transfer learning의 마지막 전체 code이다.
import os
from PIL import Image
import matplotlib.pyplot as plt
import cv2
import numpy as np
import torch
import torchvision
import torch.nn as nn
import time
import copy
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transforms
from tqdm.auto import tqdm
import torch.nn.functional as F
import torchvision.models as models
os.chdir('/home/mskang/hyeokjong/birds/rename_train')
train_list = os.listdir('/home/mskang/hyeokjong/birds/rename_train')
val_list = os.listdir('/home/mskang/hyeokjong/birds/rename_valid')
class custom_dataset(Dataset):
def __init__(self, input_dir, transform = None): # omit target directory because filename itself is target.
self.input_dir = input_dir
self.input_list = os.listdir(input_dir)
self.transform = transform
def __len__(self):
return len(self.input_list)
def __getitem__(self,idx):
os.chdir(self.input_dir)
input_image_numpy = cv2.imread(self.input_list[idx])
target_class = int(self.input_list[idx][0:2]) # get class from filename slicing
if self.transform:
input_image_numpy = self.transform(input_image_numpy)
input_tensor = torchvision.transforms.functional.to_tensor(input_image_numpy)
target_tensor = torch.tensor(target_class) # 여기서 torch.tensor와 위의것의 차이점은 위의 함수는 0-1까지로 변환까지 해준다.
return (input_tensor, target_tensor)
class RandomFlip(object):
# input으로 numpy를 받는다.
def __init__(self, horizontal = True, vertical = False, p = 0.5):
self.horizontal = horizontal
self.vertical = vertical
self.p = p # p는 그냥 예의상 넣었다. 건들이는 경우가 있나 싶긴하다
def __call__(self, inputs):
if (self.horizontal) and (np.random.rand() > self.p):
inputs = cv2.flip(inputs,1)
if (self.vertical) and (np.random.rand() > self.p):
inputs = cv2.flip(inputs,0)
return inputs
train_dataset = custom_dataset('/home/mskang/hyeokjong/birds/rename_train', RandomFlip())
val_dataset = custom_dataset('/home/mskang/hyeokjong/birds/rename_valid', RandomFlip())
device = 'cuda:1'
batch_size = 32
train_dl = DataLoader(train_dataset, batch_size, shuffle=True,
num_workers=4, pin_memory=True)
val_dl = DataLoader(val_dataset, batch_size, shuffle=True,
num_workers=4, pin_memory=True)
for i,j in train_dl:
train_input=i.to(device)
train_target=j.to(device)
break
for i,j in val_dl:
val_input=i.to(device)
val_target=j.to(device)
break
print(train_input.shape, train_target, val_input.shape, val_target,sep='\n')
vgg16 = torchvision.models.vgg16(pretrained = True)
vgg16_conv = vgg16.features
vgg16_conv
class vgg16__(nn.Module):
def __init__(self, conv_seq, flatten, classifier):
super(vgg16__, self).__init__()
self.conv_seq = conv_seq
self.flatten = flatten
self.classifier = classifier
def forward(self, x):
x = self.conv_seq(x)
x = self.flatten(x)
x = self.classifier(x)
return x
class Flatten(nn.Module):
def forward(self, input):
return input.view(input.size(0), -1)
classifier = nn.Sequential(nn.Linear(in_features = 512*7*7, out_features = 512*7, bias = True),
nn.ReLU(),
nn.Dropout(p = 0.5),
nn.Linear(in_features = 512*7, out_features = 512, bias = True),
nn.ReLU(),
nn.Dropout(p = 0.5),
nn.Linear(in_features = 512, out_features = 100, bias = True))
vgg16_new = vgg16__(vgg16_conv, Flatten(), classifier)
vgg16_new = vgg16_new.to('cuda:1')
vgg16_new(train_input).shape
import pytorch_model_summary
from torchinfo import summary
model = vgg16_new
x = train_input
print(pytorch_model_summary.summary(model, x, show_input=True))
print('!@#'*40)
summary(model, input_size = x.shape )
for name, parameter in model.named_parameters():
print(name)
for name, parameter in model.named_parameters():
if name[:4] == 'conv':
parameter.requires_grad = False
for name, parameter in model.named_parameters():
print(name, parameter.requires_grad)
model = vgg16_new.to('cuda:1')
