
사진 출처 https://medium.com/@zurister/depth-wise-convolution-and-depth-wise-separable-convolution-37346565d4ec
https://towardsdatascience.com/review-dilated-convolution-semantic-segmentation-9d5a5bd768f5
https://machinethink.net/blog/googles-mobile-net-architecture-on-iphone/
1. Dilated CNN
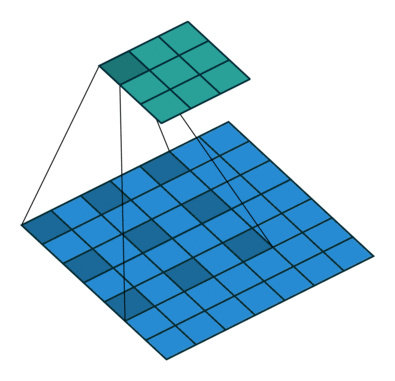
- Object를 판단할 때, contexteal information이 중요하다.
- Receptive field를 확장하는 방법을 다음과 같이 생각해 볼 수 있다.
- kernel ( filter ) size 확장
- layer stacking
하지만 두 방법 expensive, 특히 stacking의 경우 모서리 부분이 계산이 잘 안됨. 따라서 image와 filter의 합성곱시 전부 하지 않고 간격을 두고 뽑아 계산한다.
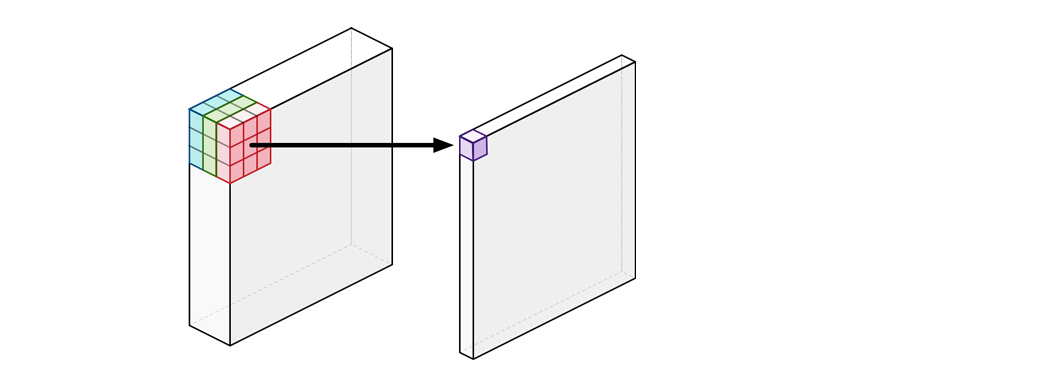
2. Point-wise CNN
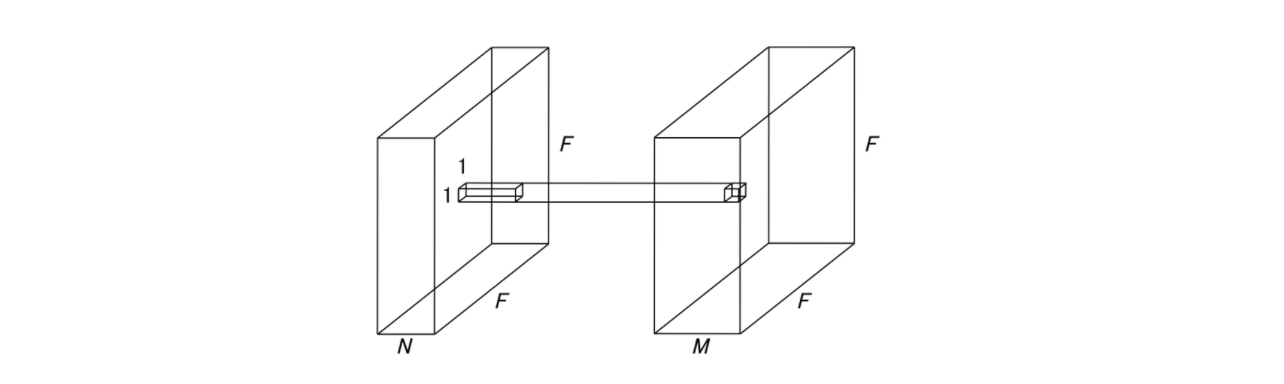
N : Input channel
M : Output channel이므로 filter의 개수와 같다.
- kernel ( filter )의 크기가 1×1이다. 따라서 input, output size가 같다.
- Channel을 압축하는 효과가 있다.
- Spatial feature는 추출되지 않는다.
- 위의 그림의 1×1 filter가 동일하게 모든 위치에서 작용한다. 즉 parameter가 총 N×M+M으로 적은편이다.
- filter는 어떤 channel에서 얼마나 뽑는것이 좋은지가 학습된다.
