논문의 핵심 아이디어만 정리함.
( Fully convolution Architecture 에 집중.)
예를들어 쌍선형 보간법을 사용했지만 결과가 좋지 않았다 그래서 제외함.
Abstract
-
본 논문의 가장 중요한 개념은
Fully convolutional이다.- 기존 VGG같은 ConvNet에서는 inputsize가 모든 input image에 동일해야 했는데 이유를 생각해보면 마지막의 Fully-connected layer때문이다.
Convolution layer는 filter가 학습된다. 이때 filter는 보통 3×3 이고 input channel과 같은 수의 filter가 input의 모든 channel과 연산을 하여 하나의 matrix가 되고 이를 output filter만큼 반복한다.
즉. convolution layer는 input size에 구애받지 않는다.
이후 마지막의 Dense layer이전에 flatten을 거친다. 이렇게 하여 spatial feature가 사라짐과 동시에 dense의 weight때문에 모든 input image의 size가 같아야 한다.
따라서 마지막의 FC를 FCN으로 바꾸어 input image가 arbitrary size로 들어와도 문제없이 학습하게 한다.
- 기존 VGG같은 ConvNet에서는 inputsize가 모든 input image에 동일해야 했는데 이유를 생각해보면 마지막의 Fully-connected layer때문이다.
-
기존의 classification에서 좋은 성능을 낸 모델들 즉, pre-trained weight를 가지고와 fine tuning하는 transfer 기법을 사용한다.
-
Skip architecture라는 구조를 사용한다.
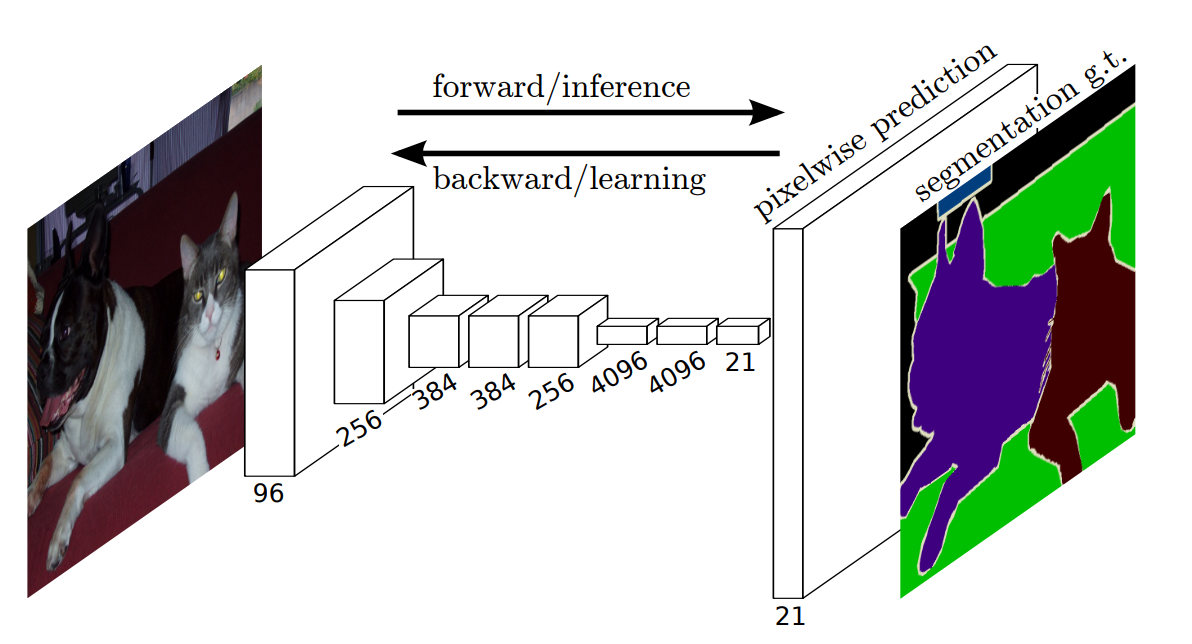
 https://www.researchgate.net/figure/Fully-convolutional-neural-network-architecture-FCN-8_fig1_327521314
https://www.researchgate.net/figure/Fully-convolutional-neural-network-architecture-FCN-8_fig1_327521314
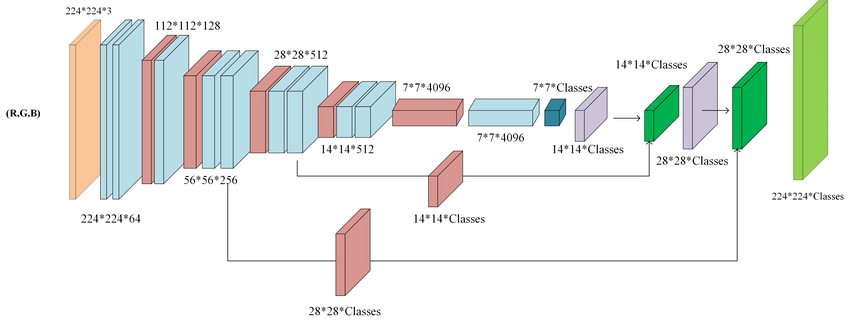
 https://mohamedameen93.github.io/Semantic-Segmentation-using-Fully-Convolutional-Networks/
https://mohamedameen93.github.io/Semantic-Segmentation-using-Fully-Convolutional-Networks/
Fully Convolution Architecture
Unsupervised Learning인 CNN Autoencoder에서 encoder와 decorder와 같다.
