YOLOv4 논문읽기
1. Introduction
2020년 당시, object detection 모델은 비교적 단순한 task에만 사용할 수 있는 수준이었습니다.
또한 정확도가 좋은 모델일수록 real-time추론에서 멀어지며, 학습 시 batchsize를 크게 주게되므로 다수의 GPU를 사용해야 했습니다.
이러한 문제를 해결하고자 YOLOv4는 하나의 GPU에서 학습과 real-time추론이 동시에 가능하도록 여러가지 최신 기법을 적용한 결과, EfficientDet보다 두 배 빠르며 YOLOv3의 AP와 FPS를 각각 10%, 12%정도 상회하는 성능을 보여주었습니다.
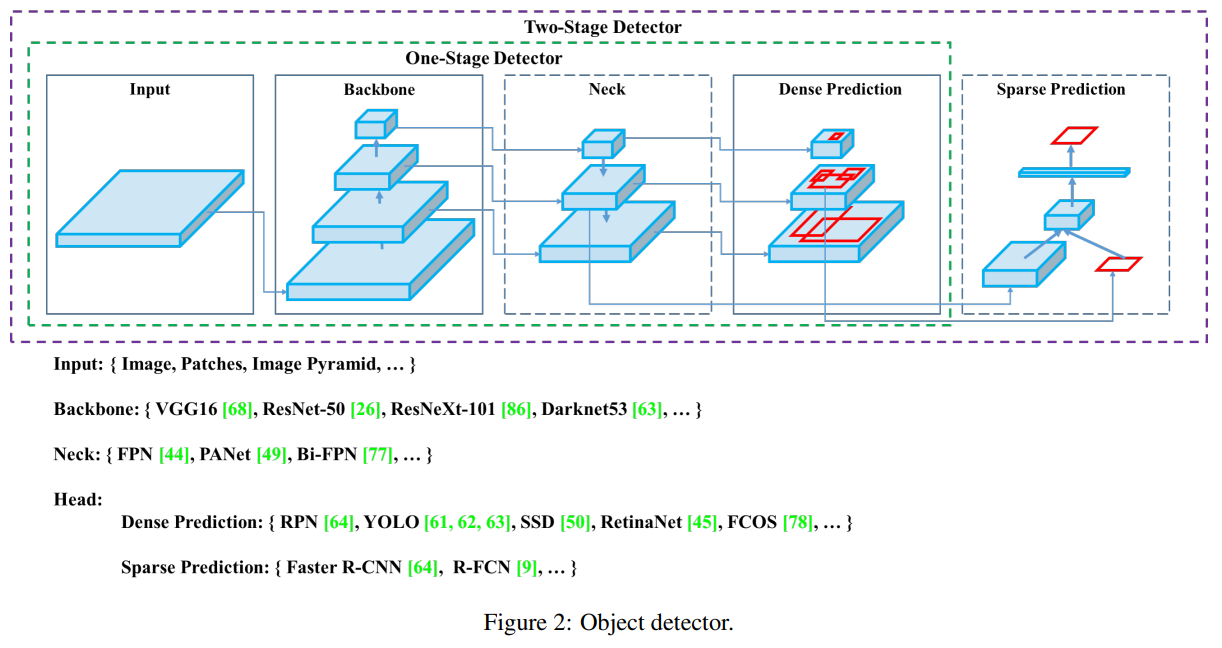
2. Related work
본 논문에서는 Related work에 object detector와 연관된 방법론 대부분을 담았습니다.
