STL과 컨테이너
컨테이너
컨테이너란 데이터를 담는 자료 구조입니다. 자료 구조란 데이터를 어떻게 구조화할 것인지에 대한 개념이라면, 컨테이너는 특정 자료 구조를 코드로 구현한 것입니다.
컨테이너의 핵심 역할은 다음 세 가지 입니다.
- 데이터를 저장
- 데이터에 접근하고 탐색
- 데이터를 삽입, 삭제 등으로 조작
자료구조에 따른 구현 방식을 기준으로 순차 컨테이너와 연관 컨테이너로 나눌 수 있습니다.
순차 컨테이너 (Sequence Container)
순차 컨테이너란 데이터를 순서대로 저장하고, 인덱스 또는 순차 접근이 가능한 컨테이너입니다.
대표적으로는 배열(array), 벡터(vector), 리스트(list), 덱(deque)가 있습니다.
std::array (c++11부터 도입)
array는 정적 크기 배열로 컴파일 타임에 크기가 결정되어야 합니다. 연속된 메모리에 배치되며 런타임에서는 크기 변경이 불가능합니다. operator[]나 at()으로 Random Access가 가능합니다. []는 바운드 체크 없이 매우 빠르게 접근할 수 있고, at()은 범위 체크를 통해 안전한 접근이 가능합니다. 이러한 인덱스 기반 접근의 시간 복잡도는 O(1)입니다.
# include <array>
std::array<int, 5> arr1;
std::array<int, 3> arr2 = { 1, 2, 3 }; // aggregate initialization 가능std::vector
vector는 가변 크기 동적 배열로 런타임 중 크기를 동적으로 조절할 수 있는 배열 컨테이너입니다. 내부적으로 힙에 메모리를 동적 할당하여 데이터를 저장합니다. 새로운 원소를 삽입할 때 자동으로 크기를 늘리는데 일반적으로 2배 증가 정책을 따릅니다. array와 마찬가지로 operator[]와 at() 을 통한 접근을 지원합니다. 이 접근의 시간 복잡도 또한 O(1)입니다.
#include <vector>
std::vector<int> v1(5, 3); // 크기는 5, 초기값 3
std::vector<int> v2 = { 1, 2, 3, 4, 5 }; // initializer_liststd::list
list는 이중 연결 리스트 기반 컨테이너입니다. 런타임 시 크기를 자유롭게 늘리고 줄일 수 있습니다. 힙 영역에 각 노드를 하나씩 동적 할당하여 관리합니다. 각 노드는 다음 노드와 이전 노드의 포인터를 함께 보유하기 때문에, 앞/뒤로 양방향 탐색이 가능합니다. list는 연속된 메모리 공간에 배치되지 않으므로 인덱스 접근이 불가능한 대신 iterator 기반 접근이 가능합니다. 해당 위치의 iterator만 알고 있다면 삽입/삭제는 O(1)에 가능합니다. 각 노드마다 값과 두 개의 포인터를 저장해야 하므로 메모리 사용량이 비교적 큽니다.
- 추가로,
list는Random Access Iterator가 아니므로, sort, binary_search 등 사용할 수 없습니다.
std::deque (double - ended queue)
deque는 런타임에 크기를 동적으로 조절 가능한 컨테이너입니다. 앞과 뒤 양쪽에서 삽입/삭제 연산이 O(1)에 가까운 시간 복잡도로 가능합니다. 메모리는 연속된 하나의 덩어리가 아닌 여러 블록의 배열로 구성됩니다. 즉, deque에 대한 인덱스 접근은 포인터 역참조를 두 번 수행해야 합니다. Random Access를 지원하여 O(1)로 접근할 수 있습니다.
deque의 자세한 동작 방식에 대해 설명하겠습니다. 아래 블로그를 참고하여 이해한 대로 작성하였습니다.
https://medium.com/%40ssakib/how-does-std-deque-actually-work-part-1-482a3273d773
이를 위해 다음 세 가지 개념을 알아야 합니다.
start : deque의 반복자
- curr : 첫 번째 데이터 블록의 첫 번째 요소의 현재 위치
- first : 첫 번째 데이터 블록의 시작 위치
- last : 첫 번째 데이터 블록의 종료 위치
- node: 첫 번재 데이터 블록의 위치
finish : deque의 반복자
구조적으로는 start 와 동일하지만 deque의 마지막 블록 요소를 담당합니다.
