이 글은 MySQL을 기준으로 포스팅했습니다.
- 참고자료 : MySQL Docs (https://dev.mysql.com/doc/refman/8.0/en/join.html)
먼저 JOIN에 대해 알아보기 전에 JOIN을 왜 사용해야 하는 지 궁금할 수 있습니다. 한 테이블에 다 모아놓고 필요한 것만 꺼내쓰면 안되는 것일까? 하는 생각으로 JOIN의 필요성을 의심할 수 있지만, 데이터테이블을 공부할 때 처음에 공부하게 되는 정규형에 대해 생각해보면 JOIN이 필요함을 알 수 있습니다.
정규형
데이터의 갱신이 발생한 경우에도 데이터의 부정합이 발생하지 않도록 하는 형태를 말합니다. 즉 테이블을 여러 개로 분리하고 중복성을 최소화하여 데이터의 일관성을 유지하기 위함입니다. 그래서 제1정규형부터 5정규형까지 존재합니다. (이건 꽤 분량이 있기 때문에 따로 포스팅하겠습니다.)
JOIN의 종류
여러 개로 나눈, 정규화된 테이블 간의 JOIN을 할 때 어떤 종류가 있을까요?
joined_table: {
table_reference {[INNER | CROSS] JOIN | STRAIGHT_JOIN} table_factor [join_specification]
| table_reference {LEFT|RIGHT} [OUTER] JOIN table_reference join_specification
| table_reference NATURAL [INNER | {LEFT|RIGHT} [OUTER]] JOIN table_factor
}DOCS에 이런 종류의 JOIN이 기술되어 있습니다. 실무에서 이것을 다 분류해서 사용하기 보다는 가장 자주 쓰는 INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN에 대해 알아보겠습니다.
INNER JOIN
INNER JOIN은 가장 흔하게 사용하는 JOIN입니다. 가장 필요한 개념인 교집합과 비슷하기 때문입니다. 두 테이블 간에 일치하는 행을 뽑기 위한 일이 기본적인 JOIN의 의도라서 INNER JOIN을 많이 사용합니다.
예를 들어 보겠습니다.
EMPLOYEE 테이블
| EMPLOYEE_ID | NAME | DEPART |
|---|---|---|
| 1 | 홍길동 | 영업 |
| 2 | 유재석 | 홍보 |
| 3 | 박명수 | 교육 |
| 4 | 정준하 | NULL |
| 5 | 정형돈 | NULL |
DEPARTMENT 테이블
| DEPART | FLOOR |
|---|---|
| 영업 | 7 |
| 홍보 | 5 |
| 교육 | 3 |
해당 테이블을 INNER JOIN한다면, 각 테이블에 공통적으로 있는 값을 가져옵니다.
- 실행 쿼리
SELECT *
FROM EMPLOYEE
INNER JOIN DEPARTMENT ON EMPLOYEE.DEPART = DEPARTENT.DEPART;- 실행 결과
| EMPLOYEE_ID | NAME | DEPART | DEPART | FLOOR |
|---|---|---|---|---|
| 1 | 홍길동 | 영업 | 영업 | 7 |
| 2 | 유재석 | 홍보 | 홍보 | 5 |
| 3 | 박명수 | 교육 | 교육 | 3 |
OUTER JOIN (LEFT, RIGHT, + FULL)
OUTER JOIN은 INNER JOIN과 다르게 기준을 가지고 있습니다. 어느 기준으로 하느냐에 따라 LEFT, RIGHT로 나뉘는 거죠.
LEFT JOIN
말그대로 JOIN의 기준이 LEFT(왼쪽) 테이블에 있는 것입니다. 따라서 왼쪽 테이블을 기준으로, 오른쪽 테이블에 동일한 행이 있다면 가져오고, 그렇지 않다면 NULL(NaN)값을 채워서 출력합니다.
동일하게 위의 테이블을 가지고 LEFT JOIN해보겠습니다.
- 실행 쿼리
SELECT *
FROM EMPLOYEE
LEFT JOIN DEPARTMENT ON EMPLOYEE.DEPART = DEPARTENT.DEPART;- 실행 결과
| EMPLOYEE_ID | NAME | DEPART | DEPART | FLOOR |
|---|---|---|---|---|
| 1 | 홍길동 | 영업 | 영업 | 7 |
| 2 | 유재석 | 홍보 | 홍보 | 5 |
| 3 | 박명수 | 교육 | 교육 | 3 |
| 4 | 정준하 | NULL | NULL | NULL |
| 5 | 정형돈 | NULL | NULL | NULL |
RIGHT JOIN
RIGHT JOIN은 기준테이블이 LEFT와 반대인 JOIN을 말합니다.
