Day 1
- CLI
- Docker LifeCycle
Docker
- 어플리케이션 실행 환경을 코드로 작성할 수 있고 OS를 격리화하여 관리하는 기술
- 리소스 격리성을 제공하는 기술 중 하나
- 하나의 컴퓨터에서 여러개의 컴퓨터를 이용하는 것
- 리눅스에서 돌아가는 프로그램을 PC에서 동작할 수 있도록 제공하는 것 + 쉽고(Dockerfile), 빠르게(Container)
Linux Container
- 리눅스 기반의 기술 중에 하나로 필요한 라이브러리와 어플리케이션을 모아서 마치 별도의 서버처럼 구성한 것
- 프로세스의 구획화
- 특정 컨테이너에서 작동하는 프로세스는 기본적으로 그 컨테이너 안에서만 엑세스 가능
- 컨테이너 안에서 실행되는 프로세스는 다른 컨테이너의 프로세스에 영향을 줄 수 없음
- 네트워크의 구획화
- 컨테이너 하나에 IP주소 할당
- 파일시스템의 구획화
- 컨테이너 안에서 사용되는 파일 시스템은 구획화되어 있음
→ 해당 컨테이너에서의 명령이나 파일 등의 엑세스 제한 가능
- 컨테이너 안에서 사용되는 파일 시스템은 구획화되어 있음
Docker CLI
- Docker Image 가 실행되면 Docker Container가 됨
- Image : 파일
- 레지스트리(Registry) : 도커 이미지가 관리되는 공간, 다른 지정이 없으면 도커 허브를 기본 레지스트리로 설정
- 레포지토리(Repository) : 레지스트리 내에 도커 이미지가 저장되는 공간, 이미지 이름이 사용되기도 함
- 태그(Tag) : 같은 이미지일지라도 버전에 따라 내용이 다름, 해당 이미지를 설명하는 버전 정보를 입력, 다른 지정이 없으면
latest태그가 붙은 이미지 가져옴 - Registry_Account/Repository_Name:Tag
Docker CP 와 DockerFile
- docker container cp = docker cp
- 도커 버전 차이 때문, docker cp가 전 버전
- docker container 에서 copy 한다는 것을 정확하게 명시하기 위해 변경
- 서버에 문제가 생기는 것을 호스트와 별개로 파악가능
- 문제가 생긴 서버를 끄고 도커 이미지로 서버 재구동 용이
로컬에 있는 파일과 도커 이미지를 연결하는 방법
- CP(copy) : 호스트와 컨테이너 사이에 파일을 복사
- Volume : 호스트와 컨테이너 사이에 공간은 마운트(Mount)
docker docs https://docs.docker.com/
Docker 이미지 만들기
이미지로 만들어 놓으면 이전에 작업했던 내용을 다시 한번 수행하지 않아도 됨 + 배포 및 관리가 유용
- Docker container 를 이미지로 만드는 방법
docker container commit - Docker image 빌드를 위한 파일인 Dockerfile로 만드는 방법
docker build
https://docs.docker.com/engine/reference/builder/
docker container 끼리 연결할 수 있을까?
volume으로 가능
Cloud platform
AWS, GCP 등 어디서든 접근할 수 있는 저장소
docker 와 cloud platform을 연결해서 공부해야 할까?
github, dockerhub는 클라우드 플랫폼이 아님
cloud platform과 docker를 연결하는 이유는 배포할때나 컴퓨터를 세팅해줄때 docker image로 하면 편리함
docker cp
앞에 인수의 경로를 뒤에 인수의 경로에 복사
1. 호스트 → 로컬
2. 로컬 → 호스트
docker는 개발환경일까?
yes, 개발환경을 통일시켜주는 역할
docker container ps 와 docker container ps -al 의 차이
전자 : 현재 실행중인 것
후자 : 중지된 것까지 모두 나오는 것
실행중인 웹 서버 컨테이너가 있을 때 종료 후 도커 이미지까지 삭제하려고 할 때 어떤 순서로 어떤 명령어를 실행해야 할까?
