Paper_Review_object_detection
1.Thumbnail

2022년 1월 21일
2.순서
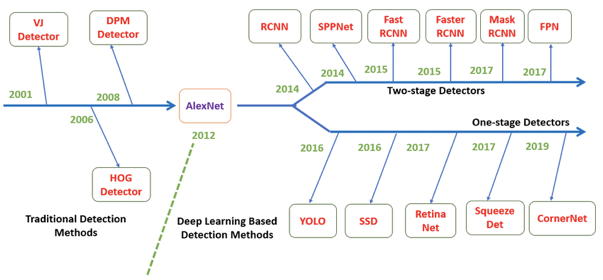
2022년 1월 24일
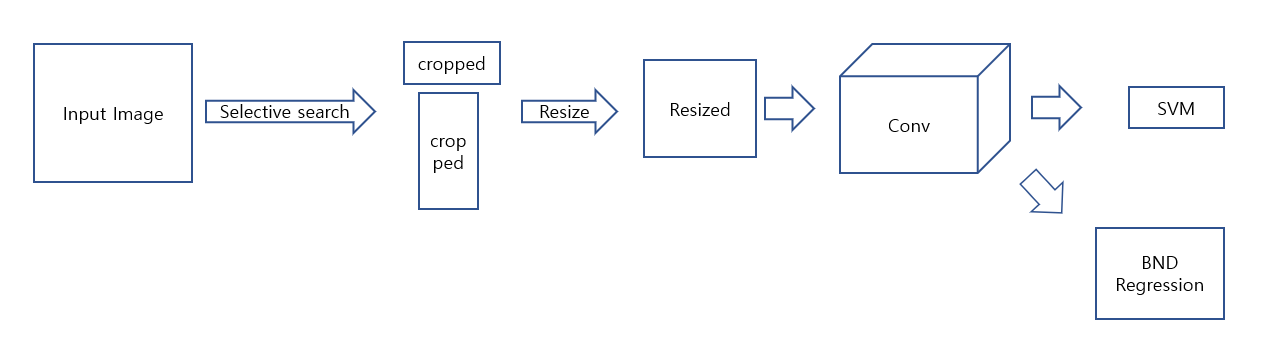
3.Rich feature hierarchies for accurate object detection and semantic segmentation, RCNN
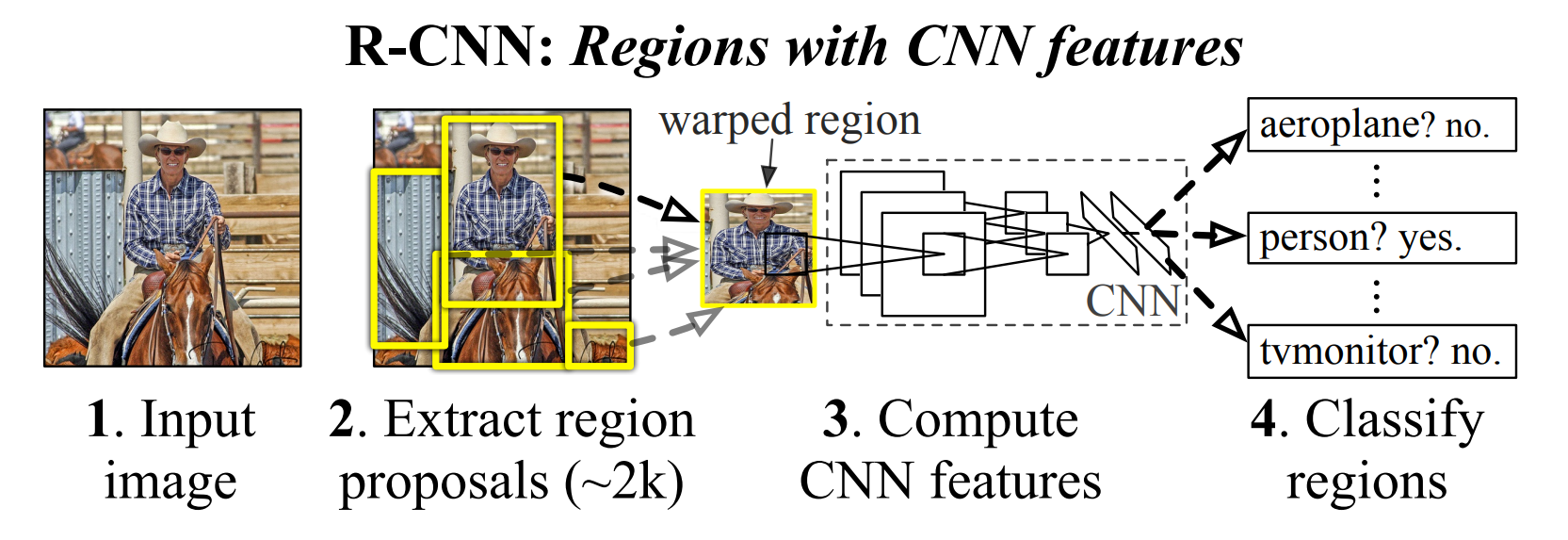
https://arxiv.org/abs/1311.2524Object detection 분야에서 convolution 구조를 이용한 model로 현재는 여러가지 이유로 안쓰인다.그래도 기본인 되는 model이고 이후 나온 RCNN을 활용한 model을 이해하는데
2021년 12월 25일
4.Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition, SPPNet
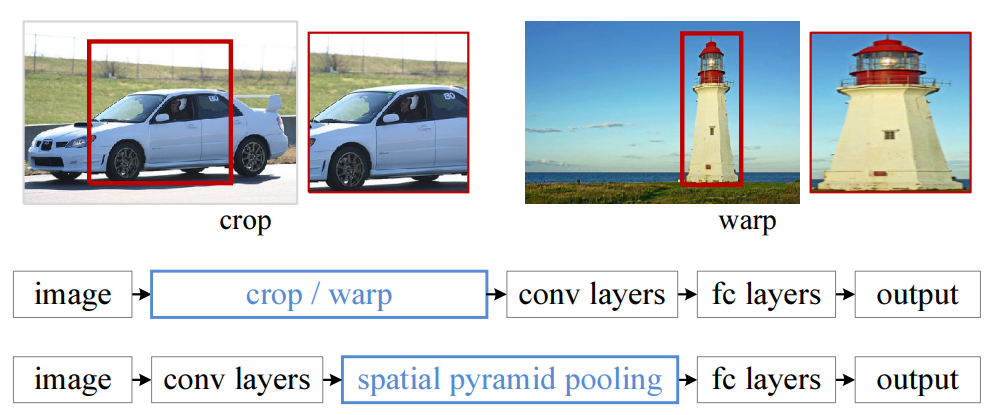
RCNN에서는 selective search algorithm을 통과한 후 warp(resize)를 거쳐서 CNN에 들어 가기전 227×227의 size로 고정해주어야 했다.엄밀히 말하면 convolution은 같은 size의 image가 들어갈 필요는 없다.대표적인