- curr : 마지막 데이터 블록의 첫 번째 요소의 현재 위치
- first : 마지막 데이터 블록의 시작 위치
- last : 마지막 데이터 블록의 종료 위치
- node: 마지막 데이터 블록의 위치
data_map
- 덱의 각 데이터 블록들을 가리키는 포인터 배열입니다.
data_map[0] → [ , , ] (블록)
data_map[1] → [ , , ] (블록)
...제가 이해한 방식대로 설명하겠습니다.
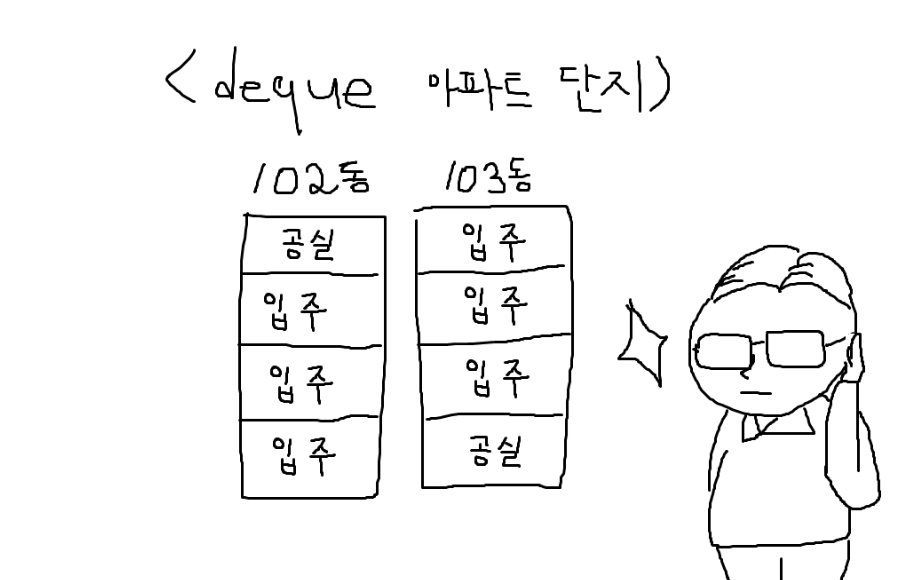
deque 아파트 단지의 관리인이 되었다고 가정하겠습니다. 이 관리인은 반드시 입주민들을 연속되게 배치하는 습관이 있습니다.
