
소프트웨어 개발을 하다 보면 이런 상황이 반복된다.
- “왜 Kafka 대신 RabbitMQ를 썼죠?”
- “왜 PostgreSQL을 선택했나요?”
- “이 API 구조는 누가 결정했어요?”
- “당시에는 왜 이렇게 설계했죠?”
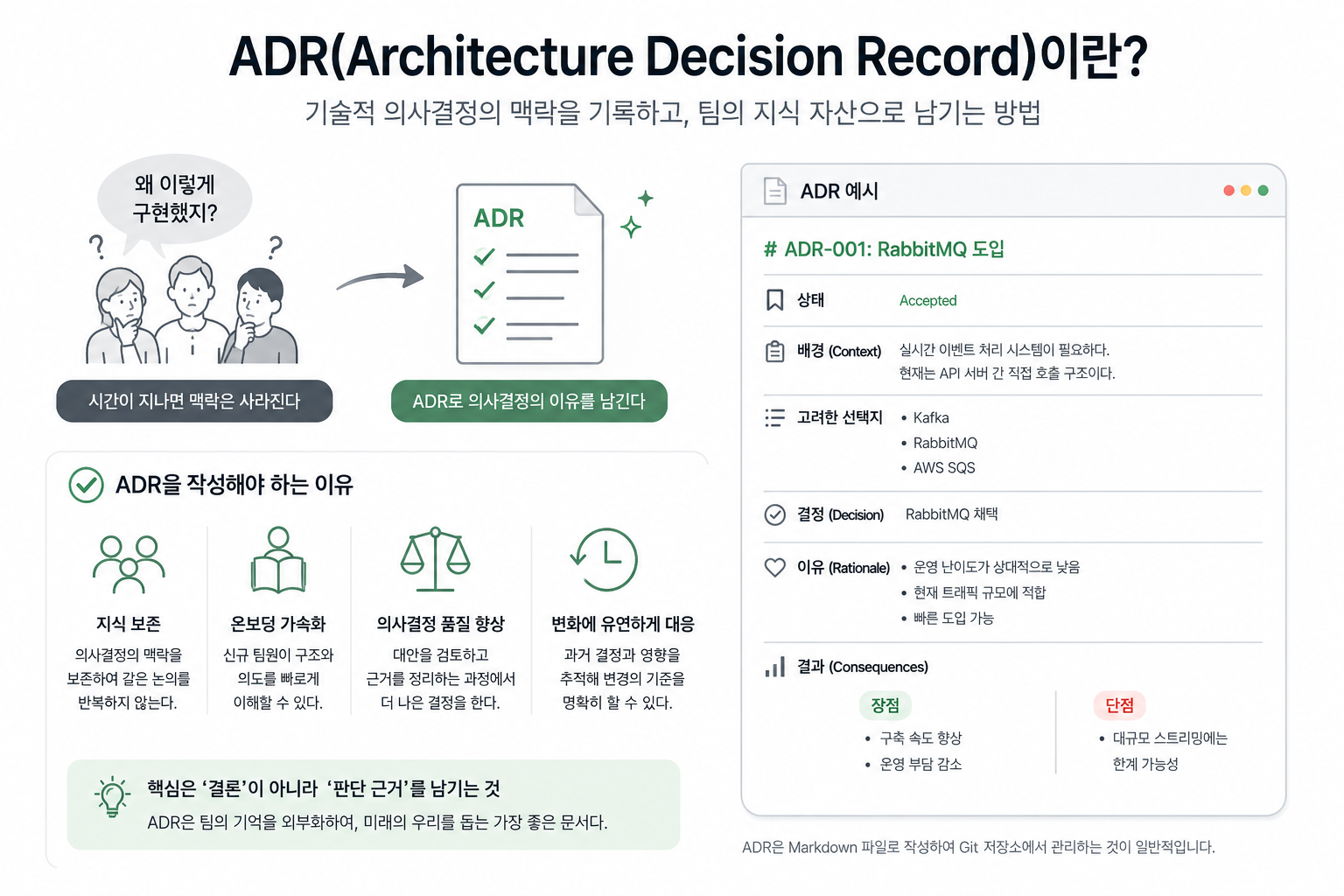
처음에는 모두 알고 있었던 내용이지만, 시간이 지나면 맥락(Context)은 사라지고 결과(Result)만 남는다.
그리고 결국 팀은 같은 논의를 반복하거나, 이미 검토했던 결정을 다시 뒤집게 된다.
이 문제를 해결하기 위해 사용하는 것이 바로 ADR(Architecture Decision Record) 이다.
