논문 링크 : https://dl.acm.org/doi/abs/10.1145/2959100.2959190
현재 구글 유튜브의 추천 알고리즘 paper
- Nandy et al., (2010) The YouTube Video Recommendation System
- Covington et al., (2016) Deep Neural Networks for YouTube Recommendations - 리뷰
- Zhao et al., (2019) Recommending What Video to Watch Next: A Multitask Ranking System
추천시스템 중에서 가장 근본이라고 할 수 있는 유튜브 추천 알고리즘에 대해서 리뷰하고자 한다.
- 위 사이트는 그래프 형태로 citation된 paper들을 시각화해서 접근하기 쉽게 나타냈다. 위 사이트를 참고해도 좋을 것 같다.
목차
- Introduction
- System Overview
- Candidate Generation
- Ranking
- Conclusions
1. Introduction
- 딥러닝을 이용해서 유튜브 영상 추천을 다루고자 한다.
- 유튜브 비디오 추천은 3가지의 상당한 어려움 존재
- Scale : 너무 많은 유튜브 user와 corpus(비디오 데이터)
- Freshness : 하루에도 몇 백만 개 이상의 영상들이 업데이트되기에 이러한 부분들을 유저의 최신 반응에도 반영해야 함
- Noise : 진정으로 각기 유저의 만족도를 알기 어렵기 때문에, 노이즈가 많이 껴 있는 implicit feedback signal들로 파악해야 한다. 뿐만 아니라 영상 메타데이터도 잘 구조화되어있지 않음.
2. System Overview
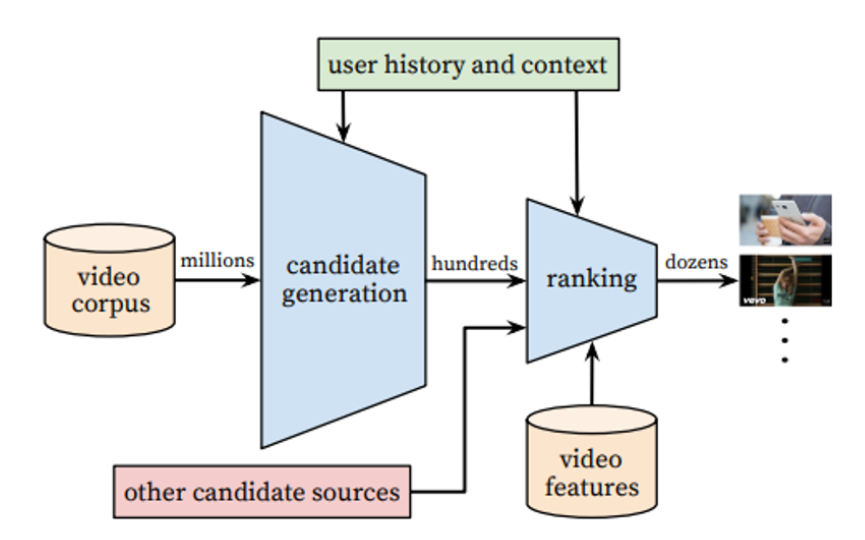
- 이 추천시스템에는 크게 2가지 Neural Network로 구성되어있다.
- Candidate Generation
- 유저의 유튜브 활동 이력을 가지고 소수의(수백여개) 정도의 비디오를 예측
- 높은 Precision으로 유저의 일반적인 연관성을 의도
- 협업 필터링을 통해 제공
- 시청한 영상 ID, 검색 토큰, demographics 등의 user feature 사용
- Ranking
- 소수의 (수백여개) 영상들 중 score를 매겨서 사용자가 “가장” 좋아할 극소수의 영상(몇 십 개)들을 추천함
- Offline 평가와 Online 평가 모두 진행
- Offline 평가 : Precision, Recall, ranking loss, etc.
- Online 평가 : live A/B testing
- Candidate Generation
3. Candidate Generation
- 접근 방식 : nonlinear generalization of factorization(분해) techniques.