Backbones
VGG16, ResNet-50, SpineNet, EfficientNet-B0/B7,CSPResNeXt50, CSPDarknet53
Neck
- Additional blocks:
- SPP, ASPP, RFB, SAM
- Path-aggregation blocks:
- FPN, PAN, NAS-FPN, Fully-connected FPN, BiFPN, ASFF, SFAM
Heads
- Dense Prediction (one-stage):
- RPN, SSD, YOLOv3, RetinaNet (anchor based)
- CornerNet, CenterNet, MatrixNet, FCOS (anchor free)
- Sparse Prediction (two-stage):
- Faster R-CNN, R-FCN, Mask RCNN (anchor based)
- RepPoints (anchor free)
3. Methodology
3.1. Selection of architecture
CSPDarknet53
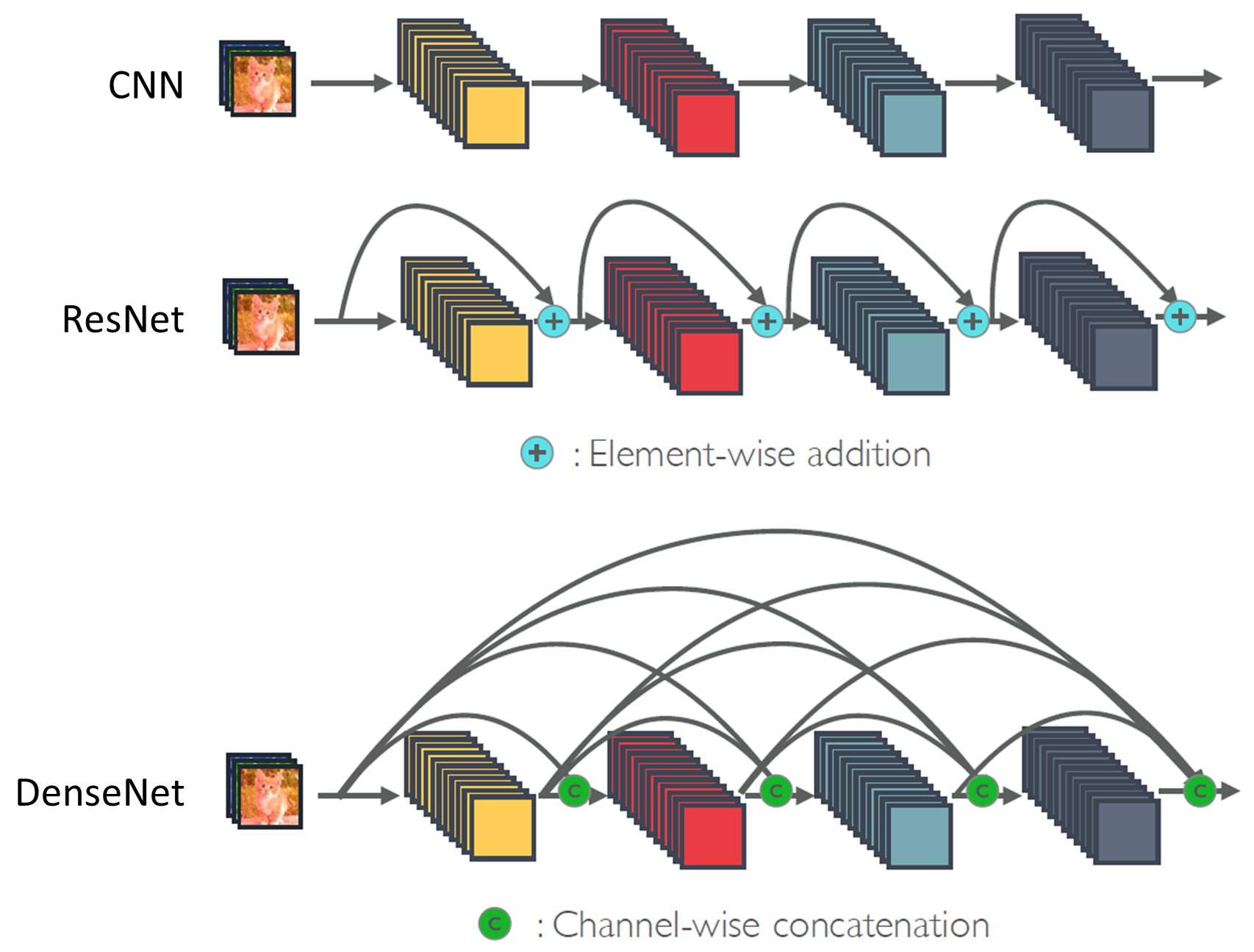
YOLOv3에 사용되었던 Darknet53은 ResNet기반의 모델이었습니다.
