. deque 구조로 앞/뒤로 밀고 당김. lrange로 부분 조회, lpop/rpop으로 제거.
- set: 중복 없는 집합. sadd로 멤버 추가, smembers로 전체 조회, sismember로 특정값 포함여부 확인.
- sorted set(zset): score 값으로 정렬. zadd로 추가, zrange/zrevrange로 순서대로 조회.
- hash: 필드-값 구조(map과 비슷). hset/hget/hgetall 등으로 조작. 객체의 속성이나 관계형 DB의 행 비슷하게 사용 가능.[9][11]
주요 활용 예시
- 실시간 좋아요/재고 관리: incr/decr로 카운팅
set likes:posting:1 0 # redis는 기본적으로 모든 key, value가 문자열. 따라서 0으로 세팅해도 내부적으로 "0"으로 저장(연산가능) incr likes:posting:1 # 특정 key 값의 value를 1만큼 증가 decr likes:posting:1 # 특정 key 값의 value를 1만큼 감소 - 로그인 토큰: set으로 저장 후 ex 옵션으로 만료시간 지정
set user:1:refresh_token abcdexxxxxx ex 1800 # 30분이 지나면 redis에 저장된 토큰이 불일치하게 되어서 (사라져서) 로그아웃 상태가 됨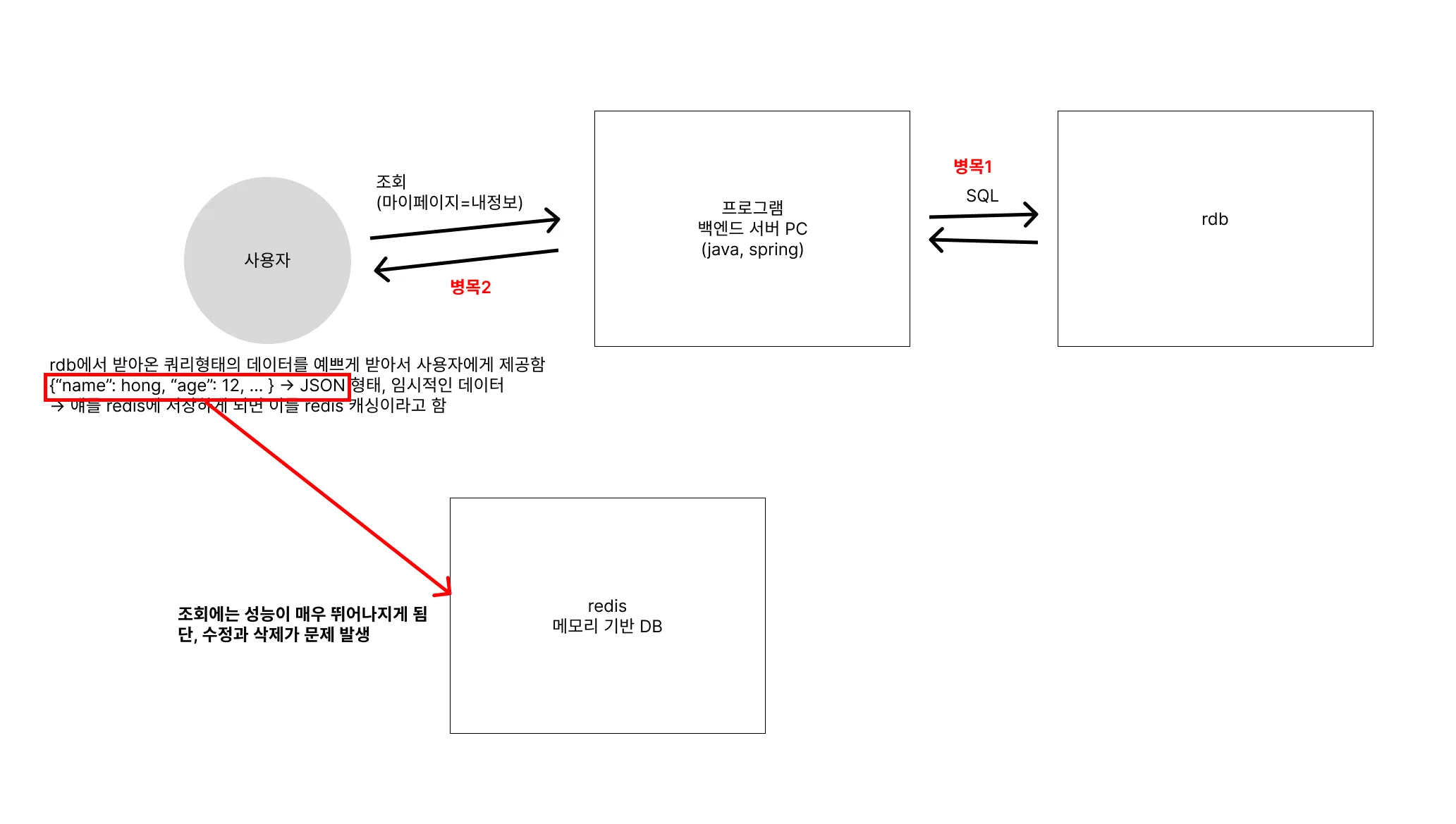
- JSON 데이터 캐싱
set member:info:1 "{\"name\":\"hong\", \"email\":\"hong@daum.net\", \"age\":30}" ex 1000- 최근 방문/조회 로그: list나 zset으로 저장
- 집합성 집계: set 자료구조로 중복 없이 저장 및 조회
- 해시(map)로 복잡한 객체 저장: hash 구조 활용
Redis와 Full Scan 이슈
