
마무리 정리를 해보자.
전체적으로 코드를 리뷰하며 알고 지나가야하는 것들, 개념이 확실하지 않았던 것들을 적어보자.
🎀 Vector Search
Q. 현재 코드의 벡터 검색 방식은 무엇일까?
A. 지금 app.py 기준으로 보면, Milvus를 이용해 벡터 유사도 검색(vector similarity search)을 하고 있다.
- n차원 벡터 = 요소(숫자) n개를 가진 리스트
- 차원 = 좌표값 개수
- 2차원 평면 → (x, y) → 좌표값 2개
- 3차원 공간 → (x, y, z) → 좌표값 3개
- 1536차원 공간 → (x₁, x₂, x₃, … x₁₅₃₆) → 좌표값 1536개
✅ 요약
✔ OpenAI 임베딩 모델 → 1536개의 float 숫자를 뱉음
✔ Milvus 같은 벡터 DB → 1536칸짜리 좌표계에 모든 문서 벡터를 저장하고 검색
✔ “질문 임베딩” = 사용자의 질문을 임베딩 모델로 보내서, 질문을 모델이 정한 n차원 벡터로 변환
✔ Milvus 같은 벡터DB는 그 벡터를 다른 벡터(문서 chunk)와 비교해서 “가장 가까운 문맥”을 찾아옴
✅ 무엇을 쓰고 있나?
results = client.search(
collection_name=collection_name,
data=[query_vec],
anns_field="dense_vector",
search_params=search_params,
limit=top_k,
output_fields=["text", "filenm"],
)client.search()→ MilvusClient의 검색 API- 검색 대상:
collection_name(Streamlit 사이드바에서 선택한 Milvus 컬렉션) - 검색 기준 필드:
anns_field="dense_vector"→ Milvus 컬렉션 안의dense_vector필드 (OpenAI 임베딩 벡터 저장)
- 유사도 측정 방식:
search_params안에 정의search_params = { "metric_type": "COSINE", "params": {"nprobe": 10}, }metric_type="COSINE"→ 코사인 유사도 (벡터 방향이 얼마나 비슷한지)nprobe=10→ IVF 계열 인덱스일 때 몇 개의 클러스터(bucket) 를 탐색할지
✅ 지금 벡터 검색 방식