또한 ResNet구조에서 Dense connect를 추가하여 feature의 활용률을 높인 DenseNet이 발표된 바 있지만 연산량이 많이 요구된다는 단점을 갖고 있었습니다.
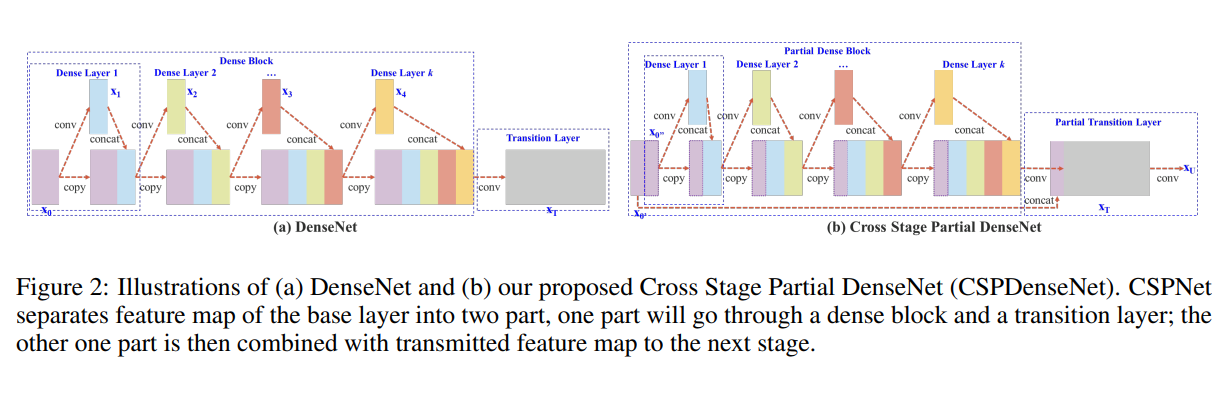
CSPNet은 이러한 단점을 해결하고자 개발된 모델이었고, CSPDarknet53또한 CSPNet에서 비롯되었습니다.
CSPNet
전체 채널에 대해 Dense connect를 수행하는 대신 채널 일부를 잘라 shortcut시키는 구조로 구성되어 필요이상의 gradient flow을 억제함과 동시에 info flow를 한층 더 강화함으로서 feature의 활용률을 유지하며 연산량을 획기적으로 낮춘 모델입니다.
SPP(Spatial Pyramid Pooling)
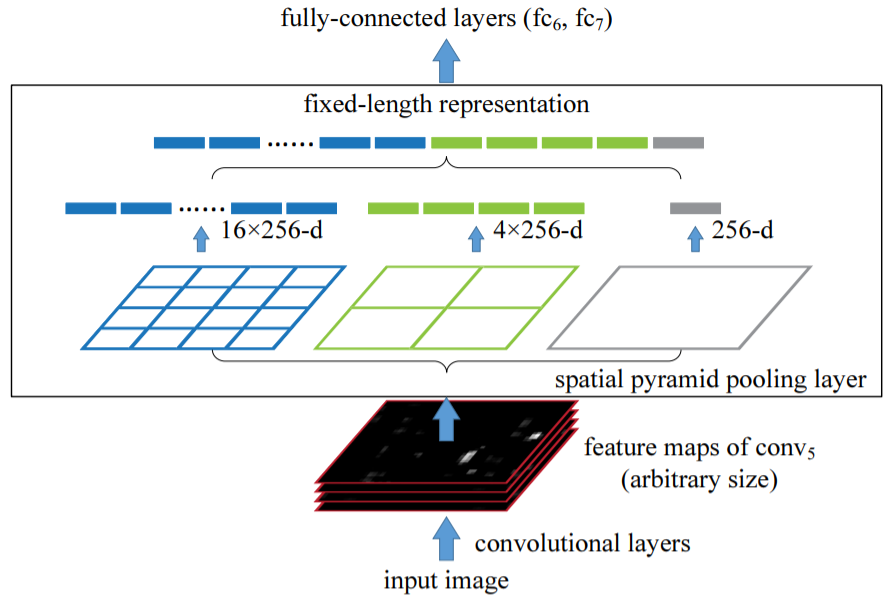
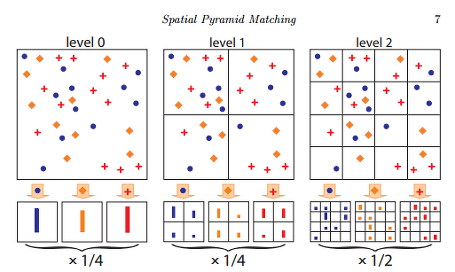
SPP구조는 2-stage detector 초창기 모델인 R-CNN을 개량하기 위해 탄생한 SPPNet에서 비롯되었습니다.