Downsampling
마지막의 Dense가 달라지는 것만 설명
-
간단하게 설명하자면 기존의 ConvNet과 같으며 마지막의 FC가 1×1 convolution으로 대체되어 FCN이 되는것이다.
1×1 convolution에서 channel의 개수는 class의 개수와 동일하게 맞춘다. -
기존의 classification network들은 마지막에 FC layer를 거친다.
이는 Dense의 weight matrix 때문에 input의 size가 fix되어야하고 , flatten 후 dense layer를 거치게 되면서 output이 spatial teature를 잃어버리게 된다. -
마지막에 FC layer가 있는 AlexNet같은 기존의 network들은 고정된 size의 image가 들어가 non-spatial output이 나온다.
하지만 fully convolutional network는 어떠한 size의 image가 들어가도 되고
( output의 size가 같다는 의미는 아님 ! 주의!! ) output에 spatial feature를 유지한다.
Upsampling
*본 논문에서는 unpooling을 사용하지 않았다. 아마 이후에 나온 개념인거 같다.
-
Deconvolution
Downsampling을 하게 되면 size가 준다. 따라서 이를 복구 시켜야 하므로 convolution과 반대로 연산해줘야 한다.
설명하기에 앞서 convolution을 다시 복습해보자.
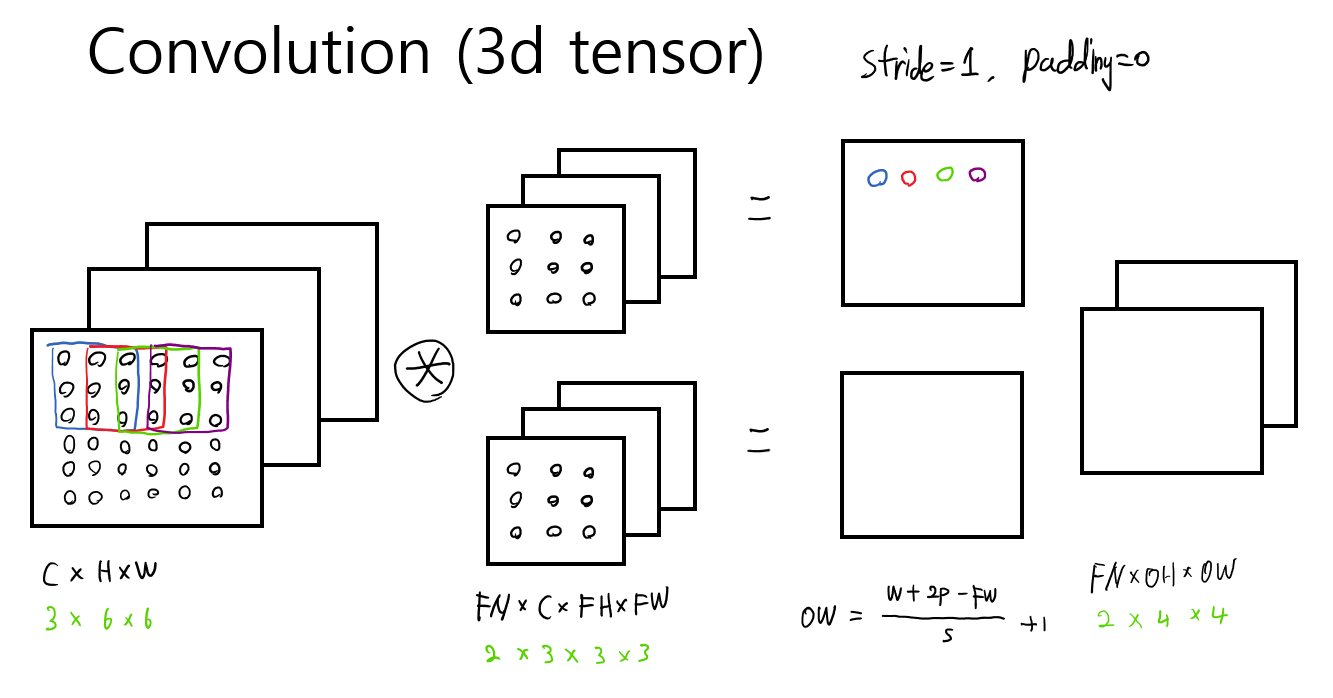
가장 쉽고 빠르게 이해하는 방법은 filter를 이해하는 것이다.
