
Milvus 벡터DB의 인덱스 타입을 알아보자. 그리고 TF-IDF와 BM25를 사용하여 sparse vector를 구해보고, 이를 milvus에 적재해보자.
📑 Milvus index type
👉 Milvus 인덱스 전체 개념 + 타입별 추천 사용법을 정리해보자!
1️⃣ Milvus 인덱스란?
- Milvus는 벡터 검색을 빠르게 하기 위해 인덱스(Index)를 미리 만들어두는 구조.
- 인덱스를 지정하면 Milvus는 벡터를 효율적으로 저장 → 빠른 검색 가능.
- 필드 타입마다 지원되는 인덱스가 다름.
💽 Dense Vector Index
2️⃣ Milvus 인덱스 종류 (Field Type 별)
🔹 (A) Dense Vector용 인덱스 (FLOAT_VECTOR)
→ Dense Vector = OpenAI Embedding, Sentence-BERT 같은 768/1536차원 임베딩
| Index Type | 특징 |
|---|---|
| FLAT | 전체 스캔(Exhaustive Search). 인덱스 없음. 정확도 100%지만 느림 |
| IVF_FLAT | 벡터를 여러 “버킷”(클러스터)로 나눠서 검색. nlist 파라미터 필요 |
| IVF_SQ8 | IVF + 8비트 양자화. 메모리 절약 |
| IVF_PQ | IVF + Product Quantization. 초고차원 벡터 압축 |
| HNSW | 그래프 기반 검색(빠르고 정확). 최신 RAG/LLM 서비스에서 자주 사용 |
| AUTOINDEX | Milvus가 알아서 선택 (실험적 기능) |
🔔 Metric Type (유사도 측정 방식)
L2(유클리드 거리) → 가장 기본적IP(Inner Product) → 코사인 유사도 대신 자주 씀 (특히 normalized embedding일 때)COSINE→ 코사인 유사도 (Milvus 최신 버전에서 지원)
from pymilvus import Collection
collection = Collection("my_dense_collection")
# Dense Vector 인덱스 생성
collection.create_index(
field_name="dense_vector", # 벡터 필드 이름
index_params={
"index_type": "HNSW", # ✅ 추천 인덱스 (빠르고 정확)
"metric_type": "COSINE", # ✅ 유사도 측정 방식 (COSINE, IP, L2 중 하나)
"params": {"M": 8, "efConstruction": 64} # HNSW 세부 설정
}
)
print("✅ Dense Vector 인덱스 생성 완료")💽 Sparse Vector Index
🔹 (B) Sparse Vector용 인덱스 (SPARSE_FLOAT_VECTOR)
→ Sparse Vector = BM25, TF-IDF 처럼 {단어ID: 점수} 형태로 만든 벡터
| Index Type | 특징 |
|---|---|
| SPARSE_INVERTED_INDEX | 희소 벡터 전용 역색인. BM25/TF-IDF Sparse Search 전용 |
| (별도 옵션 거의 없음) | metric_type 지정할 필요 없음 (대부분 IP 사용) |
collection = Collection("my_sparse_collection")
# Sparse Vector 인덱스 생성
collection.create_index(
field_name="bm25_vector", # Sparse Vector 필드 이름
index_params={
"index_type": "SPARSE_INVERTED_INDEX", # ✅ Sparse 전용 인덱스
"params": {"drop_ratio_build": 0.3} # ✅ (옵션) 희귀 단어 드롭 비율
}
)
print("✅ Sparse Vector 인덱스 생성 완료")💽 Scalar Field Index
🔹 (C) Scalar Field (숫자, 문자열)
INT64,VARCHAR같은 메타데이터 검색용 인덱스
| Index Type | 특징 |
|---|---|
| INVERTED | 텍스트/숫자 역색인 (SQL WHERE 절 같은 조건 검색 가능) |
| STL_SORT | 정렬(search with sort) 최적화 |
collection = Collection("my_collection")
# 문자열(VARCHAR) 필드 인덱스 생성
collection.create_index(
field_name="text",
index_params={
"index_type": "INVERTED" # ✅ 텍스트 역색인
}
)
print("✅ VARCHAR 필드 인덱스 생성 완료")dense/sparse/scalar 등 인덱스를 생성한 후에는 load()를 진행해야 한다!
