
SKTBrain의 KoBERT를 이용해 Text Classification을 수행해보자. KoBERT는 구글 BERT base multilingual cased의 한국어 성능 한계를 이유로 SKTBrain에서 개발된 기계번역 모델이다. Naver Sentiment Analysis(nsmc) task에 대해서도 BERT base multilingual cased는 0.875의 acc, KoGPT2는 0.899의 acc를 보이는 반면 KoBERT는 0.901의 정확도를 보이는 것으로 알려져 있다. KoBERT의 사용방법에 대한 자세한 설명은 SKTBrain의 KoBERT Repo에서 확인할 수 있다.
본 포스트에서는 BERT 모델의 구조나 동작 과정에 대해서는 다루지 않으며 KoBERT를 이용하여 다중분류를 수행하는 코드에 대해서만 다룰것이다. 본 포스트에서 리뷰하는 다중분류 코드는 SKTBrain이 친절히 제공하고 있는 Colab 코드이며, 여기에서 확인할 수 있다.
- Colab
- pytorch_kobert_model 사용
- transformers = 3.0.2
확인 해두어야할 기본 셋팅은 위와 같으며, GPU를 사용하였고 고용량 RAM(Colab pro)으로 설정해주었다. 데이터셋의 크기에 따라 Colab pro를 사용하지 않는 이상 램이 터지(?)는 일이 빈번하게 발생하므로, 부족하다면 부족하지만 한달 만원내고 12->25GB로 업그레이드하자. 💸만원💸의 행복! 그럼 코드를 보도록 하자.
SETTINGS
필요한 라이브러리와 모듈은 아래와 같다. 깃허브에서 KoBERT도 설치해준다.
!pip install mxnet
!pip install gluonnlp pandas tqdm
!pip install sentencepiece
!pip install transformers==3.0.2
!pip install torch!pip install git+https://git@github.com/SKTBrain/KoBERT.git@masterimport torch
from torch import nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import gluonnlp as nlp
import numpy as np
from tqdm import tqdm, tqdm_notebook
from kobert.utils import get_tokenizer
from kobert.pytorch_kobert import get_pytorch_kobert_model
from transformers import AdamW
from transformers.optimization import get_cosine_schedule_with_warmup아래는 gpu 사용 시 실행해주어야 하는 코드이다. 아래 코드를 실행하면 device가 gpu로 설정된다. 해당 코드로 device를 선언한 후, 이후 코드에서 연산량이 많아 gpu 연산을 사용할 부분(ex loss 연산) 뒤에 .to(device) 를 붙여 gpu를 사용해줄 수 있다. 후에 gpu 연산이 수행되는 부분에서 다시 한 번 설명하겠다.
📌 cpu를 사용시에는 아래 device 선언을 생략하고 다음 코드부터 실행해주면 된다.
##GPU 사용 시
device = torch.device("cuda:0")kobert 모델과 vocab을 불러오는 부분이다.
#bert 모델, vocab 불러오기
bertmodel, vocab = get_pytorch_kobert_model()DATASET
dataset_train = nlp.data.TSVDataset('/content/drive/MyDrive/train.tsv', field_indices=[1,2], num_discard_samples=1)
dataset_test = nlp.data.TSVDataset('/content/drive/MyDrive/validation.tsv', field_indices=[1,2], num_discard_samples=1)train과 test 데이터를 불러오고 있다. /content/drive/MyDrive/train.tsv, /content/drive/MyDrive/validation.tsv 부분을 본인의 데이터셋에 맞게 수정해주면 된다. 코랩의 드라이브 마운트 기능을 이용하면 편리하게 데이터를 불러오고 저장할 수 있다. dataset_train에는 train set, dataset_test에는 validation set의 tsv 파일을 넣어주면 된다. 또한 사전에 train_test_split을 이용하여 train data를 train/validation으로 나누어 tsv로 저장해둔 후 위 코드로 불러오면 편리할 것이다.
그럼 nlp.data.TSVDataset()에 대해 알아보자.
