1. Introduction
Attention is all you need
attention 메커니즘은 기존의 NLP 모델이 사용하던 RNN(vanila RNN,seq2seq,LSTM) 구조의 gradient vanishing으로 인한 문제를 해결하고 Transformer 구조를 제안한다. self-attention을 활용하며 parallel 처리로 빠른 학습 속도를 가지며, long distance dependency 해결
기존 구조들
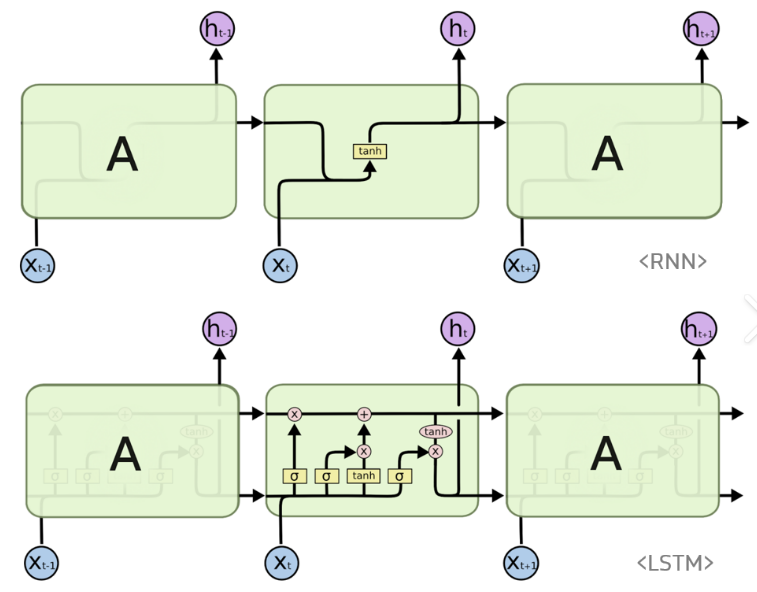
- vanila RNN
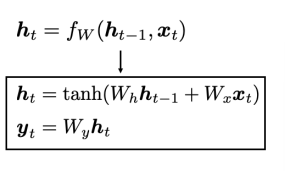
weight update를 위한 backpropagation 시, vanishing(or exploding) gradient 문제로 long term effect 소실 가능성 있음.
- LSTM
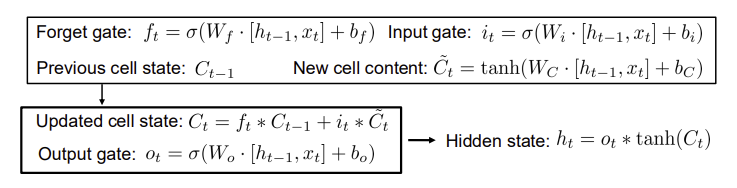
RNN에 cell state(memory -> )를 추가함. sigmoid layer([0,1]로 만드는 함수) 인 forget gate(), input gate(), output gate()를 통해서 cell state내에 정보 조절함
- seq2seq
encoder-decoder 구조 사용
encoder: input sequence를 읽고 encode to context vector(고정길이)
decoder: 벡터에서 output sequence 추출 (auto regressive)
->고정된 벡터 사용으로 인해서 모든 decoding step에서 동일 context 사용해야하는 문제(실제로는 각 decoding 부분마다 요구하는 context가 다름)
이후 RNN 구조에 attention 추가해서 해결
attention: query(decoder hidden state), key(encoder hidden state), value(encoder hidden state) 벡터들을 사용해 각 context의 확률을 계산
기존 모델의 문제
RNN
-> 먼 단어가 상호작용에 시간이 걸리고, 정보 손실이 존재(gradient 문제 있음)
-> unparallelizable(병렬 불가능), future hidden state 가 먼저 계산될 수 없음
2. Attention Architecture
encoder-decoder structure 을 통해서 auto regressive하게 작동한다.
