Fully convolutional networks for semantic segmentation (2014)과 비교하기위해 원래 논문에 내용을 추가함. 이하 FCN이라 하자.
1. Introduction
Convolution을 사용한 전형적이고 쉬운 network는 Classification model이다.
하지만 이는 Dense layer의 연산으로 location에 대한 정보가 사라진다.
따라서 이를 해결하기 위해 FCN architecture를 사용하는 이는 첫째, output이 location 정보를 가지고 있고 둘째, input size가 달라도 되는 장점이 있다.
본 논문에서는 FCN 논문의 fully-convolutional network를 사용하고 이를 변형하여 training set이 작아도 잘 작동하고, 더 정확한 segmentation가 나오게 한다.
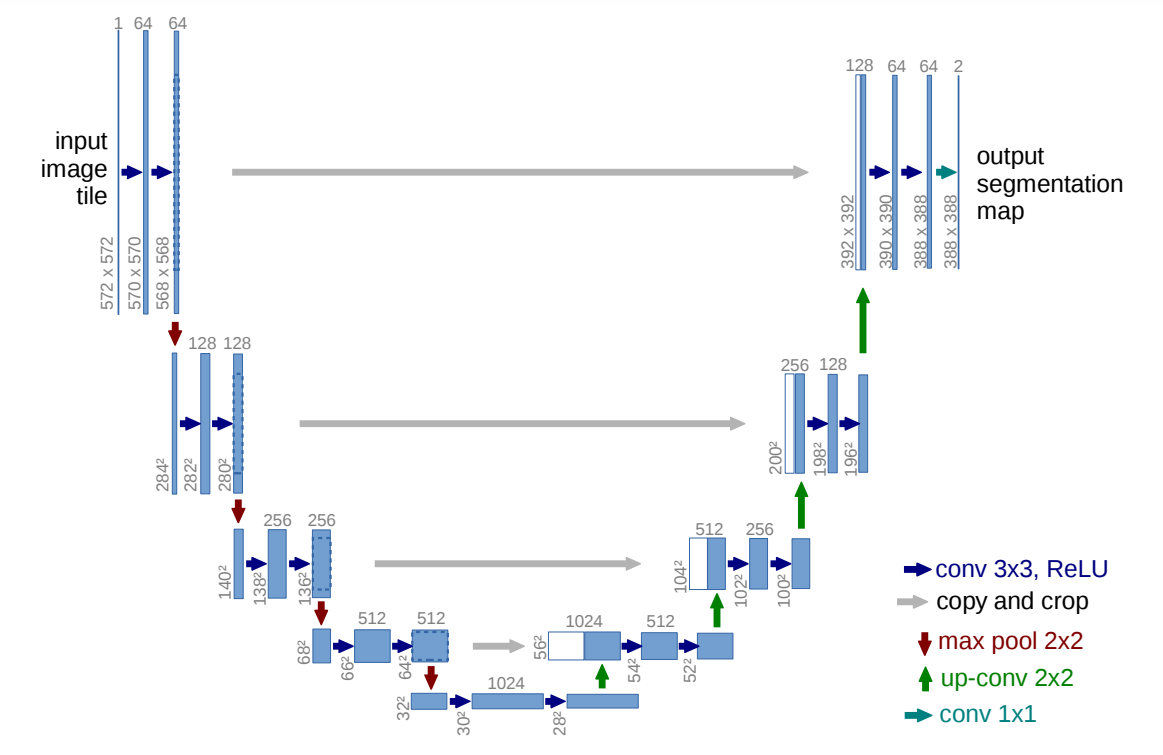
-
FCN의 구조를 생각해보면 32s, 16s, 8s...이렇게 있던 이유가 segmenation output을 더 정교하게 나오게 하기 위함이었다. 이때 skip-connection을 많이 사용할수록 output이 정교해졌다. 그래서 U-Net에서도 skip-connction을 사용한다.
-
둘간의 차이점이 있는데 FCN에서는 skip-connection으로 연결되면 두 tensor를 더하였고 U-Net에서는 channel방향으로 concatenation하여 channel을 늘려준다.
그리고 FCN은 skip-connection mapping에 size를 맞춰주기 위헤 convtrasnpose가 들어가는 반면 U-Net은 clean한 skip-connection이다. 이부분은 ResNet과 연관지어 몇가지 실험을 해볼 수 있을거 같다!
이때 bit-wise addition과 concatenation의 역할이 달라보인다???? -
본 논문에서는 왼쪽부분을 contracting path 오른쪽 부분을 expansive path라고 지칭한다. FCN의 expansive path을 보면 convtrasnpose만 존재하는데 U-Net에서는 conv도 있다.
-
overlap-tile전략을 사용한다.
위의 그림을 다시 보자. 숫자를 보면 뭔가 어색한점이 있다.
첫째 .
일반적인 VGG나 ResNet을 생각해보면 보통 convolution layer를 bottle neck architecture와 같은 방법으로 stacking하여 하나의 block을 만들고 이를 다시 반복하여 network를 구성한다. 이는 U-Net에서도 마찬가지이지만 VGG나 ResNet에서 중간에 size를 보면 그대로이거나 pooling을 사용하여 반감시킨다. 즉 위의 숫자처럼 -2이런것이 아니라 배수를 하게 된다.
둘째.
FCN구조를 보면input에 대한 target이 당연히 같은 size여야 하므로 input과 output의 size가 같다. 그런데 U-Net에서는 이또한 다르다.