3.1. Recommendation as Classification
- 추천 task에 대해서 multi - class classification task로 치환함
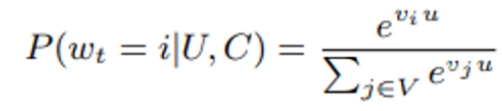
- 유저 와 context 가 주어졌을 때, 시각의 비디어 시청 내역인 가 전체 비디오 집합 중 i번째 비디오일 확률 → 유저 및 상황(context)의 임베딩(u)과 비디오 임베딩(v)의 softmax로 정의
- 유저가 비디오를 끝까지 보면 positive 데이터로 처리
- explicit 피드백은 너무 sparse해서 implicit 피드백을 활용함
- negative sampling
- 전체 negative에 softmax하는 것보다 100배 이상 빠름
- hierarchical softmax도 시도해볼 수 있지만, accuracy가 떨어짐
- 실제 모델 서빙 시에는 top N개 클래스(비디오들)만 찾으면 되기에, softmax까지 계산하지 않고 내적(dot product) 값만 비교함 (이 내적 공간에서 가장 가까운 item 찾음)
3.2. Model Architecture
- 사용자의 시청 이력과 검색기록에 대해서 각 비디오의 dense(밀집된) 임베딩 평균으로 표현
- 사용자의 영상 시청 이력과 다른 feature들을 concat하여 tower 구조의 여러 ReLU layer를 통과
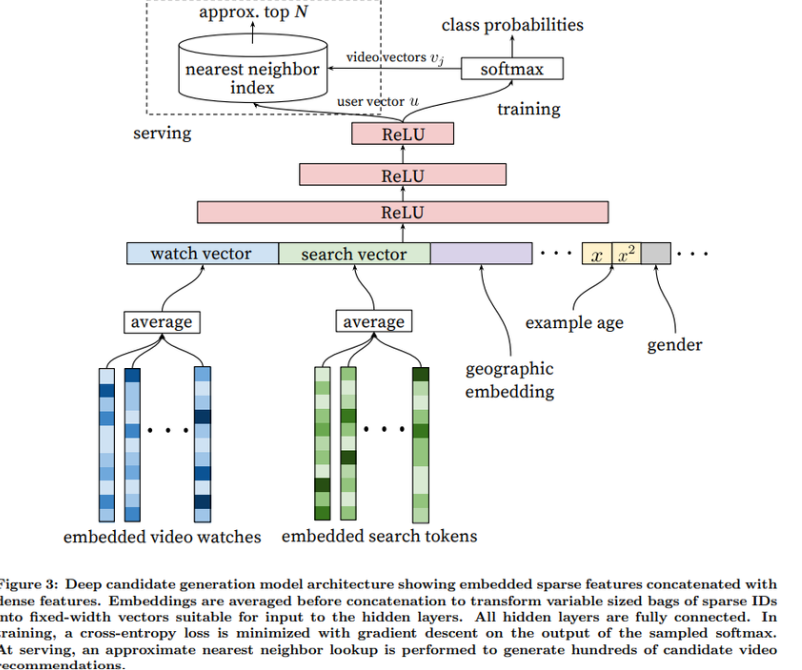
3.3. Heterogeneous Signals
- DNN 사용하는 주요 이점 → 연속형, 범주형 feature들을 쉽게 추가할 수 있다.
- Search query는 각각 unigram 및 bigram으로 토큰화(임베딩 평균)
- 사용자의 지리적 지역과 디바이스 임베딩
- 사용자의 성별, 로그인 여부, 나이를 input으로 [0,1] 사이로 정규화시킨 값으로 나타냄
- 이러한 유저의 인구통계학적 피쳐는 정보가 많이 없는 새로운 유저에게 추천해줄 때 필요함
- “Example Age” Feature
- 영상이 업로드된 시간에 따라 인기도가 크게 변함.
- 따라서 이를 반영하기 위해 “Example Age” feature 추가
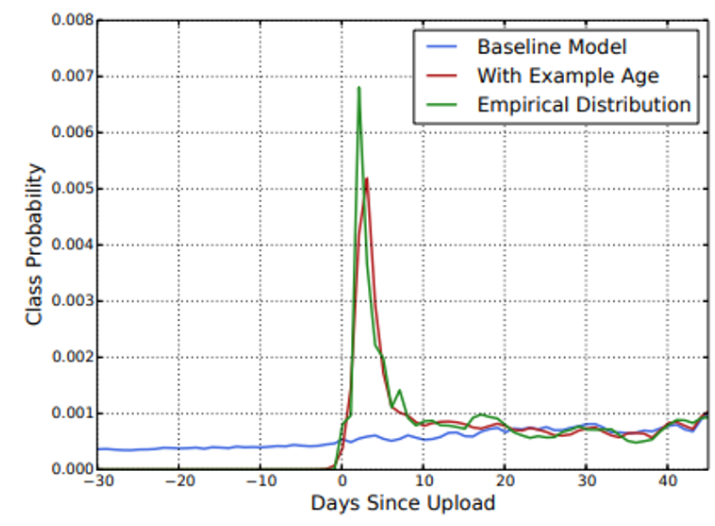
- Baseline은 모든 시간의 시청 확률 평균을 예측하고 있음
- 그러나 해당 feature를 추가한 모델은 업로드 직후 인기도가 높아지고, 이후 다시 낮아지는 경향을 잘 반영하고 있음
3.4. Label and Context Selection
- 추천 → “surrogate problem”
- 복잡하고 어려운 원본 문제를 더욱 간단하거나 다루기 쉬운 문제로 대체하여 해결하고자 함
- A/B 테스트 성과에 대해 online 실험은 괜찮지만, offline 실험으로는 성과를 정확히 알기 어렵다.