ADR이란?
ADR은 특정 기술적 의사결정에 대해 아래 내용을 기록하는 문서다.
- 어떤 문제를 해결하려 했는가
- 어떤 선택지가 있었는가
- 왜 특정 선택을 했는가
- 어떤 트레이드오프가 있었는가
- 이후 어떤 영향을 미치는가
쉽게 말하면:
“왜 이런 결정을 했는지 남기는 기술 의사결정 로그”
라고 볼 수 있다.
👉 GitHub Engineering Blog에서도 ADR을 다음과 같은 관점으로 설명한다.
ADR은 단순 문서가 아니라, 미래의 팀원과 자신에게 남기는 의사결정의 맥락이다.
왜 ADR이 필요한가?
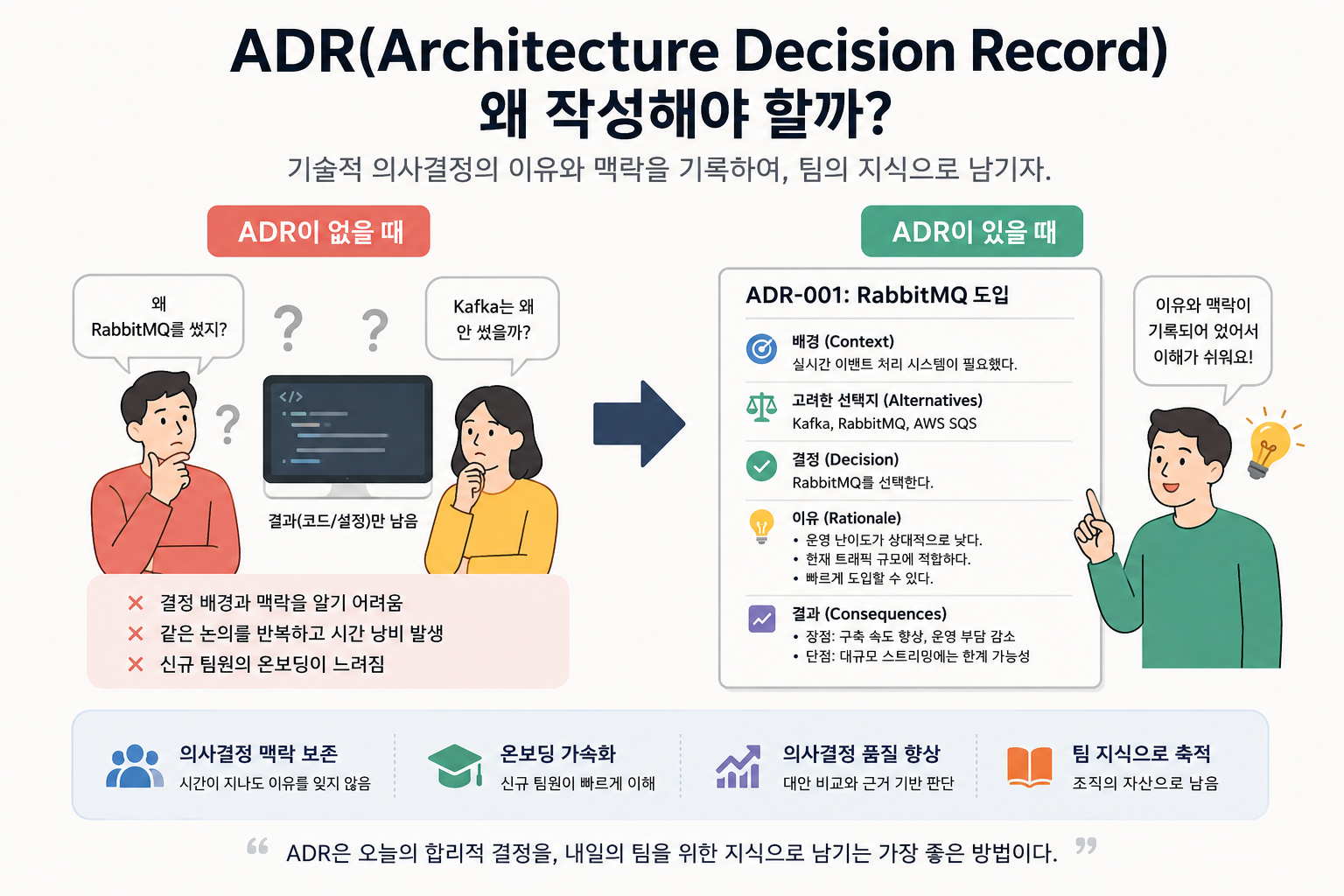
1. 결정의 “이유”는 시간이 지나면 사라진다
코드는 남는다.
