https://www.youtube.com/watch?v=nDPWywWRIRo&t=2974s
-
처음 공부했던 Convolution을 이용한 network들을 보면 마지막에 flatten하여 Dense로 들어가 softmax를 거쳐 input image가 어떤 object를 찍은 것인지에 대한 probability가 output으로 나왔다.
이를 Classification 문제라고 한다. -
위 network는 치명적인 결함이 있다.
Convolution은 filter가 돌아다니면서 input에 대한 feature map을 작성한다.(해당 filter에 잘 반응하는 결과는 크게) 또한 trained weight를 visualization 해보면 image의 어떤 부분 때문에 특정 label이 나오는지에 대해서도 어느정도 알 수 있다.
즉, Convolution은 위치적 특성을 가지고 있지만 flatten 하여 Dense층을 거치면서 이러한 spatial information을 잃게 된다. -
CNN을 활용하여 Localization, Detection, Segmentation 을 할 수 있다.
이때는 특정 label이 input image에서 어디에 있는지 찾아야 한다, 즉, locational information이 끝까지 살아 있어야 한다. -
Localization은 classification에 lacation을 찾는 것이고 detection은 여러개의 object와 bnd를 찾는 것이다.
- Localization
output = ( x,y,w,h )- Image가 들어오면 기존의 classification model을 학습시킨다.
다음 bnd를 결과물로 하는 regression head를 추가한다.
regression head만 학습시킨다.
- Image가 들어오면 기존의 classification model을 학습시킨다.
Segmentation

https://divamgupta.com/image-segmentation/2019/06/06/deep-learning-semantic-segmentation-keras.html
Object가 어디에 있는지 정확히 알아내고 싶다.
Classification은 whole image information을 이용하여 하나의 label이 나오는 것 이라면, Segmentation은 각각의 pixel에 대한 classification인 것이다. 즉, pixel-level의 labelling이다.
따라서 image에 무엇이 있으며 또한 어디에 있는지를 찾아낸다.
VAE, GAN
- Autoencoder
이는 segemtation은 아니지만 비슷한 구조이다.
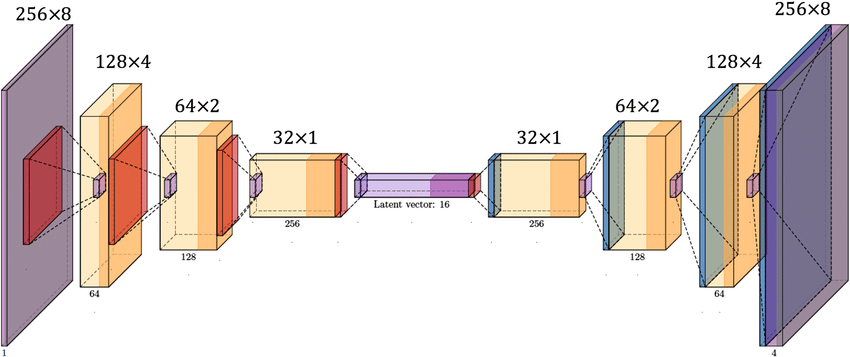
https://www.researchgate.net/figure/Autoencoder-CNN-structure_fig2_341802517
classification는 target label은 사람이 만든 supervised learning이다.
Autoencoder는 target과 input이 같은 unsupervised learning이다.
이때 중간에 차원을 감소 시키면 가운데가 feature extraction의 역할을 한다. 즉, data를 더 작은 차원으로 표현 하는데 어떤 부분이 더 중요한가를 알 수 있다.
- Upsampling - Unpooling
다음과 같은 여러가지 방법이 있다.
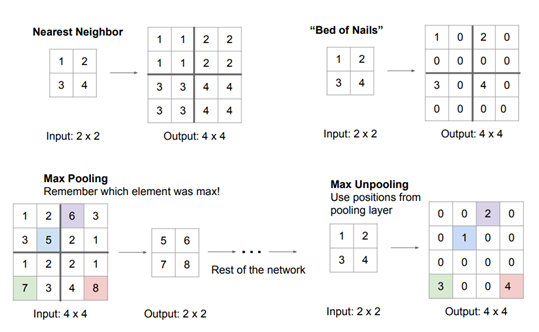
-
Upsampling - Transposed Convolution
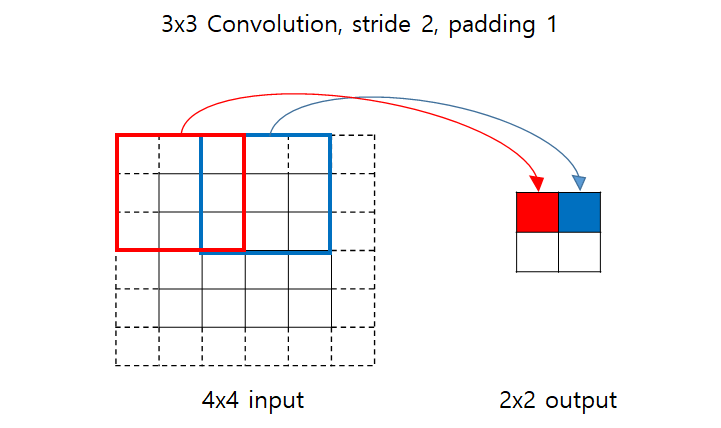
실제 연산은
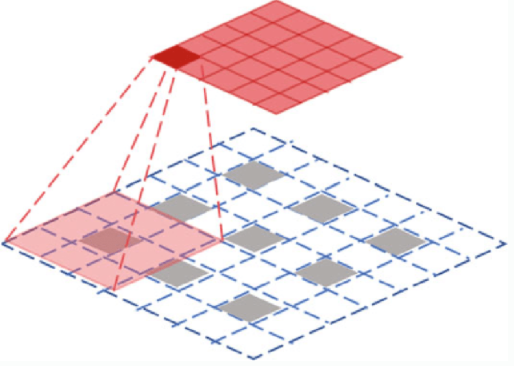
https://www.researchgate.net/figure/Structure-of-a-transposed-convolution-with-3-3-kernel-and-stride-of-2-Input-is-a-3-3_fig8_343356912
위 부분이 input이고 filter size가 3인 경우이다.
input의 원소에 대해 filter와 곱하여 output으로 나가게 된다. 겹치는 부분이 있으면 더해준다. -
추가
이부분이 제일 찾기 어려웠다.
마지막의 channel을 classs의 개수와 맞춰둔다.
target은 해당 object의 channel에 one-hot encoding을 해준다.
.png)