위와 같이 3개의 channel을 가진 input이 들어온다면 하나의 filter는 3개(FC)로 이루어져 있어야 하고 filter의 size에 맞춰channel별 hadamard product후 합친다. 이렇게 하면 한장의 output이 나오게 되고 이를 filter의 개수(FN)만큼 하면 된다.
Deconvolution은 아래와 같다.
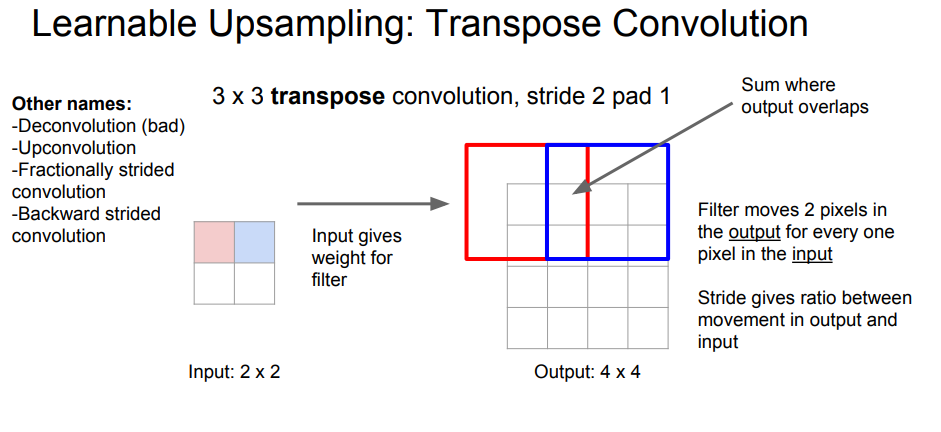 http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf
http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf
위와 같이 filter가 3×3라면 분홍색 부분과 filter를 곱하여 빨간색 bnd에 넣어주고 겹치는 부분은 더해주면 된다.
마찬가지로 filter로 input과 output의 channel을 조정한다.
stride가 커질수록 output이 커진다.- 추가적으로, 본 논문에서는 Deconvolution라고 하는데 cs231n.stanford강의에서는 오히려 deconvolution이 bad 단어라고 말한다. 이유는 de-라고 붙어서 이를 inverse라고 생각할 수 있기 때문이라고 한다.
실제로 이의 연산 과정을 보면 inverse의 개념은 전혀 아니고 굳이 설명하자면 convolution과 비슷한 연산이라고 하는것이 맞아 보인다.
또한 pytorch, keras에서도 Transposed convolution라는 단어를 사용한다.
- 추가적으로, 본 논문에서는 Deconvolution라고 하는데 cs231n.stanford강의에서는 오히려 deconvolution이 bad 단어라고 말한다. 이유는 de-라고 붙어서 이를 inverse라고 생각할 수 있기 때문이라고 한다.
Skip Connection
-
위의 구조로만 network를 설계하면 아래와 같이 결과가 아래와 같아진다.

