[논문 리뷰] A framework for detecting unknown defect patterns on wafer bin maps using active learning (2025 ESWA)
Motivation
1. 기존 WBM 결함 패턴 분류 연구는 대부분 closed-set 가정에 기반한 지도학습 접근이었으며, 실제 제조 환경에서 새롭게 발생하는 unknown defect pattern을 효과적으로 탐지하지 못한다는 한계 존재함
2. unknown 패턴이 테스트 또는 운영 환경에 등장하면, 기존 분류기는 이를 알려진 클래스 중 하나로 오분류하여 전체 분류 성능을 저하시킬 수 있으며, 이는 수율 관리와 비용 측면에서 심각한 문제를 초래함
3. 따라서 본 논문은 known 패턴에 대한 높은 분류 성능을 유지하면서도 unknown 패턴을 탐지하고, 이를 active learning과 결합해 지속적으로 모델을 업데이트할 수 있는 통합 프레임워크를 제안
0. Abstract
-
반도체 제조에서 Wafer Bin Map(WBM)의 결함 패턴을 탐지·분류하고 결함의 원인을 규명하는 일이 품질 관리에 중요하다고 서술
-
최근 딥러닝 기반 방법이 다수 적용되었으나, 분류 성능 저하, 라벨링 한계, 새로운 결함 패턴의 탐지·학습 불가라는 한계를 가진다고 지적
-
기존 연구가 “정확도/속도” 최적화에 치우쳐 unknown defect pattern 탐지와 분류를 우선순위로 두지 않았다고 문제를 정의
-
위 내용을 해결하기 위해 다음의 파이프라인 제안
- known/unknown을 가르는 One-Class SVM 기반 이상 탐지기 설계
- known 패턴은 ImageNet1K로 사전학습된 ResNet50을 transfer learning으로 미세조정해 세부 클래스를 분류
- unknown 패턴은 DBSCAN 클러스터링으로 새 라벨을 부여하고, active learning으로 분류기와 탐지기를 지속 업데이트
-
WM-811K 데이터셋 실험으로 unknown 패턴 탐지와 known 패턴 분류 성능 유지가 가능함을 검증했다고 주장
-
실제 산업 데이터에서 WM-811K에 없는 “Eye Defect Pattern”을 unknown으로 두고 적용 가능성을 보였다고 결론
1. Introduction
1.1 Problem Define
-
반도체 산업이 고집적/나노스케일 공정으로 진화하면서 제조 비용과 결함 리스크가 증가
-
이전에 없던 unknown, mixed, complex defect가 발생하면 수율 저하 및 공정 안정성 약화를 유발
-
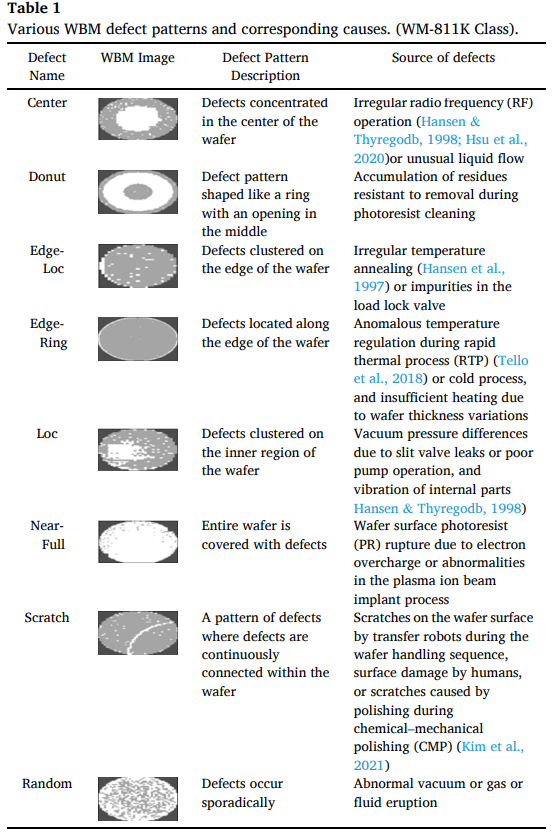
WBM은 전기적 die test/sort 결과로부터 생성되며, 불량 칩의 공간 분포를 시각적으로 제공한다고 정의 (Table 1)
-
WBM 결함 패턴은 결함의 root cause와 밀접히 연관되어 있어, 패턴 분류 및 라벨링이 공정 원인 추적에 도움이 된다고 강조
- 그러나 unknown 패턴의 정확한 분류/라벨링은 여전히 공정 엔지니어의 경험, 직관, 시각 검사에 크게 의존한다고 문제를 제기
-
기존 접근 한계
-
다수의 연구가 supervised learning 기반이며, 모든 라벨이 사전에 정의된 closed-set 가정
-
supervised는 Softmax 등 최종 분류층이 “기존 라벨 분포 기반 추론”을 수행하기 때문에 정의되지 않은 결함을 구분하지 못한다고 지적
-
unsupervised는 unknown을 볼 수 있으나, 많은 샘플을 사람이 확인해야 하고 분류 성능이 supervised보다 낮을 수 있다고 정리
-
semi-supervised는 라벨 효율은 개선하지만, unknown 패턴에서 정확한 라벨 부여가 어렵고 탐지 능력이 떨어질 수 있다고 서술