container stop → container rm -> image 삭제
Day 2
Flask
장고(Django) vs 플라스크
플라스크는 최소한의 기능만 가지고 있고, 장고는 too much
- 파이썬을 사용해 웹 어플리케이션을 작성할 수 있도록 도와줌
- 웹 프레임워크
-
return 가능한 type: 문자열, 튜플, 딕셔너리
- 딕셔너리의 경우 json 형태로 출력
- 튜플의 경우 ('a','b') → a만 출력, b는 응답코드가 됨(b는 검사의 네트워크에서 status code에서 확인 가능)
-
프로젝트 구성
- 템플릿 폴더 : 프론트, html
- static folder: css, image, js
- utils : 백엔드에서 쓰이는 함수
- routes : 구현해낼 url
- models : db 스키마짜는 모델
__init__.py
모듈 : 파일, 패키지: 모듈을 모아둔 것 = 라이브러리
하나의 프로젝트라는 것을 flask에 알려주는 것
- HTTP Request 메소드
기본적으로 flask의 라우트 데코레이터를 사용하게 되면 GET, HEAD, OPTIONS 메소드를 허용
이외의 메소드들을 사용하기 위해서는 데코레이터 함수에methods인수 추가해야 함
@app.route('/', methods=['POST','GET']) # route : 디폴트 주소에서 endpoint 지정해주는 것
def index():
...- 세부 엔드포인트
@app.route('/index/<num>')
def index_num(num): #()안에는 <>안과 같은 변수 입력
return f'Welcone to Index {num}'- 디폴트를 설정하지 않으면 값이 없는 상태로 url 입력하면 오류
```python
@app.route('/index/', defaults={'num' : 0})
@app.route('/index/<num>')
def index_num(num):
return f'Welcone to Index {num}'
```- 블루프린트
기능이 많아질수록 라우트도 많아지는데 이런 라우트들을 하나의 파일로 모아서 사용하지 않고 기능별로 나눠서 블루프린터 기능을 사용
flask에서 여러 개의 라우트를 한 곳에 묶어둘 수 있는 기능이 있음
flask_app 폴더
- __init__.py
- routes 폴더
- user_routes.py`user_routes.py`
from flask import Blueprint
bp = Blueprint('user', __name__, url_prefix='/user')
# 'user' : 블루프린트 명칭
# __name__ : 블루프린트의 import 이름
# user_prefix='/user' : URL 접두어 설정(해당 블루프린트의 라우트는 URL앞에 '/user' 가 자동으로 붙음)
@bp.route('/')
def index():
return 'User index page'`__init__.py`
from flask import Flask
from flask_app.routes import user_routes
app = Flask(__name__) # 파일이름, __init__.py일 경우 __init__.py가 포함되어 있는 상위 폴더이름
app.register_blueprint(user_routes.bp)
@app.route('/')
def index():
return 'Hello World!'
- Application Factory
circular import error
HTML 렌더링
렌더링 : 객체를 하나의 장면으로 출력시키는 것
render_template
# index.html 파일
<html>
<head>
<title>
New HTML Page
</title>
</head>
<body>
<h1>I am in templates folder</h1>
</body>
</html># __init__.py 파일
from flask import Flask, render_template
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
#이렇게 하면 index.html 보여줄 수 있음진자
-
웹 템플릿 엔진
-
쉽게 변수를 특정해 출력, 함수를 사용할 수 있음
-
엔진 : 다른 프로그램이 해당 프로그램을 위해 핵심적이거나 본질적인 기능을 해주는 것
-
템플릿 엔진 : 맞춤형 웹 페이지를 자동으로 생산할 수 있도록 도와줌
-
표현식
# {}
<body>
<h1>{{ title }}</h1> # title 이라는 변수를 <h1> 태그 안에 넣어서 렌더링 하는 방식
</body>
# {%...%} : if, for 등의 구문에 사용
# {{...}}} : 템플릿 결과(html)에 출력할 표현(ex. 변수)
# {#...#}: 주석 처리할 때 사용-
Flask에서 Jinja로 변수 넘기기
render_template(... 생략 ...) @app.route('/') def index(): apple = 'red' apple_count = 10 return render_template('index.html', fruit_color=apple, number=apple_count)# html 파일 (... 생략 ...) <body> <h2>Apple is {{ fruit_color }}</h2> <h2>{{ number }} 개의 과일이 있습니다.</h2> </body> (... 생략 ...) -
상속 : 반복적으로 사용된 부분을 하나로 묶어서 사용할 수 있게끔 해주는 기능
{% extends %}
{% block %} ... {% endblock %}- 2번 상속된 파일이 가장 상위 부모의 내용을 접근하기 위해서는
super.super()를 통해 가능 - jinja의 상속기능은 전부 가져오거나 안가져오거나 두가지 선택 뿐
- 2번 상속된 파일이 가장 상위 부모의 내용을 접근하기 위해서는
Bootstrap
- 프론트엔드에 대한 최소한의 지식으로 다양하고 예쁘게 꾸밀 수 있도록 도와주는 도구
우리는 웹 개발자가 아닌데 왜 웹 개발을 배울까?