셋째.
또 한가지 이상한 점은 skip-connection부분이 분명 아무것도 없는데 size가 다르다.
아래 사진을 보자.
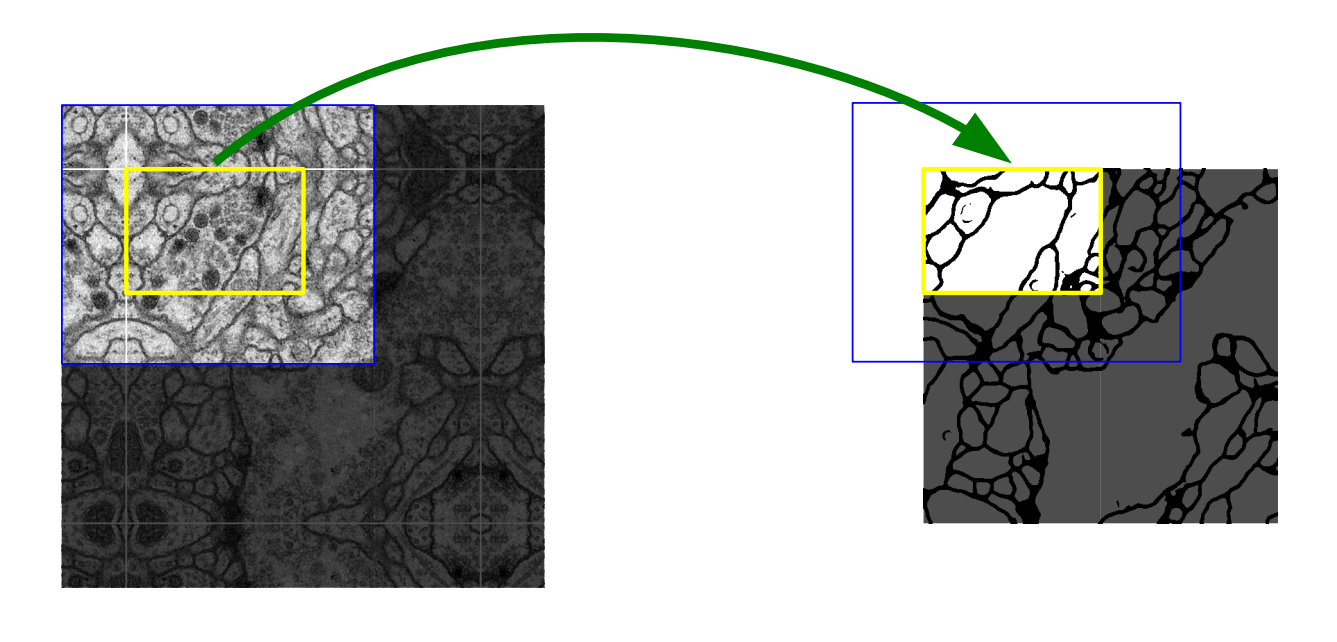
왼쪽이 input이고 오른쪽이 target이다.
원래 size는 오른쪽이 맞다. 위의 숫자를 빌리자면 원래 size는 388×388이고 input을 전처리
하여 572×572으로 늘린것이다. 이때 방법은 필요한 만큼 mirroring을 한다.
이렇게 하여 끝의 부분정보를 잘 가지고 온다. -> 뒤에서 자세하게 설명
2. Network Architecture
- contracting path
3x3 convolution (unpadded convolution)여기서 channel 두배
ReLU
3x3 convolution (unpadded convolution)
ReLU
2x2 max pooling stride 2여기서 size반감
????????????????????????????? 왜 나왔있는 code들은 padding이 있나????????????
총 4번 반복.
이때 보통 convolution에서는 zero padding을 사용하는 것과는 다르게 padding을 사용하지 않아서 conv를 지날때 size가 달라진다.
또 이렇게 하면 boundary의 정보가 잘 안잡히는데 이를 보완하기 위해 mirroring을 해주는 것이다. - 사이에
3x3 convolution (unpadded convolution)
ReLU
3x3 convolution (unpadded convolution)
ReLU - expansive path
2x2 up-convolution여기서 size두배
ReLU
3x3 convolution (unpadded convolution)여기서 channel 반감
ReLU
3x3 convolution (unpadded convolution)
ReLU
총 4번 반복
이후 마지막으로
1x1 convolution - skip-connection
crop을 해주고 다른것은 하지 않는다.
3. Training
optimizer로는 SGD를 사용한다. momentum=0.99
앞서 말했듯이 padding이 없으므로 input보다 output의 size가 더 작다.
loss function으로는 pixel wise soft-max cross entropy loss function를 사용한다.
우선 예측값은 다음과 같다 그냥 activation이후 softmax이다.
이때 는 channel의 위치가 인 pixel의 값이다.
는 channel즉 class의 개수이다.
따라서 위 식은 마지막 축력 tensor에서 같은 위치의 pixel별로 모든 channel에 대한 확률을 구한다.
즉, 는 번째 channel의 위치 pixel의 output이다.
다음은 위에서 구한 output과 target의 loss function이다.
=
기본적인 CEE식과는 살짝 달라보이는데 (기본적인 CEE는 이런모양)같은모양임.
위 식의 은 인 함수이다. 이때 1 ~ K는 true label.
즉 는 target이 1일때만 계산하겠다는 의미이다.
다음 는 seperation boader를 더 잘 구분하게 하기 위함이다.
.png)