-
1.2 Contribution
-
목표는 known 패턴에 대해 높은 분류 정확도를 유지하면서 unknown 패턴을 올바르게 탐지하는 “종합 프레임워크”를 제안
-
구성은 One-Class SVM(known/unknown), ResNet50 transfer learning(known class 분류), DBSCAN(unknown clustering), active learning 기반 업데이트로 요약
-
WM-811K와 실제 산업 데이터로 효과를 검증
2. Related works
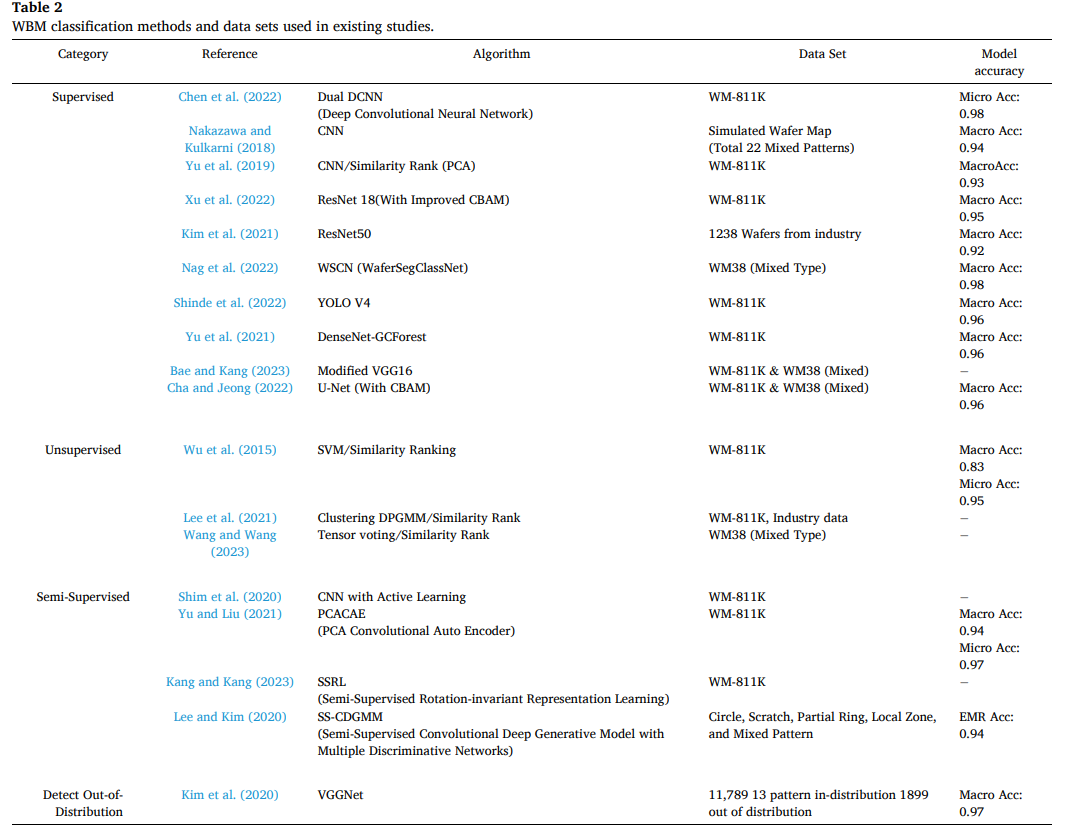
해당 논문은 관련연구를 supervised, unsupervised, semi-supervised, active learning 관점으로 정리했고, “unknown pattern을 다루지 못한다”는 공통 한계를 중심으로 서술
2.1 Supervised learning
-
종류: CNN, Dual DCNN, U-Net+CBAM, 개선형 CBAM, WSCN(분류+세그멘테이션), YOLO 기반 위치 예측
-
목표: 정확도 향상, 모델 경량화, 학습 시간 단축
-
한계: 정답 라벨과 데이터 균형이 필요하고, 실제 제조 환경에서는 샘플링 검사로 인해 데이터가 불균형·불완전해 라벨 확보가 어렵다고 지적
-
따라서 unknown 패턴이 발생하면 탐지하지 못해 분류기를 지속 재학습해야 하며 비용이 증가하는 문제 발생
2.2 Unsupervised learning
-
종류: SVM 기반 초기 분류 후 유사도 랭킹, 극좌표 변환+DPGMM 기반 유사도 랭킹, 텐서 보팅 기반 유사도 비교 등의 접근
-
한계: unknown 패턴을 시각화/발견할 수 있으나, 라벨 기반 학습이 아니라 분류 정확도와 속도가 떨어지고, 결과 해석을 위해 많은 수작업 검토가 필요함
2.3 Semi-supervised learning
-
종류: 라벨이 제한된 상황에서 active learning, 회전 불변 표현 학습, PCA 기반 autoencoder, mixed-type을 multi-label로 바꾸는 방법
-
한계: 기존 라벨과의 유사성에 의존하거나, 발생 가능한 패턴 유형/분포를 사전에 가정하는 경우가 많아 “완전히 새로운 패턴”을 식별하기 어렵다고 지적
- OOD(Out-of-distribution) 탐지 연구도 언급되었으나 관심 OOD 데이터가 함께 학습되어야 하는 제약 존재
2.4 Active learning
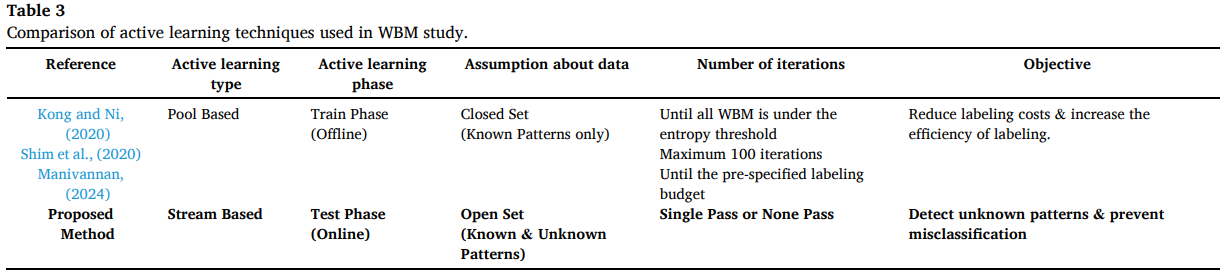
본 연구는 unknown 패턴이 공정에서 계속 생길 수 있다는 문제를 반영하여 stream-based를 채택했고, 제조 환경 특성(로트 단위, 심한 imbalance)을 고려해 window-based buffer로 데이터를 모아 처리하는 online active learning을 제안
- 종류: pool-based와 stream-based active learning
- pool-based: 오프라인에서 큰 unlabeled pool 중 정보량 높은 샘플을 고르는 방식이며 closed-set 한계
- stream-based: 데이터가 흐르며 즉시 라벨 쿼리 여부를 결정하고 new class도 처리 가능하나, 순차 처리로 선택 품질이 낮을 수 있음
3. Proposed Method
프레임워크 4step으로 구성되어 있기에 이를 기준으로 각 subsection 별로 설명
1) unknown defect 탐지
2) known class 분류
3) unknown에 대한 unsupervised clustering
4) active learning
