
1. Basic architecture
기본적인 구조는 다음과 같다.
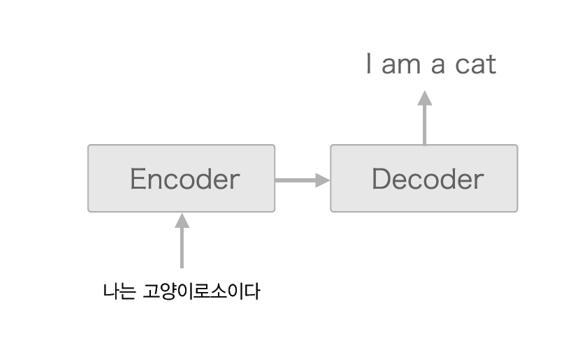
LSTM으로 예를 들어보자.
1. Encoder
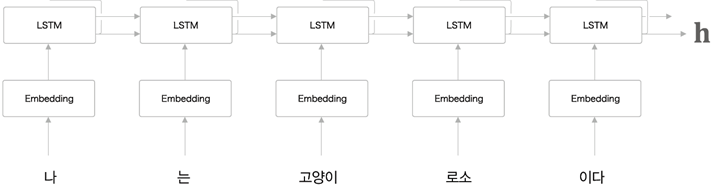
- Encoder는 입력 시계열 데이터로부터 각 time마다 hidden state와 cell state를 만들어 다음 time으로 전달한다.
- Encoder에서는 각각의 time에 대해서는 출력이 필요 없고 최종 출력은 마지막 time의 hidden state이다.
마지막 time의 hidden state에는 이전 time들의 input정보가 모두 담겨있다.
단, 이때 Encoder의 input size ( = time size )에 관계없이 항상 같은 길이로 encoding된다. - minibatch 학습시 문장의 길이는 padding을 이용해 맞춰준다.
2. Decoder
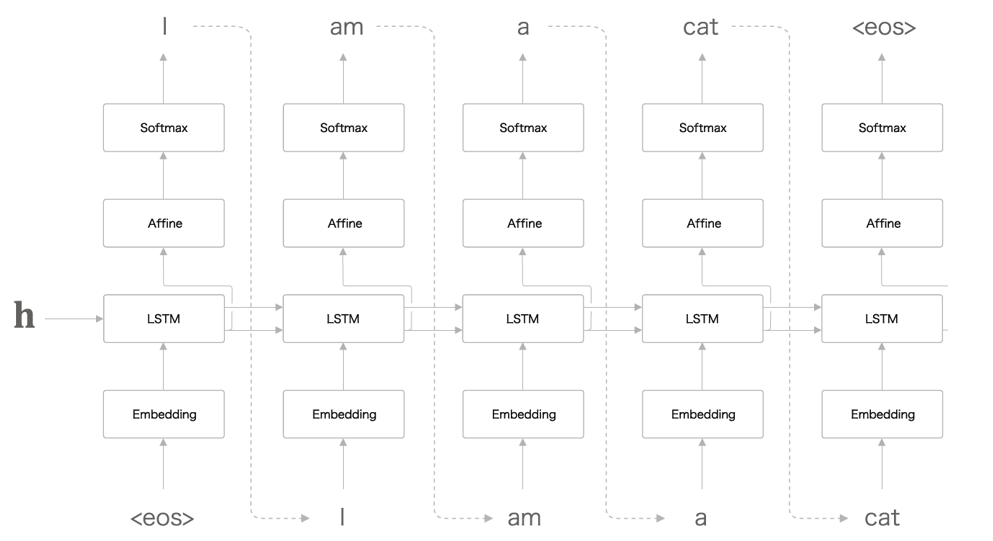
- Encoder의 출력을 첫번째 time의 LSTM에서 input hidden으로 받는다.
- 첫번째 time의 output은 다음 time의 input이 된다.
- Train과 Generate의 과정의 차이점을 주의하자.
Generate일때는 "I"가 나오면 그 다음 time으로 "I"를 집어넣는다.
Train일때는 "I"가 아니여도 "I"를 집어 넣는다.