( 불필요한 channel이 제거되는 효과 ) - Form [ Batch × F × F × N ] [ Batch × F × F × M ]
3. Depth-wise CNN
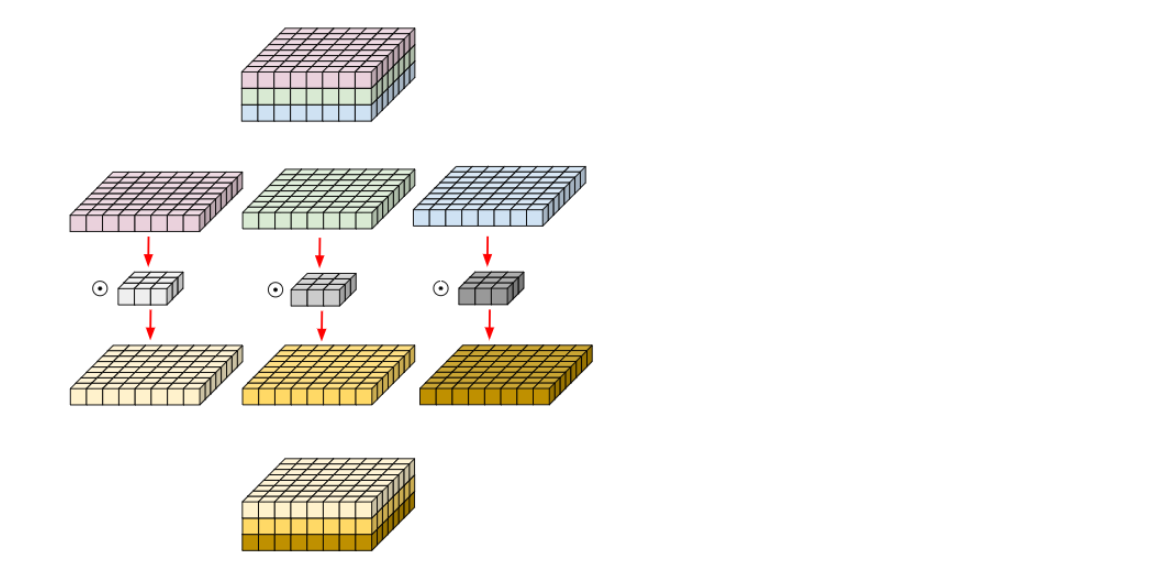
- 일반적인 CNN은 filter의 개수가 output의 개수가 된다.
즉, filter가 input channel만큼 있고 각 channel에 대해 합성곱을 한 뒤 더하여 한장이 되고 이를 filter개수 만큼 반복한다.
- 이렇게 하면 input channel별 feature가 아닌 통합 feature가 추출된다.
- 따라서 filter의 개수 FN와 input channel C를 맞춘다.
다음 input channel별 서로 다른 filter를 적용한다. - Form [ N × H × W × C ] [ N × FH × FW × FN ]
- Parameters = FN × FH × FW + FN
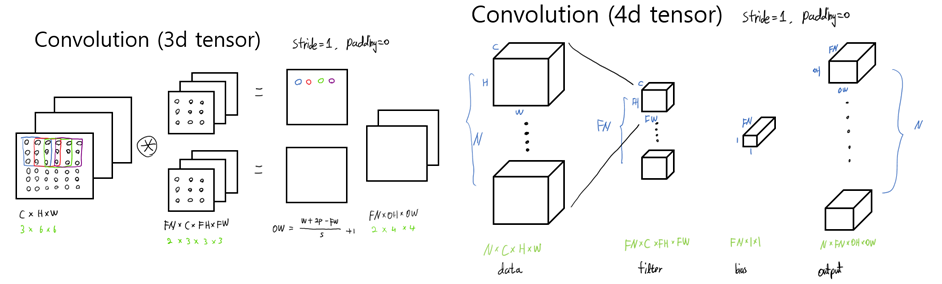
4. Depthwise separable CNN
- 바로 위의 concept을 합쳤다.
- 즉, 다음과 같이 image를 channel별로 Depth-wise 한 후 다시 point-wise를 거친다.
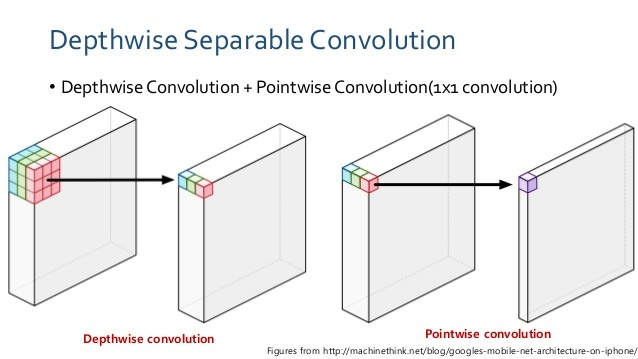
- Regular CNN's parameter : FN × C × FH × FW + N
- Depthwise separable CNN's parameter : ( FN × FH × FW + FN ) + ( N × M+M )
.png)