추가로, offline 학습(탐지기·분류기 학습)과 online 테스트(운영 중 unknown 수집 및 업데이트)로 구조 분리
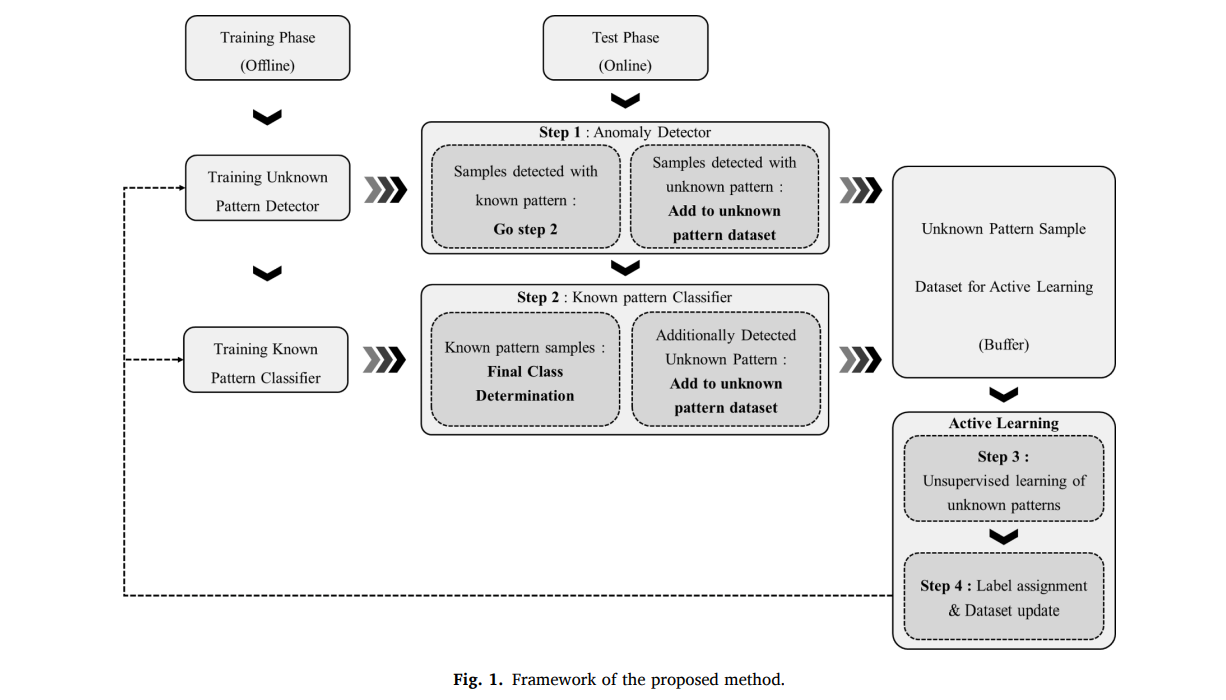
offline training과 online test, 그리고 unknown buffer와 active learning 업데이트 루프 과정
3.1 Step 1: detect unknown defect patterns
-
Step 1은 OSR(Open Set Recognition) 및 anomaly detection 관점으로, 운영 환경에서 들어오는 샘플을 known/unknown으로 binary classification 진행
-
목적: Step 2 분류기가 unknown을 known으로 오분류하여 성능이 무너지는 것을 최소화하는 것
-
따라서 “패턴의 상세 클래스”가 아니라 “known인지 unknown인지”만 결정
3.2 Step 2: classification of known pattern samples
- Step 2는 supervised learning 기반 분류기로 known class를 세부 클래스로 분류
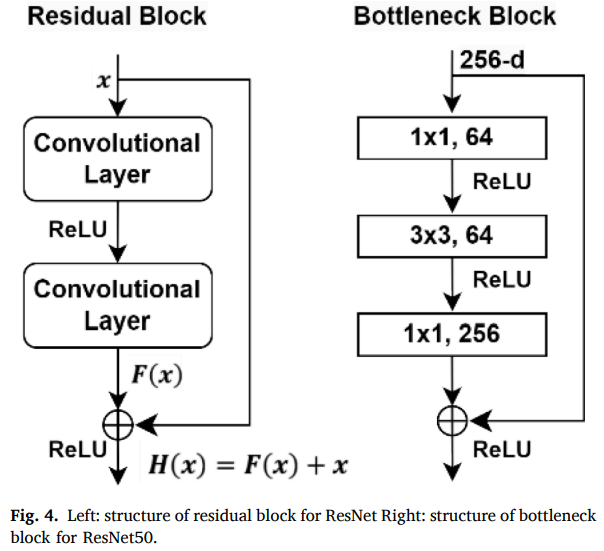
- backbone으로 ResNet, DenseNet, ViT, EfficientNet 등을 언급했으나, 본 연구 구현에서는 ResNet50 기반 pre-trained classifier를 구축

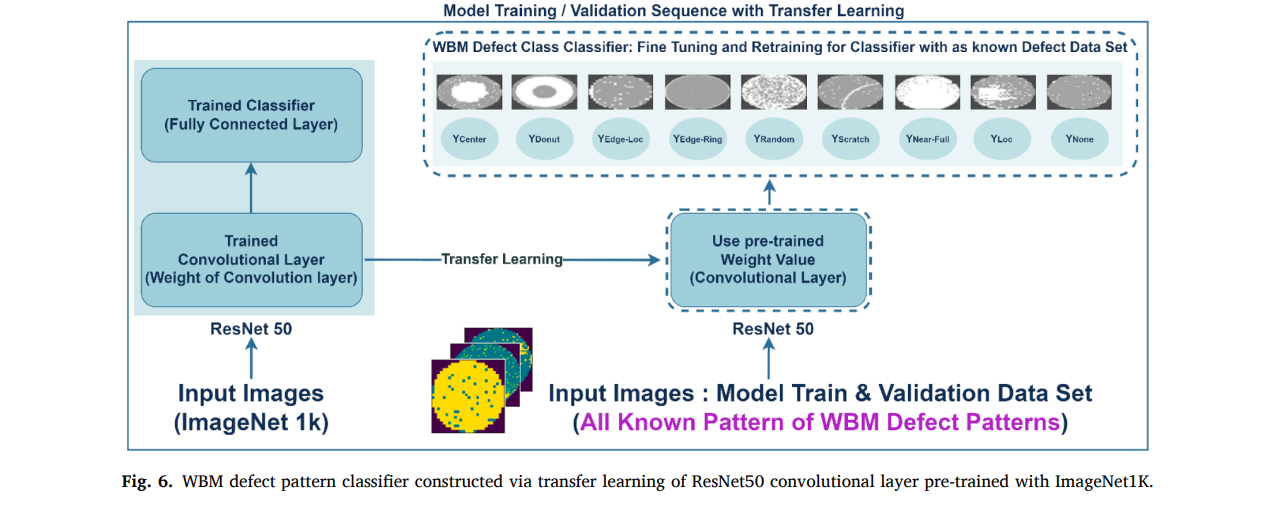
-
WM-811K 데이터의 severe imbalance 문제를 고려해, ImageNet1K로 사전학습된 ResNet50의 convolution layer 가중치를 활용하는 transfer learning을 적용 (Fig 5, 6에서도 pre trained model 구조와, transfer learning 방식에 대해서 설명)
-
convolution layer를 동결하지 않고 fine-tuning을 수행해 WBM 도메인에 적응하도록 함.
ResNet 구조 설명
-
ResNet의 residual block이 gradient vanishing을 완화하기 위한 skip connection 구조
-
ResNet50은 bottleneck 구조(1×1로 차원 축소, 3×3으로 학습력 유지, 1×1로 복원)를 사용해 파라미터 수를 줄이고 과적합을 완화
클래스별 최적 Threshold 기반 unknown 재판정
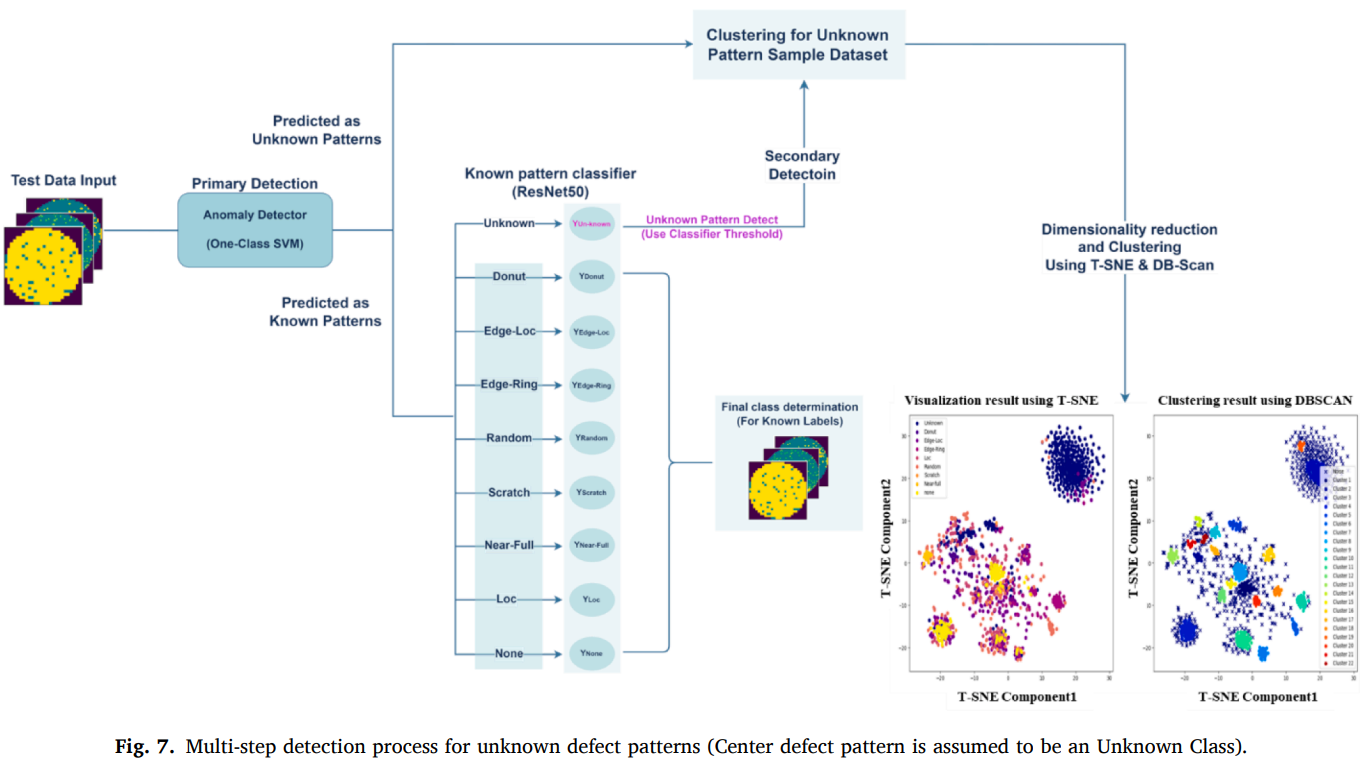
논문은 Step 1에서 unknown이 known으로 들어오는 경우를 고려했다고 서술했다.
이를 완화하기 위해 ResNet50 다중분류 과정에서 Unknown Defect Pattern Class를 개념적으로 도입하고, One-vs-All 방식으로 클래스별 threshold를 학습해 “어느 known 클래스도 임계값을 넘지 못하면 unknown으로 처리”하는 다단계 프로세스를 설계했다고 설명했다. (Fig. 7에서 핑크색 부분)
임계값 탐색은 Algorithm 1에 제시되어 있으며, 평가 지표로 precision을 사용

3.3 Step 3: unsupervised learning for unknown pattern samples
-
WBM은 80×80 형태이며, 고차원에서 클러스터링은 curse of dimensionality로 비효율적일 수 있다.
-
misclassified known 샘플과 true unknown 샘플을 구분하기 위해 차원 축소가 필요하다고 논문이 주장했다.
-
본 연구는 unknown으로 판정된 샘플에 대해 t-SNE로 차원 축소 및 시각화를 수행했다고 설명했다.
