바로 Architecture로 들어가 앞 내용과 함께 설명하겠다.
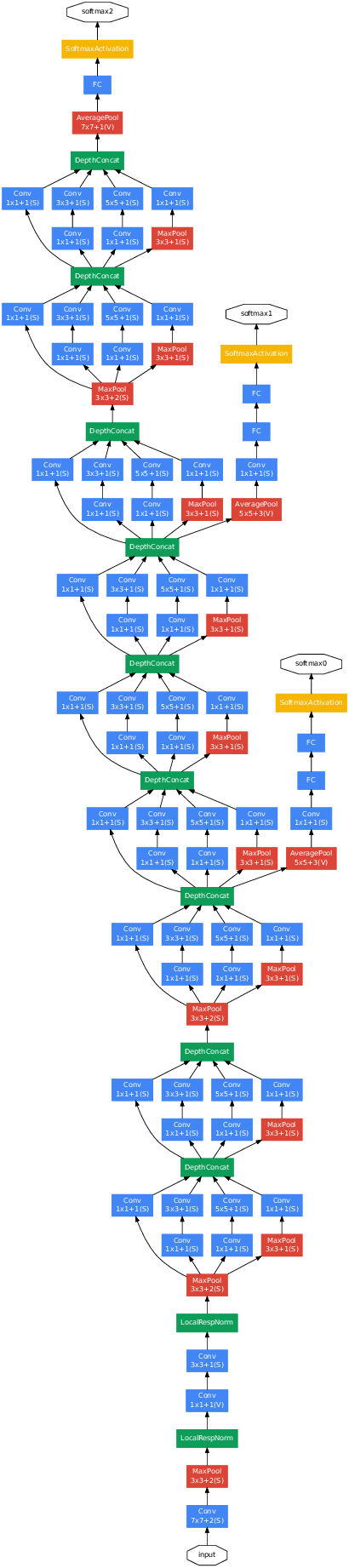
GoogLeNet Architecture이다.
기존의 또는 대부분의 CNN model은 세로가 길었다. 정확히 세로로만 길었다.
중간에 옆으로 되어있는 구조가 보이는데 이 구조를 Inception module이라고 한다.
정확하게 말하면 Inception module에는 여러 종류가 있는데 그 중 한 종류이다.
이 module이 본 논문의 핵심이며 Inception model로 불리기도 하는 이유이다.
Inception module
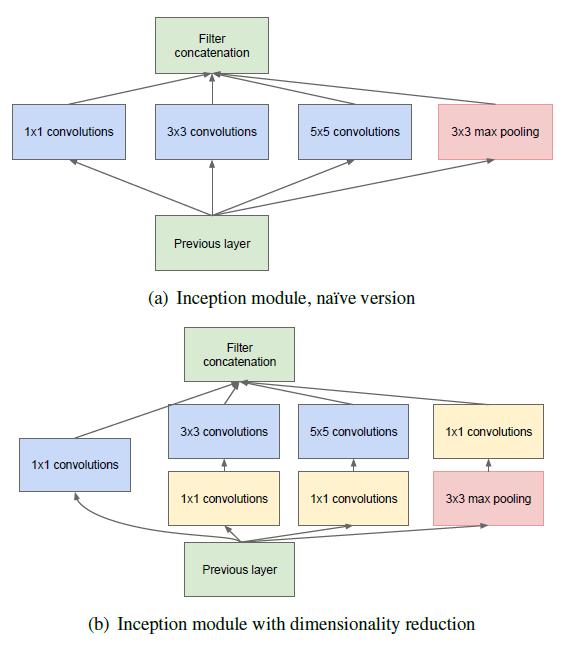
기존의 CNN은 세로방향으로 convolution을 stacking하는 방향으로 설계되었다.
예를들어 같은 대회의 2등을 했지만 주목을 더 많이 받았던 VGG를 보더라도 아래와 같은 방식으로 conv3개를 연속으로 두는 방법으로 설계하였다.

그럼 Inception module을 사용하면 뭐가 좋은가?
첫번째는 경량화이다.