즉, Trian일때는 output에 상관없이 Decoder의 input이 target처럼 작용하고 그래서 time별 학습 후 tensor로 묶을 수 있다.
반면 Generate일때는 time별로 순차적인 과정이 필요하다.
- 또한 Emdebbing의 matrix(projection)은 사전 학습된 모델의 것을 사용하면 빠르다.
2. Improvements
- Dropout같은 기본적으로 사용하는 개선법은 생략.
1. Reverse -> Bi-LSTM
https://arxiv.org/abs/1409.3215
'Sequence to Sequence Learningwith Neural Networks'
-
단순하게 data을 반전 시키는 것만으로도 학습 속도가 빨라지고 정확도도 높아진다.
이때 data의 반전은 input data에서만 일으킨다. -
이러한 사실을 이용하여 순방향과 역방향을 합쳐 양뱡향 LSTM.
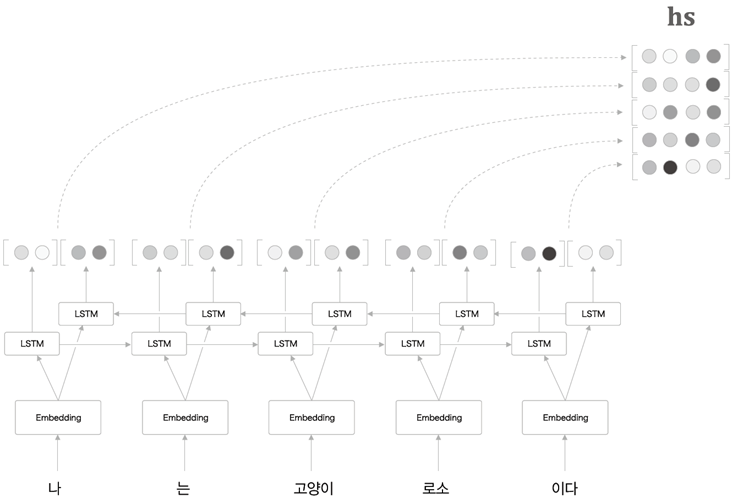
-
마지막에는 concatenate, sum, mean
-
이방법을 사용하려면 마지막 h가 아닌 다 모아놓은 tensor hs가 Decoder로 들어가야 한다.
2. Peeky
- 위의 Basic architecture에서는 Encoder에서 Decoder로 hidden state를 넘겨줄때, Encoder의 마지막 time의 hidden state가 Decoder의 첫번째 time의 input hidden state가 되었다.
- 우선 LSTM의 hidden state에 대해 자세하게 보자.
- form을 먼저 보면 다음과 같다.
- 이때 에서 마지막 인 만이 Decoder로 전달된다.
- 여기서 Encoder의 input 문장의 길이( padding을 고려한다면 정확한 표현은 아니지만 라고 이해해도 된다. )와 상관없이 즉, 일정한 size로 전달된다.
- form을 먼저 보면 다음과 같다.
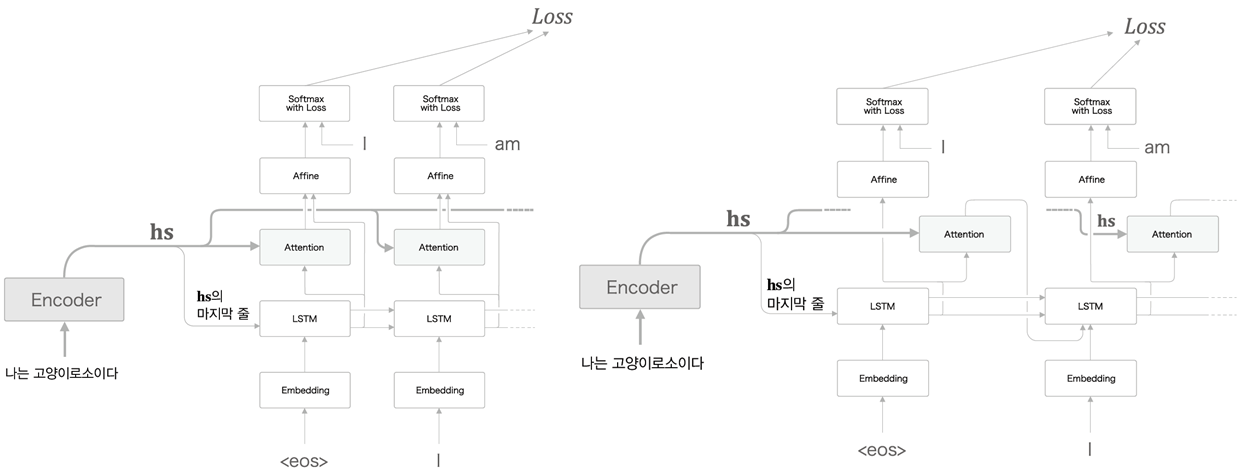
- 다음 그림은 Peeky에서는 를 Decoder의 처음에만 전달하는 것이 아니라 모든 time에 전달하는 것을 표현한 그래프이다.