- DB: Milvus (벡터 데이터베이스)
- 검색 함수:
client.search() - 검색 기준: 질문 벡터(query_vec)와 Milvus 컬렉션에 저장된 벡터의 코사인 유사도(COSINE)
- 결과: 유사도가 높은 순으로 top_k개의 문맥(chunk) 반환 → 그리고 그 chunk에 연결된 메타데이터(text, filenm) 같이 가져옴
📌 결론
👉 “OpenAI 임베딩 모델로 질문을 1536차원 벡터로 만들고 → Milvus의client.search()로 ‘코사인 유사도’ 기반 검색을 해서 → 가장 가까운 벡터(문맥)를 찾아오는 방식”
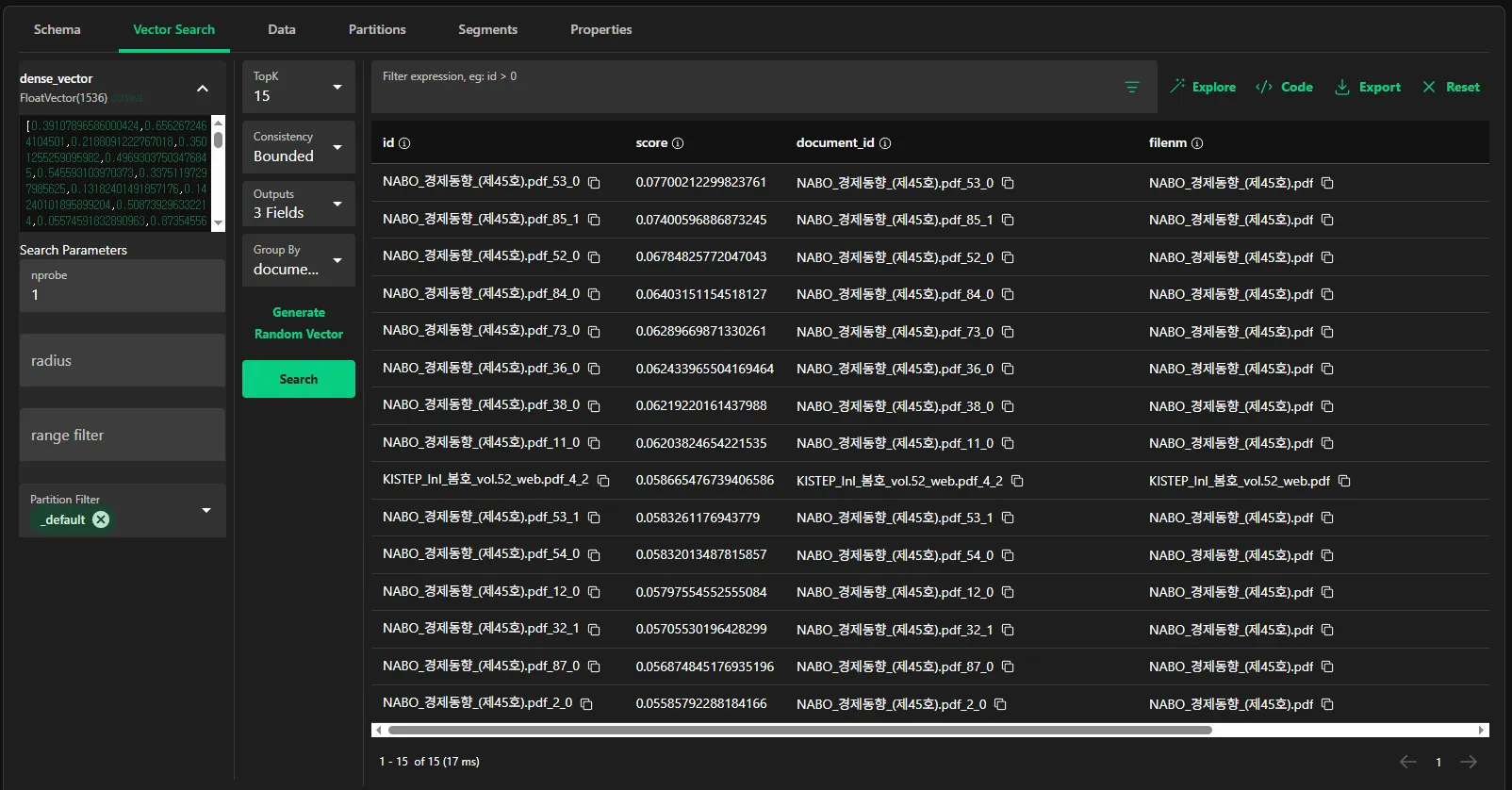
🎃 Milvus UI
밀버스 사이트에서도 벡터 검색을 수행해볼 수 있다.
Generate Random Vector로 임의의 벡터(=질문 임베딩 벡터)를 만들어 검색을 수행한 결과이다.
- 🤷♀️ 다만, 임의의 벡터가 어떤 텍스트를 임베딩한 것인지 모른다는 한계가 존재한다.
# python search code
res = client.search(
collection_name="~~~", # Collection name
data=query_vector, # Replace with your query vector
search_params={
"metric_type": "COSINE",
"params": {"nprobe":1}, # Search parameters
}, # Search parameters
limit=15, # Max. number of search results to return
output_fields=["document_id","filenm","text"], # Fields to return in the search results
consistency_level="Bounded"
)
🔍 왼쪽 패널
✅ 1. dense_vector (FloatVector(1536) cosine)
dense_vector: 검색 대상이 되는 벡터 필드 이름.FloatVector(1536): 이 필드의 타입과 차원 → 1536차원 float 벡터.cosine: 검색 시 사용할 거리 측정 방식 (metric type).- 현재 코사인 유사도로 설정됨 → 벡터 방향이 얼마나 비슷한지 비교.