- 실행 쿼리
SELECT *
FROM EMPLOYEE
RIGHT JOIN DEPARTMENT ON EMPLOYEE.DEPART = DEPARTENT.DEPART;- 실행 결과
| EMPLOYEE_ID | NAME | DEPART | DEPART | FLOOR |
|---|---|---|---|---|
| 1 | 홍길동 | 영업 | 영업 | 7 |
| 2 | 유재석 | 홍보 | 홍보 | 5 |
| 3 | 박명수 | 교육 | 교육 | 3 |
FULL JOIN
참고로 FULL JOIN에 대해 써보도록 하겠습니다. 실무에서는 많이 안쓰이지만 FULL JOIN까지 알고 간다면 큰 도움이 될 것이라 생각합니다. :)
INNER JOIN은 교집합으로 말씀드렸는데요, FULL JOIN은 합집합으로 이해하면 쉽습니다. 즉, 두 테이블을 FULL JOIN할 때, INNER JOIN의 값 + LEFT/RIGHT JOIN의 값을 모두 모아서 출력합니다. (왼쪽 테이블에는 존재하나, 오른쪽 테이블에는 존재하지 않는 컬럼값 == NULL / 오른쪽 테이블에는 존재하나, 왼쪽 테이블에는 존재하지 않는 컬럼값 == NULL)
마찬가지로 쿼리와 실행 결과를 보도록 합시다.
- 실행 쿼리
SELECT *
FROM EMPLOYEE A
FULL OUTER JOIN DEPARTMENT B ON
A.DEPART = B.DEPART- 실행 결과
| EMPLOYEE_ID | NAME | DEPART | DEPART | FLOOR |
|---|---|---|---|---|
| 1 | 홍길동 | 영업 | 영업 | 7 |
| 2 | 유재석 | 홍보 | 홍보 | 5 |
| 3 | 박명수 | 교육 | 교육 | 3 |
| 4 | 정준하 | NULL | NULL | NULL |
| 5 | 정형돈 | NULL | NULL | NULL |
🧐 참고 : SQL JOIN Visualizer라는 서비스가 있어서 앞서 설명드린 특징들을 눈으로 확인해보세요! 쿼리도 함께 나와서 좋습니다.
https://sql-joins.leopard.in.ua/
UNION
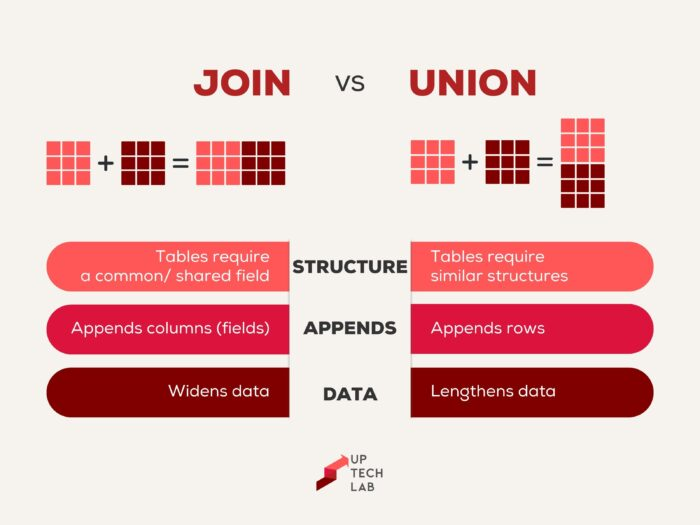
- '합친다' 라는 개념에서 JOIN, UNION의 개념이 헷갈릴 수 있습니다. JOIN은 적어도 하나의 컬럼이 공통적으로 있는 두 테이블 간의 결합에서 사용합니다.
그에 반해 UNION은 하나의 결과 세트를 보여주는데요, 수직결합의 형태로 출력되며 이러한 특징으로 주로 SELECT문의 결과를 단일 결과 세트로 연결할 때 사용합니다.
덧붙여, 결합되는 값이 중복될 때는 알아서 제거해주는 DINTINCT의 특징도 가집니다.
(+ 중복을 제거하고 싶지 않다면 UNION ALL로 하면 됩니다.)
- 실행 쿼리
SELECT * FROM EMPLOYEE
UNION
SELECT * FROM DEPARTMENT