하지만 “왜 그렇게 만들었는지”는 남지 않는다.
예를 들어:
queue_system: rabbitmq설정은 남아있다.
하지만 아래 정보는 대부분 사라진다.
- Kafka를 검토했는지
- 운영 난이도 차이는 어땠는지
- 트래픽 규모를 어떻게 예상했는지
- 당시 인프라 제약이 있었는지
결국 몇 달 뒤 누군가는 다시 같은 비교를 시작한다.
ADR은 이런 중복 비용을 줄인다.
2. 신규 팀원의 온보딩 속도가 빨라진다
신규 개발자가 가장 어려워하는 부분은:
“현재 구조를 이해하는 것”
이다.
특히 레거시 프로젝트에서는 코드만 보고 의도를 파악하기 어렵다.
ADR이 있으면:
- 왜 MSA를 선택했는지
- 왜 Redis 캐시를 도입했는지
- 왜 인증 구조를 OAuth2로 변경했는지
같은 맥락을 빠르게 이해할 수 있다.
즉:
- ✅ 코드 = “무엇을 만들었는가”
- ✅ ADR = “왜 그렇게 만들었는가”
를 설명한다.
3. 의사결정의 품질이 좋아진다
ADR을 작성하기 시작하면 자연스럽게 아래를 고민하게 된다.
- 대안은 무엇인가?
- 왜 이 선택이 더 적절한가?
- 장점만 있는 건 아닌가?
- 향후 비용은?
- 운영 리스크는?
즉, 문서화 자체가 사고를 정리하는 과정이 된다.
실제로 ADR 문화가 잘 잡힌 팀은:
- 감정적 결정 감소
- 근거 기반 논의 증가
- 기술 부채 추적 용이
- 아키텍처 일관성 향상
같은 효과가 나타난다.
ADR의 핵심 구조
ADR은 복잡할 필요 없다.
보통 아래 정도면 충분하다.
# ADR-001: RabbitMQ 도입
## 상태
Accepted
## 배경(Context)
실시간 이벤트 처리 시스템이 필요하다.
현재는 API 서버 간 직접 호출 구조이다.
## 고려한 선택지
- Kafka
- RabbitMQ
- AWS SQS
## 결정(Decision)
RabbitMQ 채택
## 이유
- 운영 난이도가 상대적으로 낮음
- 현재 트래픽 규모에 적합
- 빠른 도입 가능
## 결과(Consequences)
### 장점
- 구축 속도 향상
- 운영 부담 감소
### 단점
- 대규모 스트리밍에는 한계 가능성핵심은:
“결론”보다 “판단 근거”를 남기는 것
이다.
ADR 실습 예제
아래는 프로젝트에서 담당한 기능에 대해 작성한 ADR의 일부이다.
당시에 복잡하고 세세하게 기억하기 어려웠던 의사소통 과정을 문서로 정리하여 관리하니 한결 편안했다.
# ADR-001: Milvus 하이브리드 검색(dense + sparse)과 가중 rerank
## 상태
Accepted
## 컨텍스트
벡터 유사도만으로는 한국어 질의·키워드 매칭 품질이 불안정할 수 있고, 반대로 희소(BM25)만으로는 의미 확장이 부족할 수 있다. Milvus 2.x 계열에서 **dense ANN + sparse BM25**를 한 번에 조회하고 가중치로 합치는 API를 사용할 수 있다.
## 결정
- `hybrid_search`에서 `AnnSearchRequest` 두 개(dense: `dense_vector`, sparse: `sparse_vector`)를 구성하고, `FunctionType.RERANK`의 `weighted` 방식으로 `Config.HYBRID_WEIGHTS`를 적용한다.
- 명사가 있을 때는 dense/sparse 입력 문자열에 명사를 덧붙여 임베딩·희소 입력을 보강한다(`USE_NOUN_EXPANDED_EMBEDDING`, `USE_NOUN_BOOSTED_SPARSE`).
## 결과
- 장점: 의미 검색과 키워드 검색을 한 번의 Milvus 호출 경로로 결합할 수 있다.
- 단점: Milvus 스키마가 dense+sparse+ranker를 지원해야 하며, 임베딩·토큰화 품질에 따라 튜닝이 필요하다.