-
이후 여러 클러스터링 알고리즘을 비교했고, cluster proportion 지표로 “동일 결함이 동일 클러스터에 모이는 정도”를 정량화했다고 서술했다.
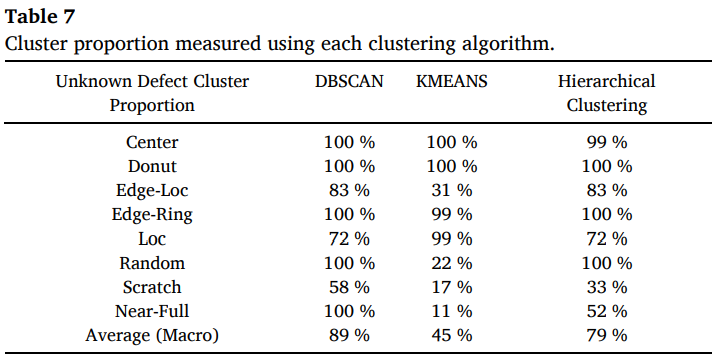
-
DBSCAN을 최종 선택한 이유는 (Fig. 7. visualization 부분)
(1) 클러스터 개수를 사전 지정할 필요가 없고,
(2) 비선형 클러스터 및 노이즈에 강하며,
(3) 반도체 환경에서 defect 수를 미리 알기 어렵다는 특성과 맞기 때문이다.
3.4 Step 4: Model update process based on active learning
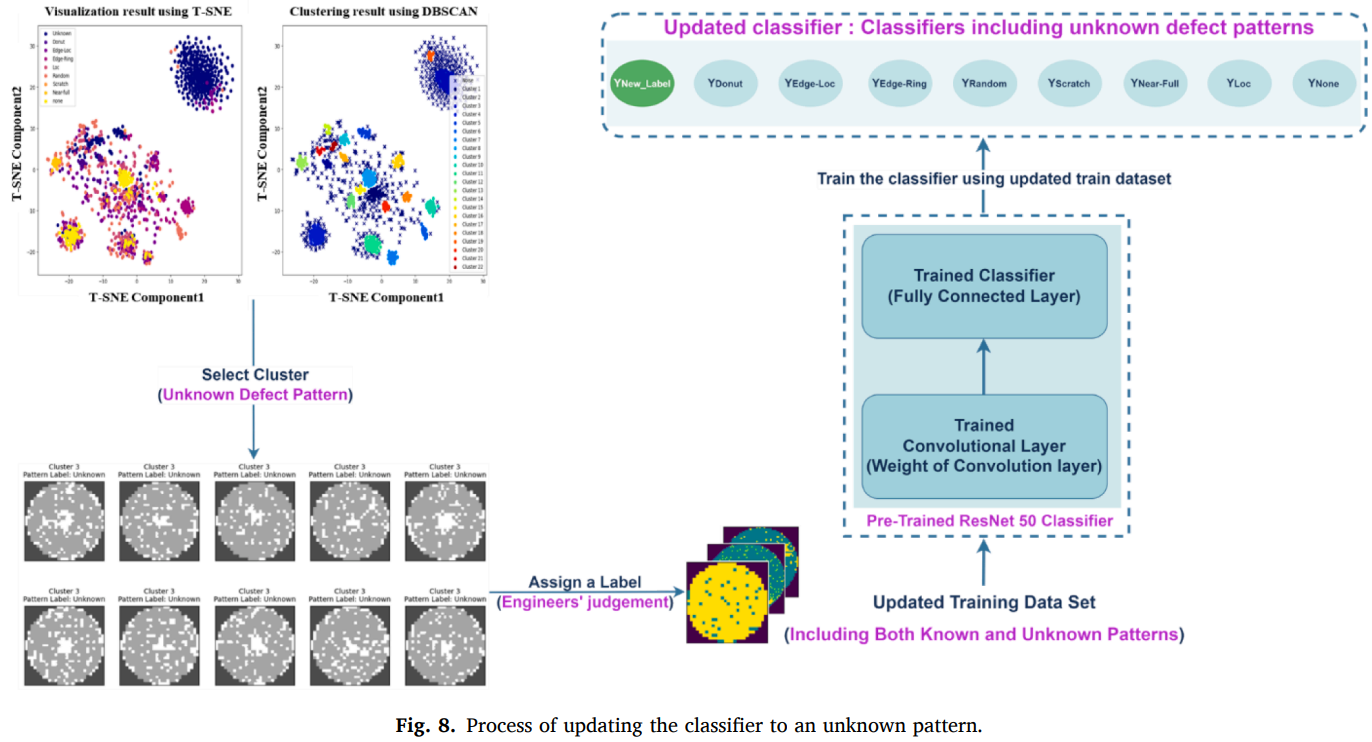
-
Step 4는 탐지기와 분류기를 unknown 패턴으로 update하는 단계 (Fig. 8. 업데이트 과정)
-
DBSCAN으로 군집화하여 엔지니어가 검토할 데이터의 노이즈와 양을 줄이고, HITL(Human-in-the-loop)로 최종적으로 unknown 패턴 존재와 라벨을 확정
-
unknown 패턴이 기존 패턴과 유사하거나 anomaly detector가 예측 가능하면 active learning만으로도 충분할 수 있으나, 패턴 정의가 추가로 필요하면 엔지니어 도메인 지식이 효과적
4. Case study 1: using WM-811K dataset
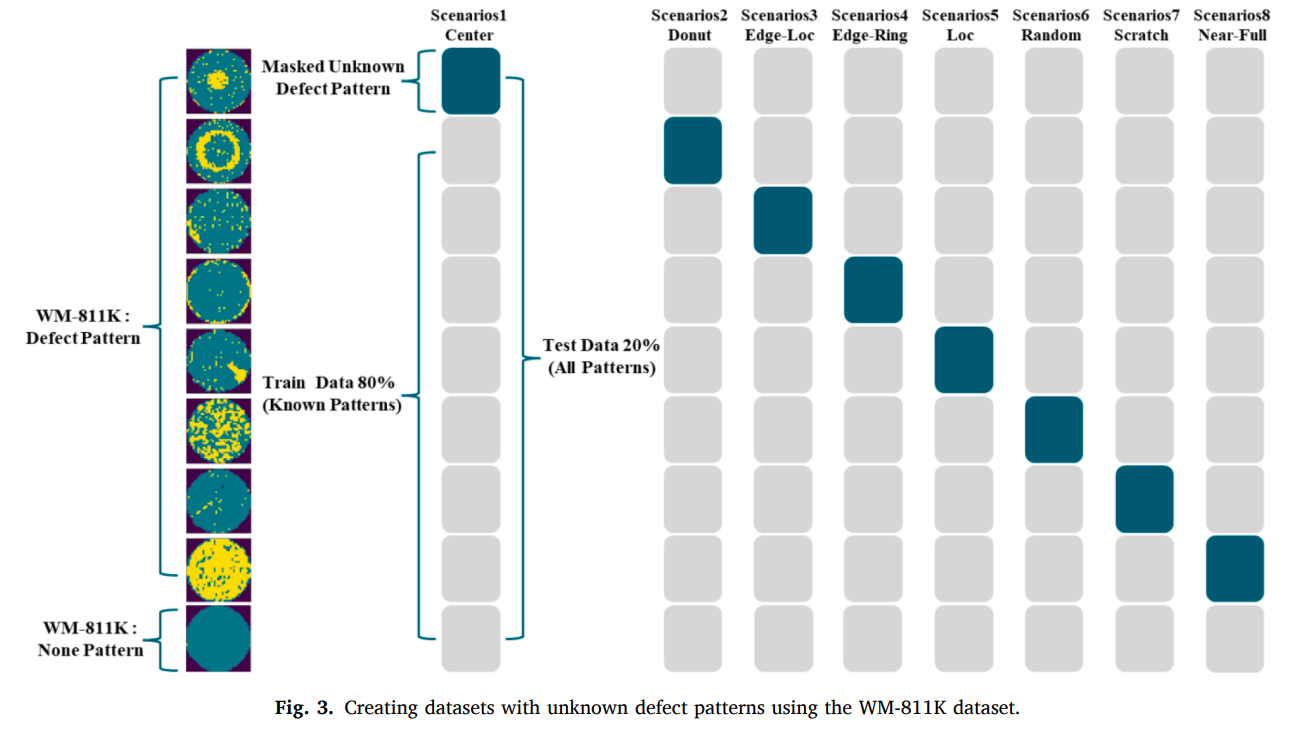
4.1 WM-811K dataset
-
실험 목표 및 구성
- WM-811K 오픈 데이터셋으로 제안 프레임워크의 각 모듈을 설명하고 성능 검증
- “Original classifier(업데이트 전)”와 “Updated classifier(active learning 후)”를 비교했고, 모든 결함을 미리 학습한 benchmark classifier와도 비교
-
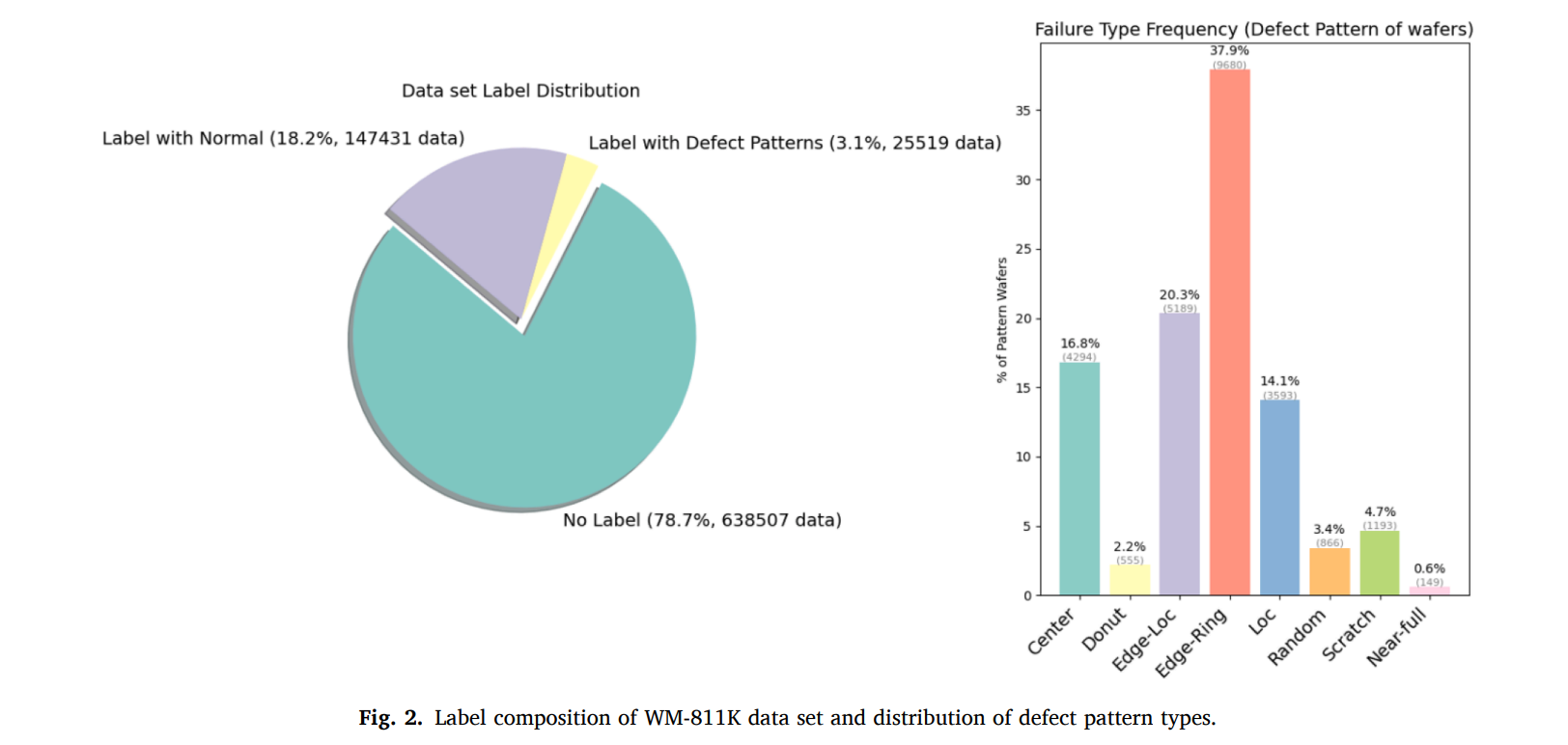
데이터 설명
- WM-811K는 총 811,457장의 WBM 이미지로 구성되며, 약 21.3%만 라벨이 있고 나머지 78.7%는 unlabeled