# 현재의 lr을 출력한다.
def get_lr(opt):
for param_group in opt.param_groups:
return param_group['lr']
# optimizer 와 scheduler를 설정한다.
opt = torch.optim.Adam(model.parameters(), lr=0.001)
from torch.optim.lr_scheduler import ReduceLROnPlateau
lr_scheduler = ReduceLROnPlateau(opt, mode='min', factor=0.1, patience=10)
# metric function을 만든다.
def metric_function(output, target):
_, argmax = torch.max(output, dim = 1)
corrects = (argmax == target).sum()
return corrects
# loss function을 만든다.
loss_function = nn.CrossEntropyLoss(reduction = 'sum')
def train_val(model, params):
num_epochs=params['num_epochs']
loss_func=params["loss_func"]
opt=params["optimizer"]
train_dl=params["train_dl"]
val_dl=params["val_dl"]
lr_scheduler=params["lr_scheduler"]
path2weights=params["path2weights"]
loss_history = {'train': [], 'val': []}
metric_history = {'train': [], 'val': []}
best_model_weight = copy.deepcopy(model.state_dict())
# 아래에서 best parameter저장할때를 대비하여 미리 모양만 만들어 둔다. 공식문서에서 clone 대신 이거 사용함.
# https://discuss.pytorch.org/t/copy-deepcopy-vs-clone/55022
best_loss = float('inf')
# best model을 저장할때 기준이 loss value 이므로 미리 큰 값으로 설정 해 둔다.(작으면 좋은 거니까)
start_time = time.time()
for epoch in range(num_epochs):
# 1-epoch이다.
current_lr = get_lr(opt)
print('Epoch {}/{}, current lr={}'.format(epoch, num_epochs-1, current_lr))
#-------------------------------------------------------------------------------------------------------
model.train()
# nn.Module에 있다. 하는 역할이 크지는 않다. 하지만 필수 적인데 일단 이는 train과 validation을 구분하게 해준다.
# parameter를 계산안하고 하고를 결정하는 것은 아니고, dropout같이 train과 validation에서
# 다른 연산을 하는 layer들에게 지금 뭘 하고 있는지 알려준다.
running_loss = 0.0
running_metric = 0.0
# epoch 마다 0으로 만들어 준다.
len_data_train = len(train_dl.dataset)
# 이는 전체 data의 개수이다.
for inputs, targets in tqdm(train_dl):
# 1-batch train
inputs , targets = inputs.to(device) , targets.to(device)
outputs = model(inputs)
loss_batch = loss_func(outputs, targets)
metric_batch = metric_function(outputs, targets)
opt.zero_grad() # 이미 저장되어 있는 grad를 없애준다.
loss_batch.backward() # autograd = True 되어있는 parameter들의 위치에서 grad를 계산한다.
opt.step() # update한다.
running_loss += loss_batch.item() # 이는 1-minibatch의 value이고 epoch이 될때까지 누적합을 계산한다.
running_metric += metric_batch
train_loss = running_loss / len_data_train # 따라서 이 값이 1-epoch당 loss와 metric이다. 이때 굳이 loss에서 sum을 하였는데
train_metric = running_metric / len_data_train # 이는 batch 별로 다 더하고 여기서 한번에 다음과 같이 나누는게 편해서이다.
loss_history['train'].append(train_loss) # 매 epoch당 저장해 둔다.
metric_history['train'].append(train_metric)
#-------------------------------------------------------------------------------------------------------
model.eval() # nn.Module에 있다
with torch.no_grad():
# 이렇게 하여 with문 아래에서는 autograd = False가 되는데 이는 with문 아래에서만 일시적으로 그렇하다.
# 아니면 transfer에서 사용하는 방법처럼 layer마다 grad를 off 해줘도 되는데 그럼 또 다시 켜줘야 하니까 이렇게 하는 것이 합리적이다.
running_loss = 0.0
running_metric = 0.0
len_data_val = len(val_dl.dataset)
for inputs, targets in val_dl:
inputs , targets = inputs.to(device) , targets.to(device)
outputs = model(inputs)
loss_batch = loss_func(outputs, targets)
metric_batch = metric_function(outputs, targets)
running_loss += loss_batch.item()
running_metric += metric_batch
val_loss = running_loss / len_data_val
val_metric = running_metric / len_data_val
loss_history['val'].append(val_loss)
metric_history['val'].append(val_metric)
# Best model을 판단하고 저장하고 불러온다.
if val_loss < best_loss:
best_loss = val_loss
best_model_weight = copy.deepcopy(model.state_dict()) # 앞에서와 마찬가지로 parameter를 복사한다.