1️⃣ 첫번째 파라미터는 본인이 적용하고 싶은 데이터의 파일명이다.(당연하게도, tsv 파일이여야 한다)
2️⃣ 두번째 파라미터 field_indices=[1,2]는 다음을 의미한다. [학습시킬 데이터의 인덱스, 데이터 레이블의 인덱스]
3️⃣ 세번째 파라미터 num_discard_samples는 데이터의 상단에서 제외할 row의 개수를 의미한다. default 값은 0이다.
dataset_train, dataset_test가 어떻게 생겨야 하냐, 한번 찍어보자. 이렇게 생기면 된다.
dataset_train[0]## output ##
['치주질환 원인 인 제어용 식물항체백신 개발치주질환은 세균감염질환으로서 만성염증을 초래하여 성인에서 치아상실을 유발하는 가장 중요한 원인 최근 기술 등이 발전하면서 새로운 치주질환 원인균이 밝혀지고 이들 원인균의 치주질환병인과정에서의 역할이 활발히 연구되고 있음 는 새로 밝혀진 원인균 중에서 가장 중요한 균으로 주목받고 있으며 최근에는 치주조직파괴에 직접적으로 관여하는 중요한 로 알려지고 있음 본 연구의 목표는 를 억제하는 수동면역백신으로 사용할 식물항체를 생산하는 것 이를 위해 첫 단계로 마우스에서 단클론항체를 생산하고 와 반응하여 응집을 일으키는 항체를 선택 이들 응집 항체 중에서 의 감염을 가장 잘 억제하는 항체를 선정하고 이와 반응하는 항원단백질을 표적항원 백신후보항원 또는 보호항원 으로 발굴한 다음 표적항원에 대한 단클론항체의 유전자를 클로닝하여 벼 를 형질전환시키고 이 형질전환 벼 의 현탁배양을 통해 식물항체를 생산하는 것 생산한 식물항체는 치주질환 동물모델을 사용하여 감염억제효과를 확인 본 연구자는 이미 전균 을 마우스에 주사하여 다양한 단클론항체 를 생산하였고 이 중에서 를 강하게 응집시키는 즉 를 제어하는데 유리한 균 표면항원에 대한 단클론항체를 개 선택하였음 본 연구에서는 선택된 항체가 실제 표면항원에 대한 것인지를 으로 확인 단클론항체들의 대식세포 탐식 및 사멸 증진효과 의 숙주세포침투 억제효과를 확인하여 가장 우수한 효과를 보인 단클론항체를 표적항원의 항체로 선택 확인 선택된 항체와 반응하는 표적항원을 결과를 로 하여 에서 분리 분리된 항원은 - 로 단백질분석하여 에 등록된 동일 항원단백질의 유전자를 동정 선행연구에서 개의 항체 중 개는 이미 - - 와 반응하는 것으로 동정되었음 에 등록된 동일 단백질 유전자의 염기서열을 토대로 표적항원을 클로닝하여 염기서열분석 얻어진 표적항원 유전자의 실제 염기서열을 토대로 표적항원을 클로닝하여 표적항원의 재조합단백질 제조 제조한 재조합단백질에 대해 단클론항체가 반응하는 지를 확인함으로써 동정한 단백질이 실제 표적항원임을 검증 이후 검증된 표적항원에 대한 단클론항체를 생산하는 세포에서 항체의 유전자를 분리하여 식물발현벡터에 클로닝한 다음 벼 를 형질전환시키고 형질전환된 벼 의 세포현탁배양을 통해 식물항체를 생산하고 그 감염억제효과를 치주질환 동물모델을 사용하여 확인 치주질환은 복합균 감염질환이고 그 중심에는 와 가 있기 때문에 동물모델에 이 두 가지 세균을 감염시키고 이미 개발된 의 식물항체 그리고 이번 연구과제에서 개발될 의 식물항체를 함께 사용하여 치주질환 억제효과를 관찰할 계획 학문적 기대효과 의 중요성을 제시하고 국내 연구자들의 관심을 유도 치주조직의 염증 파괴 방어 보호 등 치주질환 병인론의 이해를 통해 손상 차단 및 치료 표적항원 발굴 전략을 위한 이론적 기초 제공 각종 질병의 유발기전에 기여하는 중요 원인균의 항원단백질 발굴 및 규명 연구에 이용 기술적 파급효과 제어분야에서 기술적으로 선도역할을 할 수 있는 