Introduction
저번주에 CNN에 대해 처음 접하게 되었다. 그 전까지는 NLP(자연어 처리)모델들을 배우다보니 이번 이론들은 꽤나 새롭고 흥미로웠다. 더 깊게 들어가면 분명 어려운 부분도 있지만, AI가 이미지를 파악하는 것이 얼마나 어려운지를 알게 되었다. 생각해보면, 사람의 직관과 감각을 기계가 따라잡기 위해서 흉내낼 수는 있겠지만, 이를 완벽히 구현해내는 것은 꽤나 오랜 기간이 걸릴 수 있을 것 같다.
CNN의 기본 구조(feature extractor[covolutions- subsampling] - fully connection)
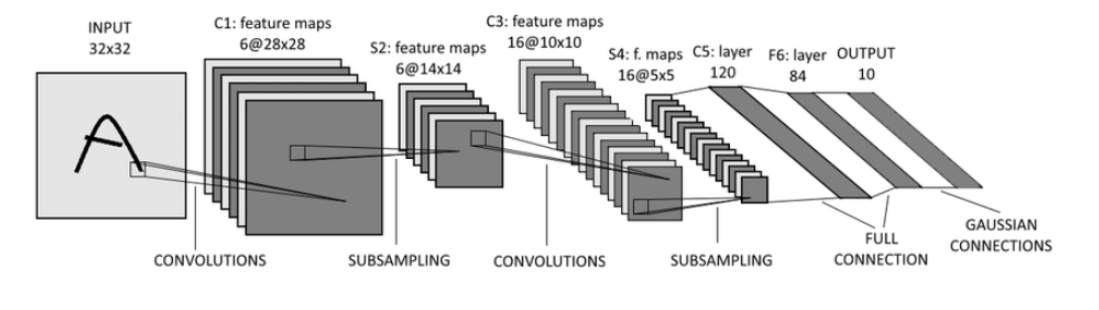
CNN의 feature extractor : Fully connected가 아닌 convolution- subsampling 구조
왜 fully connected layer를 사용하지 않을까?
fully connected layer는 이미지의 공간적(spatial)구조를 학습하는 것이 어려움.
그니깐, 만약에 강아지 이미지가 있다고 해보자. 강아지가 왼쪽에서 달려오는 것과 오른쪽에서 달려오는 것이 이미지에서 위치만 다를 뿐이지 우리 눈엔 같은 강아지지만, 기계는 그걸 아예 다른 물체로 인식한다는 의미임.
그래서, 이미지의 특징을 추출하기 위해서 Convolution(합성곱) 연산을 사용!
그게 몬데!!!
합성곱 연산은 input data와 weight 간의 가중합을 구할 떄 한번에 구하지 않고, 옆으로 이동하져면서 작은 크기의 filter를 만들어서 가중합을 구하는 방식임. 이때 필터에 표현된 값과 이미지의 합성곱 결과가 값이 나오면, 그 부분은 이미지에 필터가 표현하는 이미지 특성이 존재한다는 뜻임.
Deep Learning(CNN)에서의 Filter:
Filter를 구성하는 원소(element) = parameter(weight)
convolution layer도 여러 층으로 쌓임. (저수준 > 고수준의 특성을 찾음)
1) 저수준- 일반화하기 쉬운 기초적인 특성
2) 고수준- 각 사물만이 가지는 특성
Convolutional Layer 작동 방식
torch.nn.Conv2d
입력 변수: N,Channel, Height, Width shape의 tensor를 받음
- in_channels : 입력 데이터의 channel size
- out_channels : 출력 데이터의 channel size(kernal의 개수: Feature map의 depth, channel의 크기)
- kernel_size: Filter의 크기(height, width)
보통 홀수 크기로 잡음(3 3, 5 5) - padding=0: input tensor의 추가할 여백의 크기(default는 0으로 padding을 추가함)-> 문자열로 줄 경우 1) "same": input의 height와 width와 동일한 output이 나오도록 padding을 추가함 2) "valid": padding을 사용하지 않음
- stride=1: 연산시 Filter의 이동 size
# Conv2d 생성
layer = nn.Conv2d(
in_channels=3, # 입력 데이터의 channel 개수. 입력 tensor의 shape: (batch_size, channel, height, width)
out_channels=5, # 필터의 개수 (output feature map의 개수)
kernel_size=3, # 필터의 크기 (3, 3)
stride=1, # 계산을 위하 이동 크기. 좌->우: 1칸씩, 상->하: 1칸 (default: 1)
padding=1, # 패팅 크기 (정수: 상하/좌우 동일할 패팅크기를 명시 - 0(default): 패딩추가 안함.)