2021년 12월 27일
5.Fast R-CNN
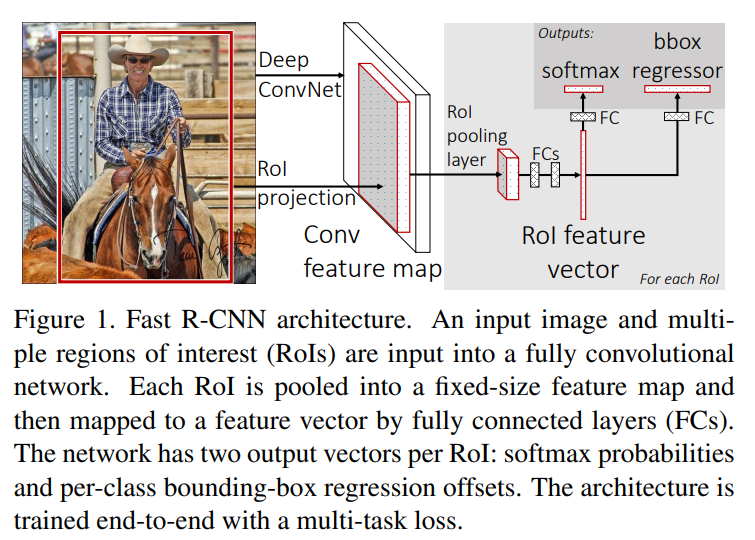
multi-stage pipeline입니다.https://velog.io/@jj770206/Rich-feature-hierarchies-for-accurate-object-detection-and-semantic-segmentation-RCNN 의 중간 그림을
2022년 1월 10일
6.Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
https://arxiv.org/pdf/1506.01497.pdf기존의 RCNN의 문제는 첫번째는 End-to-end가 아니여서 학습하기 어렵다라는 문제가 있고, 두번째는 selective search와 같은 region proposal을 사용하므로 시간이 오
2022년 1월 8일
7.Feature Pyramid Networks for Object Detection ; FPN

2022년 1월 24일
8.You Only Look Once: Unified, Real-Time Object Detection

https://arxiv.org/abs/1506.02640
2022년 1월 24일