계기를 마련 치주질환 원인균 감염 진단 또는 치주질환 예후 예측법 개발에 활용 본 연구의 표적항원 선택과 검증 전략은 백신관련 연구에 중요한 기반자료로 활용 표적항원 탐색기술을 다른 유기체 내 단백질 표적 탐색에 응용 치주질환 제어기술은 염증질환과 골대사 질환 등 다양한 질환 치료에 이용 가능 경제 사회적 기대효과 구강건강뿐만 아니라 치주질환으로 인해 야기될 수 있는 전신질환의 예방 또는 개선 의료비용 경감으로 인한 개개인 재정적 삶의 질 향상 개개인 노동력 회복으로 산업 활동이 보장되어 결과적으로 국가적으로도 경제적 이익 구강과 전신의 건강으로 국민 특히 노년층의 삶의 질 향상',
'0']토큰화, 패딩, 어텐션 마스크, 배치 및 데이터로더 설정
데이터셋을 불러왔다면, 이제 KoBERT의 입력이 될 수 있도록 데이터를 가공해주어야 한다. KoBERT의 입력 데이터로 만들어주기 위해서는, 토큰화와 패딩, 어텐션 마스크를 만들어주는 과정을 거쳐 torch의 dataloader로 변환시켜 주어야 한다.
SKTBrain은 토큰화, 패딩, 어텐션 마스크를 만들어주는 BERTDataset이라는 클래스를 제공하고 있다.
class BERTDataset(Dataset):
def __init__(self, dataset, sent_idx, label_idx, bert_tokenizer, max_len,
pad, pair):
transform = nlp.data.BERTSentenceTransform(
bert_tokenizer, max_seq_length=max_len, pad=pad, pair=pair)
self.sentences = [transform([i[sent_idx]]) for i in dataset]
self.labels = [np.int32(i[label_idx]) for i in dataset]
def __getitem__(self, i):
return (self.sentences[i] + (self.labels[i], ))
def __len__(self):
return (len(self.labels))BERTDataset 클래스는 tsv dataset과 dataset의 sent_idx, dataset의 label_idx, 버트 토크나이저, max_len, pad와 pair에 대한 bool값을 인자로 받아 토큰화, 패딩을 하고 어텐션 마스크를 만들어 inputs, labels, masks들을 TensorDataset으로 변환해 뱉어준다. 클래스 내부를 보면 BERTSentenceTransform 모듈을 이용하고 있는 것을 확인할 수 있다.
BERTDataset 클래스를 사용하기 전에, 파라미터 값을 세팅해준다. 본 포스팅에서 파라미터 값은 별다른 튜닝을 거치지 않았으며 SKTBrain의 예시 파라미터 값을 그대로 이용하였다.
## Setting parameters
max_len = 64
batch_size = 64
warmup_ratio = 0.1
num_epochs = 5
max_grad_norm = 1
log_interval = 200
learning_rate = 5e-5아래는 앞서 설명한 BERTDataset 클래스를 선언하는 코드이다. 토크나이저로는 BERTSPTokenizer를 이용하였으며, 앞서 불러온 tsv 데이터셋, tsv 데이터셋에서 학습시킬 문장의 위치 인덱스, 학습시킬 라벨 인덱스, 선언한 토크나이저, max_len, pad = True, pair = False를 인자로 넣어주었다. tsv dataset의 형태나 토크나이저, max_len에 따라 각자 데이터셋에 맞게 아래 코드를 응용해주면 된다.