# "same": 입력 size와 동일한 size의 출력이 나오도록 알아서 패딩을 추가.
)Zeropadding을 붙이는 이유
가장 큰 이유는 자리를 옮기면서 feature를 추출하면, 가장 자리에 있는 값들은 한번씩 밖에 추출이 안되는 현상이 발생함. 그래서, 패딩을 붙여줌으로써 가장자리까지 똑같이 학습할 수 있도록 만들어줌.
또 다른 이유는 입력값과 출력값의 사이즈를 맞춰주기 위함. 보통 filter를 하면, 출력값이 줄어들기 때문에, 결국 입력값과 출력값의 사이즈를 같게 만들 수 있음.
input & output을 똑같게 하기 위해서, 3*3 filter에 padding을 1로 주면 됨!
Input Shape(데이터 개수(batch size), channel, height, width)
Channel은 하나의 data를 구성하는 행렬의 개수를 의미하는데, channel은
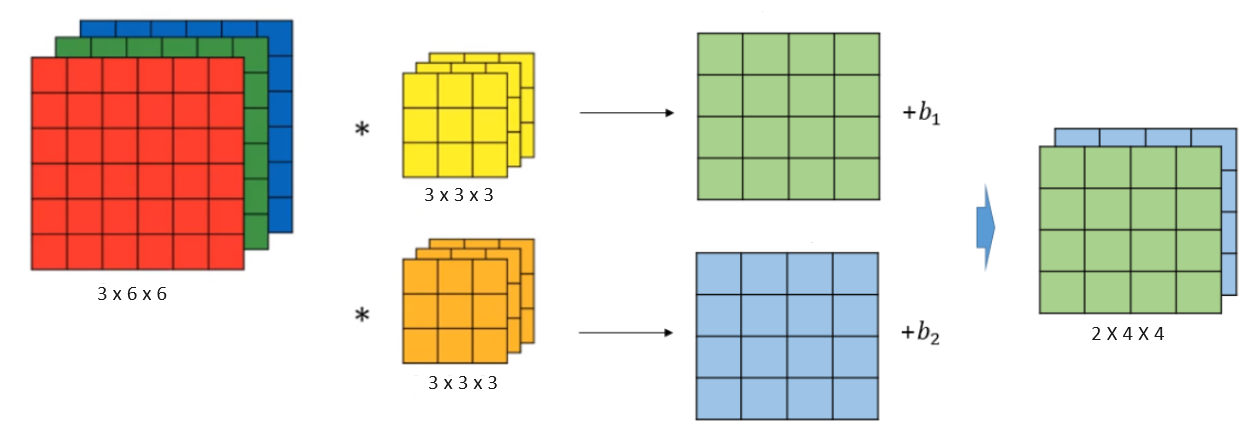
흑백과 컬러에 따른 이미지의 행렬 개수와 feature map(특성 개수- height x width)로 이루어져 있다. 이때, filter의 channel 수는 입력 데이터의 channel 수와 동일해야 함 !!

