Seq2Seq(1) - Encoder&Decoder
Seq2Seq
- Encoder-Decoder 구조를 RNN 계열에 적용한 모델.
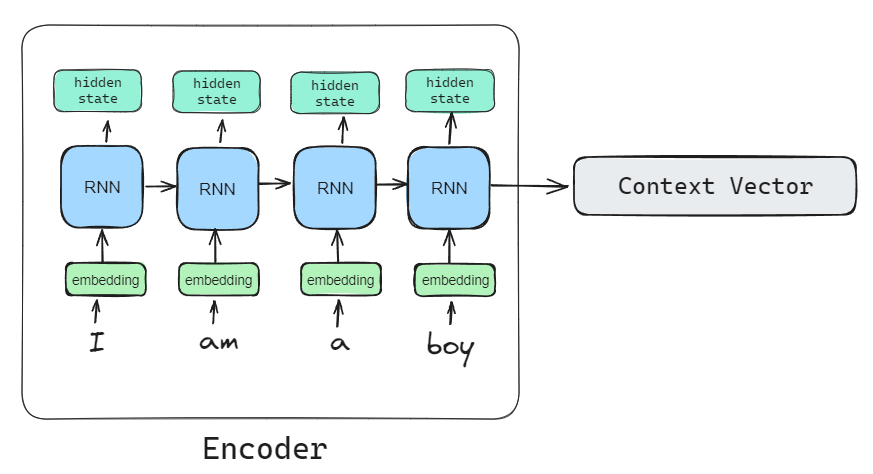
- Encoder: 입력 Sequence의 전체 의미(특징)을 표현하는 context vector를 출력
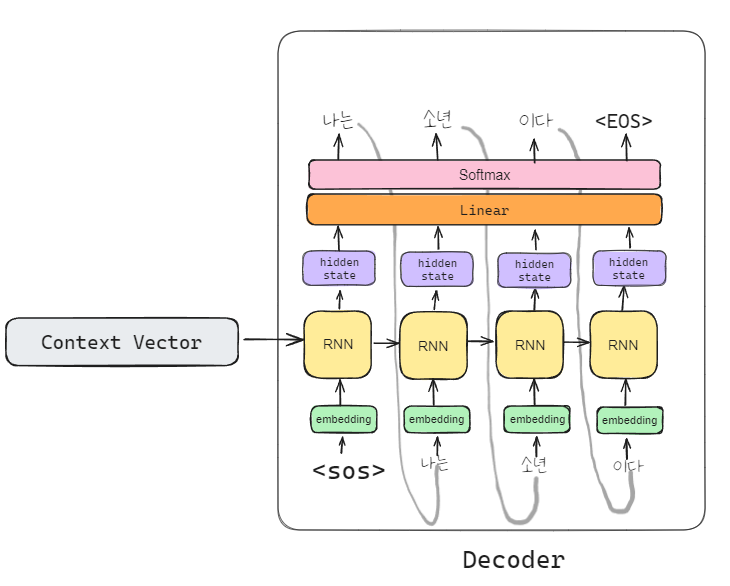
- Decoder: Encoder가 출력한 Context Vector를 입력받아 결과 sequence를 생성
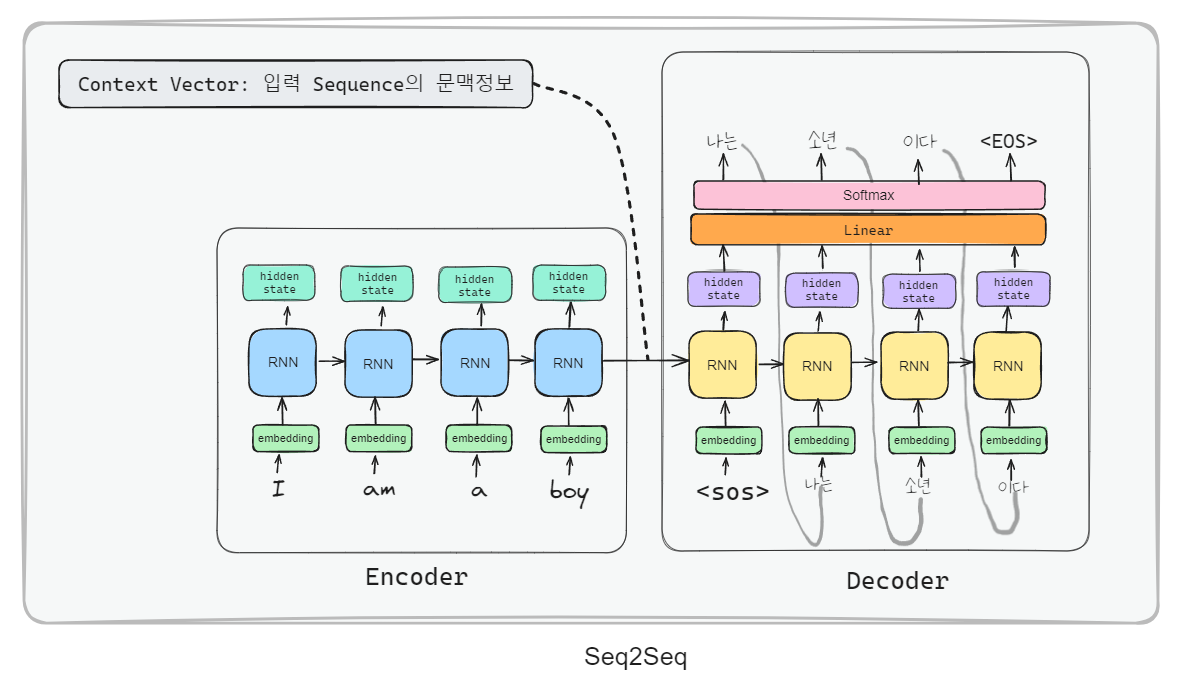
Seq2Seq 모델 정의
-
Seq2Seq 모델은 Encoder와 Decoder의 입력 Sequence의 길이와 순서가 자유롭기 때문에 챗봇이나 번역에 이상적인 구조다.