- A/B test 성과를 올리는데 도움을 준 요소들
-
유튜브 추천 탭이 아닌 다른 부분에서 시청한 영상을 반영해 새로운 추천 결과 만들기
-
유저마다 고정된 수의 학습 데이터 생성
- 일관성 있는 경험 제공 (모든 유저 loss function 동등하게 반영)
- 소수의 헤비 유저(영상을 이것저것 많이 보는)가 loss function 지배하는 상황 방지
-
특정 정보는 모델 반영하지 않기
- 유저 검색 이력의 순서 → 모델에 알려주지 않는 것 유리
- 검색어는 순서 없이 bag of tokens 방식으로 처리
-
랜덤하게 추출한 시청 이력이 아닌, 주어진 시청 이력의 다음 시청 이력 예측하기
- 시청 이력은 비대칭적
- ex. 시리즈 영상은 순서대로 시청, 유명한 가수부터 시작해 해당 장르의 인디 가수 영상순으로 시청 등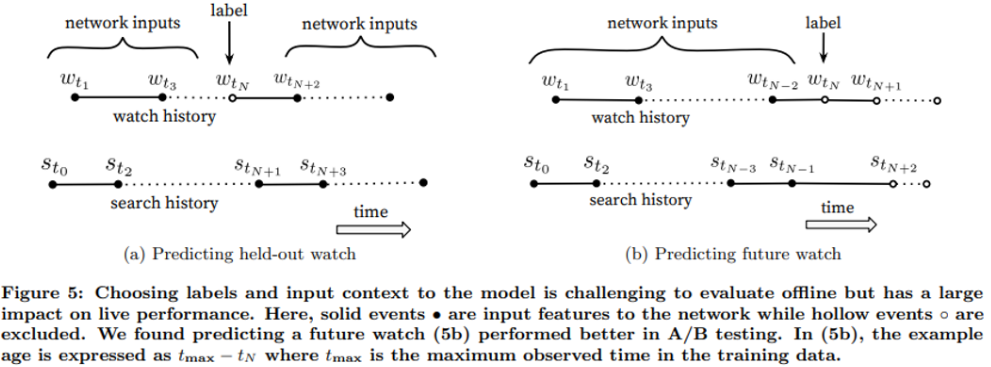
-
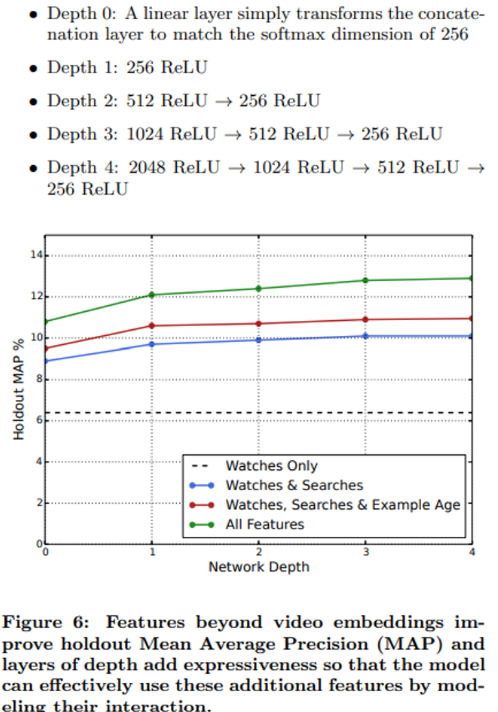
3.5. Experiments with Features and Depth
- feature와 Depth 추가하는 것 모델 성능 향상 도움(Precision)
- 실험
- 1M videos 와 1M search tokens → 256차원의 임베딩으로 매핑
- 최대 유저별 최근에 본 비디오 50개, 최근에 검색한 검색어 50개로 한정
- softmax layer : 다항 분포형태로 1M개의 비디오 클래스에 대해 256차원으로 출력
- ReLU → 첫 layer 가장 넓고, 다음 layer부터 절반씩 줄여가는 tower 구조
- 1M videos 와 1M search tokens → 256차원의 임베딩으로 매핑
4. Ranking
앞선 과정에서 생성한 후보군(높은 확률로 클릭할) 영상들을 모두 볼 수도 있지만, 특정 썸네일에 따라 안 누를 수도 있기에, 랭킹모델을 통해 수십개로 줄임
- Ranking 모델 부분에서는 오직 수백개 정도의 비디오 영상만을 다루기 때문에, 더 많은 feature들 활용 가능
- 서로 다른 Candidate Generation 모델의 결과물을 앙상블할 때 Ranking 모델을 활용가능