#토큰화
tokenizer = get_tokenizer()
tok = nlp.data.BERTSPTokenizer(tokenizer, vocab, lower=False)
#BERTDataset 클래스 이용, TensorDataset으로 만들어주기
data_train = BERTDataset(dataset_train, 0, 1, tok, max_len, True, False)
data_test = BERTDataset(dataset_test, 0, 1, tok, max_len, True, False)BERTDataset 클래스를 통해 토큰화와 패딩을 거친 inputs, labels, 또 attention masks까지 포함하고 있는 TensorDataset을 만들어 주었으면, 배치 및 데이터로더를 설정할 차례다. 아래 코드를 통해 train과 test 각각의 배치 및 데이터로더를 설정한다. 첫번째 인자로는 TensorDataset이 들어간다. 우리의 경우 위에서 BERTDataset 클래스를 이용해서 만들어준 data_train, data_test를 넣어주면 된다.
버트에서 배치사이즈의 경우 현재 쓰고 있는 GPU의 VRAM에 맞도록 배치 사이즈를 설정한다. 우선 배치사이즈를 크게 넣어보고 VRAM 부족 메세지가 나오면 8의 배수 중 더 작은 것으로 줄여나가면 된다. 해당 코드의 경우 앞서 파라미터 세팅에서 batch_size를 64로 설정하였다.
num_workers는 학습 도중 CPU의 작업을 몇 개의 코어를 사용해서 진행할지에 대한 설정 파라미터이다. 해당 환경에서 사용 가능한 코어의 개수를 확인해보고 학습 외의 작업에 영향을 주지 않을 정도의 숫자로 설정해주시는 것이 좋다. 해당 코드의 경우 4로 설정하였다.
#배치 및 데이터로더 설정
train_dataloader = torch.utils.data.DataLoader(data_train, batch_size=batch_size, num_workers=4)
test_dataloader = torch.utils.data.DataLoader(data_test, batch_size=batch_size, num_workers=4)KoBERT 모델링
class BERTClassifier(nn.Module):
def __init__(self,
bert,
hidden_size = 768,
num_classes=46, ##주의: 클래스 수 바꾸어 주세요!##
dr_rate=None,
params=None):
super(BERTClassifier, self).__init__()
self.bert = bert
self.dr_rate = dr_rate
self.classifier = nn.Linear(hidden_size , num_classes)
if dr_rate:
self.dropout = nn.Dropout(p=dr_rate)
def gen_attention_mask(self, token_ids, valid_length):
attention_mask = torch.zeros_like(token_ids)
for i, v in enumerate(valid_length):
attention_mask[i][:v] = 1
return attention_mask.float()
def forward(self, token_ids, valid_length, segment_ids):
attention_mask = self.gen_attention_mask(token_ids, valid_length)
_, pooler = self.bert(input_ids = token_ids, token_type_ids = segment_ids.long(), attention_mask = attention_mask.float().to(token_ids.device))
if self.dr_rate:
out = self.dropout(pooler)
return self.classifier(out)SKTBrain에서 제공하는 BERTClassifier다. 가장 주의해주어야 할 부분은 ## 주석 ##으로 표기해 둔 num_classes를 선언하는 부분이다. 버트의 input 형식, 토큰화, 패딩, attention mask 등 버트에 대한 이해 없이 KoBERT를 통해 한국어 텍스트 분류만 수행하고 싶다면 tsv 데이터만 잘 불러와주고 위 코드의 num_classes만 본인이 분류하고 싶은 클래스의 개수로 고쳐준다면 무리없이 KoBERT를 이용한 한국어 다중분류를 수행할 수 있다. 해당 포스트의 경우 46개의 클래스로 분류하는 모델을 만들어주어야 해서 num_classes를 46으로 설정해 두었다.
model = BERTClassifier(bertmodel, dr_rate=0.5).to(device) #gpu버트 모델을 불러와 준다. gpu로 해당 코드를 돌릴 경우 뒤에 .to(device)가 필요하며, cpu를 사용시에는 위 코드에서 .to(device)를 제거하고 모델을 불러와주면 된다. 다만 gpu의 사용을 권장한다.