# 인덱스 생성 후 load() 해야 검색 가능
collection.load()
print("✅ 컬렉션 로드 완료 (검색 가능 상태)")💽 어떤 인덱스를 지정할까?
3️⃣ 타입별로 뭐를 지정해야 하나?
📌 1) FLOAT_VECTOR (Dense Vector)
👉 추천 인덱스: HNSW 또는 IVF_FLAT
👉 metric_type:
COSINE(RAG 서비스 대부분)IP(inner product, cosine과 비슷)L2(거리 기반)
예제:
collection.create_index(
"dense_vector",
{
"index_type": "HNSW",
"metric_type": "COSINE",
"params": {"M": 8, "efConstruction": 64}
}
)📌 2) SPARSE_FLOAT_VECTOR (Sparse Vector)
👉 추천 인덱스: SPARSE_INVERTED_INDEX (무조건)
👉 metric_type: 자동으로 IP (선택할 필요 없음)
예제:
collection.create_index(
"bm25_vector",
{
"index_type": "SPARSE_INVERTED_INDEX",
"params": {"drop_ratio_build": 0.3} # optional
}
)📌 3) VARCHAR (텍스트 메타데이터)
👉 추천 인덱스: INVERTED (키워드 검색용)
👉 metric_type 없음
예제:
collection.create_index(
"text",
{
"index_type": "INVERTED"
}
)📌 4) INT64 (숫자 메타데이터)
👉 인덱스 거의 안 만듦 (Primary Key라 자동 관리)
💽 정리
4️⃣ 정리
- Dense Vector → HNSW (추천) / IVF_FLAT, metric_type 꼭 필요 (COSINE/IP/L2)
- Sparse Vector → SPARSE_INVERTED_INDEX (metric_type 없음)
- 문자열(VARCHAR) → INVERTED (필요할 때만)
- Primary Key → 인덱스 필요 없음
❓ 의문점: PK
1️⃣ Milvus에서 PK(Primary Key)는 하나만 지정할 수 있을까?
- YES.
- Milvus는 하나의 컬렉션(Collection)당 PK 필드를 단 하나만 허용
- PK는 고유성(Unique) 과 삭제/업데이트/조회 기준을 위한 필드라서, 여러 개 있을 수 없음
📌 예시 (올바른 PK 지정)
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True)📌 예시 (❌ 두 개 PK 지정 → 에러)
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="user_id", dtype=DataType.INT64, is_primary=True)
# 👉 ❌ **Milvus 에러 발생**2️⃣ PK 말고 나머지 필드는 다 인덱스를 지정해야 하나?
- No!
- “무조건” 인덱스를 지정해야 하는 건 아님.
- 하지만 어떤 “검색/조건”을 하고 싶은지에 따라 인덱스가 필요할 수도 있고 아닐 수도 있음
📂 필드 타입별 인덱스 필요 여부
- PK (INT64)
- ❌ 인덱스 지정 필요 없음 (Milvus가 내부적으로 자동 관리)
- Dense Vector (FLOAT_VECTOR)
- ✅ “유사도 검색” 하려면 반드시 인덱스 필요 (HNSW, IVF_FLAT 등)
- 인덱스 없으면
FLAT(전수 검색) 으로 검색됨 → 느림- Sparse Vector (SPARSE_FLOAT_VECTOR)
- ✅ Sparse Search 하려면
SPARSE_INVERTED_INDEX필수- 문자열(VARCHAR), 숫자(INT, FLOAT 등)
- 검색 조건(expr)으로만 쓸 거면 인덱스 없어도 됨
- 빠른 조건 검색/정렬을 원하면 INVERTED/STL_SORT 같은 인덱스 추가
✅ 정리
- PK는 1개만 가능.
