IDGenRec: LLM-RecSys Alignment with Textual ID Learning(2024.03) - 논문리뷰
논문 링크 : https://arxiv.org/abs/2403.19021
추천시스템 관련한 논문들을 접하던 중 LLM을 추천 혹은 검색시스템에 접목하여 ncsoft 등 여러 빅테크 기업에서도 이를 활용하고 있다. 따라서 LLM을 활용한 여러 방법론을 접목시켜서 추천 성능을 높이는 연구들을 리뷰하고자 한다. 이후에도 계속 LLMRec 관련한 널리 알려진 P5, M6 모델, LlamaRec 등에 대한 내용들도 리뷰할 예정이다.
그럼 IDGenRec 모델은 어떻게 활용되는지 살펴보자.
0. Abstract
핵심만 살펴보면 기존 이산적 ID 인코딩 방식을 text ID 방식으로 표현함으로써 더 풍부한 item의 representation을 반영해서 추천 성능을 올리는 것이다. IDGenRec 프레임워크는 text ID 방식으로 만들어준다. 자세히 살펴보면,
- 문제 정의
- 항목을 단순한 ID 취급하는 기존 방식은 각 항목의 개별적인 특성이나 상호작용 제대로 반영 x → 추천 성능 저하
- 해결 방법
- IDGenRec 프레임워크 제안
- 항목 간의 연관성을 보다 정교하게 모델링함으로써 추천 성능 개선
- IDGenRec 프레임워크 제안
- 주요 과정
- 항목의 정교한 표현 생성
- 다양한 데이터 소스 통합
- 생성적 모델 적용
- 시퀀스 예측 강화
1. Introduction
- 기존 추천시스템 문제점
- 단순한 ID based 접근법 (영화 A → ID 123, 영화 B → ID 456)
- 복잡한 관계 반영 x
- 부족한 항목 특성 반영
- 상품 text, image, review 등 다양한 데이터 source 활용 x
- 단순한 ID based 접근법 (영화 A → ID 123, 영화 B → ID 456)
- Solution 제안 → IDGenRec 프레임워크
- 정교한 항목 표현 생성
- ex) 한 영화에 대한 text 설명, 포스터 이미지, 사용자 리뷰 모두 사용함으로써 풍부한 항목 표현
- 생성적 모델 사용
- 이를 통해 항목의 잠재적 특성 학습, 이를 바탕으로 사용자가 관심 가질 만한 새로운 항목 예측
- 시퀀스 예측 강화