| 특징 | 설명 |
|---|---|
| 값의 범위 | ~ (실제로는 0~1 범위에서 사용하는 경우 많음) |
| 값이 1에 가까울수록 | 두 벡터의 방향이 유사 (→ 내용이 비슷함) |
| 값이 0에 가까울수록 | 거의 무관한 관계 |
| 값이 -1에 가까울수록 | 정반대 방향 (거의 사용되지 않음) |
✅ 2. Search Parameters (검색 파라미터)
nprobe:- IVF 계열 인덱스(IVF_FLAT, IVF_SQ8, IVF_PQ)를 썼을 때, 검색 시 탐색할 클러스터(bucket)의 개수.
- 인덱스를 만들 때 데이터를
nlist개의 클러스터(bucket) 로 나눠둠.- 예: nlist=100 → 100개의 클러스터로 나눔.
- nprobe ↑ → 검색 품질↑, 속도↓
nprobe는 보통 nlist의 1~10% 수준 권장.
- 지금은 1로 설정됨 → 빠르지만 정확도가 아주 높진 않을 수 있음.
radius/range filter:- radius: 벡터 간 거리 기준으로 “이 거리 이내만” 가져오기.
- range filter: 거리 범위를 정해 검색할 때 사용.
- 현재는 비어있어서 적용 안 됨.
- Partition Filter (
_default):- Milvus 컬렉션을 파티션으로 나눠 관리할 때 특정 파티션만 검색할 수 있음.
- 지금은
_default파티션에서만 검색하도록 선택됨.
✅ 3. TopK
- TopK=15 → “질문 벡터와 가장 가까운 벡터 15개만 가져오기.”
✅ 4. Consistency → “검색할 때 데이터 최신성을 얼마나 보장할까?”
Milvus는 분산 시스템이라, 데이터를 여러 노드(Shard)에 나눠 저장
➡ 새로 데이터를 Insert / Upsert 한 후, 모든 노드에 반영되는 타이밍이 조금씩 다를 수 있음
🎈 Consistency Level 은 “검색할 때 얼마나 최신 데이터를 보장할까?” 를 정하는 옵션
Strong- 가장 강력한 일관성.
- 모든 노드가 최신 상태를 반영할 때까지 기다리고 검색.
- 데이터 반영은 확실하지만, 속도 느려질 수 있음.
Bounded(기본값)- 적당한 타협.
- 최근 Insert/Update가 대부분 반영되지만, 아주 최신 데이터는 누락될 수도 있음.
- 속도와 최신성의 균형.
Session- 현재 세션에서 Insert한 데이터는 바로 검색 가능.
- (세션이라는 “연결 단위” 안에서만 최신성 보장)
Eventually- 결국엔 다 반영됨 (eventually consistent).
- 속도는 가장 빠르지만 최신성은 제일 낮음.
👉 보통 개발/서비스에선 Bounded 를 가장 많이 사용.
✅ 5. Outputs → “검색 결과에 어떤 필드를 같이 보여줄까?”
Milvus 벡터DB는 벡터만 저장하지 않고, 메타데이터 필드도 같이 저장
예:
text→ 벡터가 대표하는 청크 내용filenm→ 파일명document_id→ 문서 ID
➡ Outputs = 검색 결과에 어떤 필드를 함께 돌려줄지 선택하는 옵션.
- 예:
- 3 Fields 선택 → (예:
id,document_id,filenm) - 검색하면 벡터 ID + 지정한 필드들 같이 반환.
- 3 Fields 선택 → (예:
➡ Streamlit 코드에서 output_fields=["text", "filenm"] 라고 하는 게 바로 이거랑 같은 개념.
✅ 6. Group by → “검색 결과를 특정 필드 기준으로 묶어서 볼까?”
Milvus Studio에서 제공하는 UI 기능으로, 검색 결과를 특정 필드 기준으로 묶어서 보기.
