https://arxiv.org/abs/1409.1556v6
1. Introducion
- CNN이 computer vision에서 좋은 성과를 냈고 이를 개선하려는 많은 연구가 있었다.
- 본 논문에서는
Depth라는 ConvNet architecture 에 대해 다룬다. - 다른 parameter들은 고정하고 3×3 filter의 convolution을 stacking하여 depth를 점차 증가 시켰다.
2. ConvNet Configurations
- 순전히 depth에 의한 개선만을 측정하기 위해 모든 convolution layer들은 같은 원리를 적용하였다.
2.1 Architecture
- Input image는 224×224이고 RBG의 평균을 뺐다.
- Filter는 3×3이다. 이는 feature를 추출할 수 있는 최소 size이다.
- layer들 이후의 form을 맞추기 위해 padding = 1
- Maxpooling을 5번 사용하였고 2×2 size이고 stride = 2이다.
- Convolution layers 이후에는 3개의 Fully connected layer가 나온다.
( 4,096 - 4,096 - 1,000 ) - 마지막에는 softmax가 나온다.
- 모든 layer에서 Relu를 사용했다.
- AlexNet의 Local Response Normalization은 memory와 computation time을 증가 시켜서 제거했다.
2.2 Configurations
- 본 논문의 ConvNet의 구성은 다음과 같다.
- Bold는 옆으로 갈 수록 추가된 것을 표현한다.
- A-E 모두는 2.1의 내용을 따르고 깊이만 다를 뿐이다.
- -XX는 filter의 개수 즉, ouput channel의 개수이고 Relu는 생략하였다.
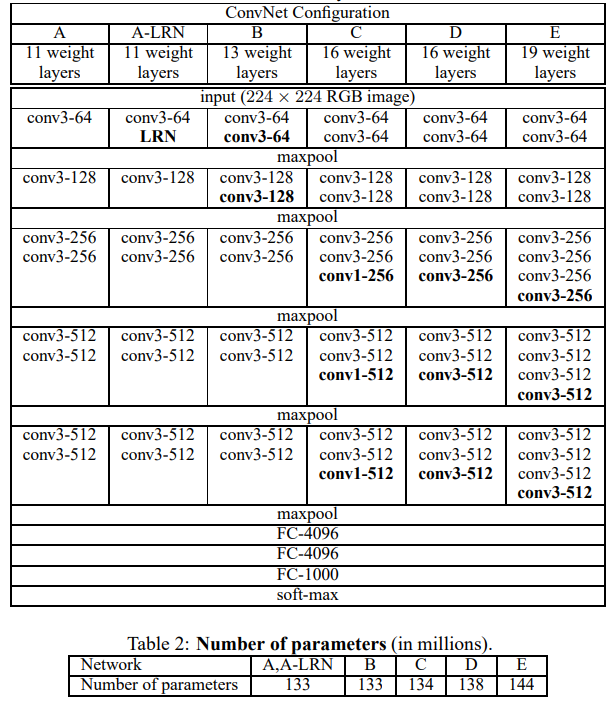
- deep하지만 small filter이기에 parameter가 많지 않다.
2.3 Discussion
- 2012 - 2013의 ILSVRC에서의 좋은 성능을 냈던 CNN은 11×11 filter에 stride = 4 또는 7×7 filter에 stride = 2 였고 본 논문에서의 CNN은 3×3 filter에 stride = 1이다.
- 하나의 convolution대신 몇개의 convolution을 연속적으로 넣고 ( 쌍을 만들어 ) 이후에 maxpooling을 하는 방식으로 stacking하여 기존과 차별을 두었다.
이렇게 하면 size가 큰 filter를 하나 사용 했을때랑 비교했을 때 이점이 무엇인가?- Convolution 이후에 Relu가 들어가므로 Non-Linearity가 증가한다.
쉽게 생각하면 linear function만 여러개 stacking하면 하나의 function과 다를것이 없고 이는 Deep의 의미를 사라지게 한다.
즉 CNN에서의 Deep learning의 Deep의 의미는 layer들을 stacking하여 각각 다른 feature map을 작성하는 것인데 중간에 nonlinear function이 들어가서 이를 각기 다른 layer로 분리 해주는 역할을 하는 것이다. - 이점이 하나 더 있는데 이는 parameter의 수가 감소 한다는 것이다.
C를 channel의 개수라 하고 계산을 해보면
7×7 하나일때는 이고 3×3 3개일때는 이다.
- Convolution 이후에 Relu가 들어가므로 Non-Linearity가 증가한다.
- Model C의 경우에는 1×1 filter가 사용 되었다. 이는 비선형성을 증가시킴과 동시에 receptive field에 영향을 주지 않는다.
- GoogLeNet에서의 very deep ConvNets과 small convolution filters 라는 부분에서는 같지만, 더 복잡하고 첫번째 layer에서 계산량을 줄이기 위해 더 feature map을 더 많이 감소 시켰다는 것에서 다르다.
3. Classification Framework
- Classification ConvNet에 대해 다룬다.
