
👣 딥러닝 Pytorch
순식간에 머신러닝을 다 배우고, 지난 금요일에 딥러닝을 나가기 시작했다. 그래도 머신러닝에서 배웠던 선형회귀 모델과 loss 함수 등을 배워서 이해하는데 큰 어려움이 있진 않았다. 예측 모델을 만드는 과정은 생각보다 정해져 있다보니, 어떻게 오차를 줄일 것인가, 혹은 과적합이 피할 수 있는가에 대해 초점을 맞춘다면 좋은 성능의 모델을 만들어갈 수 있다.
📚 회고 구성
1️⃣ LEARN
1) 지난 일주일 동안 가장 인상 깊었던 배움
2) 그 배움까지 다가가는데 어떤 어려움이 있었는지
2️⃣FINDINGS & FEELINGS
: 그 과정에서 나는 무엇을 깨달았고, 어떤 감정/생각이 들었는지?
3️⃣ RESULT
: 결과적으로, 현재 나의 상태는?
4️⃣ HOW TO SOLVE
: 이 상태에서 다음 일주일을 더 잘 보내려면 어떻게 해야 할까?
1️⃣ LEARN
지난 일주일동안 가장 인상 깊었던 배움
이번 주는 사실 저번주보다 훨씬 더 많은 진도를 나갔다보니 과부하도 있었지만, 최대한 머리 속에 넣으려고 노력했다.
💡그 중에서도 가장 인상적인 부분을 정리하자면…
- 자동미분(requires_grad = True) - weight & bias
- 다중입력 - 다중출력
- Optimizer & loss함수
1. 자동미분(requires_grad = True)
- 자동 미분을 이용해 gradient(미분계수)를 계산하는 pytorch system.
- 딥러닝 모델에서 weight와 bias tensor들(Parameter)은 backpropagation(역전파)를 이용해 gradient를 구해서 loss가 줄어드는 방향으로 update를 하게된다.
- pytorch는 이런 미분 수행을 자동으로 처리해 준다.
- gradient(기울기)를 구한다는 것은 미분을 한다는 것을 말한다.
- tensor가 미분 가능하려면(gradient 계산 대상 변수)
requires_grad=True로 설정되어 있어야 한다. (default: False)
이걸 이용해서 간단한 경사하강법을 구현해보면,,,
# 간단한 경사하강법 구현
input_data = torch.tensor([30.2])
output_data = torch.tensor([10.5])
weight = torch.tensor([0.2], requires_grad=True)
y_pred = weight * input_data
loss = (output_data - y_pred)**2
loss.backward() #loss를 백워드하면, y_pred의 도함수를 먼저 계산한 다음에 loss의 도함수를 계산해서 합성함수(즉, 두 기울기를 곱한 값)로 계산
# loss = (output_data - (weight*input_data))**2
weight.grad
new_weight = weight.data - weight.grad * 0.0001
new_weight2. 다중입력 - 다중출력
- 다중입력: Feature가 여러개인 경우
- 다중출력: Output 결과가 여러개인 경우
| 온도(F) | 강수량(mm) | 습도(%) | 사과생산량(ton) | 오렌지생산량 |
|---|---|---|---|---|
| 73 | 67 | 43 | 56 | 70 |
| 91 | 88 | 64 | 81 | 101 |
| 87 | 134 | 58 | 119 | 133 |
| 102 | 43 | 37 | 22 | 37 |
| 69 | 96 | 70 | 103 | 119 |
사과수확량 = w11 * 온도 + w12 * 강수량 + w13 * 습도 + b1
오렌지수확량 = w21 * 온도 + w22 * 강수량 + w23 *습도 + b2
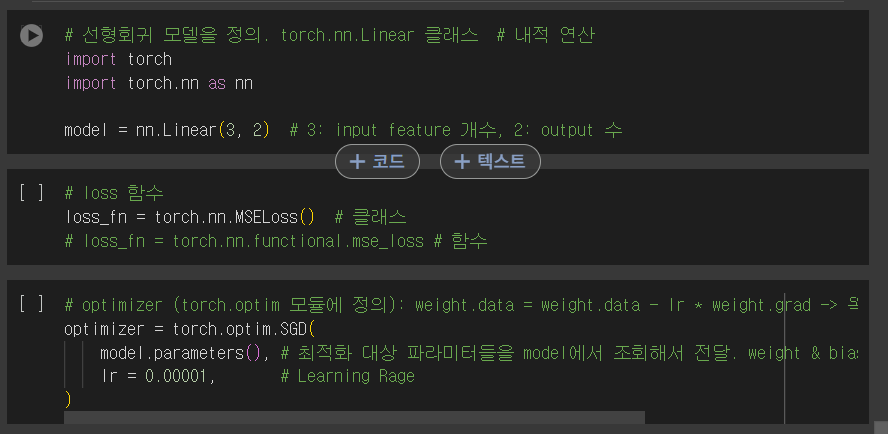
우선 weight를 보면 feature의 개수인 "온도, 강수량, 습도"와 이에 해당되는 예측할 값의 개수인 "사과수확량과 오렌지 수확량"니까 (3,2)가 된다.
다음으로 bias는 각 예측할 값에 대한 bias만 필요하니깐 (2, )의 shape가 필요하다.
3. Optimizer & Loss 함수
- Optimizer: 계산된 gradient값을 이용해 파라미터들을 업데이트 하는 함수
- Loss 함수: 정답과 모델이 예측한 값사이의 차이(오차)를 계산하는 함수.
- 모델을 최적화하는 것은 이 함수의 값을 최소화하는 것을 말한다.
2️⃣FINDINGS & FEELINGS
: 그 과정에서 나는 무엇을 깨달았고, 어떤 감정/생각이 들었는지?
저번주 금요일부터 딥러닝 파트로 넘어가면서, 난이도가 꽤나 올라가게 되었다. 그래도 가장 인상적인 부분이라고 한다면, 머신러닝과 다르게 딥러닝에서는 feature 자체의 특성을 학습해서 최종적인 feature를 줄여나가면서 주요 특성을 뽑아낸다는 점이다.
3️⃣ RESULT
: 결과적으로, 현재 나의 상태는?
머신러닝을 다루면서 꽤나 방대한 양을 빠르게 나가다보니, 놓치는 부분이 생길 때도 있었던 것 같다.그래도 딥러닝 부분과 머신러닝 부분이 어느정도 겹쳐있는 내용이 있어서 이해하는데 큰 어려움은 없었던 것 같다.
4️⃣ HOW TO SOLVE
: 이 상태에서 다음 일주일을 더 잘 보내려면 어떻게 해야 할까?
딥러닝에는 다양한 개념들이 많이 나와서, 개념별로 따로 정리해둘 필요가 있다.
이번주에는 딥러닝 모델 별로 정리한 내용을 올려볼까 한다.