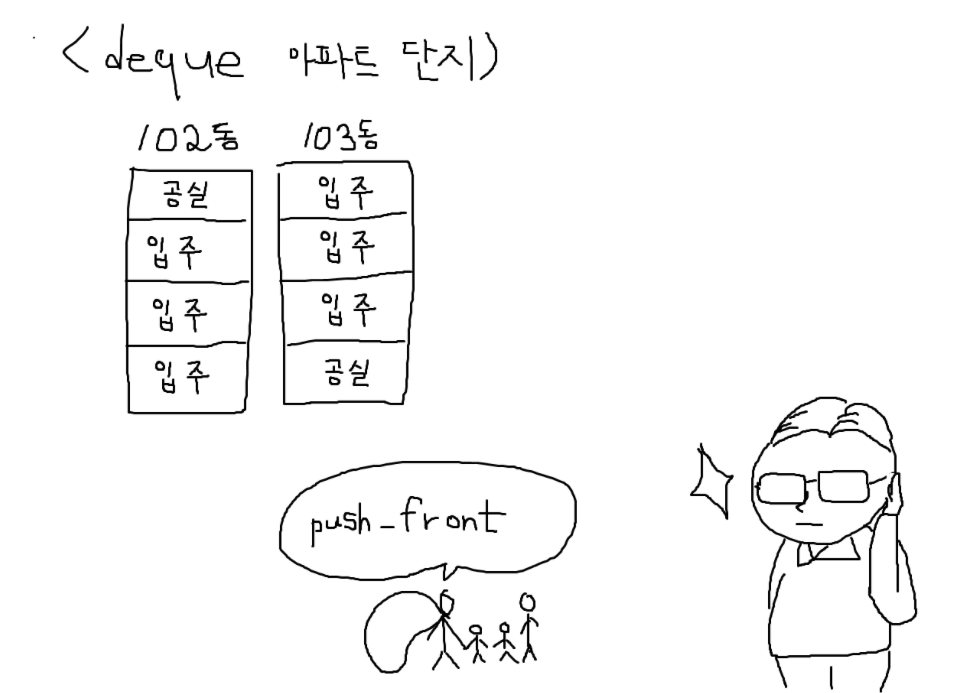 한 가정이 이 아파트를 찾아와
한 가정이 이 아파트를 찾아와 push_front()를 요청합니다.
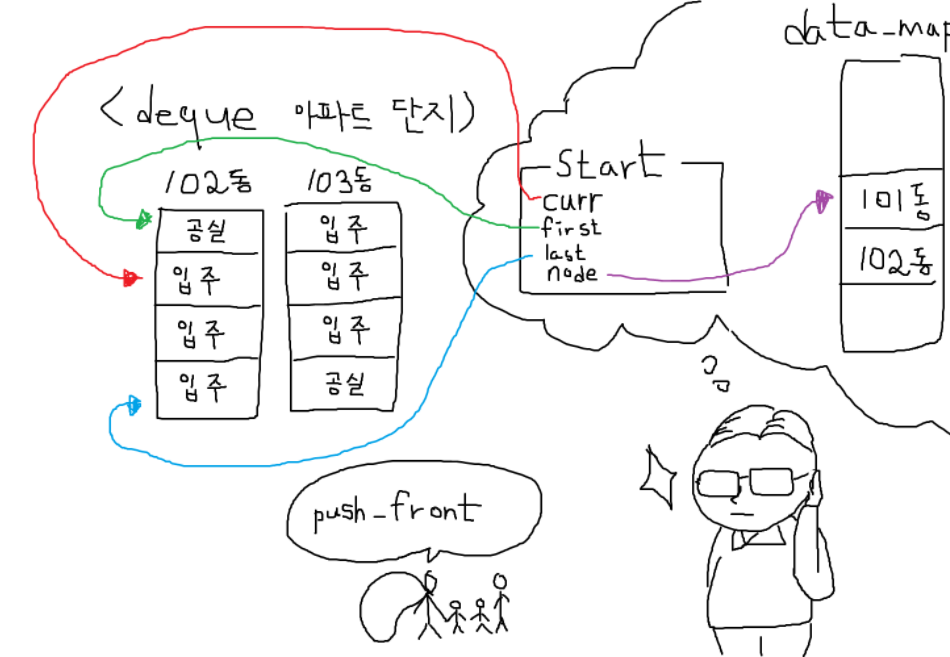
관리인은 머리를 굴리기 시작합니다. 위에서 설명한 start 반복자를 참고하여 현재 블록의 가장 앞 위치를 알아냅니다.