3.1 Training
-
mini batch = 256 , momentum =0.3 , weight decay = 0.005 , dropout = 0.5 ,
learning rate = 0.01 부터 validation set의 accuracy가 멈췄을때 10배씩 점차 줄여나가서 3번 줄어 들었고 74 epoch 학습 하였다. -
Initial weight는 잘못하면 learning이 멈출 수 있기 때문에 중요하다. 이 문제를 해결 ( 돌아가기 )위해 random하게 설정 하여도 문제가 되지 않을 만금 shallow한 A를 학습하고 다음을 순차적으로 하였다. Deeper한 architecture를 학습할 때는 처음 4개위 convolution과 마지막 3개의 dense의 initial을 trained shallower weights 로 사용 하였다.
random initialization은 N(0,0.01)으 따른다.
편향의 initial은 0이다. -
Input image size는 224×224이다. 이는 rescale된 image에서 random하게 잘린것이고 SGD iteration한번에 하나의 cropped image가 사용된다. 즉, augment이다.
추가적인 augment를 위해 좌우반전 RGB shift를 사용한다. -
(training scale)를 isotropically-rescaled training image의 가장 짧은 부분이라고 해보자.
는 224보다 작을 수는 없다. ( input 224×224이므로 )
만약 =224이면 crop을 해도 같다.
>> 224이면 crop을 하면 부분만 추출될수 있다. -
를 선택하는 방법에는 두가지가 있는데 첫번째는 fix이다.
본 연구에서 train 할때는 256으로 고정하여 학습 한 후 384를 할때 256으로 pre-trainde weights를 사용하여서 속도를 높였다. -
두번째 방법은 를 범위를 설정하여 random sampling하는 방법이다.
256 ~ 512로하고 아마도 이때는 마지막에 FC가 아니라 FCN인거 같다.이는 다양한 size의 image를 훈련할때 유리하다. Augment의 효과가 있고 이를 Scale-jittering이라 한다.
위와 비슷하게 384으로 pre-trainde weights를 initial로 사용하여서 속도를 높였다. -
isotropically-rescaled
E.g) 512×1024 image를 small side가 256이 되게끔 1:2 ratio를 유지한채 256×512로 rescale한다.
그럼 이걸 256으로 학습하고 384로 학습한 후 다시 random으로 학습한건가???????????????
3.2 Testing
( Validation set으로 검증하는 과정이라고 보는게 맞지않나?
test라는단어를 사용하지만 validation set으로 test 한다고 봐야할듯 )
-
Training과 마찬가지로 isotropically-rescaled를 사용하고 라고 한다. =일 필요는 없다.
-
생각을 해보자. input에 따라 filter의 size가 바뀌지 않는다.
하지만 마지막 flatten에서 달라진다 그러면 무조건 trian의 input과 test 할때의 input의 form이 같아야 하는거 아닌가?
이를 해결하기 위해 다음과 같은 작업을 추가해준다.
3.3 Implementation Details
4. Classification Experiments
- dataset : ILSVRC-2012 ; image of 1,000 classes
import tensorflow as tf
from tensorflow.keras.utils import plot_model
model = tf.keras.applications.VGG16(
include_top=True,
weights="imagenet",
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
classifier_activation="softmax",
)
plot_model(model,show_shapes=True)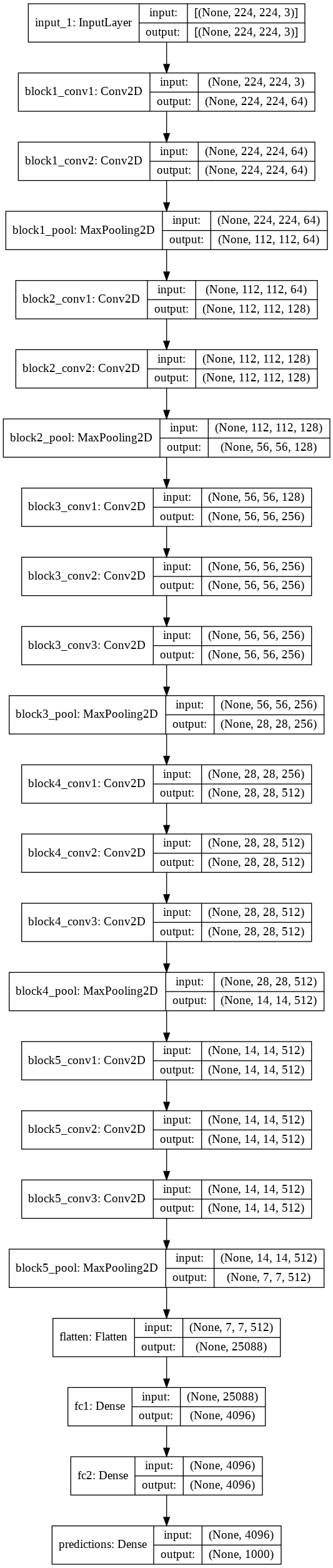

추후정리 Localization임
.png)