- 사용자가 이전에 본 상호작용 항목 데이터 반영
주요 LLM 기반 추천 모델들의 특징 비교

- 정교한 항목 표현 생성
- foundation 모델이 아닌 이유 → OOV token 사용하기 때문에
- Gen 모델 아닌 이유 → 인코더 기반
IDGen 과정에 대한 Figure
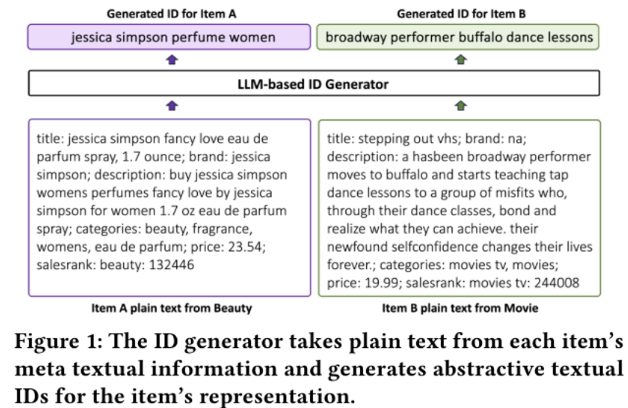
- 메타 텍스트 정보들을 바탕으로 LLM 기반의 ID Generator에 입력
- 이 Generator는 각 항목의 특성 정보를 기반으로 abstract한 Text ID 생성
2. Approach
ID Generator
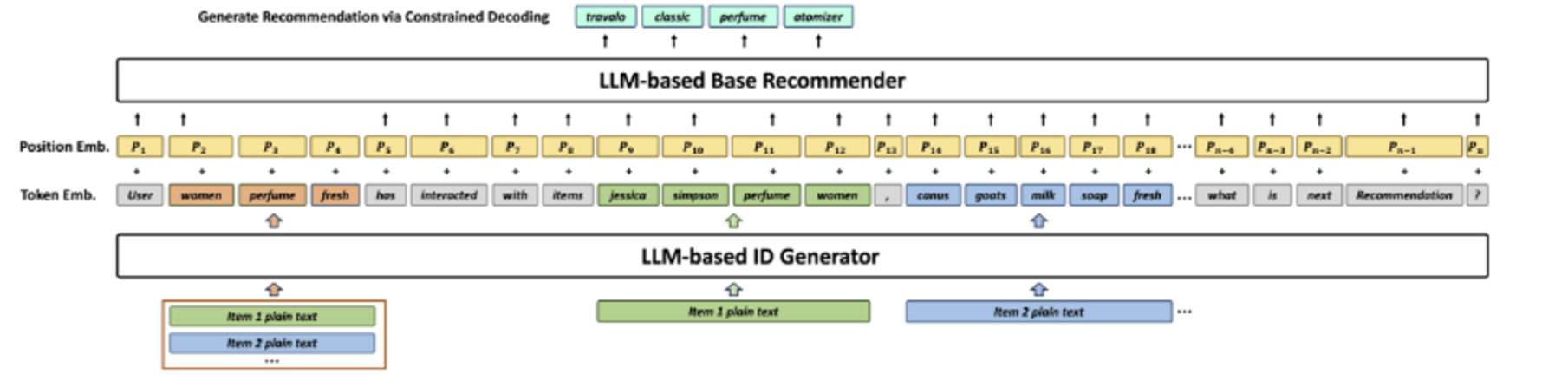
Gen 추천 워크플로우 figure
- 과정
- ID Generator를 통해 plain text → text ID로 변환
- 토큰 임베딩 진행 (각 단어 → 임베딩 벡터로 변환)
- 위치 임베딩과 토큰 임베딩 concat
- 상호작용 시퀀스 캡처 (ex user has interacted with item jessica simpson perfume ..)
- constrained Decoding 방식을 통한 최종 추천 항목 ID 생성 (동일하게 text ID 형태)
3. Experiment
- standard evaluation of seqeuntial recommendation
→ baseline들과 비교 - zero-shot
- 두 가지 데이터셋 그룹 사용 (아마존 데이터 기반)
- Pre-training datsets → the Amazon review
dataset, containing various domains,
- Testing datasets → both Amazon review datasets (intra-platform) and the
Yelp dataset (inter-platform).
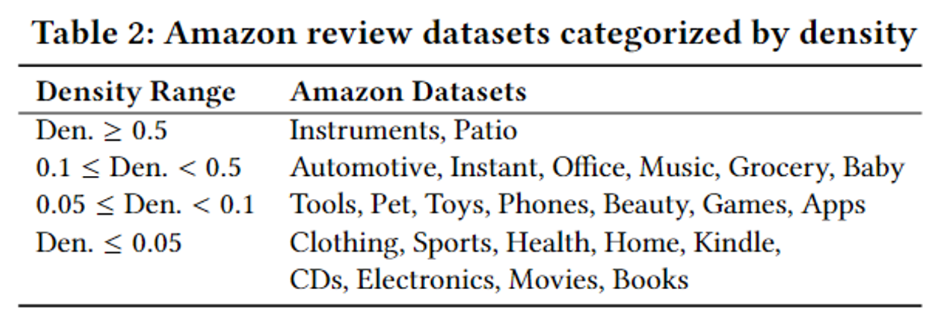
-> dataset의 density 정도
1. Pretraining dataset에 대한 실험결과
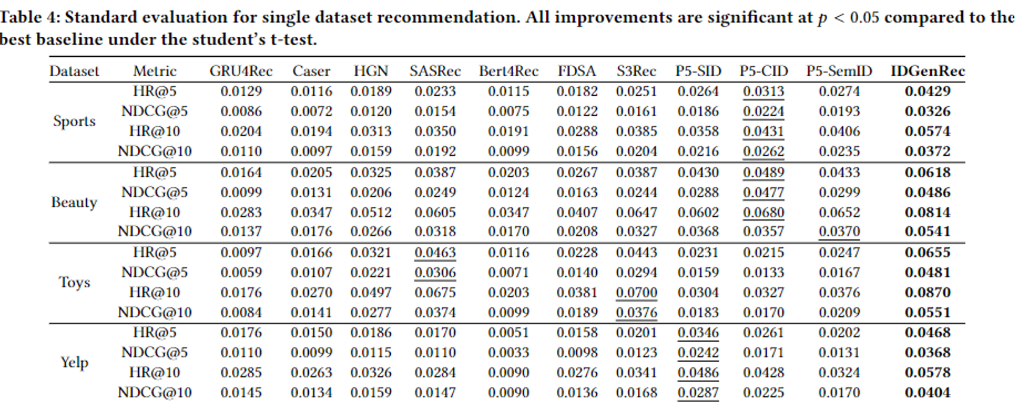
-> 기존 P5 모델들과 baseline들에 비해 IDGen을 사용한 모델의 성능이 높게 나옴.