왼쪽부터 skip connection이 없는 network이고 오른쪽으로 갈 수록 skip connection을 더한 network이다. 가장 오른쪽은 target이다.
오른쪽으로 갈 수록 더 깔끔한 segmentation이 되는 것을 볼 수 있는데 이를 본 논문에서는 upsampling하는 과정에서 skip connection을 추가하면 위치 정보가 다시 살아나기 힘들기 때문이라고 설명한다.
(ResNet에서의 identity mapping과 개념은 같지만 역할이 다르다.)
-
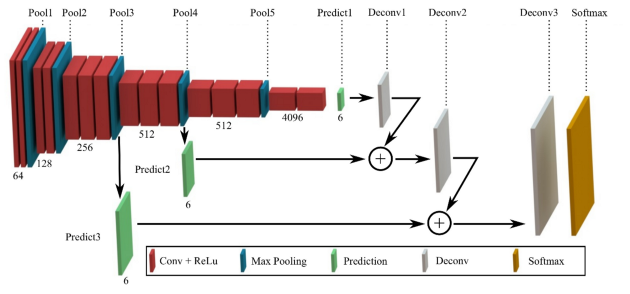
아래 그림은 network architecture를 나타낸 것이다.
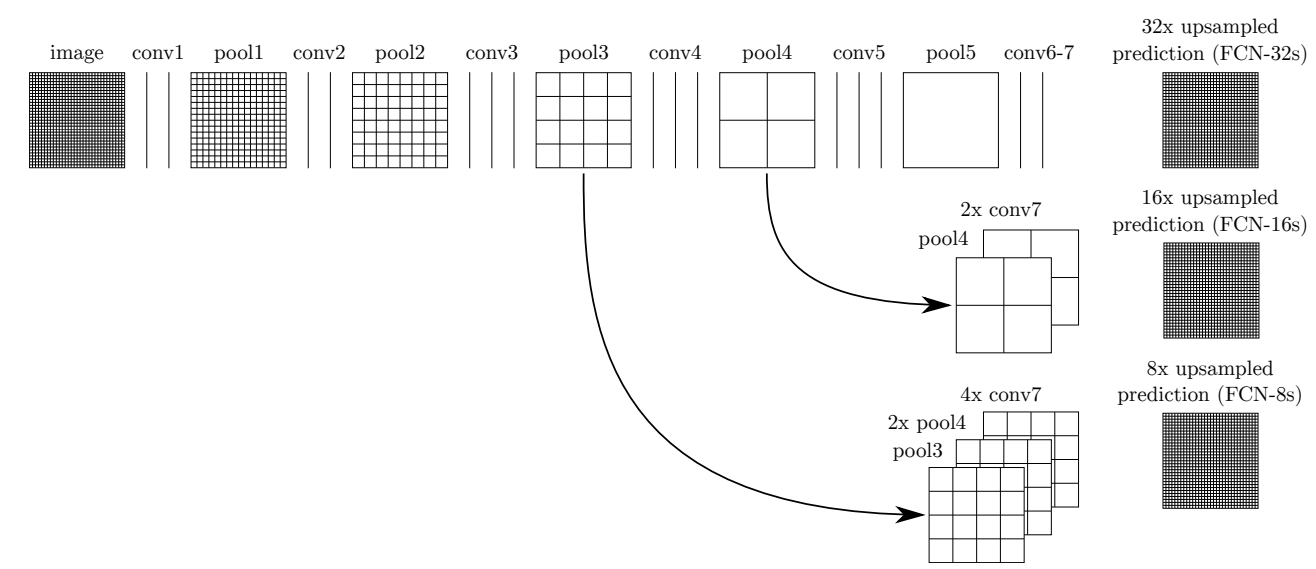
순서대로 FCN-32s , FCN-16s , FCN-8s이다.