torch.save(model.state_dict(), path2weights)
print('Copied best model weights!')
print('Get best val_loss')
lr_scheduler.step(val_loss)
print('train loss: %.6f, train accuracy: %.2f' %(train_loss, 100*train_metric))
print('val loss: %.6f, val accuracy: %.2f' %(val_loss, 100*val_metric))
print('time: %.4f min' %((time.time()-start_time)/60))
print('-'*50)
model.load_state_dict(best_model_weight)
######### 항상 마지막 epoch이 best가 아니므로 test를 위해 best의 parameter를 불러준다.
# 이때 불러줄때 이미 짜여진 model의 class에 저렇게 불러줘야 한다.
# 그러면 parameter 자리에 알아서 잘 들어간다.
return model, loss_history, metric_history
params_train = {
'num_epochs':20,
'optimizer':opt,
'loss_func':loss_function,
'train_dl':train_dl,
'val_dl':val_dl,
'lr_scheduler':lr_scheduler,
'path2weights':'/home/mskang/hyeokjong/birds/best_model.pt',
}
model, loss_hist, metric_hist = train_val(model, params_train)
model.state_dict()
num_epochs=params_train["num_epochs"]
# plot loss progress
plt.title("Train-Val Loss")
plt.plot(range(1,num_epochs+1),loss_hist["train"],label="train")
plt.plot(range(1,num_epochs+1),loss_hist["val"],label="val")
plt.ylabel("Loss")
plt.xlabel("Training Epochs")
plt.legend()
plt.show()
# plot accuracy progress
plt.title("Train-Val Accuracy")
plt.plot(range(1,num_epochs+1),metric_hist["train"],label="train")
plt.plot(range(1,num_epochs+1),metric_hist["val"],label="val")
plt.ylabel("Accuracy")
plt.xlabel("Training Epochs")
plt.legend()
plt.show()
학습이 끝나도 conv의 parameter는 유지되었다.
근데 문제가 있는데
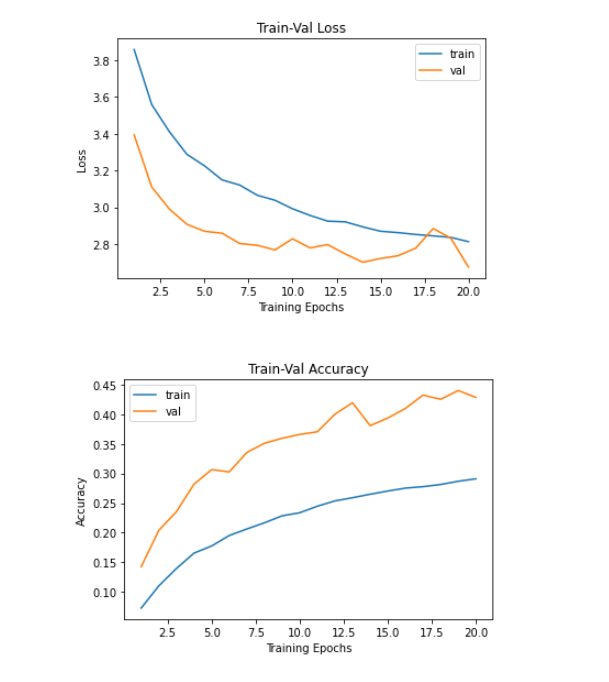
음 모양은 진짜 좋은데 acc가 너무 낮다.
epoch이 부족하거나 너무 많이 freeze하고 실질적인 이번 dataset에 맞는 parameter가 너무 적었거나 했을거다. epoch당 시간은 1:39이다.
시간비교를 위해 모든 parameter의 autograd를 켜보았다.
epoch당 시간은 4:20정도 성능은확인 안해봤다.
.png)