R-CNN은 selective search로 뽑은 region proposal과 CNN을 결합하여 object detection을 수행하고자 했던 모델입니다.
하지만 R-CNN모델은 끝단에 FC(Fully connected layer)가 붙어있기 때문에 CNN의 output channel이 미리 설계된 FC의 노드 수와 일치해야 했고, 이는 곧 최초 input이미지를 모두 같은 사이즈로 스케일링 해야 한다는 단점으로 이어졌습니다.
SPPNet은 이러한 단점을 해결하고자 FC로 들어가기 직전에 pooling을 통해 feature를 정해진 규격으로 제한하여 최초 input이미지의 크기를 자유롭게 지정할 수 있도록 하였습니다.
이렇게 FC로 인한 문제를 해결하는 것이 주된 목적이었던 SPP였으나 본 논문에서는 YOLOv4에서 SPP구조를 사용한 이유를 Receptive Field를 키워 검출력을 높이기 위함이라고 언급하였습니다.
구체적인 내용은 언급되지 않았으나 전체 이미지에 대해 다양한 grid를 적용하여 pyramid형태로 쌓는 것이 곧 Resecptive field를 확장으로 이어지는 것이 아닐까 추측하였습니다.
SAM(Self-Attention Module)
PAN(Path Augmented Network)
YOLO v3
CIoU(Complete IoU)
Mish
DIoU NMS
3.2 Selection of BoF and BoS
Bag of freebies
Bag of Freebies, 일명 BoF는 추론 비용은 유지하고 학습 비용만 증가시켜 모델의 성능을 향상시키는 방법론을 뜻합니다. 대표적인 BoF로 Data Augmentation, Label Smoothing이 있습니다.
1) Data augmentation
- Pixel-wise adjustment
픽셀의 위치와 정보는 유지한 채 값만 변경하는 방식입니다.
- Simulating object occlusion
객체가 가려지거나 서로 겹치는 상황에서 모델로 하여금 대응력을 갖출 수 있도록 하는 방법입니다.
Dataset형성 단계에서 적용되는 기법(image-level)과, 네트워크 내에서 적용되는 기법(featuremap-level)이 있습니다.
- Image Level
YOLOv4는 이 중 CutMix 를 사용하였습니다.
- Feature Map Level
YOLOv4는 기존의 DropOut, DropConnect와 같은 Random하게 drop하는 방식은 인접한 픽셀간에 높은 연관성을 갖는 이미지 데이터의 특성과는 맞지 않다고 판단하여 DropBlock 을 사용하였습니다.