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=learning_rate)
loss_fn = nn.CrossEntropyLoss()
t_total = len(train_dataloader) * num_epochs
warmup_step = int(t_total * warmup_ratio)
scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=warmup_step, num_training_steps=t_total)위는 학습을 위한 옵티마이저와 스케쥴러를 선언해주는 부분이다.
def calc_accuracy(X,Y):
max_vals, max_indices = torch.max(X, 1)
train_acc = (max_indices == Y).sum().data.cpu().numpy()/max_indices.size()[0]
return train_acc정확도 측정을 위해 함수를 정의하고 있다. 여기까지 코드 실행을 완료했다면 학습을 위한 모든 준비가 끝났다!
학습
for e in range(num_epochs):
train_acc = 0.0
test_acc = 0.0
model.train()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm_notebook(train_dataloader)):
optimizer.zero_grad()
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
loss = loss_fn(out, label)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
train_acc += calc_accuracy(out, label)
if batch_id % log_interval == 0:
print("epoch {} batch id {} loss {} train acc {}".format(e+1, batch_id+1, loss.data.cpu().numpy(), train_acc / (batch_id+1)))
print("epoch {} train acc {}".format(e+1, train_acc / (batch_id+1)))
model.eval()
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm_notebook(test_dataloader)):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
label = label.long().to(device)
out = model(token_ids, valid_length, segment_ids)
test_acc += calc_accuracy(out, label)
print("epoch {} validation acc {}".format(e+1, test_acc / (batch_id+1)))위 코드가 KoBERT 모델을 우리의 데이터로 학습시켜주는 과정이다. 데이터의 크기와 Batch size, epoch에 따라 학습시간은 상이할 것이다.
또한 앞서 설명했듯 코드에서 연산량이 많아 gpu 연산을 사용할 부분 뒤에는 .to(device) 를 붙여 gpu를 사용해주고 있다. 전 과정에서 cpu만을 사용하여 앞선 코드에서 device를 따로 gpu로 선언해주지 않았다면, 위 코드의 .to(device)를 제거하고 실행해주면 된다.
