<1> 대중교통 데이터 시각화
1) 유임 승차 비율이 가장 높은 역 찾기
rate = 유임승차인원 / 무임승차인원
1. 데이터 읽어오기
2. 모든 데이터 바탕으로 각 역의 비율(rate) 계산
3. 비율이 가장 높은 역 찾기
4. 비율이 가장 높은 역과 그 비율 출력
1. 데이터 읽어오기
데이터 정제하기
- 필요없는 작업일시 데이터는 삭제
- 그외 ','로 구분되어 있던 숫자값들의 ,삭제
import csv
f = open('subway.csv')
data = csv.reader(f)
for row in data:
print(row)
import csv
f = open('subway.csv')
data = csv.reader(f)
next(data) #헤더 제거
for row in data:
for i in range(4,8): # 4번열~7번열 정수화
row[i] = int(row[i])
print(row)
2. 모든 데이터 바탕으로 각 역의 비율(rate) 계산
import csv
f = open('subway.csv')
data = csv.reader(f)
mx = 0 #rate의 최댓값 저장
rate = 0 #각 역의 비율 데이터 저장
next(data)
for row in data:
for i in range(4,8):
row[i] = int(row[i])
if row[6] != 0:
rate = row[4] / row[6]
if rate > mx:
mx = rate
print(row, round(rate,2))
print(mx)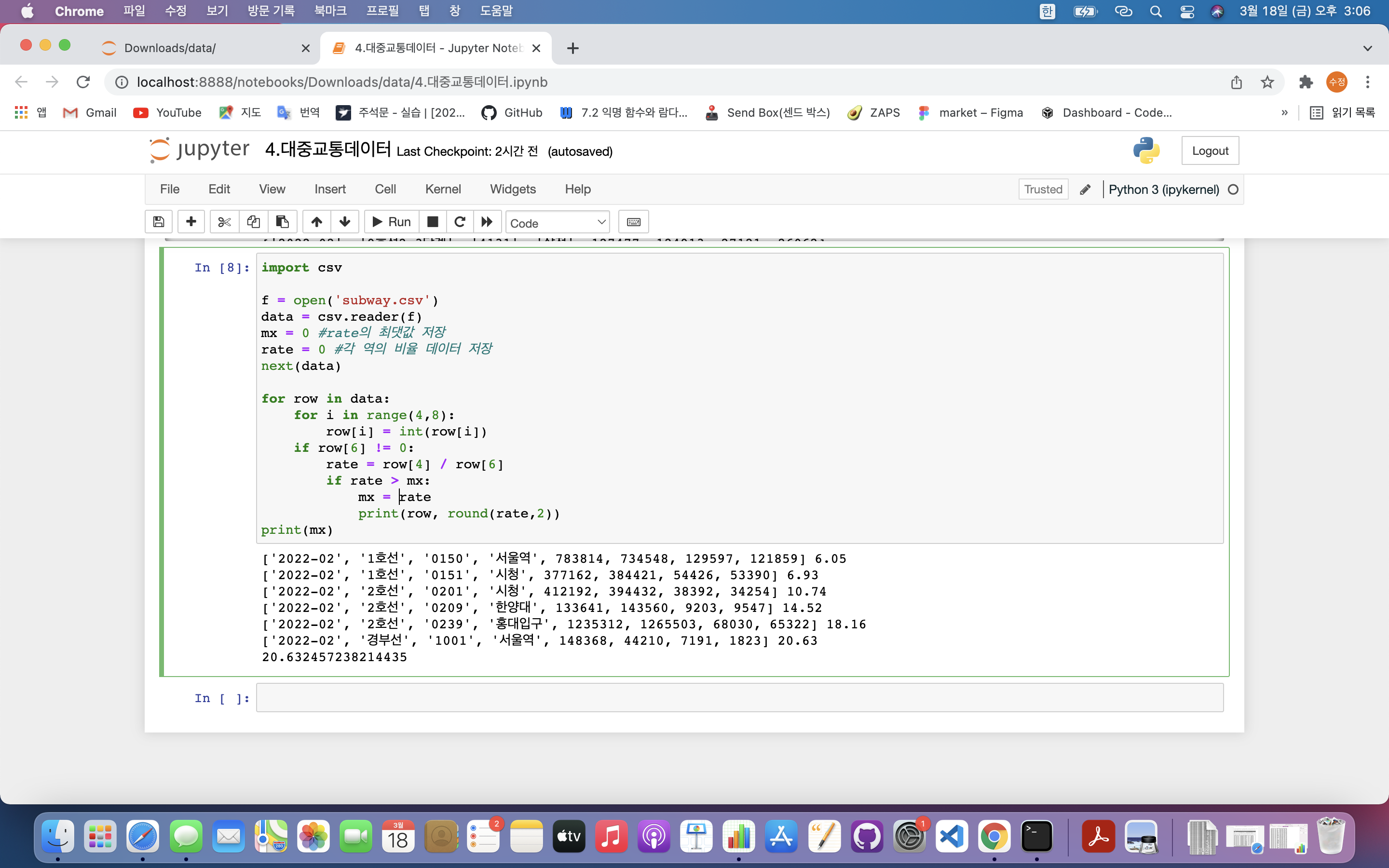
- row[4] : 유임승차 인원
- row[6] : 무임승차 인원(0 값 존재함)
- round(rate,2) : 소수점 둘째 자리까지 반올림 하라는 명령
- rate값이 최댓값으로 업데이트될 때마다 출력됨
rate = 유임승차인원 / 전체인원(무임승차 인원 + 유임승차 인원)
import csv
f = open('subway.csv')
data = csv.reader(f)
mx = 0 #rate의 최댓값 저장
rate = 0 #각 역의 비율 데이터 저장
next(data)
for row in data:
for i in range(4,8):
row[i] = int(row[i])
if row[6] != 0 and (row[4]+row[6]) > 100000:
rate = row[4] / (row[4]+row[6])
if rate > mx:
mx = rate
print(row, round(rate,2))
print(mx)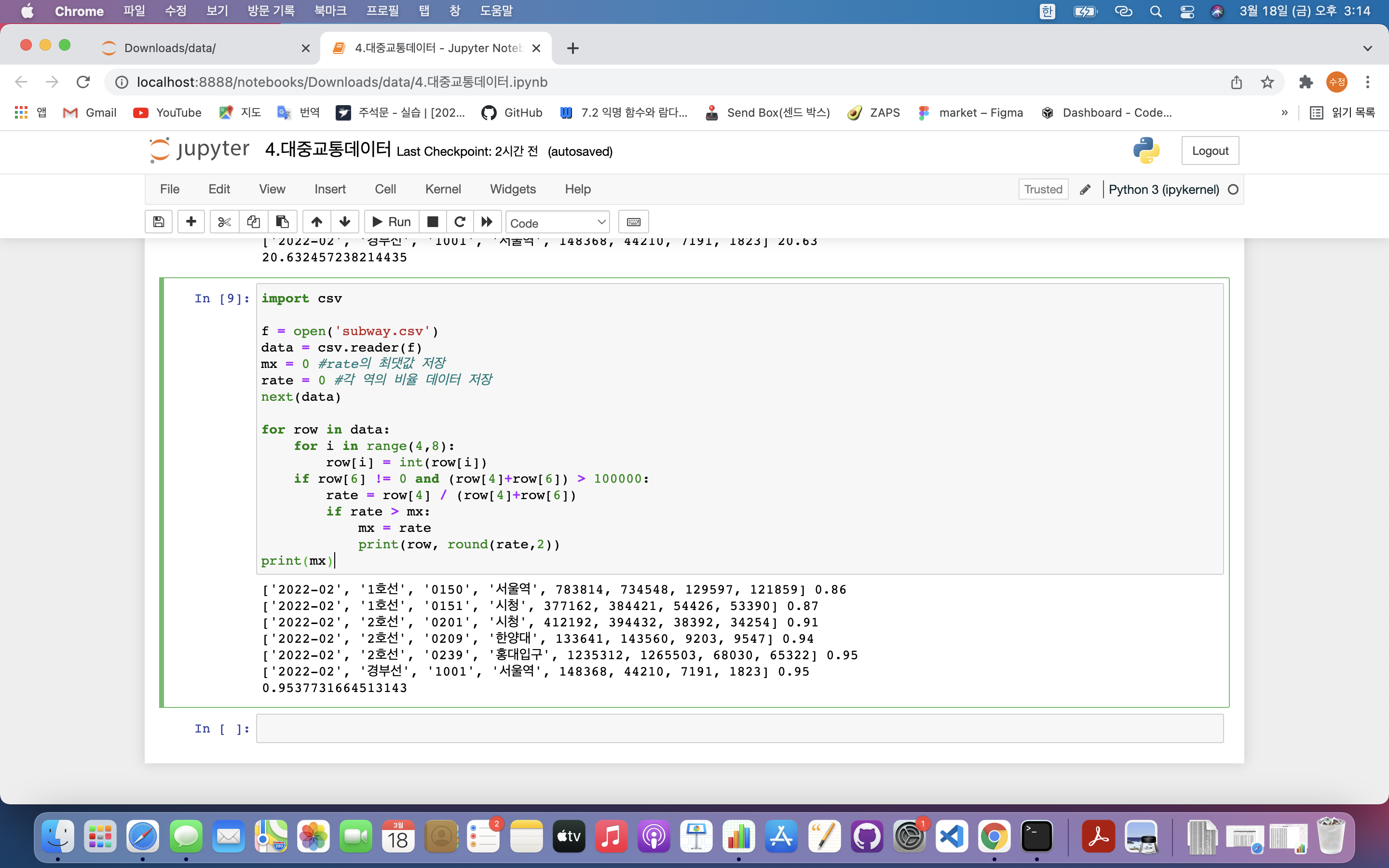
3. 비율이 가장 높은 역 찾기
import csv
f = open('subway.csv')
data = csv.reader(f)