- 결함 패턴은 8종(Center, Donut, Edge-Loc, Edge-Ring, Loc, Random, Scratch, Near-Full)과 정상(None) 1종으로 구성
- unknown 패턴 시뮬레이션을 위해 8개 결함 패턴을 하나씩 “leave one out”으로 unknown 처리하여, 해당 패턴을 train/val에서 제외하고 test에는 포함하는 8개 시나리오
- None 패턴은 항상 known으로 가정해 모든 학습 시나리오에 포함
4.2 Step 1: detect unknown defect pattern samples (with One-Class SVM)
-
One-Class SVM을 abnormal detector로 선택했고, known defect를 하나의 클래스처럼 취급하여 “known defect 범위 밖이면 unknown”으로 판단하는 방식으로 설계
-
rbf 커널을 사용했고, NU 파라미터를 grid search로 0.10으로 설정

-
8개 시나리오 평균 macro accuracy가 85.4%
-
Center 87%, Donut 90%, Edge-Loc 81%, Edge-Ring 72%, Loc 83%, Random 91%, Scratch 88%, Near-Full 91%
-
특히, Edge-Ring 시나리오가 상대적으로 낮은 정확도를 보였다는 점이 수치로 확인되어 이는 Step 2/Step 4 보강이 필요한 현실적 근거로 작동함
4.3. Step 2: classification of known pattern samples (with ResNet50)
-
unknown 패턴이 test에 존재하면 supervised classifier는 이를 제대로 탐지하지 못해 오분류가 발생하고 성능이 저하
-
Table 6에서 Step 4 적용 전(original classifier) 성능을 제시한 것을 봤을 때, macro accuracy가 약 0.90, 평균 F1-score가 0.83임을 확인할 수 있다.
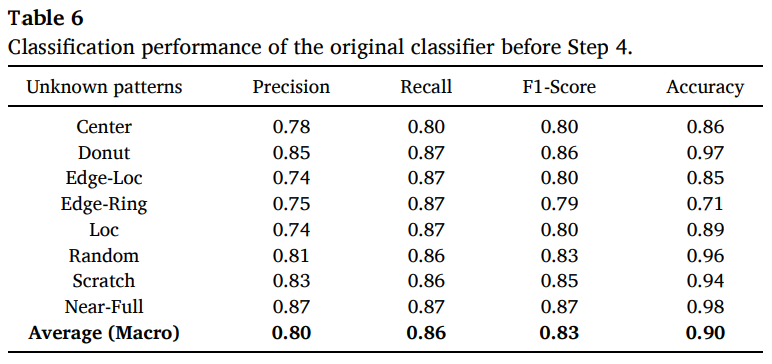
- 이 결과는 “unknown을 처리하지 않으면 분류기가 잘 학습된 것처럼 보이더라도 실제 운영에서는 성능이 무너질 수 있다”는 논문의 문제의식을 수치로 뒷받침한다.