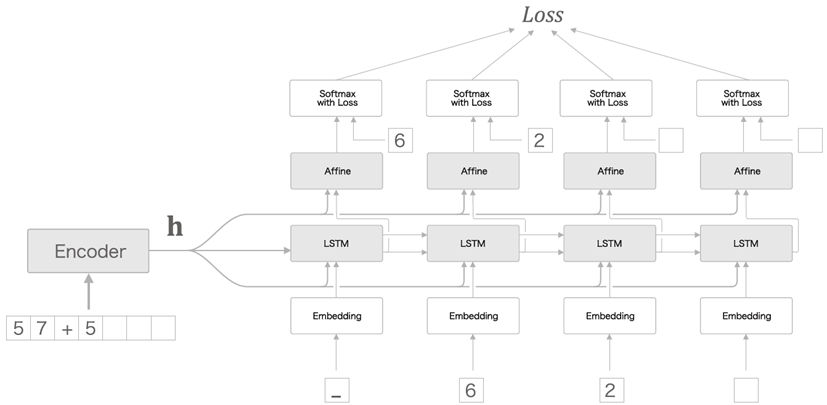
-
Peeky를 이용하면 basic seq2seq에서 Decoder부분만 바뀐다.
-
이 Encoder에서 나와 모든 time의 LSTM와 Affine layer에 들어간다.
-
LSTM : Embedding을 거쳐 나온 tensor 과 를 duplicate & reshape 을 거쳐 를 만든 후 concatenate하여 가 되어 LSTM으로 들어간다.
-
Caution !
Train 할 때는 Decoder의 input또한 target으로 주어진다.(위 그림의 6,2가 input에도 있다.) 따라서 Embedding을 거쳐 나온 tensor가 이다.
Generate 할 때는 Decoding의 input이 이전 time의 출력된 단어 이므로 time 여러개를 tensor로 묶어 계산 불가능 하다.- RNN, LSTM, GRU 등등 Time이 있는 layer들의 실제 계산(code)을 보면 Time별 계산 후 ( matrix계산 ) 다시 tensor로 묶어 주는 작업을 한다. ( 정확하게 표현하면 empty tensor를 만들고 time별 계산된 martix를 채워넣는 방식. )
-
-
Affine : LSTM에 들어간 와 LSTM에서 나온 를 cocatenate하여 가 Affine으로 들어간다.
- D : Embedding의 projection dimension
H : LSTM에서의 output dimension으로 Encoder와 Decoder의 H는 같다.
- D : Embedding의 projection dimension
-
3. 출력 확률 조정
- Train이 끝난 seq to seq 모델에서 단어를 생성하는 방법은 두가지가 있다.
- Greedy sampling - output score로 가장 높은 단어를 선택한다.
- Stocahstic sampling - output probability를 이용한다.
위 두 방법의 가장 큰 차이는 같은 문장을 넣었을때, 항상 같은 결과 Vs 확률에따른 결과 이다.
- Stocahstic sampling을 사용하고 temperature를 추가한다.
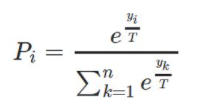
위와같이 기존의 Softmax function에 T : temperature를 추가한 것이다.