그림에서 본 것처럼, 만약 input data가 3x6x6이면, 3x3x3의 filter가 2개가 있고, 그럼 각각 4x4의 output 값이 나오고,그게 2개니깐 그럼 2x4x4의 output이 만들어짐
input_data = torch.ones(1, 3, 10, 10) # batch크기, channel수, heigth, width
output = layer(input_data)
output.shapeMax Pooling Layer for subsampling
Pooling Layer란?
Feature map의 특성 영역의 값들 중 그 영역을 대표할 수 있는 한개의 값을 추출하여 output을 만드는 것. 대표적으로 pooling layer에는 Max pooling과 Average pooling이 있음.
그렇다면, 왜 대표값을 추출해서 output값을 줄여주려고 하는 걸까?
당연히 feature map의 size가 너무 크면, 너무 오랜 시간과 비용이 필요하기 때문!
그래서 feature map을 추출하면, 그걸 downsampling 해줌.
torch.nn.MaxPool2d
- 해당 영역의 input 중에 가장 큰 값 출력
- 영역의 size와 stride를 동일하게 주어서 값을 추출하는 영역이 안겹치도록 해야 함
ex. 2x2의 크기에 stride는 2를 사용하면, height와 width가 각각 절반의 크기로 줄어듦.
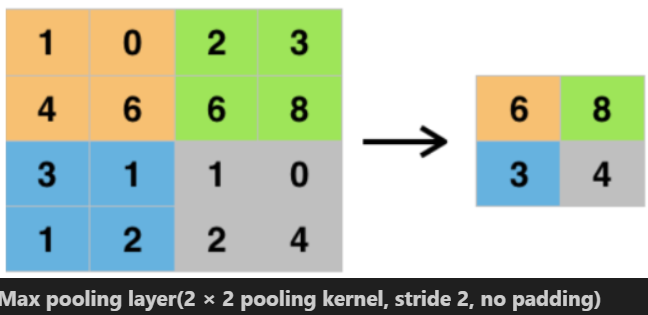
pool_layer = nn.MaxPool2d(
kernel_size=2, # 값을 추출하는 영역 크기(2, 2) - default: 2
stride=2, # 다음 값을 추출하기위해서 몇칸을 이동할지.(default: kernel_size)
padding=0
# 값을 추출할 영역이 kernel_size보다 작을 경우 추출할지 여부.
# 0-추출을 하지 않겠다.
)Pretrained 모델을 활용한 이미지 분류
pretrained model 사용하는 방식
-
Zero-shot transfer learning : 추가학습 없이 pretrained 모델을 사용
-
Transfer learning(전이 학습): pretrained 모델의 일부분을 재학습 시킴(주로 출력 Layer)
-
Fine-tuning : Pretrained 모델의 파라미터를 초기 파라미터로 사용 -> Custom dataset으로 학습을 진행해서 모든 파라미터 업데이트
이제 Pytorch에서 제공하는 Pretrained Model(https://pytorch.org/hub/)로 이미지 분류를 해보려고 하는데, 다양한 모델들이 많음.
1. VGGNet 모델: ImageNet dataset으로 사전 학습시킨 모델로 학습된 parameter를 제공 (120만장의 trainset, 1000개의 class로 구성)
1-1. 일단 정답이 뭔지 class 목록을 다운받아보자.
# ImageNet 1000개의 class 목록
%pip install wget
import wget
url = 'https://gist.github.com/yrevar/942d3a0ac09ec9e5eb3a/raw/238f720ff059c1f82f368259d1ca4ffa5dd8f9f5/imagenet1000_clsidx_to_labels.txt'
imagenet_filepath = wget.download(url) # url의 파일을 다운로드.