## 근거 코드
- `search_app/utils/milvus.py:16-77` (`hybrid_search`)
## 대안
- dense-only ANN + 서비스 측 재정렬만 사용 (인덱스 단순, 키워드 recall은 별도 처리 필요)
- 외부 검색엔진(Elasticsearch 등)으로 이전 (운영 스택 증가)
ADR은 언제 작성해야 할까?
모든 결정을 ADR로 남길 필요는 없다.
보통 아래 수준이면 작성 가치가 높다.
작성 권장 사례
- DB 변경
- 메시지 브로커 도입
- 인증 구조 변경
- 캐시 전략 변경
- MSA 전환
- 클라우드/인프라 구조 변경
- 벡터 DB 선정
- LLM Serving 구조 선정
- 모델 추론 아키텍처 변경
즉:
“나중에 왜 그랬는지 다시 물어볼 가능성이 높은 결정”
이면 ADR 대상이다.
ADR 작성 시 흔한 실수
❌ 1. 결과만 적는다
Kafka 사용 결정이건 ADR이 아니다.
중요한 건:
- 왜 Kafka였는가
- 어떤 문제를 해결했는가
- 다른 선택지는 왜 탈락했는가
이다.
❌ 2. 너무 길게 작성한다
ADR은 논문이 아니다.
길고 자세한 문서는 결국 읽히지 않는다.
보통:
- 1~2페이지
- Markdown 기반
- Git 저장소 관리
정도가 가장 현실적이다.
❌ 3. 업데이트하지 않는다
상황은 바뀐다.
예를 들어:
- 트래픽 증가
- 비용 문제
- 운영 장애
- 조직 구조 변화
등으로 인해 과거 결정이 더 이상 최선이 아닐 수 있다.
그래서 ADR은 “불변의 진리”가 아니라:
당시 기준의 합리적 의사결정 기록
으로 보는 것이 중요하다.
GitHub는 왜 ADR을 강조했을까?
GitHub Engineering Blog에서는 ADR의 핵심 가치를 다음처럼 설명한다.
“팀의 기억을 외부화한다”
사람은 퇴사한다.
기억은 사라진다.
회의 내용도 잊힌다.
하지만 ADR은 남는다.
특히 규모가 커질수록:
- 의사결정 추적성
- 기술 히스토리 관리
- 조직 지식 축적
의 가치가 매우 커진다.
즉 ADR은 단순 문서가 아니라:
“아키텍처의 Git Commit Message”
에 가깝다.
개인적으로 추천하는 ADR 운영 방식
실무에서는 아래 방식이 가장 관리하기 편하다.
디렉토리 구조
docs/adr/파일명 규칙
0001-use-rabbitmq.md
0002-adopt-fastapi.md
0003-vector-db-milvus.md번호를 붙이면 추적이 쉽다.
상태 관리
보통 아래 상태를 많이 쓴다.
| 상태 | 의미 |
|---|---|
| Proposed | 제안됨 |
| Accepted | 채택 |
| Deprecated | 폐기 예정 |
| Superseded | 대체됨 |
ADR은 특히 AI/데이터 시스템에서 더 중요하다
AI 시스템은 일반 서비스보다 변경 속도가 빠르다.
예:
- 임베딩 모델 교체
- Vector DB 변경
- RAG 구조 수정
- Reranker 추가
- GPU Serving 변경
- Batch → Streaming 전환
이런 결정들은 몇 달 뒤 다시 검토될 가능성이 매우 높다.
ADR이 없으면:
- 동일 실험 반복
- 의사결정 히스토리 유실
- 성능 비교 기준 소실
문제가 자주 발생한다.
특히 데이터 사이언스/ML 플랫폼 팀에서는 ADR 가치가 상당히 크다.
마무리
ADR은 거창한 아키텍처 문서가 아니다.
오히려:
- 짧고
- 실용적이며
- 미래의 팀원을 위한 기록
에 가깝다.
좋은 팀일수록:
- 결정을 많이 하는 팀이 아니라
- 결정을 “기억하는” 팀이다.
ADR은 그 기억을 남기는 가장 현실적인 방법 중 하나다.
참고 자료
- GitHub Engineering - Why write ADRs
- ADR GitHub Repository (joelparkerhenderson)
- Michael Nygard ADR Template
- ⭐ ADR은 “무엇을 만들었는가”가 아니라 “왜 그렇게 결정했는가”를 기록하는 문서다.
- ⭐ 시간이 지나며 사라지는 의사결정 맥락(Context)을 보존해 중복 논의를 줄이고 온보딩을 빠르게 만든다.
- ⭐ 특히 AI/데이터 시스템처럼 구조 변화가 잦은 프로젝트에서 ADR의 가치가 매우 크다.