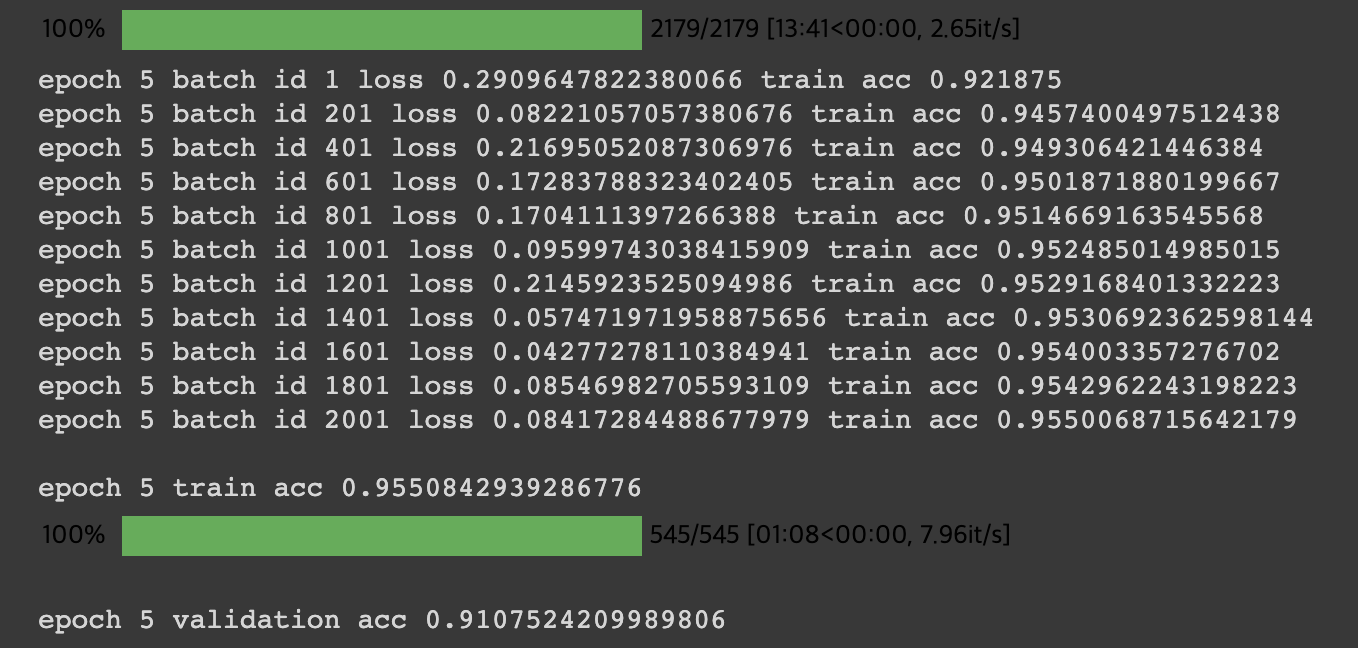
위 사진을 보면, label 0~45의 46중분류를 수행하는 KoBERT Classifier가 epoch 5회 만으로도 train acc 0.95, val acc 0.91로 아주 준수한 성능을 보이는 것을 확인할 수 있다.(물론 훈련 데이터양이 좀 많았다🥰)
테스트
학습시킨 모델로 새로운 문장들을 분류해보자.
new_test = nlp.data.TSVDataset('/content/drive/MyDrive/test.tsv', field_indices=[1,2], num_discard_samples=1)
test_set = BERTDataset(new_test , 0, 1, tok, max_len, True, False)
test_input = torch.utils.data.DataLoader(test_set, batch_size=1, num_workers=4)KoBERT를 학습시킬 때 BERT의 input으로 변환시켜준 과정을 동일히 테스트 데이터에도 적용한다. 먼저 TSVDataset()으로 field_indices에 sentence의 index, label의 index를 지정해 tsv data를 불러온다. 앞서 선언한 BERTDataset class를 이용해 토큰화, 패딩, attention 마스크를 만들어주는 과정을 거쳐 tensor dataset으로 바꿔준다. 마지막으로 DataLoader()로 배치사이즈와 데이터로더를 설정해준다.
코드를 이용할 분들을 위해 본 포스트에서는 새로운 문장들을 분류할 때 print문으로 문장별 예측 분류값을 하나씩 뱉고 있으므로, 편의상 batch_size를 1로 설정했다.
for batch_id, (token_ids, valid_length, segment_ids, label) in enumerate(tqdm_notebook(test_input)):
token_ids = token_ids.long().to(device)
segment_ids = segment_ids.long().to(device)
valid_length= valid_length
out = model(token_ids, valid_length, segment_ids)
prediction = out.cpu().detach().numpy().argmax()
print(batch_id + "번째 문장의 분류 예측값은" + prediction + "입니다.")위 코드에서는 학습시킨 KoBERT 모델에 테스트할 새로운 문장들의 데이터 로더를 넣어주고, for문을 돌려 한 문장마다 예측 분류 값을 프린트해주고 있다. batch_size나 마지막 print문 라인을 본인의 목적에 맞게 수정한다면, 새로운 문장들에 대한 라벨링 결과를 얻을 수 있을 것이다.
About Error
(GPU 이용시) RuntimeError: CUDA error: device-side assert triggered
GPU 에러 중 device-side assert triggered 에러는 이유를 알 수 없는 GPU 에러로 종종 명명되곤 한다. 물론 에러의 원인이야 있겠지만, 워낙 다양한 이유로 호출되는 에러라 에러문만을 가지고는 디버깅이 참 어렵다.