4.4 Step 3: unsupervised learning for unknown pattern samples
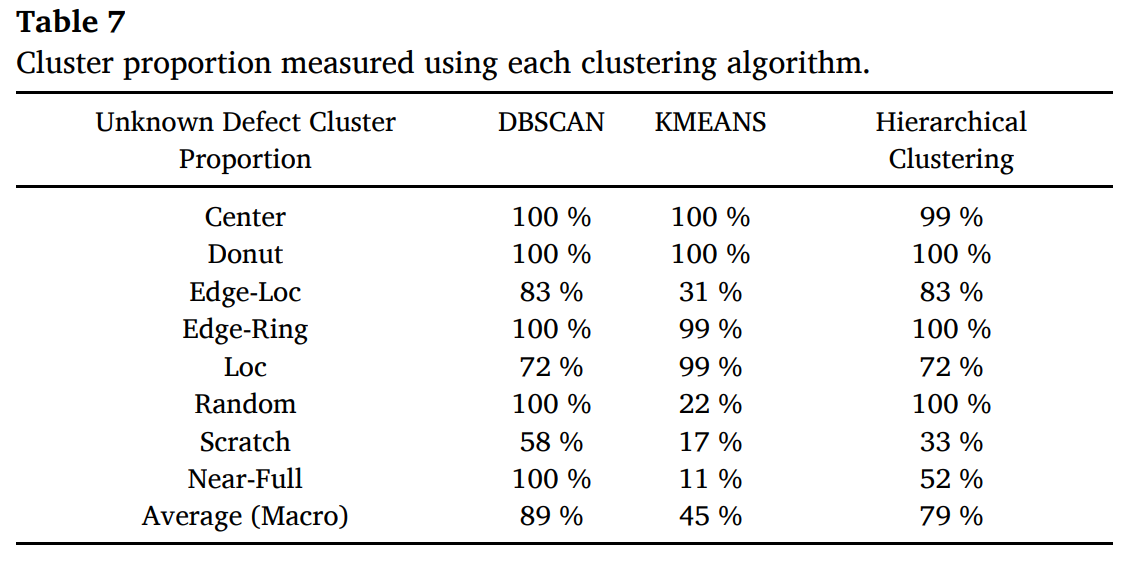
-
t-SNE를 사용해 unknown 후보 샘플을 저차원으로 임베딩하고 시각화
-
여러 클러스터링 알고리즘을 적용해 cluster proportion으로 비교했으며, Table 7에서 DBSCAN이 macro 89%로 가장 우수
-
KMEANS는 유사한 패턴(Edge-Loc, Loc, Scratch 등)에서 성능이 낮은 것을 볼 수 있고, hierarchical clustering은 성능이 유사할 수 있으나 패턴별 threshold 지정이 필요하다.
-
따라서 DBSCAN을 선택
4.5. Step 4: Model update process based on active learning
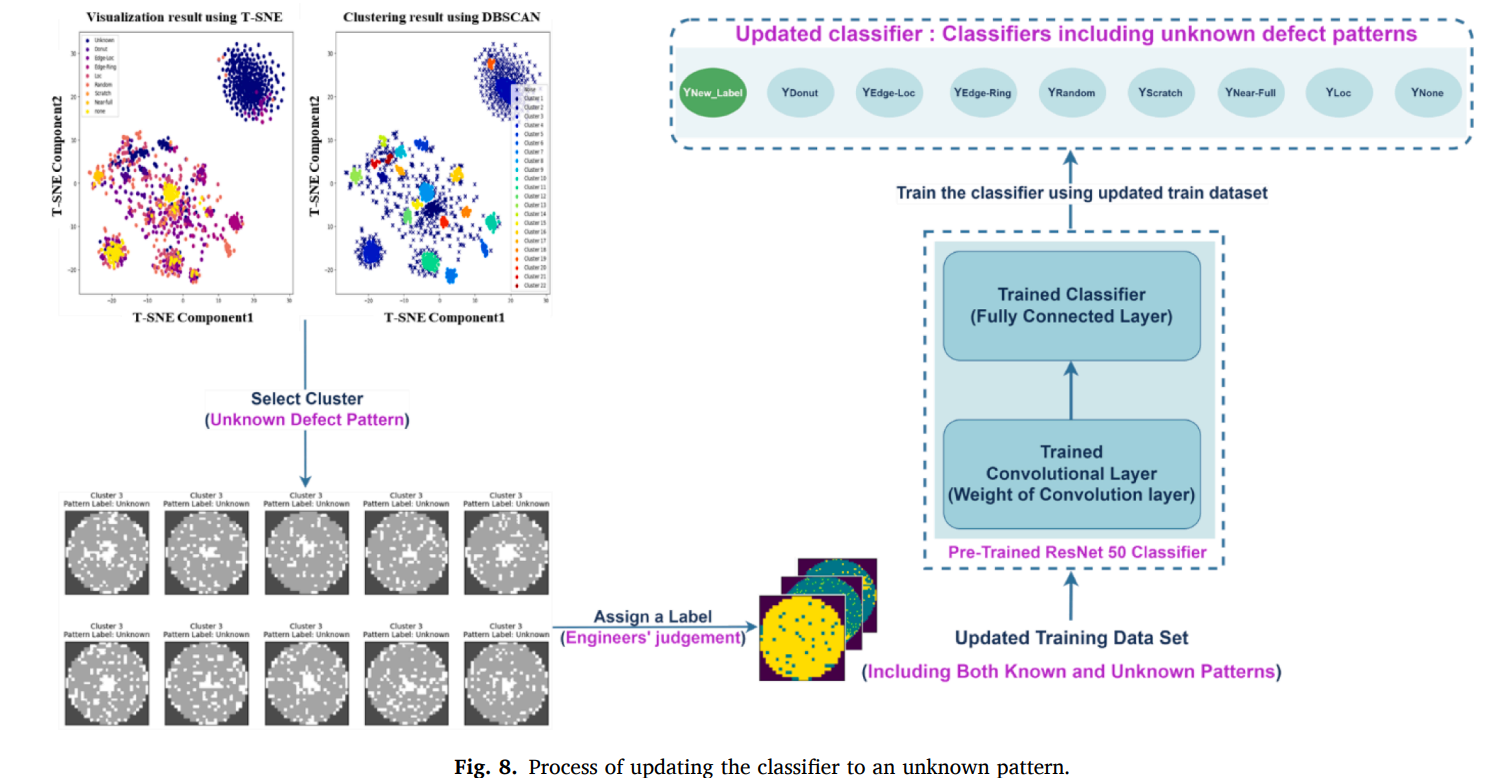
- DBSCAN 군집화 → 엔지니어 라벨링(HITL) → 업데이트 학습으로 분류기를 unknown 클래스까지 포함해 재학습하는 과정
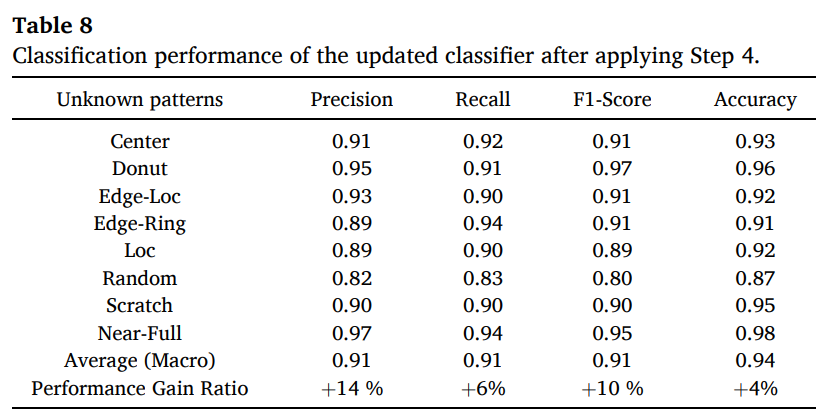
-
performance gain ratio를 함께 제시하여 업데이터 전/후에 대한 성능 확인 가능
- precision +14%, recall +6%, F1 +10%, accuracy +4% 개선
-
updated classifier 성능을 확인했을 때, macro 평균
- precision - 0.91
- recall - 0.91
- F1 - 0.91
- accuracy - 0.94
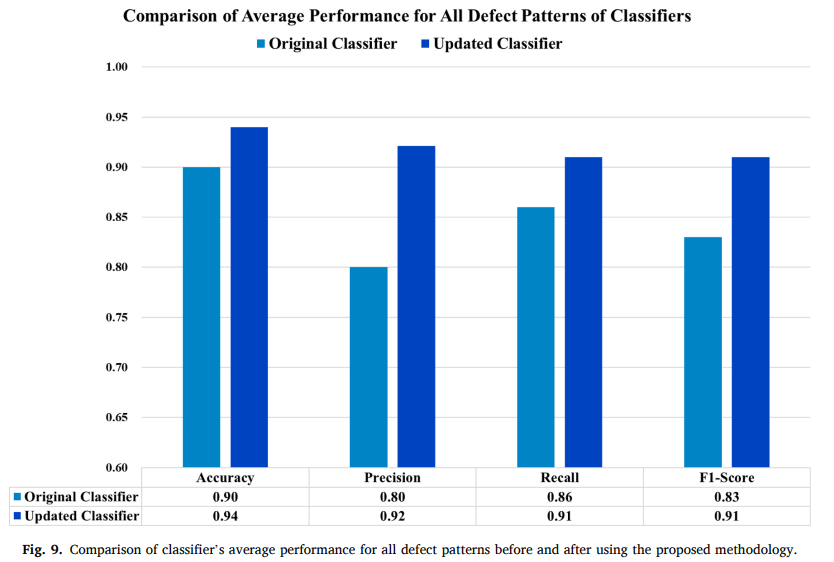
- 해당 막대그래프를 봤을 때, 업데이트 전후 성능 차이를 직관적으로 확인할 수 있음
4.6(추가) - Benchmark 및 관련 연구들과의 비교 실험
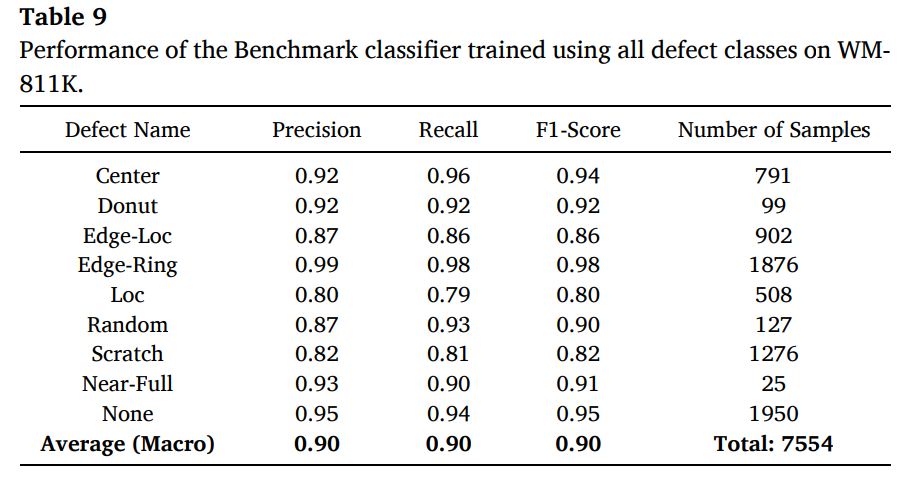
-
모든 결함 클래스를 포함해 학습한 benchmark classifier의 클래스별 정밀도/재현율/F1과 샘플 수 확인
-
데이터가 많다고 항상 좋은 것이 아니며(Near-Full과 Scratch 비교), 라벨 노이즈가 경계가 불명확한 패턴에서 성능을 악화시킬 수 있음을 확인
-
또한 WBM은 경계가 흐린 패턴이 많아 Edge-Loc vs Loc, Scratch vs Loc/Edge-Loc 같은 혼동이 발생할 수 있음
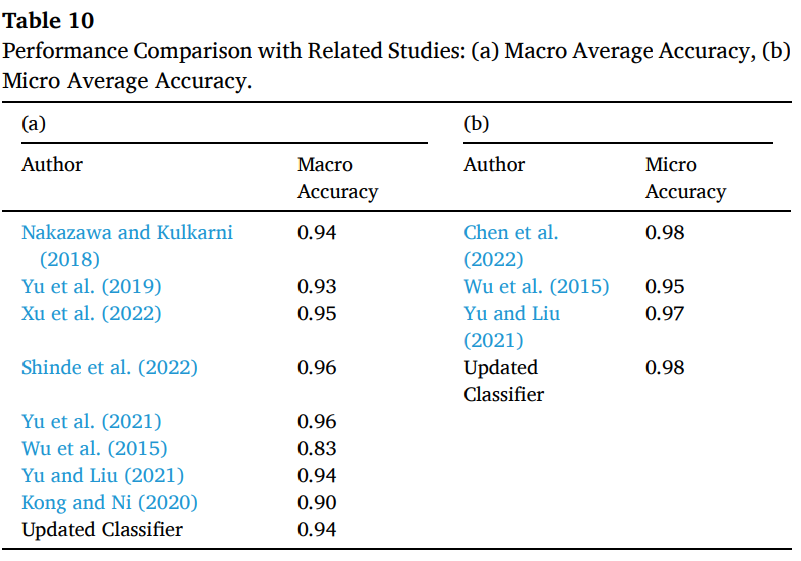
-