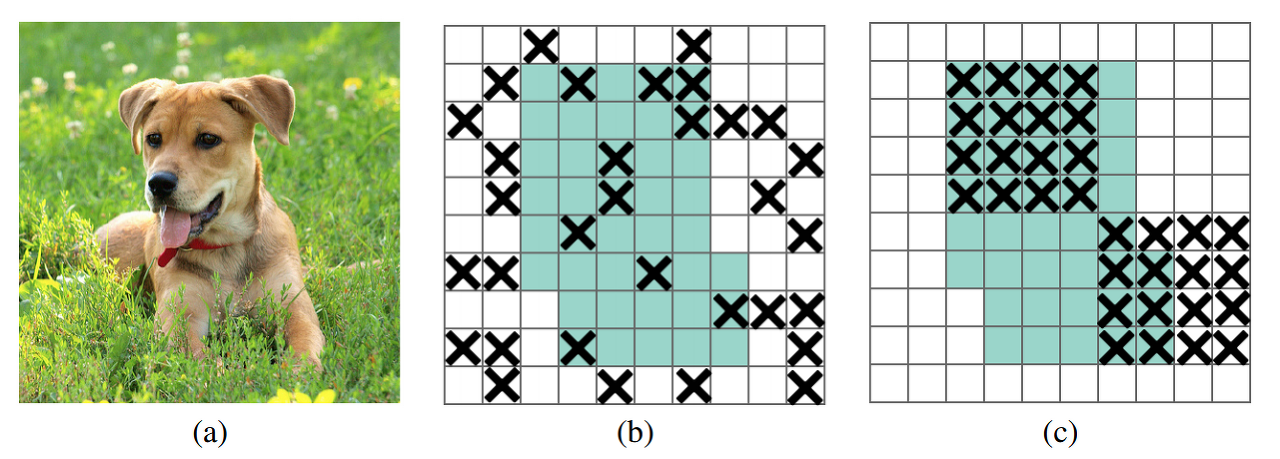
DropBlock은 Feature Map 내에서 연속하는 영역의 activation을 0으로 만들어 네트워크에 규제효과를 주는 효과를 갖고 있습니다.
아래 사진의 (b)가 종래의 random방식이라면 (c)가 DropBlock방식입니다.


2) Semantic distribution bias
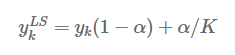
- K : 클래스 수
- α : 스무딩 파라미터
클래스의 수가 5(K=5)이고, 클래스2가 정답인 라벨에 대해서 다음과 같이 계산합니다. (α=0.1)
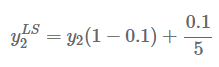
라벨 스무딩 전후 차이는 다음과 같습니다.
Hard 라벨 : [0, 1, 0, 0, 0]
Soft 라벨 : [0.02, 0.92, 0.02, 0.02, 0.02]
YOLOv4는 서로 다른 클래스간의 의미 분포가 편향되는 현상을 막기 위해 Label Smoothing을 사용하였습니다.
Hard 라벨 사용시 정답인 클래스에만 1을 부여하고 나머지 클래스에는 0이 부여되기 때문에 cross entropy loss를 최소화하는 과정에 나머지 클래스에 대한 logit이 기여하는 바가 전혀 없으므로 클래스 간의 의미차이를 학습하지 못하게 됩니다.(*1)
하지만 Label Smoothing 을 통해 생성한 Soft 라벨은 정답이 아닌 클래스에 대해서도 작지만 일정 확률을 가지고 있으니 예측값 pred를 정답 템플릿과 가깝게 하는 한편 오답 템플릿과는 동일한 거리로 먼 간격을 유지하게끔 하는 효과가 있습니다. (같은 클래스끼리 잘 뭉친다고 보시면 될 것 같습니다.)
*1
- n : 데이터 수
- C : 클래스 수
- Hard : Hard 라벨
- Soft : Soft 라벨
- P : 실제 값에 대한 확률 값 (0~1)
C=3, n=2, Hard=[0, 0, 1], Soft=[0.03, 0.03, 0.94] 라고 가정했을 때,
P_1=[0.1, 0.2, 0.7] 일 때 cross entropy loss는 다음과 같습니다. (위에서부터 Hard, Soft 순)-0 × log(0.1) -0 × log(0.2) -1 ×log(0.7) = -log(0.7) = 0.35
-0.03 × log(0.1) -0.03 × log(0.2) -0.94 ×log(0.7) = 0.069 + 0.069 + 0.335 = 0.473P_2=[0.15, 0.15, 0.7] 일 때 cross entropy loss는 다음과 같습니다.
-0 × log(0.15) -0 × log(0.15) -1 ×log(0.2) = -log(0.7) = 0.35
-0.03 × log(0.15) -0.03 × log(0.15) -0.94 ×log(0.7) = 0.057 + 0.057 + 0.336 = 0.45Hard 라벨의 경우 정답이 아닌 클래스의 logit의 계수가 0으로 할당되면서 Loss값에 전혀 영향을 주지 못하는 모습을 볼 수 있습니다.