예:
Group by: document_id→ 검색 결과를 “같은 문서에서 나온 청크들끼리 묶어서” 보여줌.
- 만약 그룹화를 안 하면 → 유사도 순으로 그냥 나열.
- 그룹화를 하면 → 같은 문서 ID 기준으로 정리해서 보기 좋음.
👉 주의: Group By는 UI 기능일 뿐, 실제 Milvus search API 자체의 결과는 그대로 오고, UI가 “보여주는 방식”만 바꿔줌.
✅ 7. Generate Random Vector
- 테스트용으로 랜덤 벡터를 만들어 검색할 때 사용하는 버튼.
- 실제 서비스에서는 질문 임베딩 벡터를 넣어야 함.
✅ 8. Search 버튼
- 클릭하면 입력된 벡터(dense_vector)와 유사한 벡터를 검색.
🔍 중앙 패널
✅ Filter expression
eg: id > 0이런 식으로 조건 필터링을 할 수 있는 SQL-like 표현식.- 예:
"filenm like '%보고서%'"→ 파일명이 보고서인 데이터만 검색.
✅ 결과 테이블
- id: Milvus에서 자동 생성한 벡터의 고유 ID.
- score:
- 검색된 벡터와 쿼리 벡터의 “거리(or 유사도 점수)”
- COSINE일 때는 → 0에 가까울수록 유사.
- IP(Inner Product) 일 때는 → 1에 가까울수록 유사.
- document_id: 데이터 적재할 때 넣은 문서 식별자.
- filenm: 벡터가 속한 원본 파일 이름.
✅ 우리가 사용 중인 score는 무엇?
Milvus에서 metric_type="COSINE" 을 지정했을 때,
- score는 Cosine Similarity (코사인 유사도) 를 의미
- 💡 Milvus에서는 기본적으로 벡터를 정규화하고 양의 값만 다루므로 일반적으로 0~1 사이의 값을 사용.
- Cosine Distance = 1 − Cosine Similarity
| 항목 | 의미 | 값이 클수록? |
|---|---|---|
Cosine Similarity | 벡터의 유사도 (우리가 사용하는 score) | 👉 더 유사함 (좋음) |
Cosine Distance | 유사하지 않음의 정도 (1 - similarity) | 👉 덜 유사함 (나쁨) |
🔍 하단 바
1 - 15 of 15 (17 ms)- 1 - 15 of 15 → 전체 검색 결과 15개 중 1~15 표시 중.
- 17 ms → 검색 처리 시간 (17밀리초).
🎀 Chunk size & Chunk overlap
🔵 1️⃣ chunk_size & chunk_overlap 의 상관관계
📌 chunk_size (청크 크기)
- 한 청크(덩어리)에 포함되는 텍스트 길이 (보통 토큰 단위 또는 문자 단위).
- 예:
chunk_size=500→ 한 덩어리에 500토큰씩 잘라 저장.
📌 chunk_overlap (청크 겹침)
- 이전 청크와 겹치는 부분의 길이.
- 예:
chunk_overlap=100→ 이전 청크 끝에서 100토큰을 다음 청크 앞에 다시 넣어 겹침.
🔍 상관관계
- chunk_overlap 값이 chunk_size에 비해 클수록:
- 청크들이 더 많이 겹침 → 더 많은 중복 벡터 생성
- 벡터DB 용량 ↑, 검색 정확도 ↑ (컨텍스트 연결성이 좋아짐)
- chunk_size 값이 커질수록:
- 한 청크가 더 긴 문맥을 포괄 → 벡터 개수 ↓
- 하지만 한 벡터에 너무 많은 내용이 들어가면 검색 granularity(정밀도) ↓
🔢 예시 (page-based chunking 가정)
📄 텍스트 길이: 2000 토큰
-
Case A:
chunk_size=500,chunk_overlap=100- 쪼개기:
- 1번 청크: 1–500
- 2번 청크: 401–900
- 3번 청크: 801–1300
- 4번 청크: 1201–1700
- 5번 청크: 1601–2000
- ✅ 총 5개의 벡터 생성
- 쪼개기:
-
Case B:
chunk_size=1000,chunk_overlap=100- 쪼개기:
- 1번 청크: 1–1000
- 2번 청크: 901–1900
- 3번 청크: 1801–2000
- ✅ 총 3개의 벡터 생성
- 쪼개기:
📊 차이점 요약
- chunk_size ↑ (500 → 1000) → 청크 수 ↓ → 벡터 적게 생성
- chunk_overlap 일정(100) → overlap 비율이 달라짐
- Case A: 500 중 100 → 20% overlap
- Case B: 1000 중 100 → 10% overlap
➡ 즉, chunk_size가 커질수록 overlap의 상대적 영향력이 줄어듦.