Table 10에서 related studies와 updated classifier를 macro, micro accuracy로 비교했고, micro accuracy는 None 비중이 매우 커서 높게 나올 수 있음을 함께 설명
-
updated classifier는 micro accuracy 0.98 수준으로 상위 성능군에 속하고, macro accuracy도 0.94로 경쟁력 있음을 확인함.
5. Case study 2: using real field data
-
실험 목적과 데이터 구성
- 실제 제조 현장 데이터로 제안 방법의 현장 적용성 평가
- 공정 관심 영역의 wafer bin 번호를 선택해 WBM 이미지로 전처리하였으며, 전체 WBM을 공정 엔지니어가 도메인 지식으로 라벨링 진행
-
WM-811K만으로 학습한 existing classifier를 real field test 데이터(unknown “Eye” 포함)에서 평가하고, proposed method 적용 후 proposed classifier와 비교
5.1 Real field industrial data

Fig. 10에서는 실제 데이터 결함 패턴 예시 시각화
- 결함 클래스는 Edge-Loc, Center, Edge-Ring, Eye, Near-full, Scratch로 구성
- Eye는 WM-811K에 없는 unknown single defect pattern이며, Center와 Edge-Ring이 결합된 mixed defect처럼 볼 수 있음

Fig. 11에서는 real field 데이터의 패턴 분포

Fig. 12에서 학습 데이터는 WM-811K의 9패턴(known)만 포함하고, test에만 Eye를 추가해 총 10패턴으로 평가하는 구성을 제시
5.2. Performance for real field industrial data
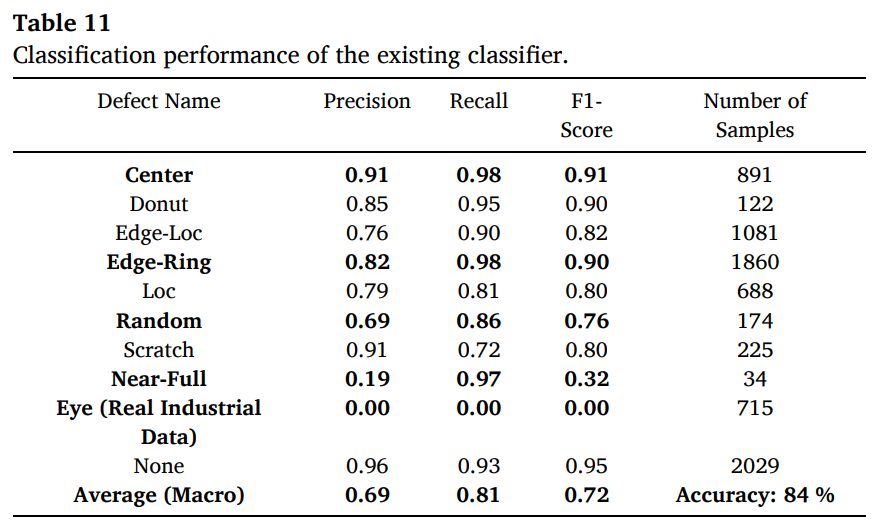
Table 11에서 existing classifier의 성능을 제시했고, Eye 클래스는 학습되지 않았으므로 precision/recall/F1이 모두 0
-
Eye와 유사한 Center, Edge-Ring 및 Near-full, Random 등에서도 오분류 영향으로 성능이 안 좋아지는 것을 확인할 수 있음
-
macro 평균
- precision 0.69
- recall 0.81
- F1 0.72
- accuracy 84%
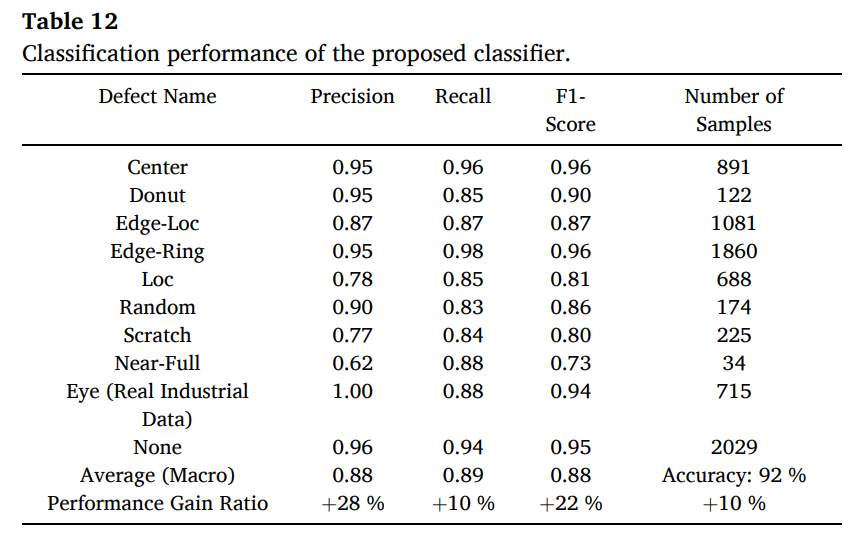
Table 12에서 proposed classifier 성능을 제시하여, Eye 클래스에 대한 성능을 확인함.