반면 Soft 라벨의 경우 정답 클래스 logit이 같은 상황에서 다른 클래스 logit간의 표준편차가 클수록 Loss값을 크게 할당하여 최대한 같은 값을 유지하는 방향으로 학습할 수 있게됩니다.
이럴 경우 모델은 정답 클래스의 logit값을 1에 맞추는 데에만 집중하고 나머지 클래스에 대한 logit값을 낮추어 클래스 간의 의미 차이를 학습하는 과정은 겪지 못하게 됩니다.
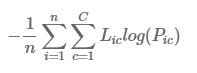
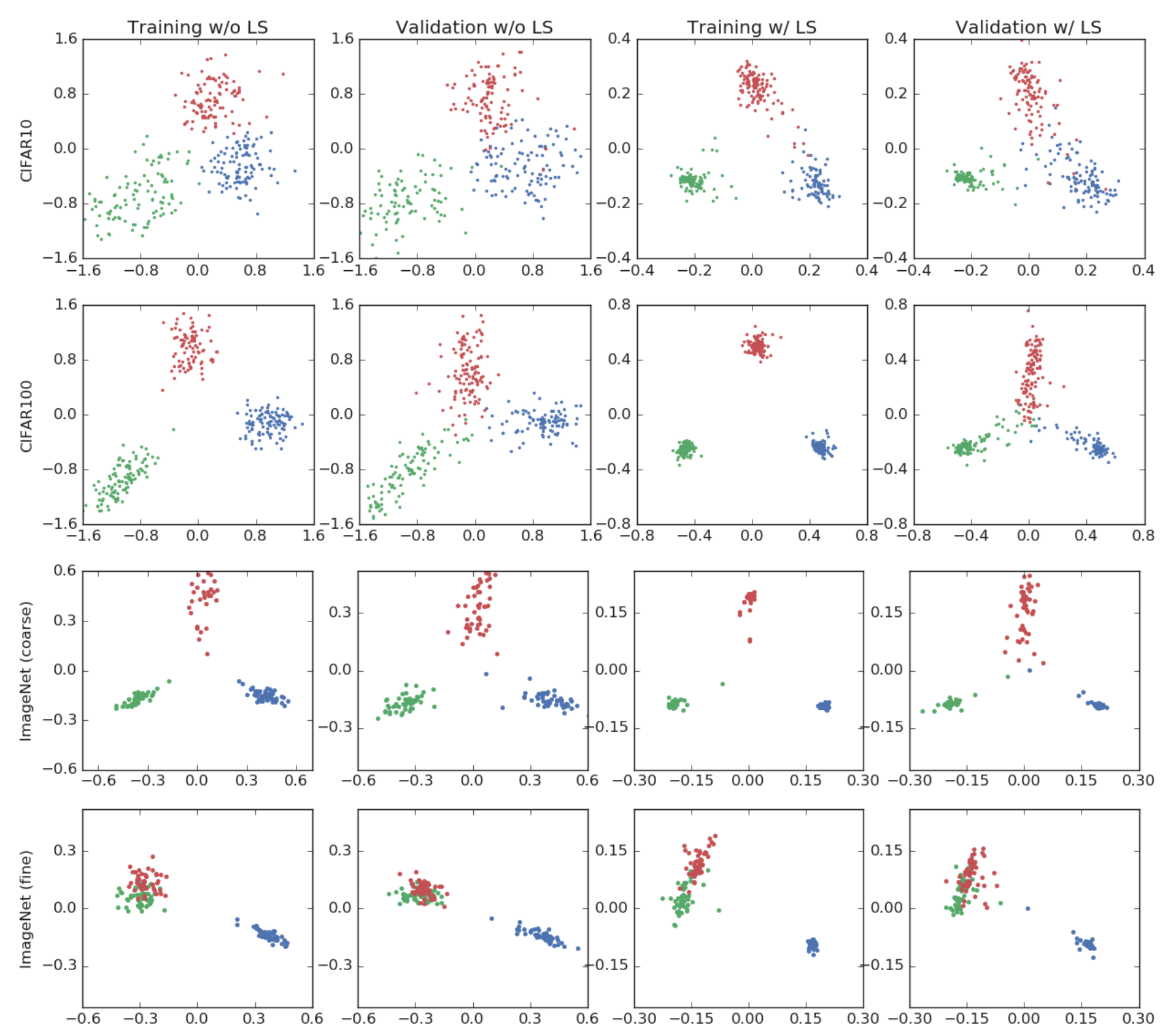
모델이 학습한 결과를 초평면에 나타낸 아래 사진에서 Label Smoothing 적용 여부에 따른 예측값 분포 차이를 확인할 수 있습니다.