서비스 개발의 궁극적 목적은 배포, 배포를 굳이 하지 않더라도 웹 개발자와 소통할 수 있기 때문
기본적으로 웹이 어떻게 돌아가는지 알게 되면 좋음
프레임워크 vs 라이브러리
프레임워크 : 서비스하나를 만들기 위해 필요한 모든 기능이 다 들어 있는 것, 표준이 존재, flask..
라이브러리 : 편의를 위해 기능들을 모아둔 것, pandas, numpy..
환경변수 설정
변수 값에 경로를 미리 세팅해서 언제든 가져다 쓸 수 있게 하는 것
env, set, export
env : 전역 변수 설정 및 조회
set : 사용자 환경 변수 설정 및 조회
export : 사용자 환경 변수를 전역변수로 설정
flask 실시간 반영
export FLASK_ENV=development
export FLASK_APP=이름 -> python -m flask run 할 수 있음
section3 프로젝트에 flask를 쓴다면 어떤 목적으로 사용할 수 있을까?
API서비스 제공 목적으로 사용가능
extend vs append
list.append(x) : 리스트 끝에 x 1개를 그대로 넣음list = [2,9,3] list.append('a') # [2,9,3,'a'] list.append([1,2,3]) # [2,9,3,'a',[1,2,3]]list.extend(iterable) : 리스트 끝에 가장 바깥쪽 iterable의 모든 항목을 넣음
list = [2,9,3] list.extend([1,2,3]) # [2,9,3,1,2,3] list.extend((4,5,6)) # [2,9,3,1,2,3,4,5,6]
Day 3
배포와 대시보드
대시보드 = 데이터베이스의 내용을 다양한 그래프를 통해 표현해주는 도구 (ex. Metabase)
배포 : 공유하는 과정
Werkzeug : 개발용 tool kit
서버 : 클라이언트에게 네트워크를 통해 정보나 서비스를 제공하는 컴퓨터 시스템으로 컴퓨터 프로그램(Server program) 또는 장치(Device)
web 서버 : HTTP를 통해 웹 브라우저에서 요청하는 HTML 문서나 오브젝트(이미지 파일 등)을 전송해주는 서비스 프로그램리소스 : 하드웨어 리소스, 소프트웨어 리소스
웹 브라우저에 html을 보냈다 렌더링 할대 문서를 해석 해야함 이 역할을 웹 브라우저에서는 DOM이 함
Heroku 배포
WSGI(Web Server Gateway Interface, 위스기)
- 서버나 게이트웨이를 어플리케이션이나 프레임워크와 이어주는 역할
- ex. flask와 같은 마이크로 프레임워크를 서버로 연결해 외부에서 접속할 수 있도록 도와주는 역할
Gunicorn(Green unicorn)
- 파이썬의 WSGI HTTP server
- UNIX체계에서 작동
- 'pre-fork worker' 모델
- 파이썬에서 어떤 어플리케이션이나 프레임워크가 주어지게 되면 사전에 '포킹' 을 한 뒤에 worker를 통해 작업을 실행
- 특징
- WSGI를 네이티브 지원
- worker를 자동으로 관리
- 손쉬운 파이썬 설정
- 동시에 다수의 worker가 사용 가능
workers = n
- HTTP 관련된 웹 요청이 들어오면 flask와 같은 어플리케이션을 이용해 처리를 도와주는 역할
Heroku
- 클라우드 플랫폼을 제공하는 서비스
- heroku의 클라우드 컴퓨터가 web서버를 실행시키기 위해 꼭 있어야 하는 정보
- requirements.txt - python 패키지 정보