- PK는 자동 인덱싱 → 우리가
create_index()안 해도 됨.- Dense/Sparse Vector는 유사도 검색하려면 인덱스 지정해야 함.
- 그 외 필드(text, number)는 선택사항 → 단, 빠른 검색을 원하면 인덱스를 지정하는 게 좋음.
➡ 예를 들어:
- BM25 검색용 →
bm25_vector→ ✅SPARSE_INVERTED_INDEX - 문자열 조건 검색 →
text→ ✅INVERTED(선택) - 메타데이터만 저장하고 검색 안 하면 → ❌ 인덱스 필요 없음
🥌 Sparse Vector
희소 벡터를 데이터베이스에 적재하기 위한 과정을 거친다.
그 전에 희소 벡터를 어떻게 생성하는지 과정을 알아보자.
1️⃣ 문서 토큰화 (Tokenization)
- 먼저 문장을 단어(토큰)로 쪼갬
- 예:
"나는 사과를 좋아해" → ["나", "는", "사과", "좋아해"] - 한국어라면
Kiwi,Mecab,Konlpy같은 형태소 분석기를 쓰고 - 영어라면
NLTK,spaCy같은 토크나이저를 사용
2️⃣ 각 단어의 가중치 계산 (TF-IDF 또는 BM25)
- TF (Term Frequency): → 특정 문서 안에서 단어가 몇 번 등장했는지
- IDF (Inverse Document Frequency): → 단어가 전체 문서에서 얼마나 희귀한지
➡ TF × IDF = TF-IDF 점수
- Vocabulary(단어 사전)는 전체 문서(corpus) 기준으로 만든다
- TF(Term Frequency)는 ‘문서 단위’로 계산 → 특정 문서에서 단어가 등장하지 않는다면 TF=0
- TF-IDF 계산 설명
💊 TF-IDF 계산
📄 **예제 문서 3개**
- 문서1: **“고양이가 귀엽다”**
- 문서2: **“강아지가 귀엽다”**
- 문서3: **“강아지가 똑똑하다”**
---
1️⃣ Vocabulary(단어 사전) 만들기
모든 문서를 토큰화하고 **등장한 모든 단어**를 모아 인덱스를 붙임.
```
['고양이', '귀엽다', '강아지', '똑똑하다']
```
---
2️⃣ TF (Term Frequency) 계산
👉 **한 문서 안에서 단어가 몇 번 나왔는지** 센 값.
예: 문서1(“고양이가 귀엽다”)
```
고양이: 1
귀엽다: 1
강아지: 0
똑똑하다: 0
```
문서2(“강아지가 귀엽다”)
```
고양이: 0
귀엽다: 1
강아지: 1
똑똑하다: 0
```
문서3(“강아지가 똑똑하다”)
```
고양이: 0
귀엽다: 0
강아지: 1
똑똑하다: 1
```
---
3️⃣ **DF (Document Frequency)** 계산
👉 **각 단어가 몇 개 문서에 등장했는지** 센 값.
- **고양이** → 1개 문서에 등장 (문서1)
- **귀엽다** → 2개 문서에 등장 (문서1, 2)
- **강아지** → 2개 문서에 등장 (문서2, 3)
- **똑똑하다** → 1개 문서에 등장 (문서3)
---
4️⃣ **IDF (Inverse Document Frequency)** 계산
👉 **자주 나오는 단어는 점수를 낮추고, 희귀한 단어는 점수를 높임.**
🏓 IDF 공식 (스무딩 적용):
`IDF(t)=log1+N1+df(t)+1IDF(t) = \log \frac{1 + N}{1 + df(t)} + 1`
- 전체 문서 수 **N = 3**
각 단어 IDF 계산:
- **고양이** → log1+31+1+1=log(2)+1≈1.693\log \frac{1+3}{1+1} + 1 = \log(2) + 1 ≈ 1.693
- **귀엽다** → log1+31+2+1=log(1.33)+1≈1.287\log \frac{1+3}{1+2} + 1 = \log(1.33) + 1 ≈ 1.287
- **강아지** → log1+31+2+1≈1.287\log \frac{1+3}{1+2} + 1 ≈ 1.287
- **똑똑하다** → log1+31+1+1≈1.693\log \frac{1+3}{1+1} + 1 ≈ 1.693
---
5️⃣ **TF × IDF = TF‑IDF 점수 계산**
👉 문서별로 각 단어의 점수를 곱함.