Bag of specials
Bag of specials, 일명 BoS는 추론 비용을 약간 높이되 그를 상회할 정도의 모델 성능향상을 도모하는 방법론을 뜻합니다. 대표적인 BoS로는 receptive field확장, attention
mechanism도입, feature integration능력 강화 등이 있습니다.
3.3. Additional improvements
3.4. YOLOv4
4. Experiments
본 논문에서는 모델 성능 향상을 위해 다양한 실험을 진행하였습니다.
1) Classifier 학습 시 label smoothing, data augmentation이 주는 영향에 대한 실험
2) Detector 학습 시 서로 다른 feature의 영향에 대한 실험
3) Detector 학습 시 서로 다른 backbone과 pretrained weight의 영향에 대한 실험
4) Detector 학습 시 mini-batch 크기에 따른 영향에 대한 실험
5. Results
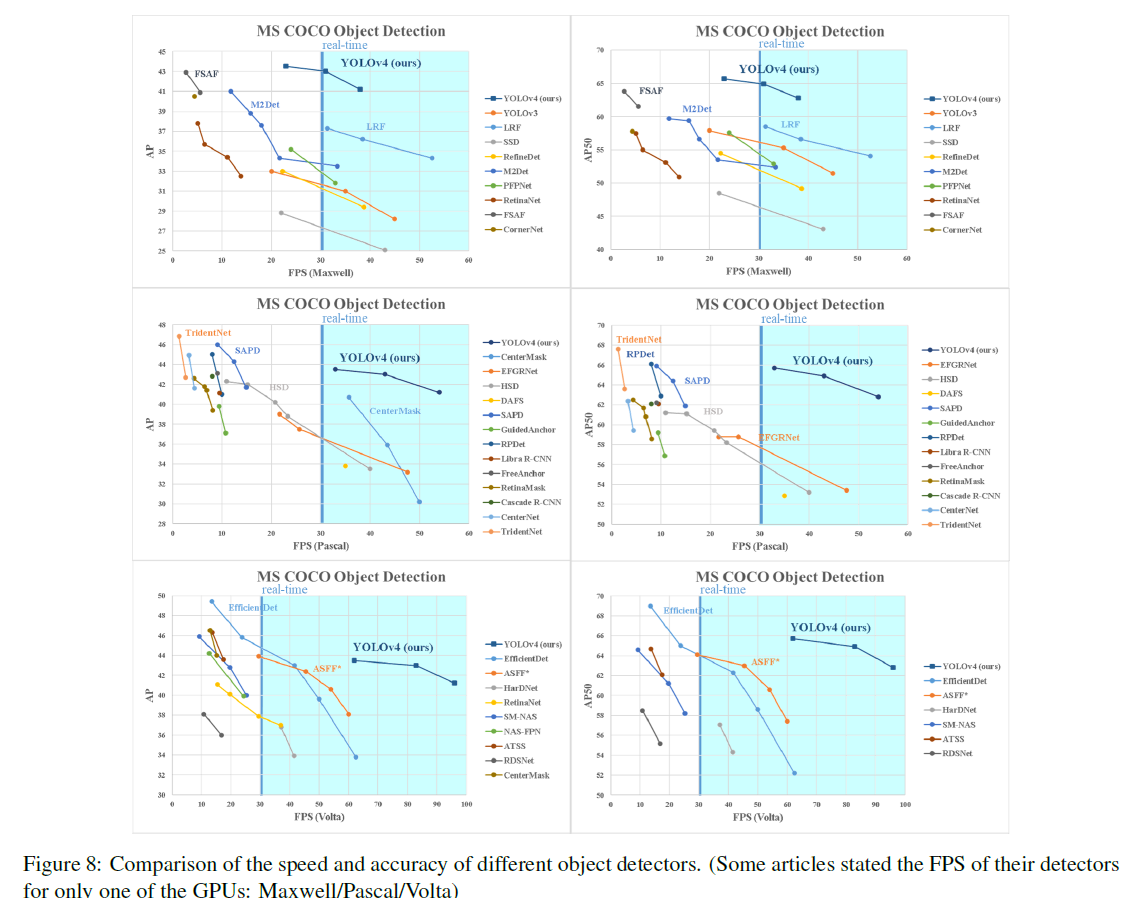
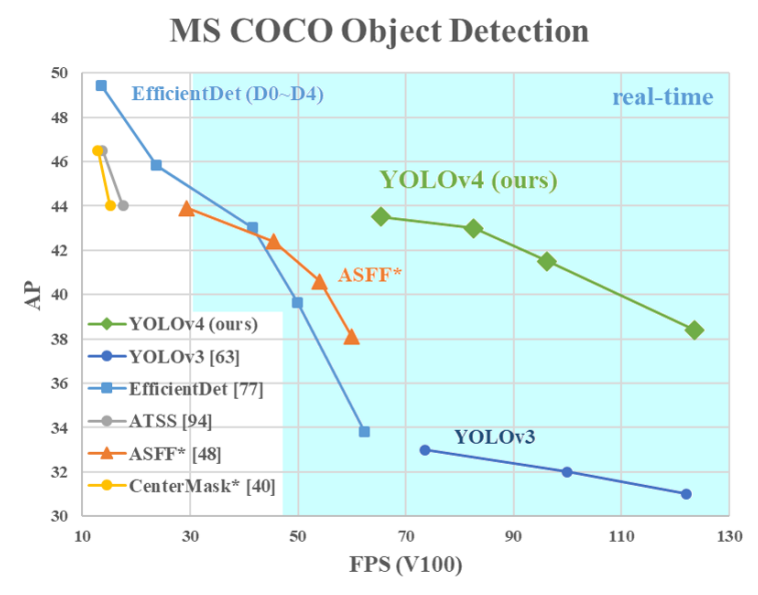
다양한 object detector와 YOLO v4와의 성능 비교
