
PEFT(Parameter Efficient Fine-Tuning)
배경: 1,750억 개의 학습 가능한 파라미터가 있는 GPT-3에서는 full-finetuning 방식을 활용하기엔 시간적 혹은 비용적 측면에서 힘들어지고 있다.
이에 많은 사람들이 일부 파라미터만 조정하거나 새로운 task를 위한 외부 모듈을 학습하여 이를 완화하려고 했다. 이렇게 하면 각 task에 대해 사전 학습된 모델 외에 소수의 task별 파라미터만 저장하고 로드하면 되므로 배포 시 운영 효율성이 크게 향상된다.
PEFT는 다운스트림 작업의 성능을 유지하거나 향상시키면서 계산량과 모델 크기를 줄이는 것을 목표로 한다.
Adapter tuning: LoRA
-> 기존 학습 모델에서 어댑터 레이어 추가 ; 모델 파라미터 재구성, 더 적은 파라미터 학습
대표적인 모델: LoRA(Low-RANK Adaption)
기본 컨셉
LoRA 파라미터 재구성 -> 모델의 Parameter 행렬을 더 작은 2개의 행렬 곱으로 표현. 기존 파라미터에다가 더 작은 2개의 행렬 수정
이때 LoRA는 내재적 차원을 사용해서 튜닝을 하는거라고 할 수 있음!
표면적 차원 vs 내재적 차원
표면적 차원(surface dimension): 모델 파라미터의 전체 수. 예를 들어, 어떤 레이어의 가중치가 W∈R 1000×1000이라면, 총 1백만 개의 파라미터를 학습하는 것이므로 차원은 1,000,000
내재적 차원(intrinsic dimension): 실제로 학습 문제를 잘 해결하는 데 필요한 최소한의 유효한 파라미터 공간의 차원입니다. 즉, 모델이 매우 높은 차원의 공간에서 정의되어 있더라도, 학습 중 유의미하게 변화하는 방향은 사실상 훨씬 적다는 뜻
이 특성을 이용해서 파라미터를 다 바꾸지 않고도, 몇천 차원의 subspace만을 가지고 학습해도 성능이 잘나옴

여기서 r은 low_rank의 차원인데, 그림에서 보면 일단 A에서는 랜덤 가우시안을 초기화를 한다. 랜덤 가우시안 분포는 정규분포를 따라 랜덤하게 설정하는 방식인데, 이걸 왜 써서 초기화를 하냐면!
신경망의 학습 성능은 초기화 방법에 민감함. 그래서 이때 정규분포를 쓰면 모든 뉴런이 동일한 값을 가지면 학습이 진행되지 않을 뿐더러, 적절할 분산을 통해서 backward 시 gradient vanishing을 막을 수 있음.
반면 B에서는 처음에 영향이 없게 0으로 시작해서, 처음에는 BA=0으로 시작할 수 있게 함. 그리고 학습이 진행되면 점차 영향을 받을 수 있게 함.
그런 다음에, LoRA scaling factor를 해줘야 하는데,
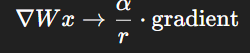
여기서 𝛼는 LoRA scaling factor이며, rank 𝑟이 커질수록 스케일을 줄여서 학습 안정성 유지해주는 역할을 함. 이 스케일링은 𝑟을 변경할 때 hyperparameter를 다시 튜닝할 필요성을 줄이는데 도움이 됨.
그럼 이제 어떻게 기존 모델의 특성값과 도메인 특성 값에 대한 차원을 구해서 업데이트를 하는지 알아보자.
- 기존 모델의 특성값 계산
(1,100) @ (100,100) = (1,100)차원의 특성값을 뽑아냄.
-
기존 가중치 행렬 :
예시 (일부):
-
계산 결과:
- LoRA를 통한 도메인 특성값 계산
그럼 (1,100)@(100, 8(r)) = (1,8) = A
(8(r), 100) = B
A @ B = (1,8) @(8,100) = (1,100)
-
LoRA 구성:
- (처음에는 0으로 초기화)
-
예시:
- : 랜덤 가우시안 초기화
- :
- : 랜덤 가우시안 초기화
-
연산:
-
도메인 투영:
예: -
원래 차원 복원:
→ 현재는 이므로
-
- 최종 출력 계산
그럼 이제 기존 모델 특성값과 도메인 특성값의 shape가 똑같으니깐, 서로 더할 수 있음!