이렇게 하면 t가 작을 수록 큰 확률은 더 크게 작은 확률은 더 작게 즉, 결정적으로 나타나게 된다.
4. Attention
- seq to seq model의 문제점
-
여기서 Encoder의 input 문장의 길이와 상관없이 즉, 일정한 size로 전달된다.
-
만을 전달한다.
- 에는 첫번째 time부터의 정보가 모두 저장되기는 하지만, 해당 ( 마지막 ) time의 정보가 더 많이 남아있다.
- 문장을 생성할때를 생각해보면, 이것이 큰 문제는 되지 않을수 있지만, 번역일때는 문제가 된다.
- 예를들어 사람이 문장을 해석할때는 보통 Alignment개념을 이용한다. 즉, 단어와 단어를 match하여 번역을 한다. 따라서 Encoder에서 Decoder로 넘어올때 마지막의 정보가 조금 더 들어가있는 hidden state 가 아닌 모든 time에 대한 을 넘겨주면 성능 개선에 효과가 있을것이다.
(추가 적으로 위의 내용이 맞다면, 문장생성 Vs 번역 모델을 non-peeky와 peeky를 비교했을때 개선율에서 차이를 보일것이다.)
-
- 따라서 Attention을 사용하여 Encoder에서 대신 을 Decoder로 넘긴다.
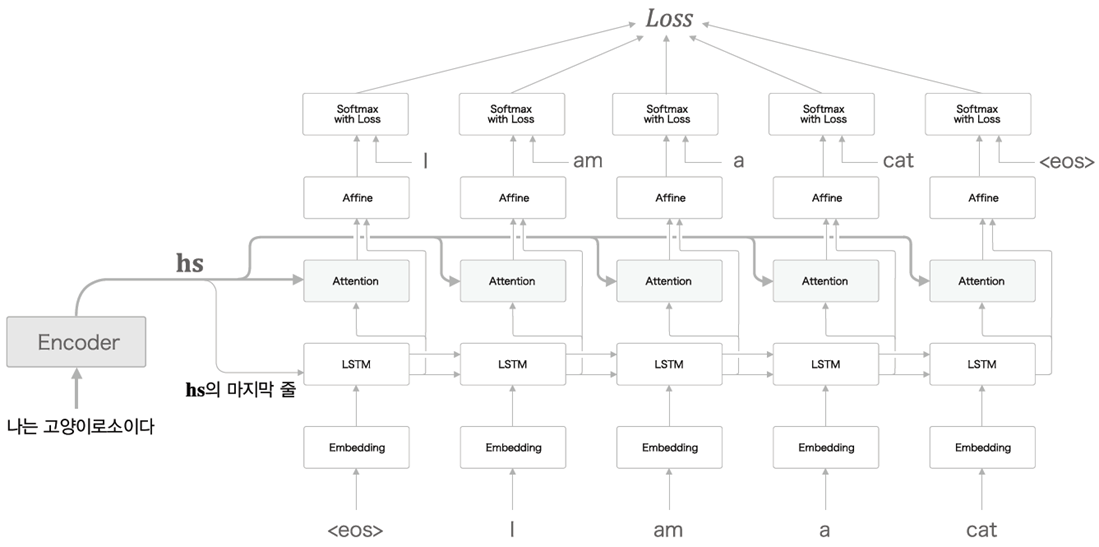
-
Peeky와 헷갈릴 수도 있는데 Peeky는 model을 그대로 두고 중간에 연산을 바꾸는 것이고 Attention은 그냥 새로운 layer인 Attention layer가(LSTM과 Affine 사이에) 추가 되는 것이다.
-
Attention Layer
- Encoder에서 ( Encoder의 모든 time에 대한 hidden state )가 출력되어
Decoder로 들어온다.
이때 Encoder의 마지막 hidden state 가 Decoder의 첫번째 LSTM으로 들어간다. (이는 Basic model과 같다.)