- 단일 RNN은 각 timestep 마다 입력과 출력이 있기 때문에 입/출력 sequence의 개수가 같아야 한다.(ex. many to many)
- Seq2Seq는 입력처리(질문,번역대상)처리 RNN과 출력 처리(답변, 번역결과) RNN 을 각각 만들고 그 둘을 연결한 형태이기 때문에,
길이가 다르더라도 상관없다.
Encoder (bidirectional, context vector)
-
Encoder class 구현하기
- nn.Module을 상속받아서 init() 메소드로 초기화 작업을 진행- forward(self, X)를 사용해서 계산식을 정의.
class Encoder(nn.Module): def __init__(self, vocab_size, embedding_dim, hidden_size, bidirectional=True, num_layers=1, dropout_rate=0.0): #bidirectional : 양방향성. 문장 token에 대해서 왼쪽에서 뽑아낸거랑 오른른쪽에서 시작해서 뽑아낸거 둘다 고려. super().__init__() # Encoder는 context vector(문장의 feature)를 생성하는 것이 목적 (분류기는 생성안함.) 여기서는 그냥 특징을 decoder에 주는 역할 # Embedding Layer, GRU Layer를 생성. self.vocab_size = vocab_size # 어휘사전의 총 어휘수(토큰수) # 임베딩레이어 self.embedding = nn.Embedding( vocab_size, # 총 어휘개수 (weight 행렬의 행) embedding_dim, # embedding vector 차원수. (Weight 행렬의 열 수) weight 행렬의 shape: [vocab_size, embedding_dim] padding_idx=0 # [PAD] (패딩 토큰의 ID) - padding의 embedding vector는 학습이 안되도록 한다.(vector값이 0으로 구성) ) # GRU self.gru = nn.GRU( embedding_dim, # 개별 토큰(time step)의 크기(feature 수). hidden_size=hidden_size, # hidden state의 크기- 개별 토큰 별로 몇개의 feature를 추출할지. num_layers=num_layers, bidirectional=bidirectional, dropout=dropout_rate if num_layers > 1 else 0.0 # stacked rnn일 경우(layer가 여러개일 경우), dropout 적용. ) def forward(self, X): # 계산 # X shape: (batch, seq_len) 토큰값 하나씩 X = self.embedding(X) # (batch, seq_len, embedding_dim) X = X.transpose(1, 0) # (seq_len, batch, embedding_dim) out, hidden = self.gru(X) return out, hiddenDecoder (bidirectional X, 다중 분류)
class Decoder(nn.Module): # auto regressive RNN 모델은 단방향만 가능 def __init__(self, vocab_size, embedding_dim, hidden_size, num_layers=1, bidirectional=False, dropout_rate=0.0): #여기서는 역방향을 할 수 없음. 앞에서 생성이 되어야 하는데, 뒤로 하면 생성 안됨. super().__init__() self.vocab_size = vocab_size # 총 어휘사전 토큰 개수. # embedding layer self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=0) # GRU ## Auto Regressive RNN은 단방향만 가능. self.gru = nn.GRU(embedding_dim, hidden_size, num_layers=num_layers, dropout=dropout_rate if num_layers > 1 else 0.0) # Dropout layer (feature랑 분류기 사이에 dropout layer 넣기) self.dropout = nn.Dropout(dropout_rate) # 분류기 (다음 단어(토큰)를 추론) # - 다중분류(단어사전의 단어들의 다음 단어일 확를) self.lr = nn.Linear( hidden_size, # GRU 출력 값 중 마지막 hidden state값을 입력으로 받음. # ev -> --- -> hidden state -> linnear에 넣기 vocab_size) # 출력: 다음 단어일 확률 def forward(self, X, hidden): # X: torch.LongTensor: shape - [batch] : 한 단어씩 입력을 받음. # hidden: torch.FloatTensor: shape - [1, batch, hidden_size] (이전까지의 특성) # sequence_length는 1이 됨 (단어가 한개) X = X.unsqueeze(1) # seq_len 축을 추가. [batch] -> [batch, 1] (Embedding Layer의 input shape) 1: sequance_length X = self.embedding(X) # [batch, 1, embedding 차원] X = X.transpose(1, 0) # [1, batch, embedding 차원] #seq_len이랑 batch 축 바꿈. out, hidden = self.gru(X, hidden) last_out = out[-1] # out: 전체 hidden state값-> 마지막 hidden state을 추출 # 근데 어차피 seq_len이 1이니까 한개임. self.dropout(last_out) # 과적합을 막아주기 위해서 dropout 진행 last_out = self.lr(last_out) #last_out : 어휘 사전의 단어들에 대해 다음 단어일 확률. return last_out, hidden # (hidden: 다음 timestep에 전달.) # hidden도 같이 다음 꺼에 넣어야 함, - forward(self, X)를 사용해서 계산식을 정의.

Proverbs 2:20
어랏 복귀하셨네요