→ 학습 전에는 LoRA의 영향이 없으며, 학습이 진행될수록 가 업데이트되면서 보정값이 추가
그리고 본래 모델의 파라미터는 freeze을 시키고, LoRA adapeter를 구성하는 dr 과 rd의 행렬이니깐 본래 모델의 d*d의 행렬보다 훨씬 더 적은 파라미터를 학습시킬 수 있음.
추가적인 inference latency 없음

downstream task & upstream task
| 용어 | 의미 |
|---|---|
| Upstream task | 대규모 데이터로 모델을 사전 학습시키는 작업 (예: 언어 모델 훈련) |
| Downstream task | 사전 학습된 모델을 실제 문제에 적용하는 작업 (예: 감정 분류) |
즉, Downstream task는 pretrained 모델을 특정 도메인 문제에 fine-tuning하거나 적용하는 것을 의미함.
LoRA의 설정 값
1. r: AB를 만들때 r을 몇으로 할지 설정
그렇다면, 최적의 r은 몇일까???
LoRA 원논문에 따르면,
BERT-base, RoBERTa 등: r=4로도 기존 full fine-tuning과 거의 동일한 성능을 달성
GPT-3 r= 8 또는 r = 16으로 안정적 성능을 확보할 수 있다고 함.
- alpha: adaptor 파라미터의 결과를 모델의 파라미터에 얼마나 반영할지를 결정(alpha가 커질수록 adpator쪽에 더 비중을 둠)
transformer에서의 LoRA
모델의 파라미터 중 어디에 adaptor를 적용할 지도 결정할 수 있음!
예를 들어서, transformer에 self-attention layer 는 key, query, value, feed-forward의 linear layer로 구성. 이중 특정 파라미터에만 LoRA를 적용할 수 있음.
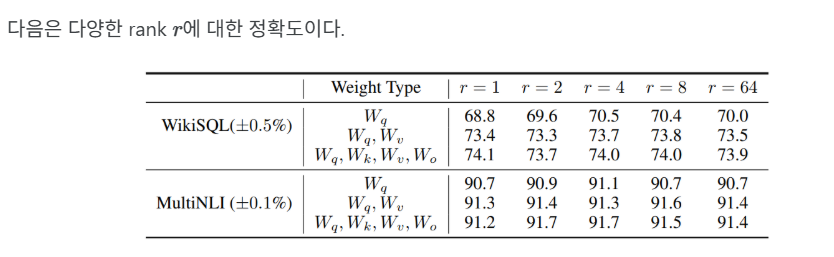
논문에서도 GPT-3의 가중치 행렬 종류에 대한 정확도가 나오는데,key, query, value, output projection 모두에 LoRA를 적용하는것이 가장 정확도가 높다.
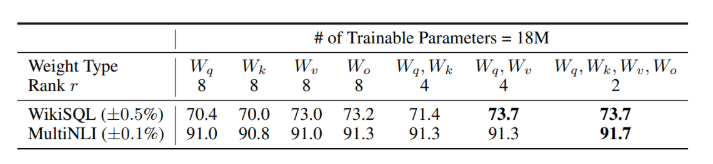
갑분 논문이지만..WikiSQL 이랑 MultiNLI는 둘다 자연어처리(NLP)분야에서 자주 사용되는 다운스트림 테스크용 데이터셋인데, 두개 차이의 용도는 완전히 다름.
| 항목 | WikiSQL | MultiNLI |
|---|---|---|
| 태스크 | 자연어 → SQL 변환 (Semantic Parsing) | 문장 간 논리 관계 분류 (Natural Language Inference) |
| 입력 | 질문 + 테이블 | 두 문장 (premise, hypothesis) |
| 출력 | SQL 쿼리 (문자열) | 범주(Label) |
| 학습 유형 | 생성(Generation) | 분류(Classification) |
| 사용 분야 | DB 질의, 데이터 접근 | 논리 추론, 질의 응답, 요약 |