- logistic regression으로 노출(impression) 대비 시청 시간을 예측하고, 이 점수대로 정렬
- 클릭률을 예측하면 낚시성 영상을 많이 추천하게 되어, 클릭이 아닌 시청 시간을 예측
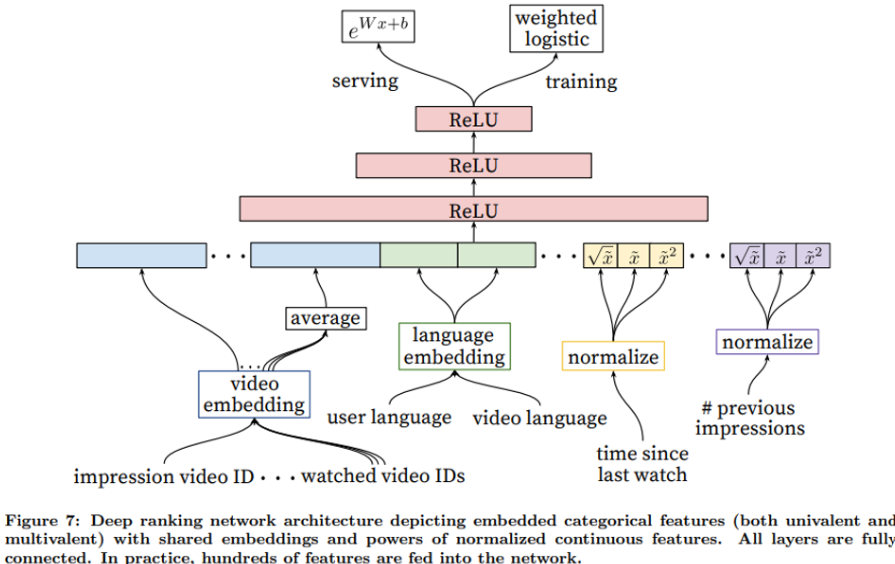
4.1. Feature Representation
- 현재 feature들은 categorical and continous / ordinal feature들로 구성되어 있다.
- univalent categorical feature : video ID
- multivalent feature : bag(집합) of the last N videos IDs
4.1.1. Feature Engineering
- 유저와 해당 비디오 또는 유사 비디오와의 과거 이력이 모델 일반화 능력에 도움
- 예시 : 이 유저가 이 채널의 비디오를 몇 개나 보았는가? 유저가 이 주제에 대한 비디오를 언제 마지막으로 보았는가? 등
- Candidate Generation 모델의 결과를 피쳐로 사용하는 것도 좋음
- 과거 해당 비디오의 노출 빈도 피쳐도 “이탈(churn)” 개념을 학습하는 데 좋음
- 최근에 유저에게 이 비디오가 추천되어 노출되었지만 시청하지 않았다면, 이 비디오를 더 이상 추천하지 않을 수 있다.
4.1.2. Embedding Categorical Features
- sparse한 범주형 feature들 → 각각 dense prepresentations 임베딩으로 매핑
- 한 feature의 범주 개수 너무 많으면(cardinality가 너무 크면) top N개의 임베딩만 만들고, 이외에는 Out-of-vocabulary, zero 임베딩으로 처리
- 범주형 피쳐의 임베딩 평균을 모델에 전달
- 같은 ID 범주형 feature는 같은 임베딩 공유, 그러나 임베딩이 전달된 layer는 다르므로 각 layer에서 같은 임베딩도 다르게 처리
- 예시 : 32차원 공간에 임베딩된 100만 개의 ID는 2048개의 유닛을 가진 완전 연결 계층보다 7배 더 많은 파라미터를 가짐.