- procfile - 웹 서버 구동 정보
- requirements.txt, procfile, flask_app 의 정보가 같은 폴더의 계층에 있어야 함
window git bah 에서 heroku cli 오류
/c/Program\ Files/Heroku/bin/heroku 로 실행되면
PATH="$PATH:/c/Program Files/Heroku/bin" 지정해줌
이후 heroku 실행 잘 됨
runtime.txt : 어떤 버전의 파이썬을 사용하고 있는지 알려주는 것
Procfile : heroku에게 우리 웹사이트를 시작시키기 위해 실행되어야 할 명령어의 순서를 알려주는 것
Metabase 대시보드
- 보고서 작성 : WORD, PPT, Google Slide 이용 = 문서
- 대화형 인터프리터 : Colab, Jupyter Notebook 이용 = EDA
- 웹 어플리케이션 : Flask, Django, Spring 이용 = 개발 리소스 ↑
- BI 도구(대시보드) : Metabase, Google DataStudio, Retool, Redash 이용
- 장점
- 대시보드를 DB에 직접 연결하여 생성하면 데이터의 변동 사항을 실시간으로 반영할 수 있음
- 비데이터 직군의 데이터 접근성을 높일 수 있음
- 유저가 직접 데이터 필터를 조작할 수 있어 생동감있는 데이터 보고서 작성 가능
matplotlib 은 대시보드일까?
no, 대시보드는 데이터의 변화를 확인할 수 있음
Day 4
시간과 부호화
API를 개발하고 외부의 서비스를 이용하다보면 많은 문제를 마주하게 되는 데 그 중의 시간을 설정하고 표현하는 방법 과 객체를 부호화 및 복호화 하는 방법
부호화 또는 인코딩
컴퓨터를 이용해 데이터를 생성할 때 데이터의 양을 줄이기 위해 데이터를 코드화하고 압축하는 것복호화 또는 디코딩
부호화와 반대되는 개념
시간(UTC, KST, Timestamp)
-
컴퓨터에서 시간을 표기하는 방법
-
시간을 주의해야 하는 상황
- 서비스에서 시간을 이용하는 경우(API, 라이브러리 등등에서)
- 시간을 저장하는 경우(인간이 보기 편하게 or 장치에서 인식하기 수월하게)
- 여러 노드에서 시간을 발생시키는 경우
-
date -u +"%Y-%m-%dT%H:%M:%SZ"- ISO 8601 표준
- 년,월,일,시간,분,초,Timezone 기준으로 작성
- 날짜와 시간은 두개의 숫자로 구성
- 확장형으로 구분자(-,:,Z,T)가 사용될 수 있음
T : timezone, Z : UTC+0 - 20211225 = 2021-12-25 = 20211225T1225 = 2021-12-25T12:25:00 = 20211225T1225Z = 2021-12-25T12:25:+0900
-
date +%s- Unix Time, Epoch Time
- Epoch : 1970년 1월 1일 0시 0분 0초를 기준으로 시간을 표현
- 1초 이후 시간을 +1 로, 1초 이전 시간은 -1 로 표기
- Timezone을 추가하지 않는다면 UTC+0을 기준으로 표기
- 시간 자체보다 시간을 이용한 연산에 활용
# 시간확인 명령어
import datetime
datetime.datetime.now()
datetime.datetime.utcnow()
import time
time.time()
time.sleep(3) # 3초 잠듦
#=
from time import sleep
sleep(3)시간을 저장하는 경우?