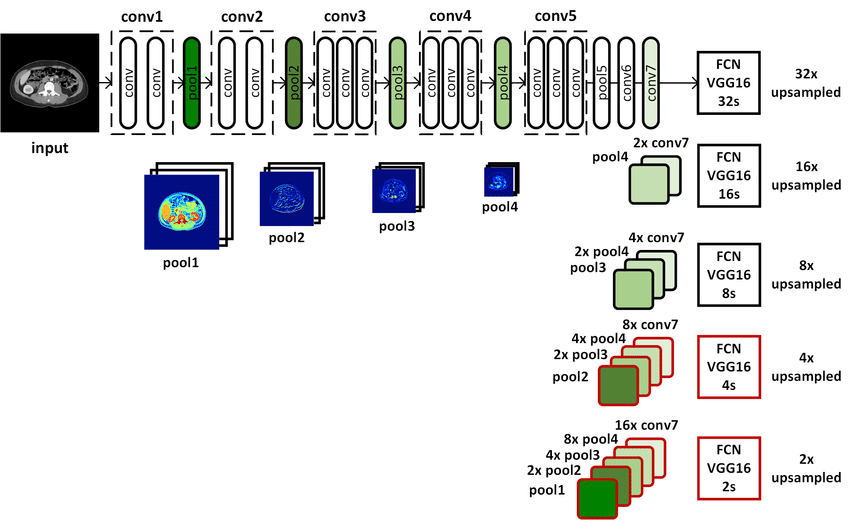
https://www.researchgate.net/figure/Overview-of-the-proposed-fully-convolutional-network-FCN-FCN-32s-FCN-16s-and-FCN-8s_fig1_317959445 -
우선 앞선 말했듯이 앞부분의 ( Encoder )구조는 VGG-16과 같은 모델을 사용하며 weight도 가지고 오고 필요하다면 fine tuning한다.
위 그림에는 생략되어 있는데 conv7이 FC의 역할을 대신하기 위하여 1×1 filter with classes-number output channel이다. 이후과정에서는 channel의 변화를 주지 않는다.
아래 network들의 이름을 보면 XXs라고 붙어있는데 이는 conv7을 거친 이후의 data를 XX배로 stride한다는 것이라고 이해하면된다.-
FCN-32s
conv7이후에 바로
ConvTranspose2d(n_class, n_class,64,stride=32, bias=False)하여 원래 size로 복원 -
FCN-16s
conv7이후에
ConvTranspose2d(n_class, n_class,4,stride=2, bias=False)하고
pool4 이후를 그대로 가지고 와 더한 후
ConvTranspose2d(n_class, n_class,32,stride=16, bias=False)하여 원래 size로 복원 -
FCN-8s는 conv7이후에
ConvTranspose2d(n_class, n_class,4,stride=2, bias=False)하고
pool4 이후를 그대로 가지고 와 더한 후
ConvTranspose2d(n_class, n_class,4,stride=2, bias=False)
pool3이후를 그대로 가지고 와 더한 후
ConvTranspose2d(n_class, n_class,16,stride=8, bias=False)하여 원래 size로 복원
(단 이때ConvTranspose2d(n_class, n_class,4,stride=2, bias=False)두개가 사용되었지만 모양만 같은 뿐 다른 weight )
-
https://github.com/wkentaro/pytorch-fcn/tree/master/torchfcn/models
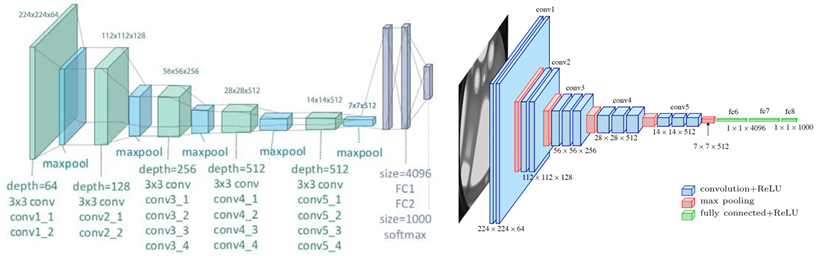
다음은 VGG 구조이다. ( 이건 그냥 헷갈려서 가지고 옴 )
두 그림 모두 같은 그림이다.
FC부분을 보면 보통 왼쪽그림을 많이 사용한다. 마지막 maxpooling 이후 펼쳐지는 부분이 flatten이고 이후 dense이므로 왼쪽과 같이 표현하는것이 conv와 구분되고 좋다.
오른쪽 그림은 마지막 dense를 90도 회전시켜 표한 한 것 뿐이다.
이건 FCN이 아니다.😡
말 그대로 모두 conv로 이루워져있어야 한다.!
.png)