Human Fall-down Event Detection Based on 2D Skeletons and Deep Learning Approach
Human Fall-down Event Detection
연구실에서 진행중인 Fall Detection을 구현하기 위해 관련 논문인 Human Fall-down Event Detection Based on 2D Skeletons and Deep Learning Approach를 읽고 간단하게 정리하였다.
Human Fall-down Event Detection Based on 2D Skeletons and Deep Learning Approach 논문 링크
논문의 내용은 어렵지 않으며, 간단하게 Fall Detection을 구현하고 싶을 때 이 논문을 읽고 구현을 진행하면 금방 구현할 수 있을 것이라 생각이 들었다.
1. Introduction
비디오 기반의 Classification을 사용해 사람의 행동을 인식하는 것은 Action Recognition이라고 한다. Action Recognition은 컴퓨터 비전의 분야중 하나이며 중요한 역할을 한다. 그리고 이것은 많은 분야에서 쓰이고 있으며 분야들의 예시로는 Human-Computer Interaction, Video Surveillance, Robotics, Game Control 등임을 알 수 있다.
여기서 사람의 행동을 인식하기 위해 사용하는 것이 두 가지가 있는데 Microsoft Kinect와 단일 RGB 센서이다.
Microsoft Kinect는 자세나 동작 인식을 위한 비교적 신뢰할 수 있는 좌표를 제공할 수 있다. RGB 센서는 일반 카메라로 생각하면 되는데 Skeleton을 추출할 때 비용이 낮다는 장점이 존재한다. 하지만 처리 속도나 인식 성능에 대해서는 조금 더 도전적임을 논문에서 언급하였다.
2. Related Works
최근 몇 년 사이 이미지와 비디오 처리, 분류, 이미지 캡셔닝 등 딥러닝의 성과들이 늘어나고 있으며, 특히 비디오에서 사람의 행동을 인식하는 부분도 늘고 있다고 언급하였다. 일부 연구는 Kinect 카메라에서 파생된 Depth의 값을 사용해 인간의 행동을 식별하는데 중점을 둔다. 이러한 Kinect 카메라 덕에 3D Skeleton을 얻을 수 있으며 인간의 행동이 더 쉽게 식별할 수 있다.
Kinect 카메라의 비용은 기존 RGB 카메라보다 더 비싼 편이다. 따라서 일부 연구자들은 RGB 이미지에서 2D 또는 3D Skeleton을 파생하려고 한다. 본 논문에서도 RGB 이미지에서 Skeleton을 추출하여 사용한다.
최근에는 이미지에서 Convolution Neural Network을 이용하여 Skeleton을 추출하고, 이미지 노이즈나 왜곡을 막아 정확도를 향상시키는 기술이 많이 사용되고 있다. 이러한 기술을 응용하여 본 논문에서는 RNN을 적절하게 더해 결과를 향상 시킬 수 있다고 생각하고 CNN을 통해 Skeleton을 추출한 뒤, RNN을 통해 행동을 분류하는 것이 목적임을 밝혔다.
3. Our System Design
본 연구에서 Fall-down Event Detection Process는 두 단계로 나뉜다. CNN으로 2D Skeleton을 추출한 후 RNN으로 2D skeleton Motion의 동작을 예측한다.
3-1. Extracting 2D skeleton by using very deep Convolution Neural Network
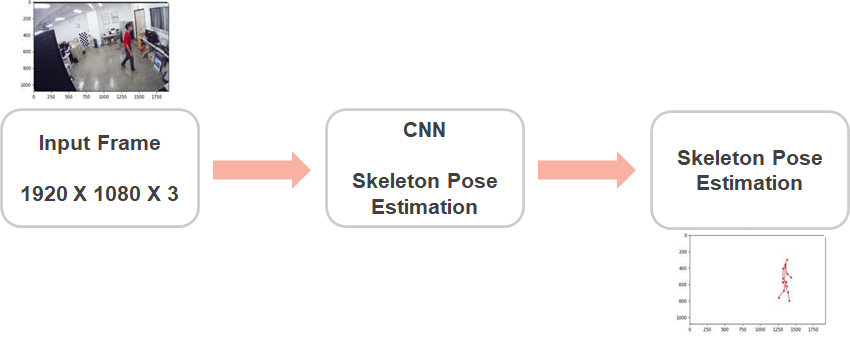
위의 사진은 첫 번째 단계의 모델 구조다. 해당 단계의 Input으로는 1920 X 1080 by RGB 이미지를 사용한다. 각 Frame은 미리 학습된 CNN 모델을 사용해 진행된다. Pre-trained Model로는 DeeperCut을 사용한다. 이 모델은 캡쳐된 이미지에 대한 Skeleton을 추출하는 것에 대해 우수한 결과를 달성할 수 있다고 본 논문에서 언급하였다. 때때로 배경에 영향을 받는데, 무관하거나 절못된 추정치를 제거하기 위해 인체를 직사각형 크기로 제한했다고 언급하였다. Output은 14개의 Joint 좌표(이마, 턱, 좌우 어깨/팔꿈치/손목/엉덩이/무릎/발목)가 나온다.
그리고 다음 단계에 사용되는 LSTM을 견고하게 만들기 위해, 중앙 엉덩이 좌표를 구하고 턱과 중앙 엉덩이 사이의 중간점을 골격 중심 좌표라 칭해 이를 구하여 14개의 Joint 좌표는 Image 좌표에서 골격 중심 좌표로 변환된다.