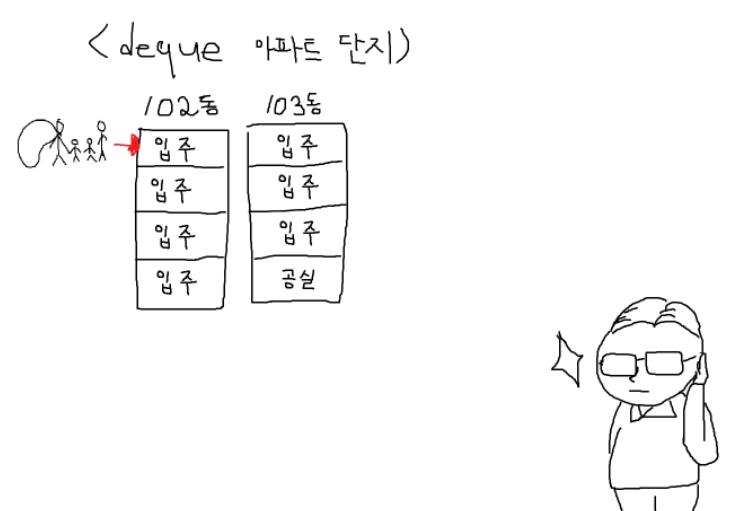
그리고 입주시킵니다. 이로써 102동은 꽉 찬 상태가 됐습니다.
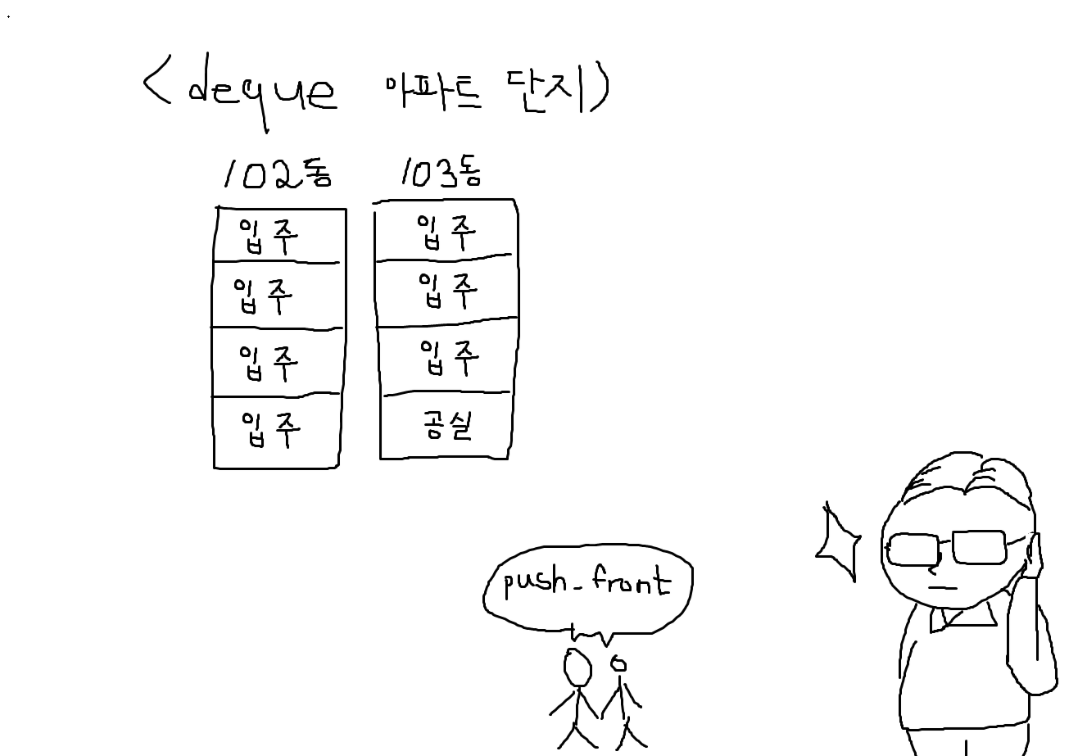
이번에는 신혼 부부가 찾아왔습니다. 하지만 102동이 가득 찬 상태네요.