# string 형태를 dictionary로 바꿈
import ast
with open("imagenet1000_clsidx_to_labels.txt", "rt") as fr:
index_to_class = ast.literal_eval(fr.read()) # dictionary로 변환. #literal_eval은 eval과 다르게 실행하지 않고 그 값만 리턴해줌.
print(type(index_to_class), len(index_to_class))
1-2. Pretrained 모델 load
import torch
from torchvision import models, transforms
# torchvision.models: Pretrained 모델들을 제공.
from torchinfo import summary
## Pretrained 모델 Loading
load_model = models.vgg16(
weights=models.VGG16_Weights.DEFAULT # 학습된 weight(parameter) 도 같이 load #pretrained-model에서 이미지를 학습할 떄 써던 weight를 가져옴. #DEFAULT는 최신으로 학습한 파라미터
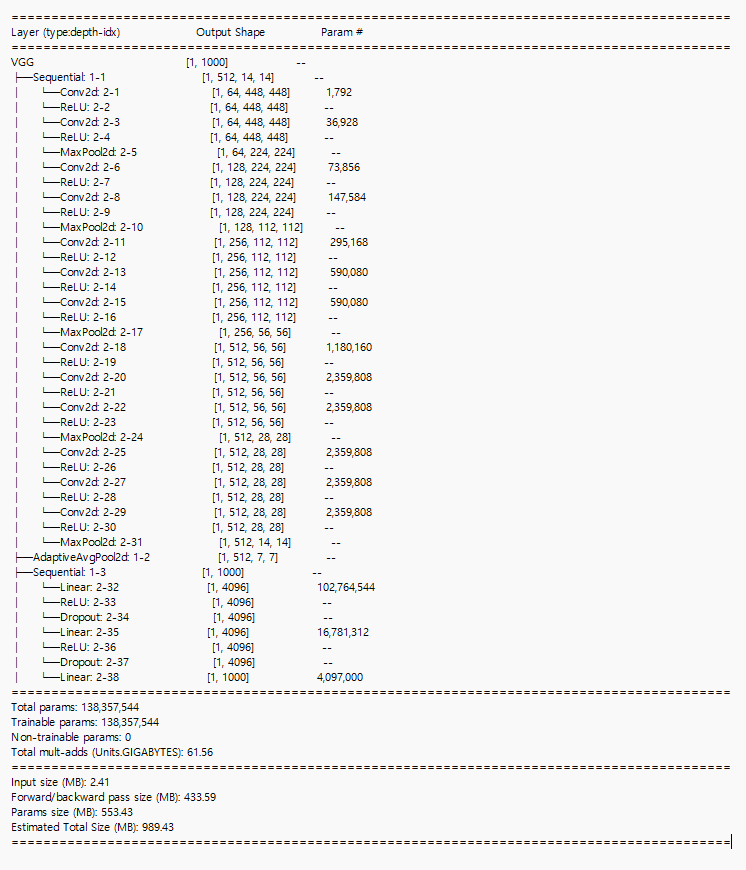
) 이 모델은 아래 summary를 보면 covolution&Relu를 두번씩 하고 나면, Max-pooling을 해서 size를 줄이는 구조를 5번 반복한 뒤에 adaptive_average pooling을 하는데 이건 output_size를 (7,7)로 맞춤. 여기서는 Global Average Pooling을 쓰는 대신 adaptive average pooling으로 장치를 하나 만들어주었는데, 그건 바로 classifier에 넣기 전에 output size를 무조건 7x7로 맞춰주기 위해 넣어둠. 즉, 각 데이터의 크기가 다를 수 있기 때문에 무조건 그걸 분류기랑 맞춰주기 위해서 장치를 하나 넣어둠
번외!) Adaptive_average_pooling - > Global Pooling에 대해 이야기 해보고자 한다! (output_size = (1,1))
추론 전에 flatten을 대신해서 Global pooling 해줄 수 있다고 했는데, 이렇게 pooling을 거치면 그냥 flatten을 할 때보다 feature map의 정보 손실을 최소화하면서 연산된 feature map의 사이즈를 크게 줄여줘서 연산 속도를 가속시키면서 globalization 효과로 overfitting을 방지해줄 수 있다.