### 📄 문서1: “고양이가 귀엽다”
- 고양이 → 1 × 1.693 = **1.693**
- 귀엽다 → 1 × 1.287 = **1.287**
- 강아지 → 0 × 1.287 = 0
- 똑똑하다 → 0 × 1.693 = 0
➡ 문서1의 TF‑IDF 벡터:
```
{'고양이': 1.693, '귀엽다': 1.287}
```
---
### 📄 문서2: “강아지가 귀엽다”
- 고양이 → 0 × 1.693 = 0
- 귀엽다 → 1 × 1.287 = **1.287**
- 강아지 → 1 × 1.287 = **1.287**
- 똑똑하다 → 0 × 1.693 = 0
➡ 문서2의 TF‑IDF 벡터:
```
{'강아지': 1.287, '귀엽다': 1.287}
```
---
### 📄 문서3: “강아지가 똑똑하다”
- 고양이 → 0 × 1.693 = 0
- 귀엽다 → 0 × 1.287 = 0
- 강아지 → 1 × 1.287 = **1.287**
- 똑똑하다 → 1 × 1.693 = **1.693**
➡ 문서3의 TF‑IDF 벡터:
```
{'강아지': 1.287, '똑똑하다': 1.693}
```
---
6️⃣ **왜 “Sparse Vector”라고 하나?**
- 전체 vocabulary = 4개 단어
- 한 문서에는 **2개 정도 단어만 등장**
- 나머지 단어 점수는 **0 → 저장할 필요 없음**
➡ 그래서 **값이 있는 것만** `{단어: 점수}` 형태로 남김.
---
## 🔍 **한 줄 요약**
- **TF‑IDF = (문서 안 단어 빈도) × (단어가 희귀할수록 점수 증가)**
- 자주 쓰이는 흔한 단어(예: “그리고”, “the”)는 자동으로 점수가 낮아지고,
- 특정 문서에만 나오는 희귀한 단어는 점수가 확 올라감.👉 “자주 나오면서 희귀한 단어”일수록 TF-IDF 점수가 높음
💊 BM25:
→ TF-IDF를 검색 성능에 맞춰 개선한 공식
→ 문서 길이 보정, 파라미터 조정(k1, b) 등으로 검색 품질을 높임
### ✅ **BM25 점수 해석 포인트**
- **0점** → 쿼리 단어가 **하나도 안 들어간 문서**
- **점수 > 0** → 쿼리 단어가 들어간 문서 (많이 들어갈수록, 희귀 단어일수록 점수 ↑)
- **점수 비교** → **점수가 높을수록 쿼리와 연관성이 크다**3️⃣ Sparse Vector로 변환
- TF-IDF나 BM25 점수를
{토큰 인덱스: 점수}형태로 바꿈 - 예:
{0: 0.5, 2: 0.9, 5: 0.7} - 이렇게 하면 대부분의 값은 0 → 메모리 절약 + 빠른 검색
4️⃣ 벡터DB에 SPARSE_FLOAT_VECTOR로 저장
📌 정리
- ✅ 토큰화 → TF-IDF/BM25 계산 → Sparse Vector 생성 → DB 적재
- 🔍 Dense Vector는 임베딩 모델(OpenAI, BERT)로 바로 얻지만,
- 🔍 Sparse Vector는 반드시 토큰화 후 → 통계 기반 계산(TF-IDF, BM25)을 거쳐야 함
📍 Milvus 적재
위에서 만든 희소 벡터를 Milvus에 적재해보자.