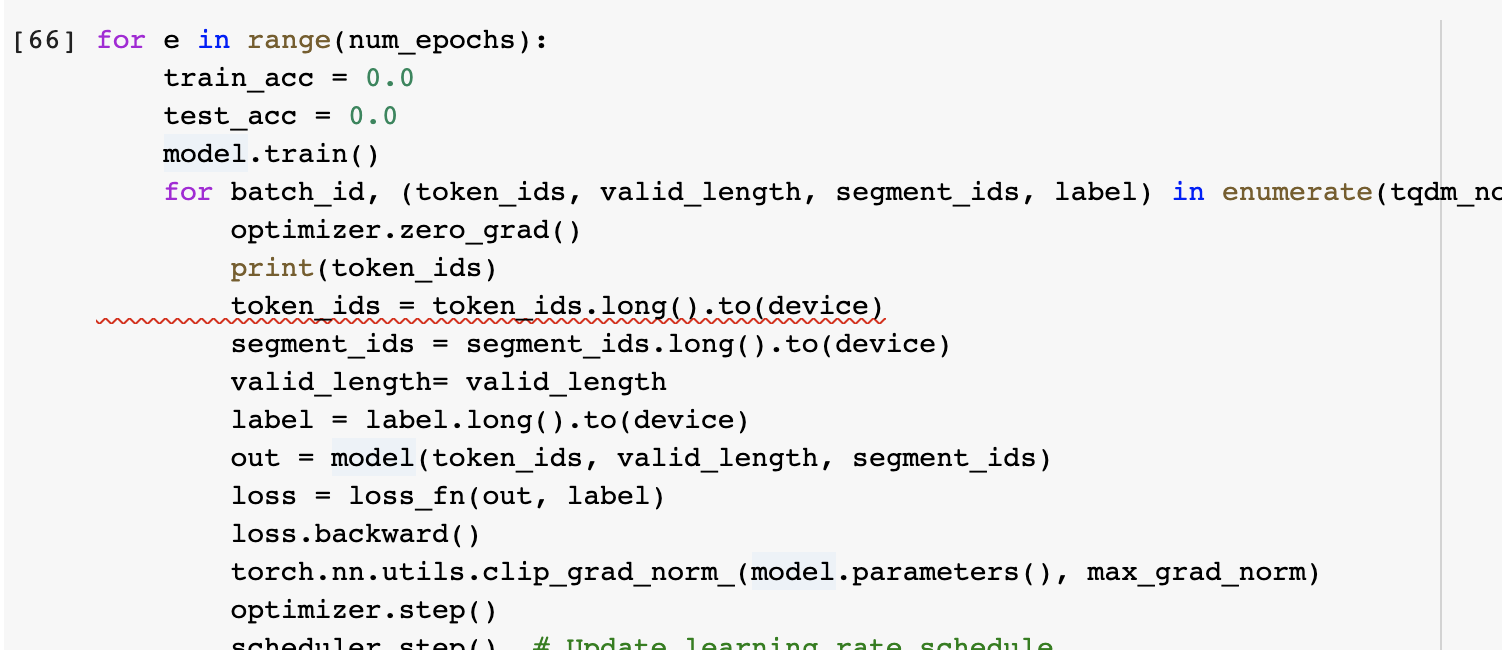

본 포스팅의 학습 부분(여기) 코드를 돌리다, RuntimeError: CUDA error: device-side assert triggered 에러를 마주쳤다. 물론 다른 이유로 인해 동일 에러가 발생한 경우도 있겠지만, 나와 같은 이유로 device side assert triggered 에러를 마주한 이들을 위해 추가로 포스팅한다.
중요한 것은, RuntimeError: CUDA error: device-side assert triggered 에러와 같은 GPU에러를 마주쳤을 때 대부분 colab의 런타임 유형을 CPU로 전환시킨 뒤 똑같이 코드를 실행, 에러를 다시 한번 띄워주면 보다 유용한 traceback error을 띄워준다는 점이다.