그러나, 본 데이터셋은 값이 작아서 average_pooling을 해도 되지만, input data의 이미지가 커질수록 이미지 합성곱 연산층이 깊어져서 pooling만으로는 충분한 결과를 얻지 못할 수 있다 왜냐면, 대표값으로 해버리면, 원래 feature map이 가지고 있던 위치 정보를 모두 잃어버릴 수 있기 때문!
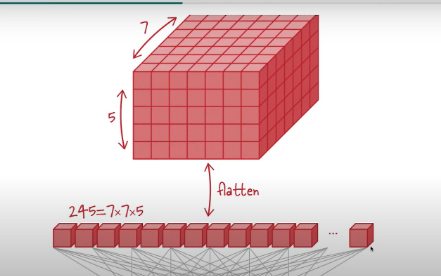 일반적으로 classfier 전달하는 방식 일반적으로 classfier 전달하는 방식 |
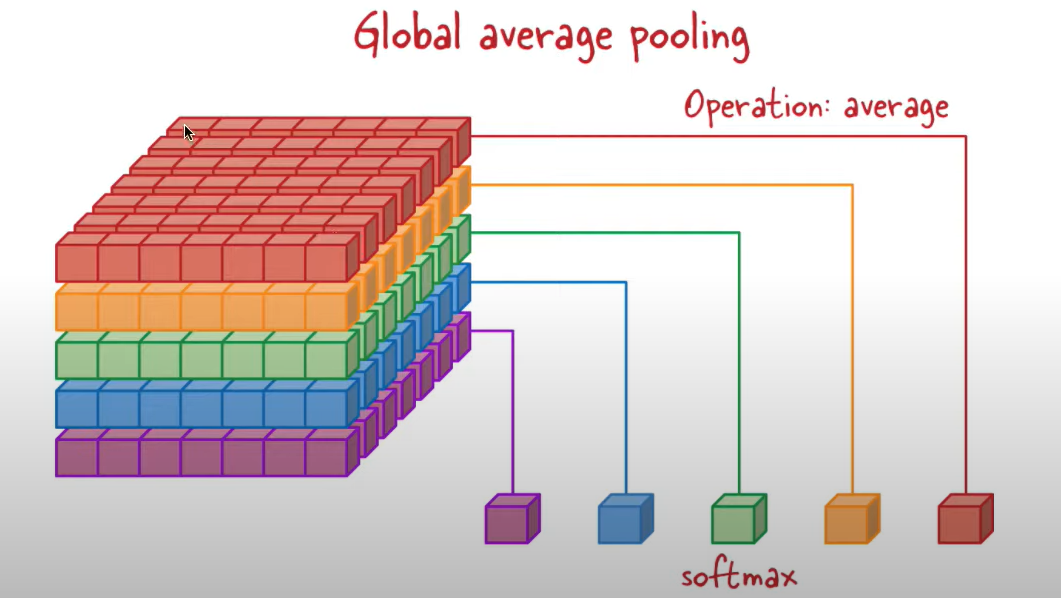 Global Average Pooling을 통해 Global Average Pooling을 통해 |
1-3. 추론
# 추론할 이미지 다운로드
import requests
from io import BytesIO
from PIL import Image
# img_url = 'https://cdn.download.ams.birds.cornell.edu/api/v1/asset/169231441/1800'
img_url = 'https://blogs.ifas.ufl.edu/news/files/2021/10/anole-FB.jpg'
# img_url = 'https://upload.wikimedia.org/wikipedia/commons/thumb/2/26/YellowLabradorLooking_new.jpg/640px-YellowLabradorLooking_new.jpg'
res = requests.get(img_url)
# res.content # binary data
# BytesIO() -> binary data(file)을 bytes 타입으로 변환.
test_img = Image.open(BytesIO(res.content)) # res: http 응답정보. res.content: 다운받은 binary 파일
test_img다음에는 데이터에 맞게 사이즈를 조정하는 과정이 필요함~!
transform = transforms.Compose([
transforms.Resize((224,224)), #데이터 사이즈에 맞게 조정
transforms.ToTensor() # tensor로 조정
])
input_tensor = transform(test_img).unsqueeze(0) # 배치 축 (batch: 1 추가)
input_tensor.shape추론 시작!