위와 같은 실험을 토대로 YOLO v4와 다양한 object detector와의 성능을 비교한 결과, YOLO v4는 파레토 최적(Pareto optimality) 곡선에 위치합니다. 이는 곧 추론 속도가 가장 빠르며, 정확도 역시 가장 높음을 의미합니다.
YOLO v4는 MS COCO 데이터셋에서 43.5%라는 AP 값을 보이며, 당시 SOTA 성능을 보였습니다. 또한 Tesla V100 GPU에서 65 FPS라는 매우 빠른 추론 속도를 보였습니다. 뿐만 아니라, 다양한 방법을 적용하여 기존에 사용하던 상대적으로 낮은 성능의 GPU에서도 빠른 학습 및 추론에도 기여했습니다.
6. Conclusions
YOLOv4가 달성한 바는 크게 세 가지로 요약됩니다.
1. 누구나 1080Ti, 2080Ti와 같은 일반용 GPU를 사용하여 빠르고 정확한 object detector를 학습시킬 수 있습니다.
2. detector 학습과정에 Bag-of-Freebies 및 Bag-of-Specials 방법론을 적용함으로서 얻는 효과를 확인하였습니다.
3. 당시의 Sota방법론에 CBN, PAN, SAM등의 다양한 기법을 적용하여 하나의 GPU에서 학습 및 추론을 가능케 하였습니다.

안녕하세요 글 잘 봤습니다 감사합니다! 혹시 논문 찾으실 때 주로 어디서, 어떤 키워드로 보통 찾으시나요?