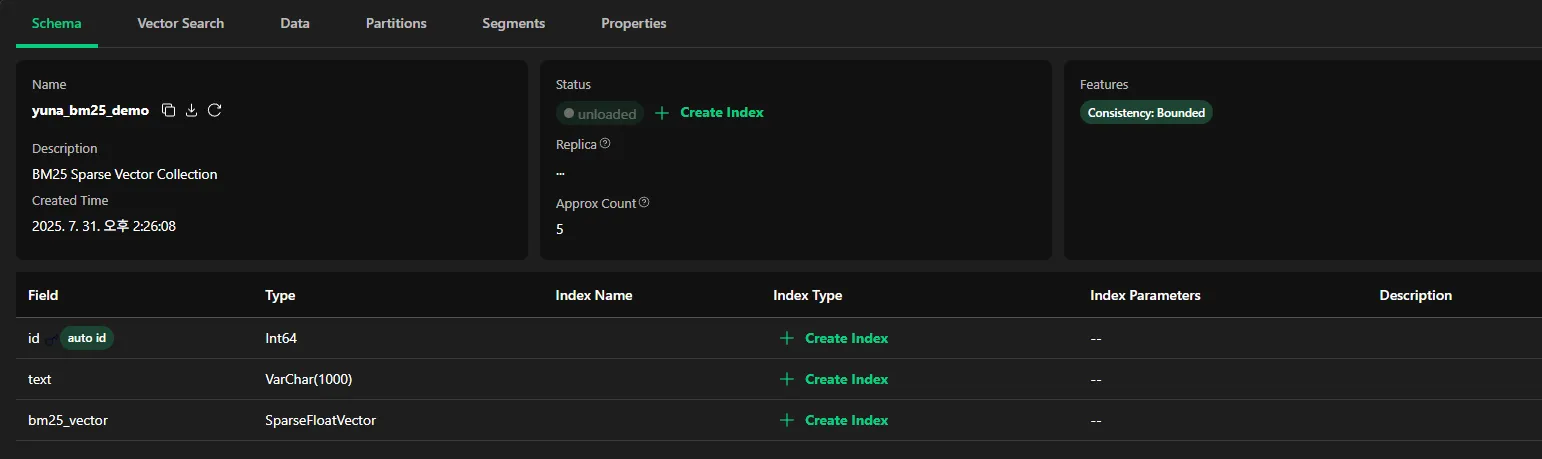
우선 희소벡터에 인덱스를 지정하지 않은 경우이다.
- 직접 index type 지정한 후 load 누르면 됨, pk는 인덱스 미지정
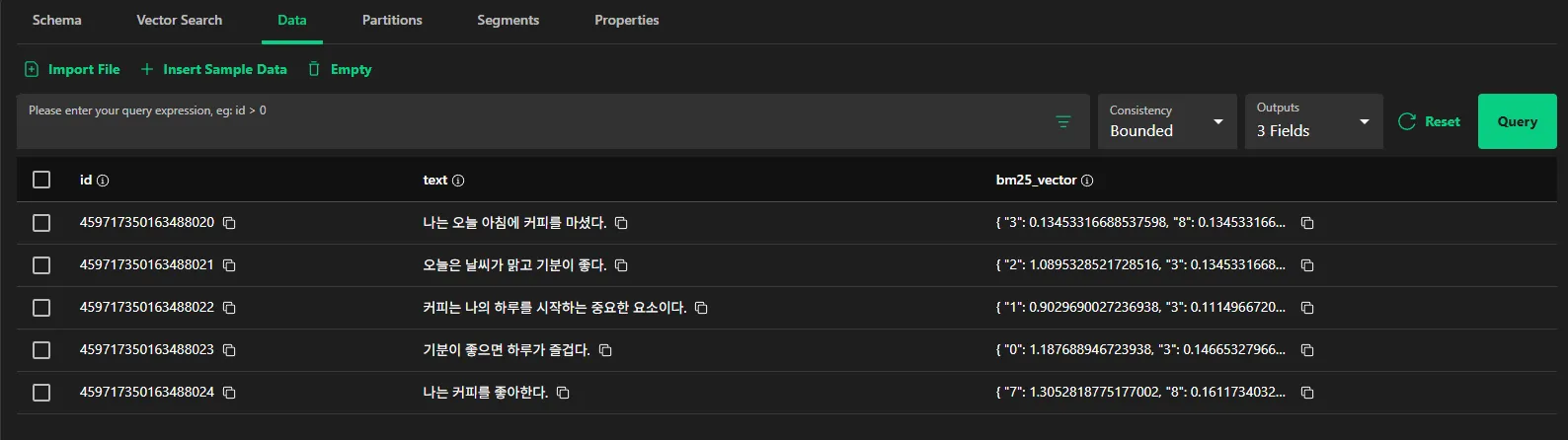
- load가 되어야 데이터가 보인다.