load_model = load_model.to(device)
input_tensor = input_tensor.to(device)
load_model.eval()
with torch.no_grad():
pred = load_model(input_tensor)
pred = torch.nn.Softmax(dim=-1)(pred) # softmax 처리
pred_cls = pred.max(dim=-1).indices[0] # 클래스 맥스값의 index 값
pred_proba = pred.max(dim=-1).values[0] # 맥스의 실제 값
print(pred_cls)
print(pred)
print(pred_proba) # softmax처리한 확률값
print(pred_cls, index_to_class[pred_cls.item()])
-------------------------------------------------------------
tensor(0.6342) #class중에 가장 높은 확률 값
tensor(47) African chameleon, Chamaeleo chamaeleon ##정답임!!2. transfer learning(전이학습)
- 미리 학습된(pre-trained) Model을 이용하여 모델을 구성한 뒤 현재 하려는 예측 문제를 해결함. 그래서 보통은 보통 Pretrained Model에서 Feature Extraction 부분을 사용함
- Computer Vision 문제의 경우 Bottom 쪽의 Convolution Layer(Feature Extractor)들은 이미지에 나타나는 일반적인 특성을 추출하므로 다른 대상을 가지고 학습했다고 하더라도 재사용할 수 있음.
- Top 부분 Layer 부분은 특히 출력 Layer의 경우 대상 데이터셋의 목적에 맞게 변경 해야 하므로 재사용할 수 없음.
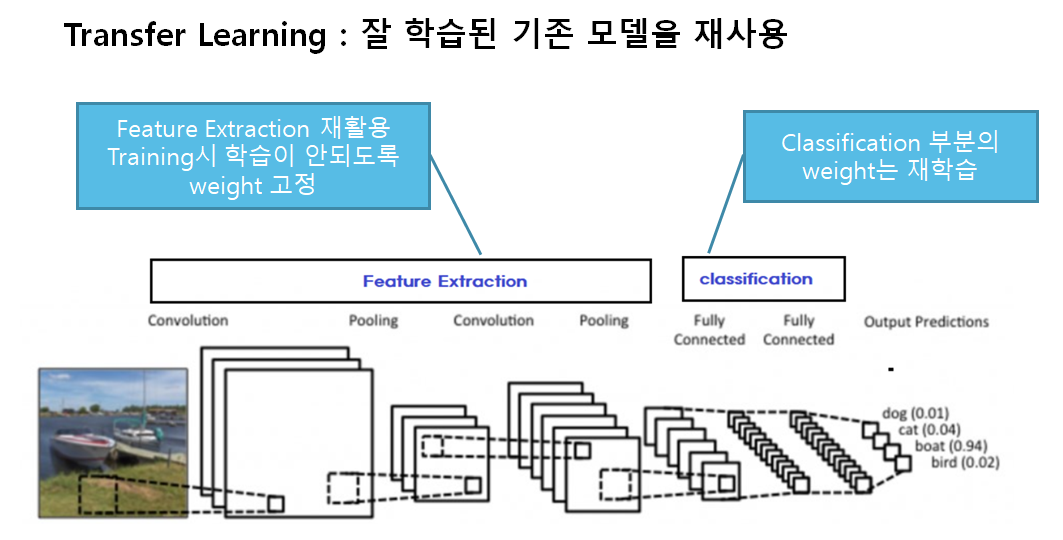
들어가기 전에 ! transfer learning의 종류에 대해서 좀 공부해보았다!