CPU로 전환시킨 뒤 똑같은 에러를 다시 한 번 발생시켰더니 다음과 같은 에러가 발생했다.
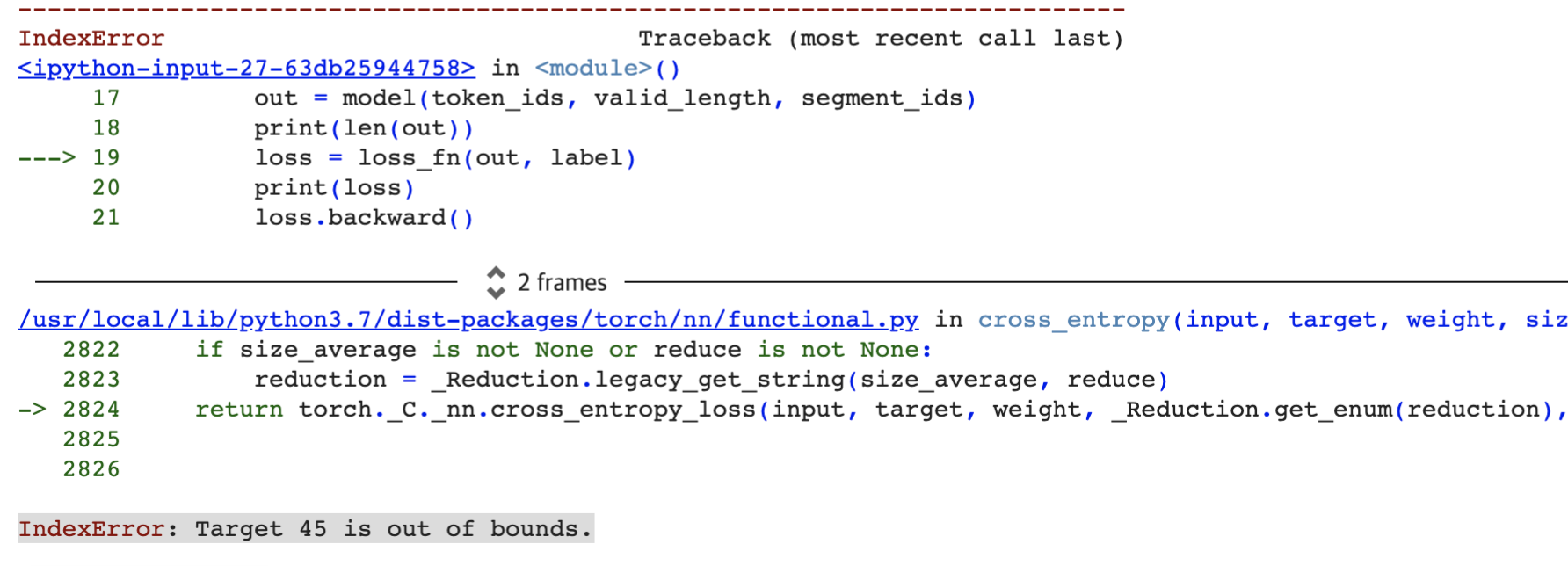
IndexError: Target n is out of bounds
해당 에러는 인덱스 에러와 비슷한 에러로, class 분류시 class가 0에서부터 시작하지 않고 1과 같은 다른 숫자에서부터 시작했기 때문에 발생하는 에러이다.
실제로 본 포스팅에서 text classification 수행시, 1부터 시작하는 class label로 분류를 시도했었다.
따라서 위와 같은 에러를 직면하게 되면, class label을 0에서부터 시작하는 것으로 수정해주면 쉽게 에러를 해결할 수 있다.
Pytorch는 원핫인코딩을 하지 않기 때문에 분류 태스크 수행 시 라벨을 0부터 시작해줘야 한다는 점, 기억하도록 하자!👍🥺

안녕하세요. 좋은 정보 감사합니다. 혹시 학습시킨 model을 저장해서 local에서 돌릴 수 있는 방법이 있을까요?