# BM25 를 활용
# 단어 사전 생성: 등장한 모든 단어 중복 제거 후 리스트화
vocab = list(set(token for doc in tokenized_docs2 for token in doc))
# 단어마다 고유 인덱스 부여
token_to_id = {token: idx for idx, token in enumerate(vocab)}
sparse_vectors2 = []# 하이퍼파라미터
# k1: 단어 빈도(TF)를 얼마나 강조할지 (기본 1.2~2.0)
# b: 문서 길이 보정 정도 (기본 0.75)
k1, b = 1.5, 0.75
# 평균 문서 길이
avgdl = sum(len(doc) for doc in tokenized_docs2) / len(tokenized_docs2)
# 한 문서씩 돌면서 tf 계산 → “이 문서에서 각 단어가 몇 번 나왔나?”
for doc in tokenized_docs2:
tf = Counter(doc) # 해당 문서에서 각 단어가 몇 번 등장했는지 (TF)
doc_len = len(doc) # 문서 길이
vec = {} # 이 문서의 sparse vector (단어ID: 점수)
for term in tf:
idf = bm25.idf[term] # BM25가 계산한 단어 희귀도 (Inverse Document Frequency)
tf_val = tf[term] # 해당 단어의 빈도수
numerator = tf_val * (k1 + 1)
denominator = tf_val + k1 * (1 - b + b * doc_len / avgdl)
score = idf * (numerator / denominator)
vec[token_to_id[term]] = score
sparse_vectors2.append(vec)
print(f"🙌 Sparse Vector 개수: {len(sparse_vectors2)}\n")
print(f"✍ 첫 번째 문서 Sparse Vector: {sparse_vectors2[0]}\n")connections.connect(alias="default", host=MILVUS_HOST, port=MILVUS_PORT)
print("✅ Milvus 연결 성공\n")
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name="bm25_vector", dtype=DataType.SPARSE_FLOAT_VECTOR),
]
schema = CollectionSchema(fields, description="BM25 Sparse Vector Collection")
collection_name = "yuna_bm25_demo"
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
collection = Collection(name=collection_name, schema=schema)
data = [docs, sparse_vectors2] # text # BM25 sparse vector
collection.insert(data)
collection.flush()
print("✅ BM25 Sparse Vector Milvus 삽입 완료\n")아래 코드를 통해 벡터에 인덱스를 지정할 수 있다.
# ✅ 4. 인덱스 생성
# 4-1. text 필드 → INVERTED 인덱스
collection.create_index(field_name="text", index_params={"index_type": "INVERTED"})
print("✅ text 필드: INVERTED 인덱스 생성 완료")
# 4-2. bm25_vector 필드 → SPARSE_INVERTED_INDEX 인덱스
collection.create_index(
field_name="bm25_vector",
index_params={
"index_type": "SPARSE_INVERTED_INDEX",
"params": {"metric_type": "IP", "drop_ratio_build": 0.32}, # optional
},
)
print("✅ bm25_vector 필드: SPARSE_INVERTED_INDEX 인덱스 생성 완료")
# ✅ 5. 컬렉션 로드 (검색 가능 상태로 전환)
collection.load()
print("✅ 컬렉션 로드 완료 (검색 가능 상태)")