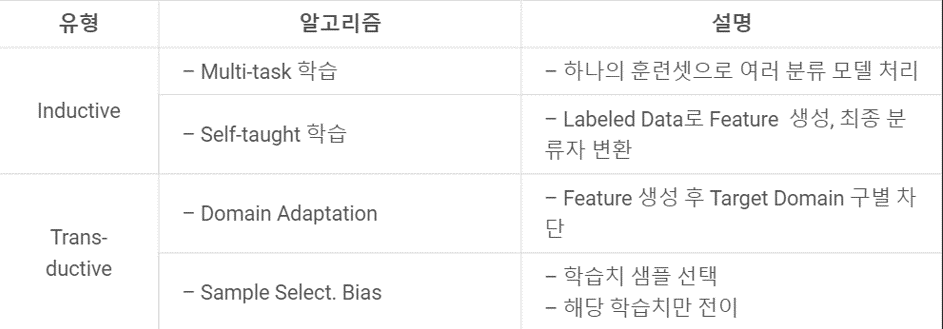 아래의 표에 자세히 설명되어 있지만, 귀납과 변형의 가장 큰 차이는 target domain에 label이 있는가 없는가의 차이이다. 귀납의 경우는 정답이 있기 때문에 그 정답에 대한 추론을 진행하지만, 변형 전이학습은 정답이 없어서, source의 label에만 국한되지 않고, target의 label을 도메인에 맞게 변형할 수 있다!
아래의 표에 자세히 설명되어 있지만, 귀납과 변형의 가장 큰 차이는 target domain에 label이 있는가 없는가의 차이이다. 귀납의 경우는 정답이 있기 때문에 그 정답에 대한 추론을 진행하지만, 변형 전이학습은 정답이 없어서, source의 label에만 국한되지 않고, target의 label을 도메인에 맞게 변형할 수 있다!
| 구분 | 알고리즘 |
|---|---|
| Inductive Transfer Learning (귀납적 전이 학습) | ✅ 특징: Target Domain에 Labeled Data 존재 ✅ 목적: 학습된 지식을 활용해 다른(또는 유사한) 태스크에 적용 |
| ┗ Multi-task 학습 | 하나의 학습 데이터셋으로 여러 태스크(분류기)를 동시에 학습 예시: 감정 분석 + 요약 작업을 동시에 학습하여 서로의 정보를 공유 |
| ┗ Self-taught 학습 | Labeled Data에서 feature를 생성하고, 이를 기반으로 최종 분류기에 전이 예시: Autoencoder로 학습된 feature를 분류기에 전달 |
| Transductive Transfer Learning (변형 전이 학습) | ✅ 특징: Target Domain에는 Labeled Data 없음 ✅ 목적: Source 도메인에서 학습된 지식을 Target 도메인에 맞게 변형 |
| ┗ Domain Adaptation | Feature를 생성한 후 target domain과 source domain 간 분포 차이를 극복 예시: 영어 뉴스로 학습한 모델을 한국어 뉴스에 적용할 때 언어 차이를 줄이는 방식 |
| ┗ Sample Selection Bias | 학습 시 특정 샘플만 선택하거나, 학습치가 제한된 상태에서 전이 예시: 특정 환경(도시)에서 수집된 데이터만으로 학습한 뒤 다른 지역에 적용 |
이제 본격적으로 코드를 하나씩 뜯어보자!
2-1. dataset, DataLoader
-
Image Augmentation
Augmentation은 기존의 이미지를 변형해주는 것인데, 데이터셋의 종류가 많지 않은 경우에 Cropping, Reverse, Rotation 등 여러 변형을 주어 모델이 받아들이기에 새로운 이미지처럼 만드는 것. (**이건 trainset에만 적용, validationset은 실제 데이터만 써야하니깐 augmentation 안함) -
전처리 과정
resize => ToTensor(channel first) => Normalization(정규화)

argumentation과 전처리를 하면 요렇게 된답니다~색깔은 normalize 하니까 이런 색깔이 됨
train_transform = transforms.Compose([
# 1) 전처리
transforms.Resize((224, 224)), # resize
transforms.ToTensor(), # ndarray, Image -> Tensor, 0 ~ 1 정규화, channel first
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)), # (Red, Green, Blue) -> 저 수치는 이렇게 했을 때 가장 성능이 좋다고 해서 가장 많이 씀.
