https://arxiv.org/abs/1506.02640
R-CNN계열은 2-stage입니다.
즉, RoI를 먼저 추출하여 추출된 image (또는 feature map) 를 classification하는 과정을 거칩니다. 즉 한번에 학습이 불가능 하고 복잡하며 최적화가 상당히 어렵습니다. 결정적으로 상당히 느립니다.
Yolo는 1-stage model로 RoI와 classification을 동시에 진행합니다.
1. Abstract & Introduction
Unified network
bnd와 classification모두를 regression으로 바라봅니다. 또한 단일 nertwork로 full input image에 대해 bnd를 예측하며 동시에 확률로 같이 예측합니다. 이는 end-tp-end입니다. 따라서 이부분에서 R-CNN에 비해 상당히 빠릅니다. YOLO의 경우 45fps이고 (초당 45장 처리) fast YOLO의 경우 155fps입니다.
R-CNN은 bnd와 classification의 두 갈래의 pipe line으로 구성되어 있어 복잡 하며 따로 학습될 수 밖에 없습니다. YOLO는 object detection문제를 하나의 regression문제로 보았습니다. 따라서 YOLO는 이미지를 한번 보고 어떤 물체이고 어디 있는지 알아 냅니다.
YOLO는 아래 그림과 같이 상당히 간단합니다. (R-CNN과 비교하면...)
하나의 Conv network가 mulitiple bounding box와 해당 box들에 대한 class probability를 계산합니다.
이unified model은 몇가지 장점이 있습니다.
1. 첫째로 상당히 빠릅니다. 복잡한 pipe line이 필요 없습니다.
2. 예측을 진행 할 때 global한 사고를 합니다. sliding window나 selective search와는 다른 방식입니다. 이와 같은 방식들은 전체를 보지 못합니다. 정확히 말하면 RoI에 대한 image 또는 featuremap을 가지고 classification을 진행 합니다. 즉, 전체를 보지 못하고 단순하게 물체가 존재할 법한 부분만을 crop하여 predict합니다. 이와는 다르게 YOLO는 predict에 있어 image전체를 봅니다. 어떻게 이게 가능한지는 아래 Architecture 에서 설명합니다.
3. YOLO는 물체의 일반적이 표현을 학습합니다. 자연의 이미지로 train을 하고 예술작품을 가지고 test를 진행 할 때 성능이 다른 모델에 비해 뛰어납니다.
결론은 빠릅니다. 하지만 성능은 떨어집니다. 이는 trade-off관계로 당연하다고 볼 수 있습니다.

2. Architecture
YOLO는 각각의 bnd를 예측하기 위해 전체 이미지 전체를 통해 나온 feature들을 이용합니다. (R-CNN, SPPNet, Fast R-CNN은 algorithm을 우선 이용한 후 이후에 서정하기 위해 regression을 진행합니다. 즉, 이부분에서 YOLO는 R-CNN과는 다르게 feature를 가지고 bnd를 예측하는 것입니다.)
첫번째로 개의 grid로 나눕니다. 실제(정답) object의 중심이 어떠한 grid에 해당된다면 해당 grad cell은 해당 object를 detect해야 합니다.
각각의 grid cell은 개의 bnd와 해당 box들의 confidence socore를 에측합니다.
입니다.
confidence score의 의미는 다음과 같습니다.
< bnd가 object를 포함한다는 사실이 얼마나 믿을만 한 가 > + < predicted bnd가 얼마나 정확한 지 >
만약 해당 grid cell에 object가 하나도 없다면 confidence score는 0이 되어야 합니다.
반대로 object가 있다면 &Pr(object)&가 1이 되어 IoU랑 score랑 같아집니다.
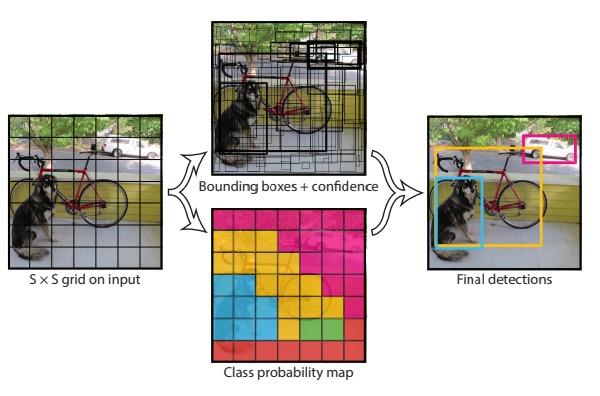
각각의 bnd는 5개의 prediction으로 이루어져 있습니다. 입니다.
이때 는 모두 0~1의 사이의 값입니다.
또한 는 grid cell안에서의 값이며 는 input image 전체에서의 값입니다.
각각의 gird cell 위의 5개와 더불어 를 예측합니다.
로 conditional probability입니다.
또한 5개의 prediction은 bnd의 개수만큼 예측하지만 는 몇개의 bnd인지와는 상관없이 grid cell당 하나만 예측합니다.
test time에서는
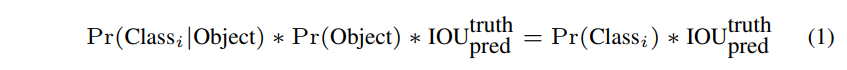
PASCAL VOC일때 을 사용하였습니다.
따라서 output tensor의 size는 입니다.
위 사실들을 이용하여 구조를 보겠습니다.