Redis도 full scan(전체 키 조회)은 O(n)이라서 데이터가 진짜 많아지면 일반 DB의 full scan보다 느려질 수 있음. SCAN/KEYS 명령은 전체를 훑기 때문에 대용량에서는 사용 주의해야함. 인덱스나 특화 구조(예: set/zset)가 있으면 빠르게 집계할 수 있음.
Redis Pub/Sub와 Streams
- Pub/Sub: 메시지 저장 없이, 빠르게 전파. 메시지 유실 가능성 있음. 실시간 알림/채팅에 좋음.
- Streams: 메시지 저장해주지만 성능은 느림. 유실 적은 편. 안정적인 메시지 저장 필요할 땐 Kafka 같은 솔루션 추천.
서버 구조
- Redis는 레플리카, 클러스터로 확장 가능함. RDB의 샤딩 구조랑 비슷해서 직접 셋업은 어려움. AWS 같은 클라우드 서비스 활용이 일반적임.

2개의 댓글
Hash 함수를 사용한 해시테이블 추가 설명
해시함수로 돌린 난수를 나눠서 배열의 개수를 넣게 되는것이다
ex)190을 100으로 나눴을 때 나머지가 100의 경우의수밖에 없어지는 것 (0~99)
(메모리 공간의 크기로 나머지를 구하는 것)
이 나머지를 메모리의 주소값으로 삼게 되는거고, 이 메모리가 0~99번째 자리를 마련해놓고 있음
이 때 난수값을 나눠서 85가 나오면 85번째에 jhone이라는 데이터를 넣게 되는거고, 다른 문자열이 69가 나오면 69번째 칸에 넣게 되는거다
그러면 jhone을 찾을 때 난수값을 또 나눠보면 한방에 85를 다시 도출할 수 있고, 원하는 위치로 갈 수 있으므로 바로 찾을 수 있다
이 때 100으로 나누면, 우연의 일치로 난수는 다르지만 나누어 떨어지는 값이 같아져버릴 수 있다
그냥 배열의 크기를 최대한 크게 (메모리를 확보를 많이)해서 확률적으로 겹치는 일을 줄일 순 있지만 메모리에 낭비가 발생함.
물론 그럼에도 겹치면 java에서 처리(해시충돌)
- 빠르지만 (장)
- 많은 메모리양을 사용함 (단)
난수값 도출 -> 해시함수를 활용해 배열의 길이만큼 나눔 -> 항상 매칭되는 공간에 담아두게 됨
제가 하는 해쉬는 스완에서끝났습니다