주식 동향을 저장할 때, 로그인 시간 저장할 때(시간이 기준이 될 때) 등
스케줄링
-
특정 시점을 기준으로 업무를 수행시키기 위해 스케줄링이 필요
-
API나 크롤링/스크레이핑을 할 때 날짜나 시간을 지정하고 지정된 시간에 맞게 데이터를 수집하는 과정이 필요할 때 사용
- 과거 시점의 데이터를 수집하는 것도 스케줄링임
-> 이점: 서버 사용량이 적은 시간에 작업 할 수 있음(과거부터 미래까지 쭉 스케줄러하면 언제든 같은 데이터를 얻을 수 있음)
- 과거 시점의 데이터를 수집하는 것도 스케줄링임
-
APScheduler: 파이썬 라이브러리, 어플리케이션- 스케줄러가 프로그램의 목적이 되는 경우
BlockingScheduler - 다른 어플리케이션과 연동해서 사용하는 경우
BackgroundScheduler
AsynclOschedule
GeventScheduler
TornadoScheduler
TwistedScheuler
QtScheuler
- 스케줄러가 프로그램의 목적이 되는 경우
# blockingscheduler 선언
from apscheduler.schedulers.blocking import BlockingScheduler
# UTC 기반으로 실행
scheduler = BlockingScheduler({'apscheduler.timezone':'UTC'})
# KST 기반으로 실행
scheduler = BlockingScheduler({'apscheduler.timezone':'Asia/seoul'})
# 스케줄러에 job 선언
def hello():
print("안녕하세요 저는 5초마다 실행됩니다.")
scheduler.add_job(func=hello, trigger='interval', seconds=5)
## trigger options : date(특정시점에 실행하고 싶을 때), interval(고정된 간격을 기반으로 실행하고 싶을 때), cron(unix 기반의 cron에서 사용하는 문법을 이용하여 스케줄링하고 싶을 때)
# 스케줄러 시작
scheduler.start()cron 으로 시간을 표기하는 방법