3-2. Predicting actions from 2D skeleton motions by using RNN with LSTM
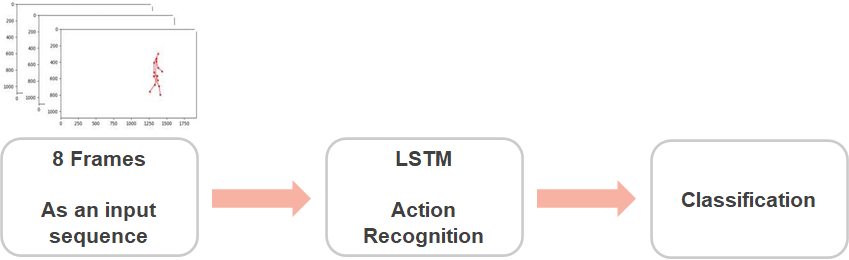
위의 사진은 두 번째 단계의 모델 구조이다. 본 논문에서는 LSTM(Long Short Term Memory)을 사용한다. LSTM의 Input으로는 8개의 Frame, 즉 8개의 골격 좌표가 들어가게 되고 LSTM을 거치게 되면서 행동을 인식하고 분류하는 과정이다. 분류되는 레이블은 서기, 걷기, 넘어짐, 눕기, 일어나기이다.
각 Frame 당 28개의 좌표를 xt로 나타낸 후 가중치 W를 곱한다. 그리고, 다음 출력 상태인 h_t는 RNN에 의해 암기, 새로운 h(t+1)을 추정하기 위해 다음 시간의 입력으로 전달된다. 여기서, LSTM은 Gradient Vanishing 문제를 해결하기 위해 사용되었으며, 각 입력상태인 h_t를 결정하기 위한 Input Sequence는 x_t-K(K=7) ~ x_t까지, 길이가 8인 것으로 설계 되었다. 그리고 8개의 연속 Skeleton을 수집해 RNN에 병렬로 공급한다.
4. Experimental Results
각 8개의 연속 입력 Frame으로 구성된 하위 Sequence를 수집하고 Dataset에서 Sample을 형성하기 위해 수집된다. 각 Frame의 크기는 1920 X 1080 pixels이다. Dataset은 800개의 Training data, 255개의 Validation data, 200개의 Test data로 구성되어 있다.
코드를 구현할 때 Tensorflow를 사용하였으며, 1단계는 이미 제작된 모델이므로 훈련을 제외하고 2단계만 500 epoch으로 0.0001 학습률을 이용하여 훈련을 진행하였다.
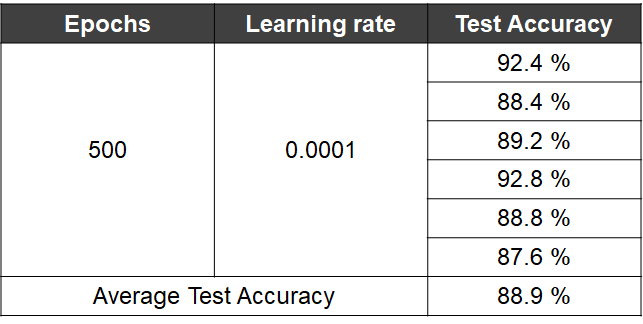
이 결과를 위의 표에 정리하였다. 여러 실험을 거쳐서 나온 결과이다. 평균 테스트 정확도는 89.9%이며, 자세한 부분은 표를 참고하면 된다.
본 논문에서 DeeperCut 모델 부분에 잘못된 Skeleton이 있는 경우가 있다고 한다. 이러한 Skeleton을 제거하기 위해 접합부와 중심 사이의 거리 합이 계산되어 임계값을 적용시킨후 불필요한 Skeleton은 제거되게끔 진행하였다고 언급되었다.
5.Conclusion
본 논문에서는 딥러닝 알고리즘을 사용해 Fall-down Event Detection을 진행하였다.
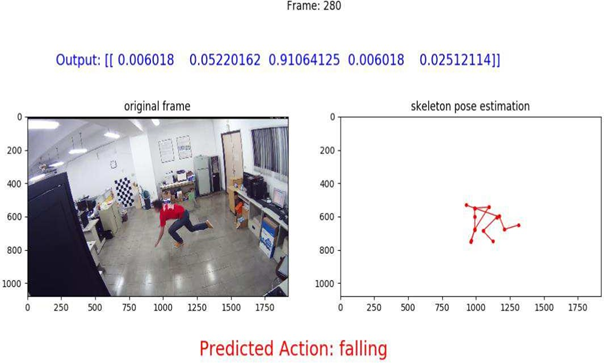
위의 사진이 본 논문에 대한 결과 사진이다. 간략하게 설명하면, 이들은 RGB 카메라에서 2D Skeleton을 추출하고 배경 노이즈도 동시에 없애기 위해 CNN을 채택하였다. 그리고 LSTM 기반으로 동적 Sequence를 처리하고 5개의 레이블로 예측할 수 있다. 그리고 간호 요구사항이 발생하게 되면 경보가 울리게 되는 시스템을 개발했다고 한다.
결론
사실 경보가 제대로 쓰이는지 논문에 정보가 거의 존재하지 않아 확인할 수 없었으며, 이 논문의 중점은 CNN을 통해 골격을 추출하였고 RNN을 사용하여 행동을 분류하는 것임을 알 수 있다. 논문 자체는 그렇게 어렵지 않았으며 금방 읽을 수 있었다.