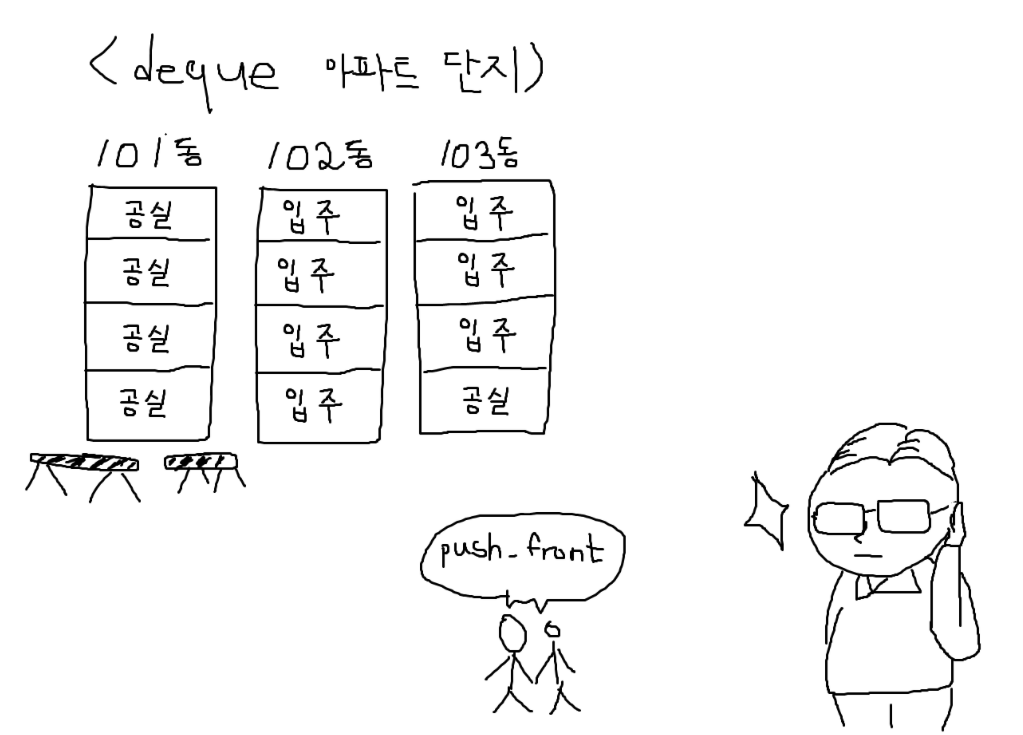
이럴 땐 101동을 빠르게 짓습니다.
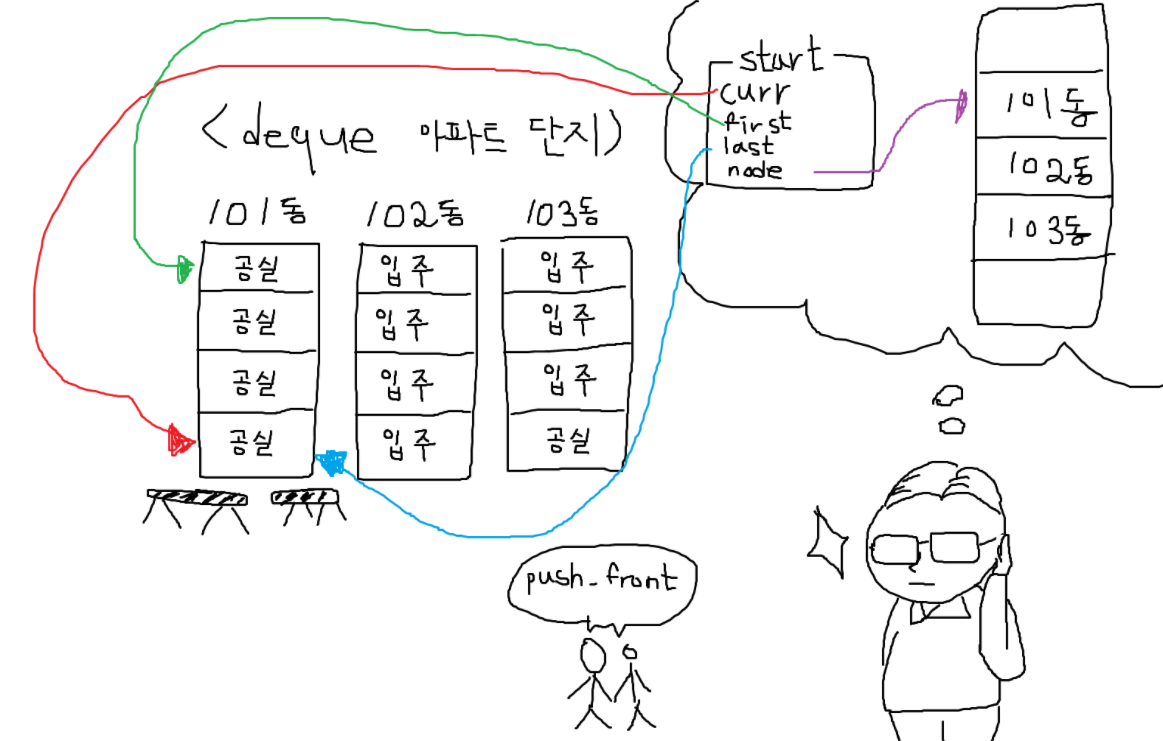
관리인은 또 다시 머리를 굴리고, 신혼부부를 입주할 집을 찾습니다.
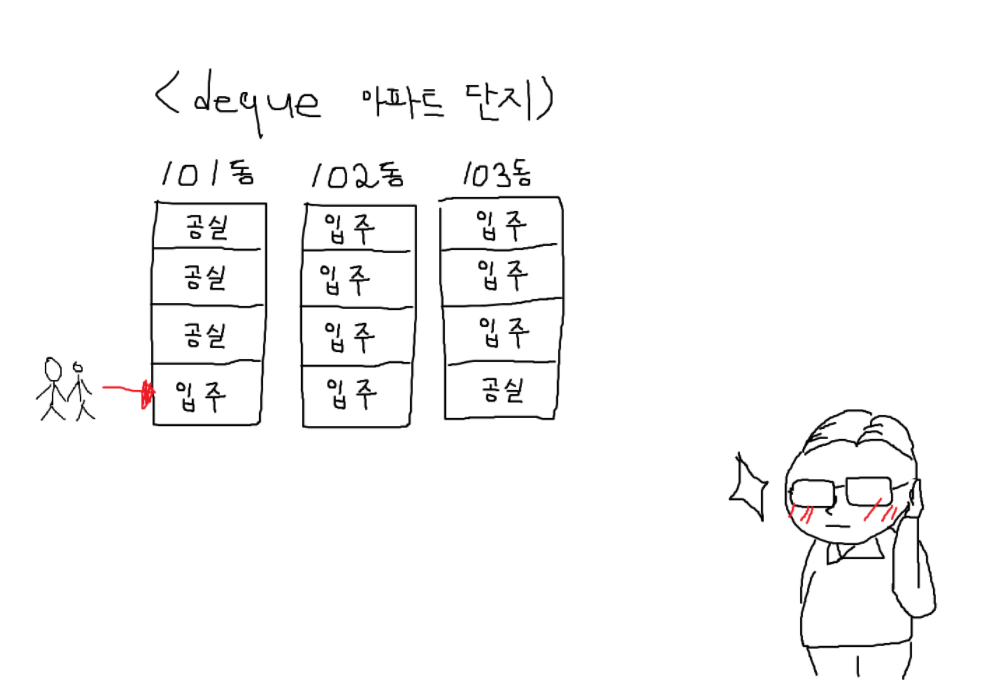
신혼부부의 입주도 끝이 났습니다.
이로써, deque는 데이터를 블록(청크)로 관리하고, 이 청크끼리는 연속된 상태라는 점, 또 이 동작을 위해 start, finish(그림엔 등장하지 않았지만), data_map 등이 쓰인다는 걸 이해하는 시간을 가졌습니다.
이상입니다. 다음 포스팅은 이어서 연관 컨테이너를 주제로 작성하겠습니다.

글에서 지즈님의 목소리가 느껴져요.