- 설명
- "32차원 공간에 임베딩된 100만 개의 ID"라는 표현은, 100만 개의 각기 다른 ID가 모두 32차원의 벡터로 변환되어 표현된다는 의미입니다. 즉, 각 ID는 32개의 값으로 구성된 벡터로 표현됩니다.
- 이때, 32차원 벡터로 표현된 100만 개의 ID를 모두 관리하려면, 많은 수의 파라미터가 필요합니다. 여기서 "파라미터"란 모델이 학습하는 동안 최적화되는 변수들을 말합니다. 이 경우, 각 차원마다 100만 개의 값을 가지므로 총 32백만 개의 파라미터가 필요합니다.
- 반면에, "2048개의 유닛을 가진 완전 연결 계층"은 각 유닛이 입력과 연결되어 있으며, 이 연결을 통해 데이터의 특성을 학습합니다. 완전 연결 계층에서는 유닛의 수에 비례하여 파라미터의 수가 결정됩니다. 따라서 2048개의 유닛을 가진 계층은 2048개의 파라미터를 가지게 됩니다.
- 이 비교에서, 32차원에 임베딩된 100만 개의 ID를 사용하는 것이 2048개의 유닛을 가진 완전 연결 계층보다 약 7배 더 많은 파라미터를 필요로 한다는 것을 알 수 있습니다.
- "32차원 공간에 임베딩된 100만 개의 ID"라는 표현은, 100만 개의 각기 다른 ID가 모두 32차원의 벡터로 변환되어 표현된다는 의미입니다. 즉, 각 ID는 32개의 값으로 구성된 벡터로 표현됩니다.
4.1.3. Normalizing Continuous Features
- continuous feature들 적절히 정규화하는 것이 수렴에 매우 중요 !!
- 분포 를 가진 연속 특성 는 누적 분포를 사용하여 [0,1) 범위에 동등하게 분포되도록 값 scaling 진행 로 정규화
- 정규화한 continuous featur들은 뿐만 아니라, 이들의 제곱과 제곱근도 추가로 입력 사용
4.2. Modeling Expected Watch Time
💡 목표**positive든 negative 데이터든 데이터가 주어졌을 때, 시청 시간을 예측하는 것 !!**
1. positive data : 유저에게 노출된 비디오가 클릭된 경우
2. negative data : 유저에게 노출된 비디오가 클릭되지 않은 경우
- weighted logistic regression을 활용해 시청 시간을 예측함
- Cross - Entropy loss 사용
- positive data : 시청 시간으로 weight 줌
- negative data : 모두 unit weight 부여
- 따라서 logistic regression으로 학습되는 odds 형태
- N : 학습 데이터 개수
- k : positive data 개수
- : i번째 데이터 시청 시간
- positive 데이터 개수가 적다는 가정하에, 학습되는 odds → 에 근사
- : 클릭 확률, : 시청 시간의 기댓값
- 값은 작으므로 이는 다시 에 근사하는 것과 같다.
4.3. Experiments with Hidden Layers
- 만약 점수에 대해서 positive data < negative data일 경우, positive 데이터의 시청 시간 만큼 틀린 것으로 간주(잘못 에측)
- metric : 유저별 전체 시청 시간 대비, 틀린 시청 시간의 비율
- hidden layer의 size 및 depth 증가시키면 성능 올라감
- 그러나 그만큼 inference에 사용되는 CPU(?) 시간 길어짐
- 정규화된 연속형 피쳐를 이 피쳐들의 제곱값 없이 쓰면 loss 0.2% 증가
- positive, negative 데이터 똑같이 weight주면 loss 4.1% 증가
💡 유튜브의 추천 시스템 모델 구성(2개)5. Conclusions
1. Candidate Generation
2. Ranking
<딥러닝 Collaborative Filtering을 사용하여 여러 이질적인 피쳐를 한 번에 반영 용이>
<Candidate Generation 부분에선 추천을 미래의 시청 내역 분류 과제로 치환>
<Ranking 부분에선 시청 시간 예측 과제를 수행>

Time Series Analysis, Artifical Intelligence