그림에서 다면체는 모두 feature map을 나타낸 것이고 사이사이가 conv 와 fc 연산을 나타낸 것입니다.

conv
본 논문에서 사용한 Conv는 GoogLeNet의 classification model을 변형하여 사용하였습니다.
총 24개의 conv layer가 있고 마지막에 2개의 fc가 있습니다.
논문에서 reduction을 사용했다고 하는데 이는 VGG, ResNet등에서 깊게 쌓을때 연산량을 줄이기 위해 즉 conv를 이용하여 channel을 줄이는 bottle neck architecture입니다.
Fast version은 9개의 conv를 이용하였습니다.
앞에서도 언급했지만 size of final output tensor is 입니다.
output tensor
output tensor에 관해서는 https://docs.google.com/presentation/d/1aeRvtKG21KHdD5lg6Hgyhx5rPq_ZOsGjG5rJ1HP7BbA/pub?start=false&loop=false&delayms=3000&slide=id.g137784ab86_4_969 의 슬라이드를 보시면 잘 설명되어 있습니다.
3. Training
처음에는 ImageNet을 이용한 classification model을 pre-train합니다.
이때 전체를 pretrain 하는것이 아니라 24개의 conv중 앞의 20개에 대해 진행합니다.
다음 이를 detection model로 바꿉니다.
즉, classifier를 삭제하고 4개의 conv와 2개의 fc를 추가합니다.
또한 input size를 224 -> 448 로 바꿉니다.
마지막 layer는 class probability와 bnd coordinate을 동시에 예측합니다.
앞에서 언급했는데 는 normalize하여 0~1의 값을 갖게 합니다.
도 0~1의 값을 갖게 하는데 이는 normalize가 아니라 parameterize합니다.
Activation으로는 Leaky ReLU를 사용하였습니다.
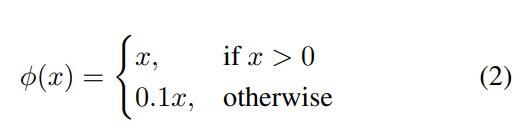
Loss function
Loss function은 위와 같습니다.
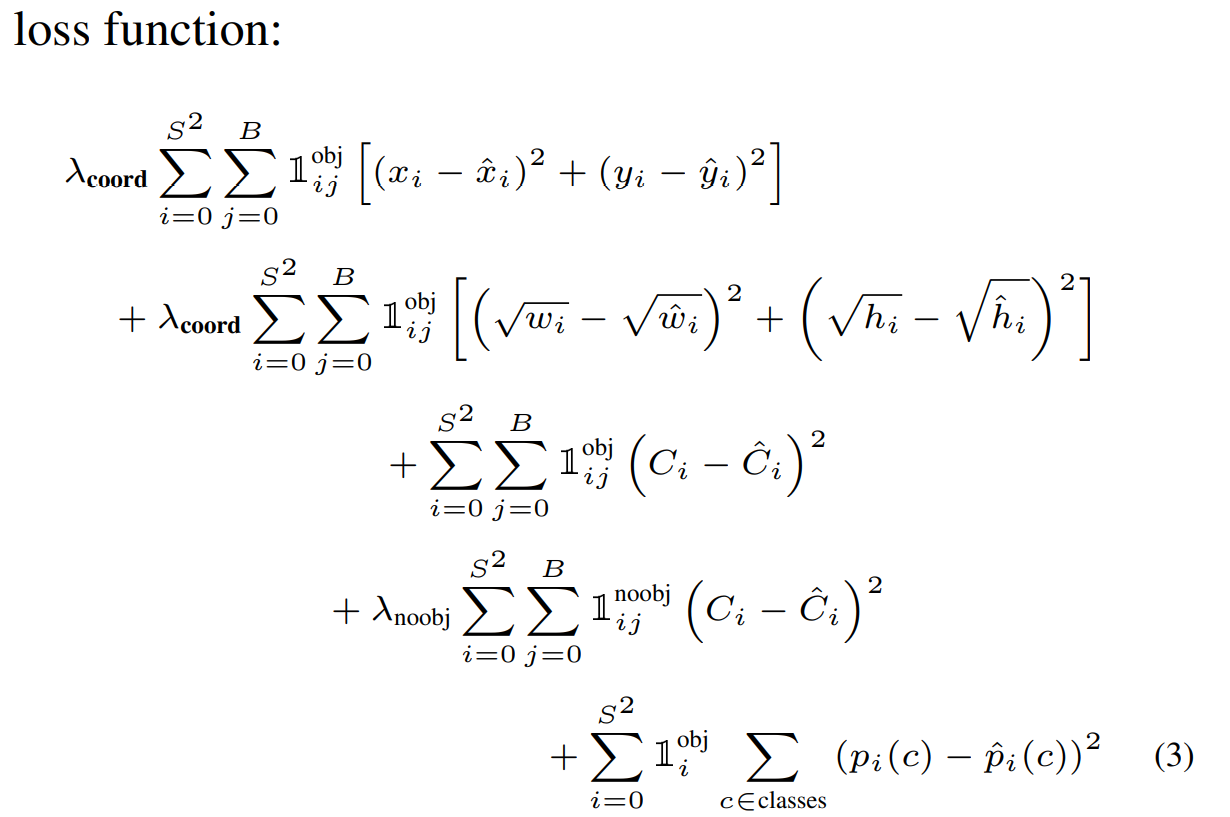
.png)