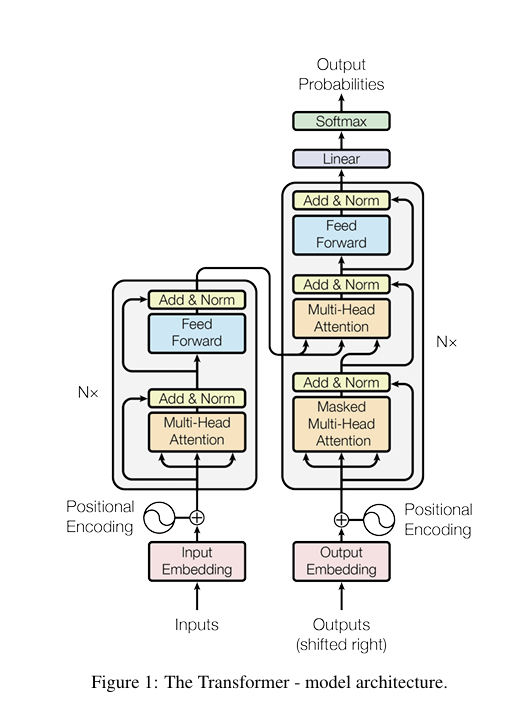
2-0. input
tokenized + positional encoding(sin/cos 함수 & 상대적 거리 파악)
2-1. encoder/decoder
encoder
- 동일한 구조 레이어 6개
- Multi-Head Self-Attention

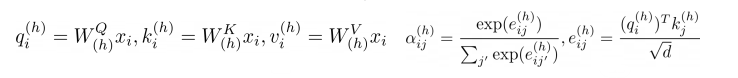
- 같은 Q, K, V를 h개의 다른 가중치 행렬(, , )로 변환
- 각각 독립적으로 Attention 계산 → h개의 headᵢ
- 모두 이어붙인(Concat) 뒤 로 선형 변환해 최종 출력
가 커질수록 Dot-product의 값이 커져 Softmax 함수에서 Gradient Vanishing 발생. 이를 방지하기 위해 로 나눔
(논문: 8개 헤드, 각 헤드 차원=64)
- Add & Normalization
Add: LayerNorm(x + z) --- 이전 출력(input 결과)과 현재 출력(attention 결과)와 선형 결합 residual connection / 기울기소실 문제 해결
Normalization: feature 차원으로 정규화 - 여러 mini batch 사용시 유리
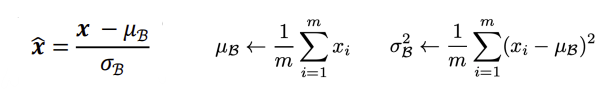
- Position-wise Fully-Connected Feed-Forward Network(FFN)
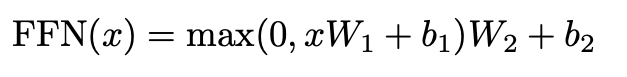
2번 선형 변환 후 ReLU 함수 적용
정보를 섞는 과정
decoder
- 동일한 구조 레이어 6개
- Masked Multi-Head Self-Attention
Masked의 역할: 학습 시 디코더가 미래의 단어를 미리 보고 예측하는 치팅을 방지하기 위해, 현재 시점 이후의 토큰들을 로 마스킹하여 Softmax 결과가 0이 되게 만듦
left to right 방식으로 과거의 정보만 사용 - Encoder decoder cross attention
seq2seq과 동일한 구조 (decoder hidden state:query, encoder hidden state:key, value)
출력 단어와 입력 문장(encoder 결과)와의 연관
3. Experiment
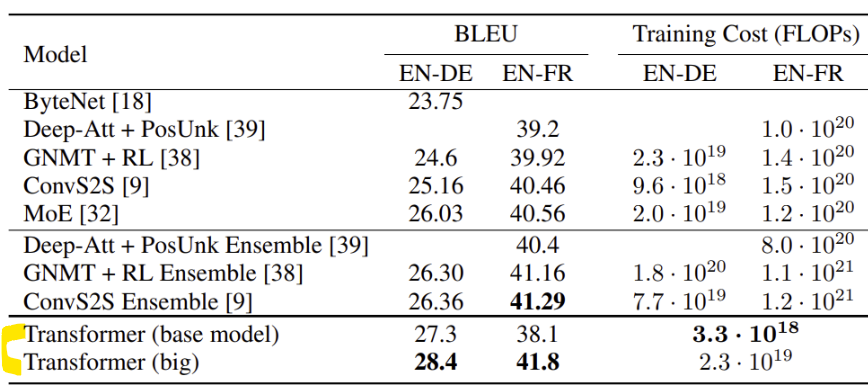
EN-DE & EN-FR 번역 과제에서 이전 모델보다 더 높은 BLEU 점수를 기록, 학습 비용 크게 절감
4. Discussion
장점
- 병렬 처리로 학습, 추론 속도 빠름
- Maximum Path Length: RNN은 O(n)이지만 Self-Attention은 O(1)
한계
- input 커질 수록 O()의 시간 복잡도 가짐