경량화는 항상 문제이고 parameter는 줄이면서 성능은 유지해야한다. 즉 어렵다.
위의 VGG구조를 포함한 많은 model에서 parameter의 수가 너무 많기 때문에 Bottle-neck구조를 사용하는 등 많은 노력을 한다.
- 1×1 convolution
정확하게 말하자면 1×1 conv로 인해 경량화가 된다.
1×1 conv은 다양한 곳에서 사용된다.
FCN에서는 FC를 대체하고자 사용하기도 한다.
일반적인 filter는 spatial feature를 뽑아내는 역할을 하는데 1×1 conv는 channel을 줄일때 많이 사용된다.
두번째
다시 CNN을 생각해보면 low-level filter는 는 점선면 등을 뽑아내고 high-level filter는 그들을 조합해 calssification한다 정도로 생각하면 편하다.
근데 이게 문제가 model에서 filter size를 fix 해두기 때문에(그래야 학습이 되므로 너무 당연한 것) 문제가 될 수도 있고 Inception이 해결해 줄수도 있다고 본다.
이렇게 생각해보자. (zero padding ,stride=1가정.)
어떤 image가 input으로 들어오는데 image에는 적어도 4×4짜리 filter가 있어야 의도한 feature를 뽑아 낼 수 있다.
그런데 여기서 3×3 filter를 사용하면 문제가 생길 수 있다?
아니다 그 다음 3×3 filter을 stacking하면 해결된다.
이유는 간단하다.
Input의 그 4×4 pixel들의 네개의 꼭짓점을 생각해 보자.
첫번째 filter에서는 (1,1),(1,4),(4,1),(4,4)(좌표는 상대적인 위치임)가 한번에 계산될수가 없다.
대신에 첫번째 filter를 거친 map의 중앙 4개의 pixel은 위 꼭짓점을 모두 포함하게 되고 다음 3×3 filter에서 같이 계산되므로 문제가 안생긴다.
그리고 이게 좋은게 low-level에서 점,선을 뽑고 그 data를 가지고 high-level에서 classification한다 라고 하면 사람이 인식하는 것과도 비슷한게 우리가 pixel을 보고 판단하는것은 아니니까 그래서 처음에는 보통 large filter를 사용하나??????????
예를들어 거울에 비친 사람을 분류한다고 생각하면 좋다.
여기서 위의 model과 Inception의 차이점을 하나 더 생각할 수 있는데, 바로 하나의 image에 대해 다양한 filter를 적용한다는 것이다.
물론 위의 내용으로 상관없지 않냐라고 생각할 수 있는데 엄밀히 말하면 다른점이 있다.
위의 내용은 filter를 두번 거쳐서 꼭짓점이 계산되는 반면에 Inception은 한번에 계산된다.
즉 매 map마다 3개의 서로 다른 filter가 적용된다는 것이다.
다음(a)와 (b)가 있는데 위에서 말한 1×1 filter를 사용하여 channel을 줄여 parameter를 줄이기 위함이다.
마지막에는 concatenation을 해준다.
auxiliary classifiers
중간에 노란색으로 나온 부분으로 끝나지도 않았는데 결과를 도출한다.
이는 grad의 전달을 위해 들어간 부분이다.
이렇게 생각해 볼 수 있다.
DL은 vanishing/exploiding grad 중요한 문제점 중 하나이다.
이를 해결하기 위해 BN등 많은 노력을 하고 있다.
2014년이라 그런지 BN이 아닌 LRN을 사용하였다.(U-Net에서도 사용함.)
그래서 그런지 몰라도 즉,LRN을 사용해도 문제가 생겼는지 중간 중간을 END로 만들어 줘서 bptt중 작아진 기울기를 다시 키워주는 역할을 한다.
code에서 보면 loss에 더해주게 되는데 weight=.3을 사용해 준다.
왜 0.3인지는 정확히 모르겠으나 (아마 hyper parameter이므로 여러번 해봤을 거다.)
중간의 목적은 기울기를 살려주는 거지 중간의 loss값을 작게 만드는 것이 주 목적은 아니므로 1보다 작은 weight를 곱해 줘야 하는 것은 분명하다.
.png)