2 * * * echo "hello AI"
0 0 12 * echo "hello AI"
https://zamezzz.tistory.com/197
스케줄러는 어떤 목적으로 사용할 수 있을까?
배포한 서버가 계속 돌아가면 매번 최신 데이터가 업데이트 되게 할 수 있음
서버의 과부화 방지 등등
객체부호화
-
부호화 : 데이터를 저장하거나 전송하기 쉽게 변환하는 과정
인메모리 방식 → 바이트열 방식 -
피클링
pickledump
-
복호화 = 역부호화 : 부호화된 데이터를 사람들이 읽을 수 있는 형식으로 바꿔주는 것, 부호화된 데이터를 해석하는 것
바이트열 방식 → 인메모리 방식 -
역피클링
load
Section 3 전체 정리
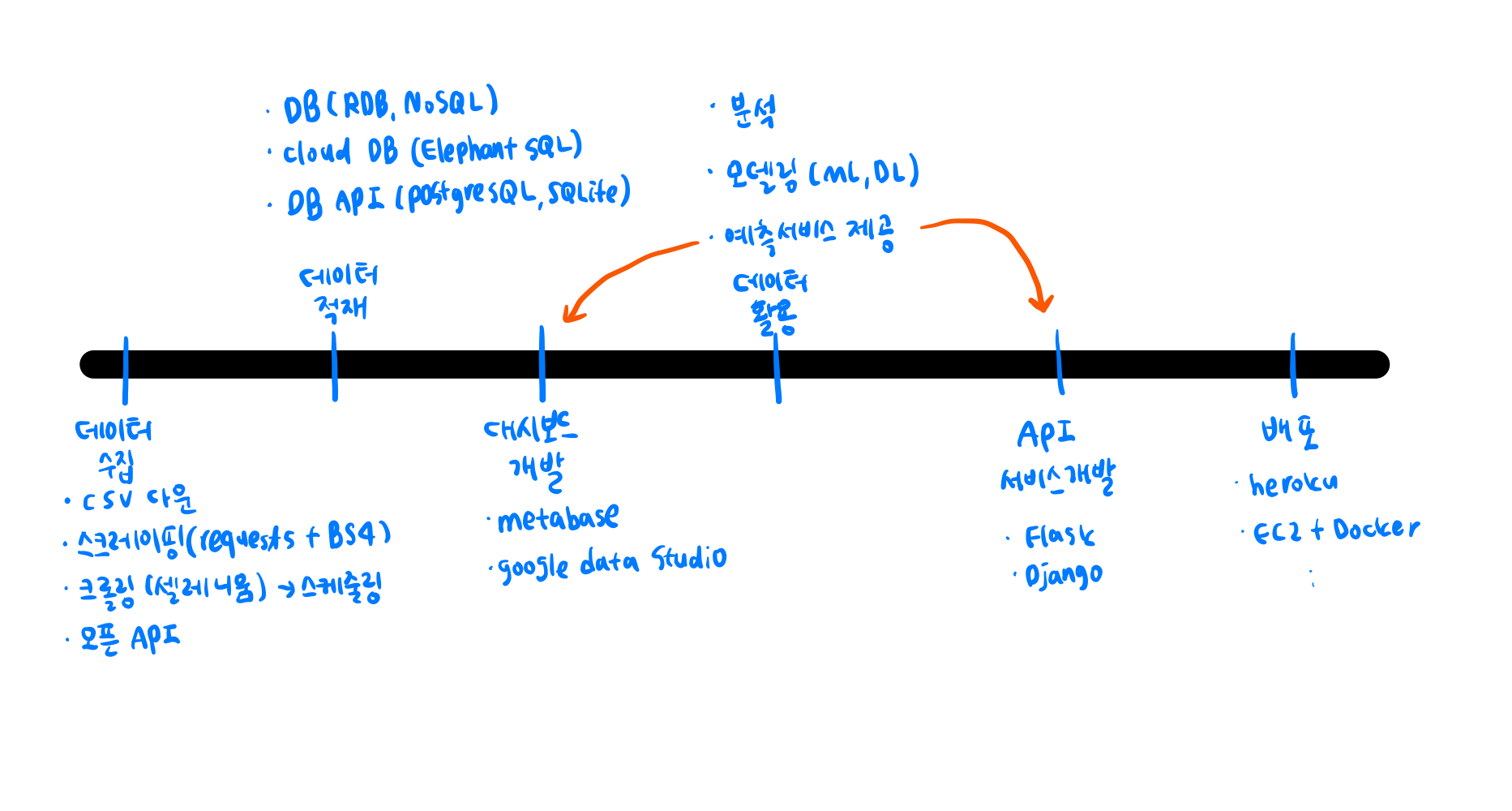
데이터 베이스의 활용
데이터 베이스
- 어떤 데이터가 데이터 베이스에 저장이 될까? >> 문자열(정형데이터)
csv파일, 사진, 동영상 > raw data > 파일 서버(파일을 저장할 수 있는 어떤 공간, usb 같은거)에 저장데이터 레이크
자연상태의 데이터를 그대로 저장하는 공간
데이터의 생명 == 무결성, 유실된 정보가 없는 데이터데이터 웨어하우스
창고에서 바로 나갈 수 있게 저장되어있는 곳, 정형데이터데이터마트
데이터웨어하우스에서 용도마다 데이터베이스가 만들어진 곳트랜젝션
- OLTP(online transection processing) : 사용을 위한 데이터 사용하는 행위 , 로그인/로그아웃/댓글달기 등등
- OLAP(online analystic processing): 분석을 위한 데이터 사용, 분석을 위해 만든 데이터 베이스 = 데이터 웨어하우스
- 둘의 접근 패턴이 다름, 데이터를 바라보는 시선이 다름
- ETL: extract - transform - load, OLTP 데이터베이스를 가져와서 OLAP 에 적합한 스키마로 변환하고 변환한 데이터를 적재하는 것