🎀 Page-based & Document-based
🔵 2️⃣ Page-based vs Document-based Chunking
📄 Page-based
- PDF나 DOC 파일의 페이지 단위로 쪼갠 뒤 → chunk_size, chunk_overlap 적용.
- 장점: 페이지 구조 유지, 스캔된 문서에 적합.
- 단점: 페이지 단위라 내용이 짤리거나 중복될 가능성.
📄 Document-based
- 전체 문서를 한 덩어리로 보고, 연속된 텍스트를 chunk_size 단위로 쪼갬.
- 장점: 페이지 개념 무시하고 문맥을 길게 유지 가능.
- 단점: 페이지 정보(예: “5쪽 참고”)가 사라질 수 있음.
🔢 같은 chunk_size / overlap이라도 결과가 달라지는 이유
✅ Page-based (500, 100)
- 각 페이지마다 chunk_size 적용 → 페이지마다 overlap 구간 생성
- 페이지가 많을수록 벡터 수도 많아짐.
✅ Document-based (500, 100)
- 페이지 경계 없이 전체 문서 길이에 따라 쪼개짐
- 페이지 수가 많아도 “연속 텍스트”로만 나누므로 중복이 덜함.
➡ 즉, 같은 chunk_size라도 page-based가 더 많은 벡터 생성 (페이지마다 overlap이 추가되니까).
📊 정리
✅ (1) chunk_size & chunk_overlap 관계
- chunk_size ↑ → 벡터 수 ↓ (큰 덩어리로 저장)
- chunk_overlap ↑ → 벡터 수 ↑ (겹치는 부분이 많아 중복 증가)
✅ (2) Page-based vs Document-based
- Page-based: 페이지마다 청킹 → overlap 중복 ↑ → 벡터 더 많음
- Document-based: 전체 문서 단위로 청킹 → 중복 ↓ → 벡터 덜 생성
🚀 요약 한 줄
- “chunk_size를 늘리면 벡터는 줄고, overlap을 늘리면 벡터는 늘어난다.
- Page-based는 overlap 중복이 페이지마다 생기므로 Document-based보다 벡터를 더 많이 만든다.”
🎀 search limit & chunk count
현재 코드에서, milvus가 vector search를 수행할 때 지정해둔 search limit과, 사용자가 streamlit에서 슬라이드바로 조정하는 chunk 수와의 관계를 알아보자.
def search_milvus(
query_vec, collection_name, top_k=3 # top_k의 기본값(default value)이 3
):
search_params = {
"metric_type": "COSINE",
"params": {"nprobe": 10},
}
results = client.search(
collection_name=collection_name, # 검색 대상 컬렉션 이름
data=[query_vec], # 입력 쿼리 벡터 (리스트 형태로 전달)
anns_field="dense_vector", # 임베딩한 벡터가 저장된 필드명
search_params=search_params, # 추가 검색 파라미터 필요 시 사용
limit=top_k, # 검색할 유사 문서 개수, 몇 개의 유사 결과를 가져올지 지정
output_fields=["text", "filenm"], # 결과로 가져올 메타데이터 필드
)
# limit = “Milvus가 반환할 유사한 벡터(문서 chunk) 의 개수”
# Milvus 입장에서 “상위 몇 개를 줄까?” 를 정하는 값.
# 예: limit=5 → 질문 벡터와 가장 가까운 5개의 chunk 반환.
...