-
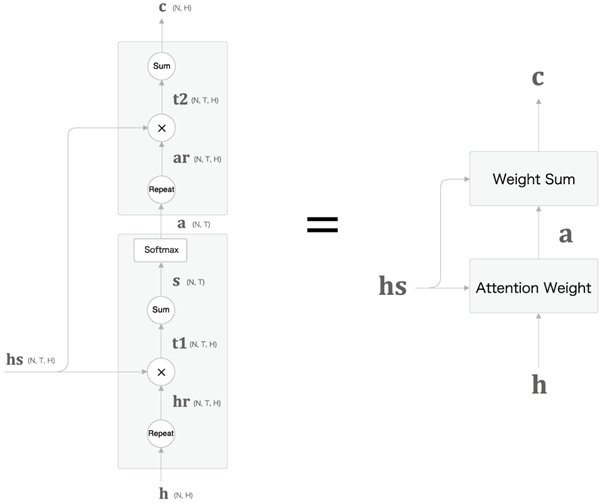
LSTM에서 나온 hidden state를 라고 하자.
-
를 repeat하여 로 만든다.
-
와 를 inner product -> sum -> softmax 하여 가중치 를 만든다.
이때 가중치 의 의미는 Encoder의 어떤 단어와 Decoder의 어떤 단어가 유사한지 (Alignment)를 나타내는 vector이다.
가 의 각 단어 vetor와 얼마나 비슷한가 즉, 유사도를 나타내기 위해 inner product. -
다음 가중치 를 repeat하여 한 후 와 ineer prouct -> sum 하면 맥락vetor
-
마지막으로 맥락vetor 과 LSTM에서 나온 hidden state를 를
concatenate 하여 Affine으로 들어간다.- 항상 그랬듯이 repeat는 code에서 생략해도 된다. ( broadcasting )
-
-
Attention은 layer이므로 다양한 위치에 들어갈 수 있다.
5. Skip-연결
-
Time 방향의 기울기 소실과 기울기 폭발에는 게이트와 Gradient Clipping으로 해결.
- Gradient Clipping
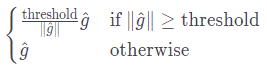
- Gradient Clipping
-
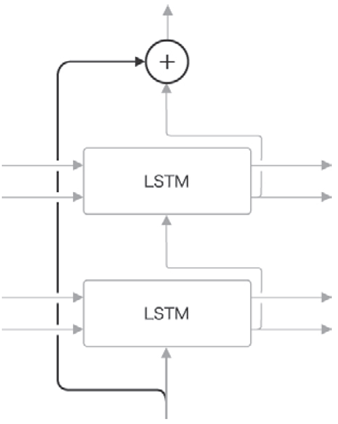
깊이 방향의 기울기 소실은 skip으로 해결.
Input을 output에 한번더 더해 주어 역전파시 기울기가 그대로 돌아온다.
( sum node는 기울기 그대로 )
5. 1D-Convolution
https://arxiv.org/abs/1408.5882
Convolutional Neural Networks for Sentence Classification
- Image에서의 2D-convolution과 유사하다.
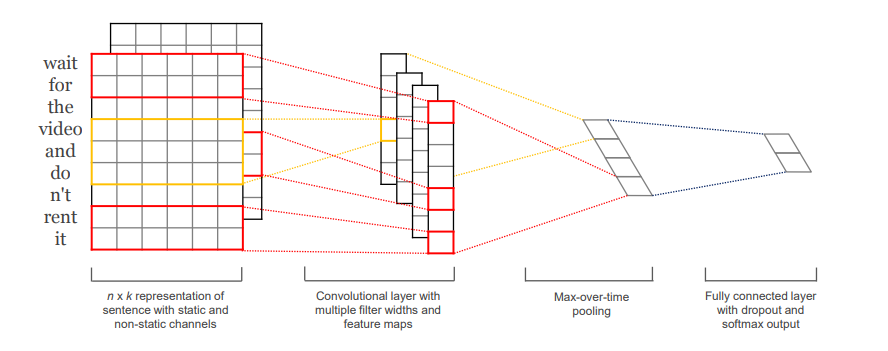
* 일반적인 언어모델의 Embedding이후의 설명하는 form이 다름 주의.
- Embedding을 거친 가 filter embedding과 같음와 convolution연산을 하여 가 된다.
.png)