# 채널별 평균, 표준편차설정. -> Standard Scaling 처리.(픽셀값-평균)/표준편차
# 2) Augmentation
transforms.RandomHorizontalFlip(), # 좌우 반전, 랜덤
transforms.RandomVerticalFlip(), # 상하 반전
transforms.RandomRotation(degrees=180) # 0-180도 사이 렌덤하게 회전
])
# validation에는 실제 데이터만 써야 하니까, augmentation 안함.
test_transform = transforms.Compose([
transforms.Resize((224, 224)), # resize
transforms.ToTensor(), # ndarray, Image -> Tensor, 0 ~ 1 정규화, channel first
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])- dataset 정의
# cat/dogs 디렉토리 이름이 class, 그 안에 데이터가 input data
train_set = datasets.ImageFolder(
os.path.join(target_path, "train"), # Data들을 저장한 디렉토리.
transform=train_transform
)
valid_set = datasets.ImageFolder(
os.path.join(target_path, "validation"),
transform=test_transform
)
test_set = datasets.ImageFolder(
os.path.join(target_path, "test"),
transform=test_transform
)- DataLoader
train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, drop_last=True,
num_workers=os.cpu_count()) # 데이터 불러오는 것 병렬처리.
valid_loader = DataLoader(valid_set, batch_size=BATCH_SIZE, num_workers=os.cpu_count())
test_loader = DataLoader(test_set, batch_size=BATCH_SIZE, num_workers=os.cpu_count())2-2. pretrained 모델(Backbone) 가져오기 (vgg16 활용)
# Transfer Learning - Backbone 모델: VGG16 + classifier(내것)
model = models.vgg16(models.VGG16_Weights.DEFAULT)
model2-3. Backbone 모델 frozen 시키기 -> 파라미터들이 학습시 update 되지 않도록 변경.
for p in model.parameters():
p.requires_grad = False2-4. classifier(분류기) 내것으로 변경
model.classifier = nn.Linear(in_features=25088, out_features=2) Linear(in_features=4096, out_features=1000, bias=True) ->
Linear(in_features = 25088, out_features =2)
이렇게 out_features가 바뀐걸 볼 수 있음 !
2-5. 학습
여기서 mode="multi"는 다중모델임을 설정해주는 값임.
os.makedirs("saved_models", exist_ok=True)
save_model_path = "saved_models/cat_dog_model.pt"
model = model.to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
result = fit(train_loader, valid_loader, model, loss_fn, optimizer, EPOCH,
save_best_model=True, save_model_path=save_model_path,
device=device, mode="multi") 2-6. 최종 평가
input_data 의 값을 사이즈에 맞춰서 넣어준 다음에 추론을 진행
load_model = torch.load(save_model_path)
def predict(image_path, model, transform, device):
# "model로 image_path의 이미지를 추론한 결과를 반환."
img = Image.open(image_path) # 추론대상 이미지 loading
input_data = transform(img) # shape: (C, H, W)
input_data = input_data.unsqueeze(dim=0) # (C, H, W) -> (1, C, H, W)
input_data = input_data.to(device)
# 추론
model = model.to(device)
model.eval()
with torch.no_grad():
pred = model(input_data)
pred_proba = pred.softmax(dim=-1) # 확률값으로 변경.
pred_label = pred_proba.argmax(dim=-1).item() # Tensor([3]) -> 3
pred_proba_max = pred_proba.max(dim=-1).values.item()
class_name = "cat" if pred_label == 0 else "dog"
return pred_label, class_name, pred_proba_max
predict("test_img/dog.jpg", load_model, test_transform, device)나가며..
이번 CV 의 여정은 꽤나 길었다... 하지만,,, 아직 2편이 남아있다. CV 너무 재밌자나~
2편에는 GAN 모델과 Stable Diffusion이 남아있으니, 많관부~~😁