-
precision - 1.00
-
recall - 0.88
-
F1 - 0.94
-
전체 macro 평균은 precision 0.88, recall 0.89, F1 0.88, accuracy 92%
-
performance gain ratio는 precision +28%, recall +10%, F1 +22%, accuracy +10%로 제시
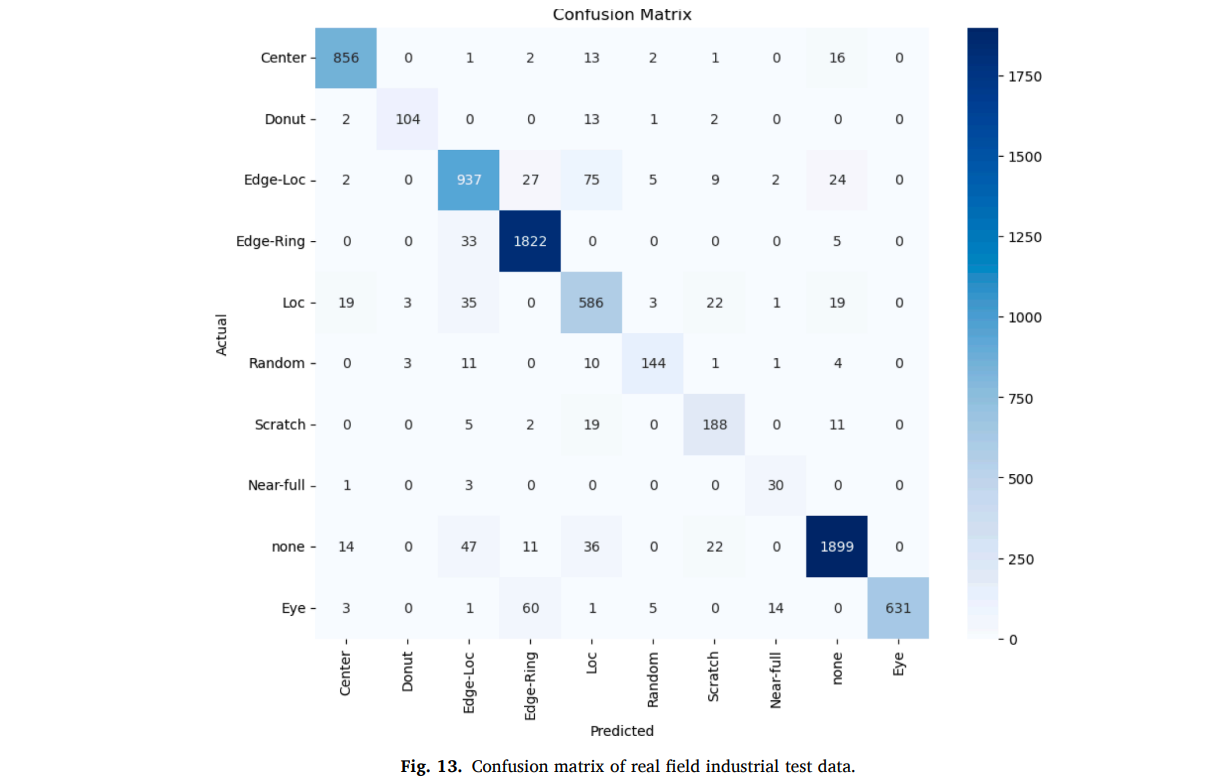
Fig. 13에서 confusion matrix를 통해 predict 분포를 확인할 수 있음
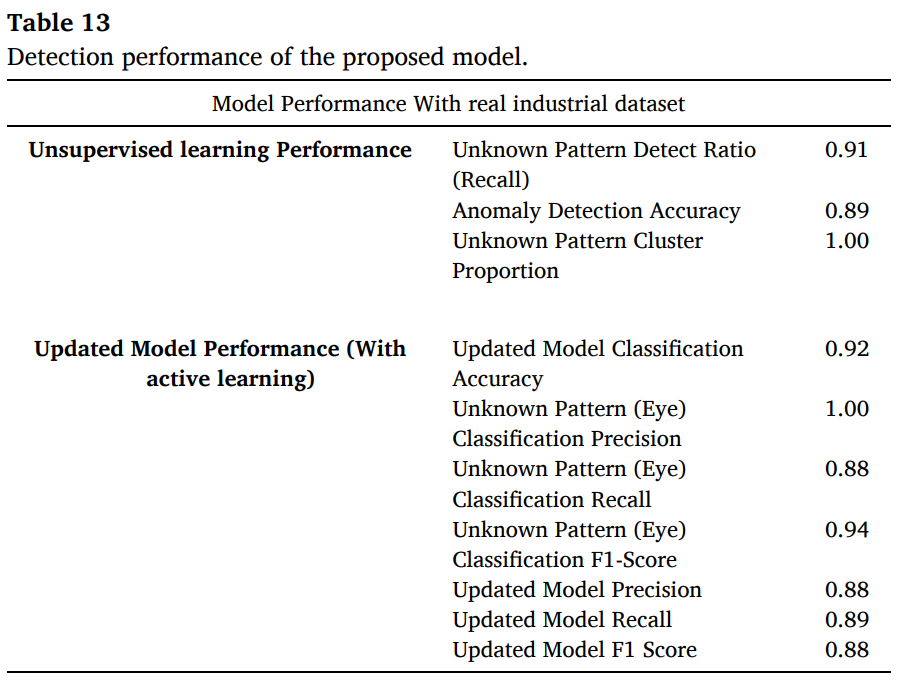
Table 13에서 unknown detect ratio(Recall) 0.91, anomaly detection accuracy 0.89, unknown cluster proportion 1.00 등을 포함한 종합 지표를 보이고 있음
6. Conclusions
-
기존 WBM 분류 연구가 unknown defect 패턴의 등장과 그로 인한 분류기 성능 저하를 충분히 고려하지 못했다고 문제를 강조
-
본 연구는 unknown 패턴을 효과적으로 탐지하면서 known 패턴 분류 성능을 유지했고, active learning으로 탐지기와 분류기를 지속 업데이트하는 전략을 제안
-
WM-811K에서 Step 4 미적용 시 모든 지표가 최소 4%에서 최대 14%까지 악화될 수 있음을 언급하며, Step 4 적용 후 성능이 유의미하게 개선됨을 강조
-
real field 데이터에서 Eye unknown 패턴을 포함할 때 proposed classifier가 existing classifier 대비 10%~28% 개선을 보임
-
프레임워크 적용이 실제 제조 환경에서 비용 절감과 품질 관리 강화로 이어질 수 있다고 주장
Future works
-
known 패턴만으로 unknown 탐지 효율을 높이기 위해 OSR과 zero-shot learning 등을 탐색
-
또한 known 패턴으로 학습된 딥네트워크 레이어를 활용해 uncertainty estimation과 clustering을 결합하고, data selection을 고도화해 active learning 효율을 높일 수 있을 것 같다.