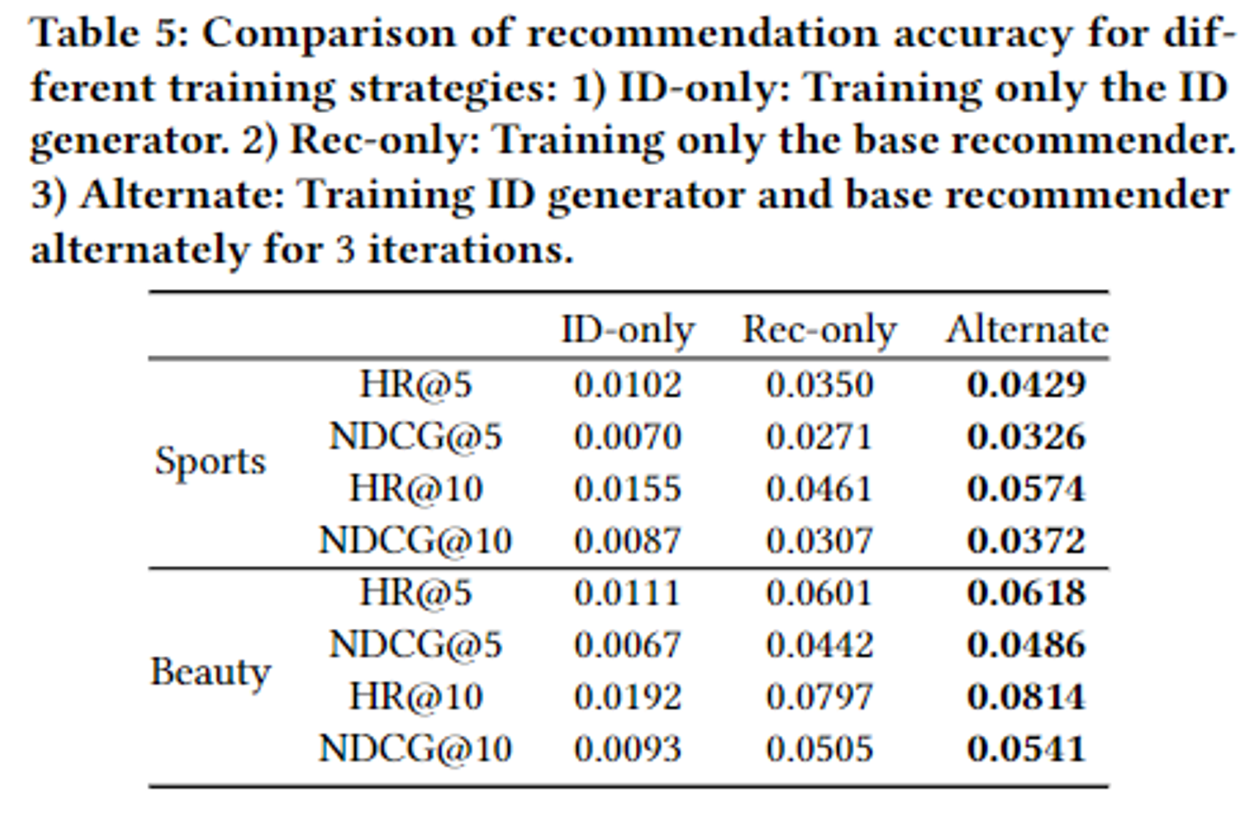
-> Alternative Learning 진행
총 3가지 case 존재
1. userID만 학습
2. item만 학습
3. 두 개 Alternate하게 학습
- user ID만을 사용했을 때는 성능 좋지 않지만,
- ItemID만 사용할 때, 그리고 userID + itemID 동시에 고려할 때 성능 잘 나옴.