search_limit = st.sidebar.slider(
"🔍 Number of chunks to retrieve", min_value=1, max_value=10, value=3
)
# 사용자가 UI에서 직접 조절하는 값.
# 결국 이 값이 Milvus limit에 전달됨.
...
my_bar.progress(40, text="🔍 Milvus 검색 중...")
context_texts = search_milvus( # 리스트 안에 (텍스트, 파일명) 튜플이 들어있는 형태.
search_vector, selected_collection, top_k=search_limit
)
# 여기서 search_limit → top_k → Milvus limit 로 연결됨.✅ 정리하면
- Milvus limit: DB 차원에서 검색 결과를 몇 개 줄지 결정하는 “하드 파라미터”
- Streamlit 검색할 청크 수(search_limit): 사용자가 UI에서 몇 개를 가져올지 선택하는 값 → Milvus limit에 그대로 반영됨
🚀 결론
- 지금 코드에서는 둘이 같음: 사용자가 정한 “검색할 청크 수” = Milvus
limit값 - 차이점:
- Milvus
limit= DB가 몇 개를 “찾아서” 줄지 - Streamlit 설정값 = 사용자가 몇 개를 원한다고 “지정”하는 값 → Milvus limit로 전달됨.
- Milvus
🔎 다르게 쓸 수도 있음?
- 네. 지금은 두 값이 1:1 대응 되게 썼지만, 원한다면 다르게 활용할 수도 있어요.
예:
- Milvus
limit을 크게 (예: 20) 설정하고, - Streamlit에서 “검색할 청크 수”를 작게 (예: 5) 해서, → Milvus는 20개 찾아오지만, Streamlit UI에는 상위 5개만 보여주기 가능.
➡ 이렇게 하면 후처리(필터링, rerank) 가 가능해진다!
🎀 Query Rewriting
- Query Rewriting/Question Rewriting
: 사용자가 입력한 질문을 더 나은 검색 쿼리로 다듬어서 다시 작성하는 기능.
사용자 질문: “AI 기술?”
➡ 리라이팅: “AI(인공지능) 기술이란 무엇인가요?”
# 더 구체적이고 검색 친화적인 쿼리로 변환됨.try:
response = client_openai.chat.completions.create(
model=model,
messages=[
{
"role": "system",
"content": """You are an assistant that rewrites user questions into clearer,
more specific queries for a search engine or knowledge base.
Make the rewritten question precise and well-formed,
but do NOT change its meaning.""",
},
{
"role": "user",
"content": f"Rewrite this question for clarity: {question}",
},
],
)
rewritten_question = response.choices[0].message.content.strip()
# 디버깅용 출력
print(f"🔍 원본 질문: {question}\n")
print(f"🧨 리라이팅 결과 원본 질문: {response}\n")
print(f"🔄 리라이팅된 질문: {rewritten_question}\n")
return rewritten_question📣 sorted() 문제 정리
지난 시간에 작성한 문제점과 해결방안을 더 세세히 작성해두었다.
Streamlit은 UI 컴포넌트(selectbox,slider등)의 state(현재 선택 값) 를 “인덱스 기반”으로 기억
🔍 문제 상황
client.list_collections()→ Milvus 컬렉션 목록을 반환.- 리스트 순서가 매번 같지 않을 수도 있음 (DB 상태, 추가/삭제, 내부 정렬 방식 때문에).
➡ Streamlit이 index=2 라고 기억하고 있었는데, 리스트 순서가 바뀌면 index=2가 다른 컬렉션을 가리키게 됨.
👉 UI에서 “선택했던 컬렉션”이 바뀌어 보이는 현상 발생.
collections = sorted(client.list_collections())- 컬렉션 목록을 알파벳순으로 정렬 → 항상 같은 순서 보장.
- Streamlit이 기억하는 index → 같은 컬렉션을 계속 가리킴.