2. Zero-Shot 실험결과
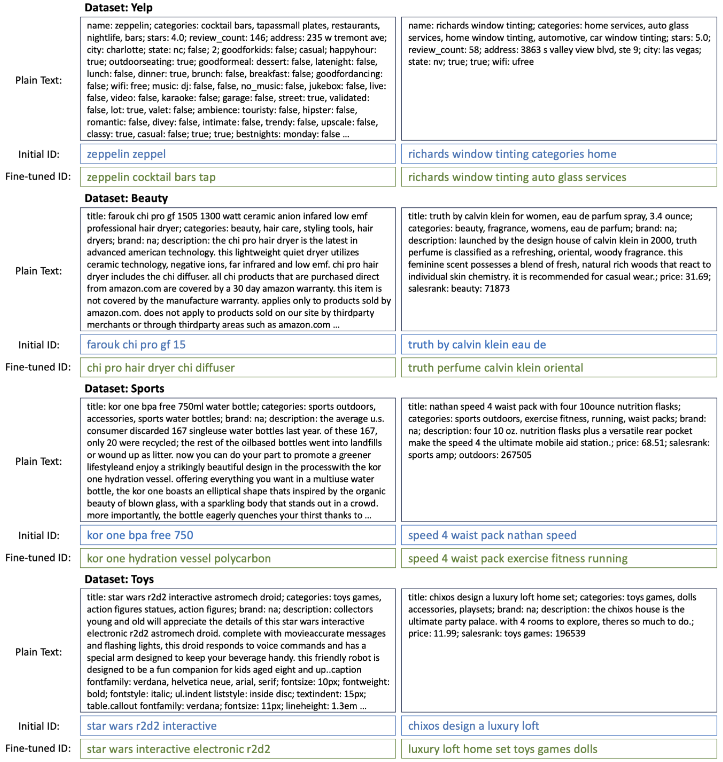
-> Yelp dataset 활용 : Fine-Tuning된 case가 원 데이터에 대해서 더 자세한 ID를 생성하는 것을 확인할 수 있다.
4. Related Work
- LLM-based Discriminative Recommendation
- 사용 목적: 사용자 및 아이템의 컨텍스트 정보 활용
- 중요한 연구: BERT 사용 다수
- 핵심 아이디어: 사용자와 아이템의 임베딩 학습과 순위 계산에 통합
- LLM-based Generative Recommendation
- 사용 목적: 아이템을 직접적으로 텍스트로 생성
- 주요 연구:
- Geng et al. (2022): T5 기반의 generative recommendation 시스템, 5가지 추천 작업에서 기존 방법들과 비교
- [9]: 시각적 특징을 고려한 멀티모달 추천 시스템
- [14]: 인덱싱 아이템 ID 메서드가 성능에 미치는 영향 연구
- 한계점: 숫자 ID, OOV 토큰 사용으로 풍부한 텍스트 정보 활용 어려움
- 제안된 대안 연구
- 본 연구가 독자적으로 제안한 방법:
- 문맥 정보를 활용한 의미론적 아이템 ID 생성
- 다양한 플랫폼에서 Zero-shot 추천 가능
- 본 연구가 독자적으로 제안한 방법:
- 기타 연구
- 학습이나 Fine-Tuning 없이 LLM 활용 추천 연구:
- 초점: 프롬프트 디자인
- 주요 연구: ChatGPT의 추천 시나리오 성능 평가
- 학습이나 Fine-Tuning 없이 LLM 활용 추천 연구:
5. Conclusion
- 텍스트 ID의 중요성
- text id → 플랫폼 구애 x 받지 않아 여러 플랫폼에서 동일한 항목을 쉽게 식별하고 공유 가능
- 항목의 특성 더 잘 반영함
- zero shot 추천 시나리오에서의 성능 향상
- zero shot, 새로운 dataset을 학습하지 않고도 강력한 성능 보여줌 → 다양한 데이터 상황에서 유연하게 작동
- 유사한 항목 식별 능력이 뛰어남.
- 이 텍스트ID는 이미지, 리뷰 등 다양한 데이터를 통합하여 멀티모달 데이터를 활용하기에 복합적인 특성을을 학습할 수 있어, 더욱 강력한 추천을 제공할 수 있다.

Time Series Analysis, Artifical Intelligence