mx = 0 #rate의 최댓값 저장
rate = 0 #각 역의 비율 데이터 저장
next(data)
for row in data:
for i in range(4,8):
row[i] = int(row[i])
if row[6] != 0 and (row[4]+row[6]) > 100000:
rate = row[4] / (row[4]+row[6])
if rate > mx:
mx = rate
if rate > 0.94:
print(row, round(rate,2))
print(mx)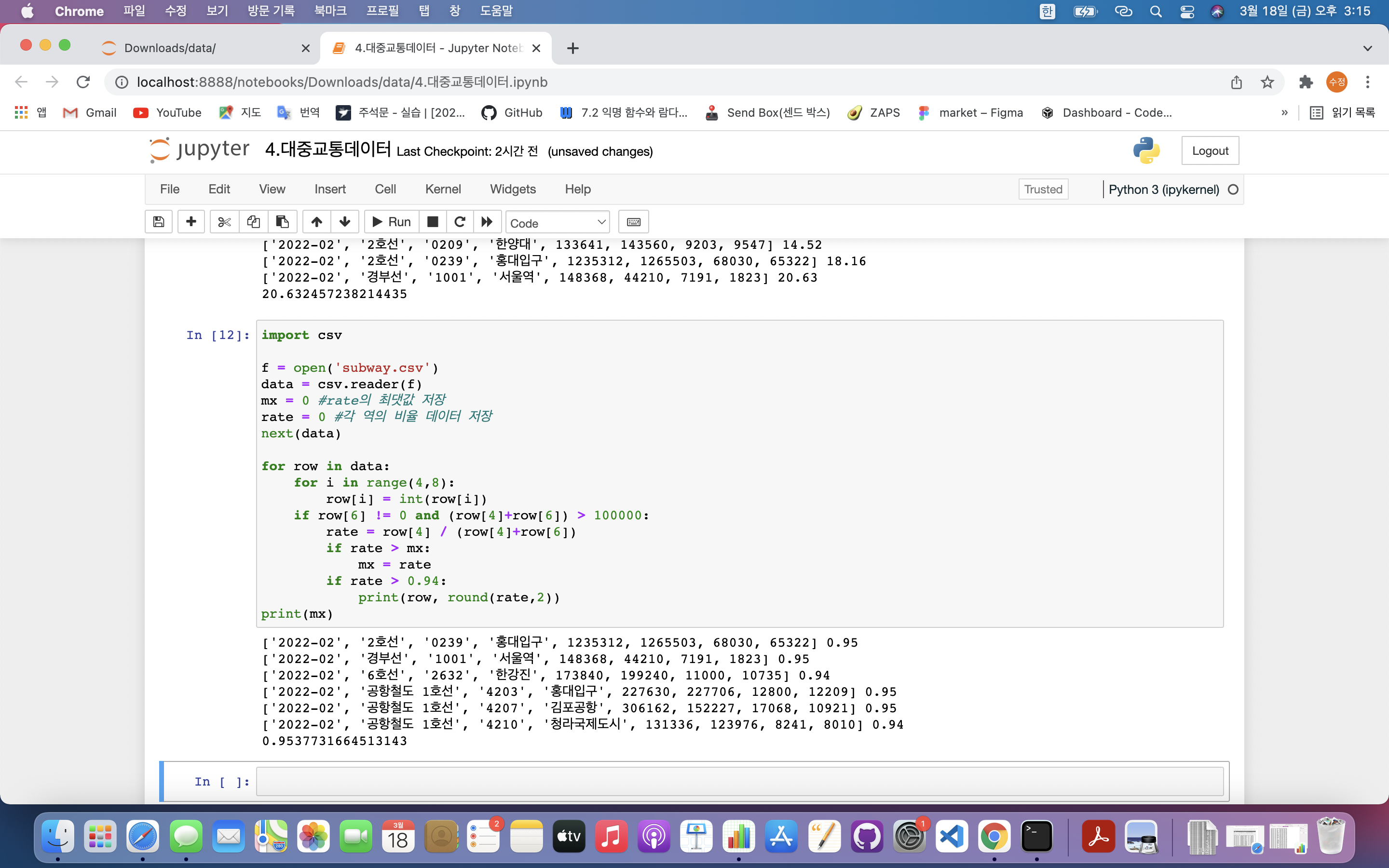
4. 비율이 가장 높은 역과 그 비율 출력
import csv
f = open('subway.csv')
data = csv.reader(f)
mx = 0 #rate의 최댓값 저장
rate = 0 #각 역의 비율 데이터 저장
mx_st = ''
next(data)
for row in data:
for i in range(4,8):
row[i] = int(row[i])
if row[6] != 0 and (row[4]+row[6]) > 100000:
rate = row[4] / (row[4]+row[6])
if rate > mx:
mx = rate
mx_st = row[3] + '({})'.format(row[1])
print(mx_st, round(mx*100, 2))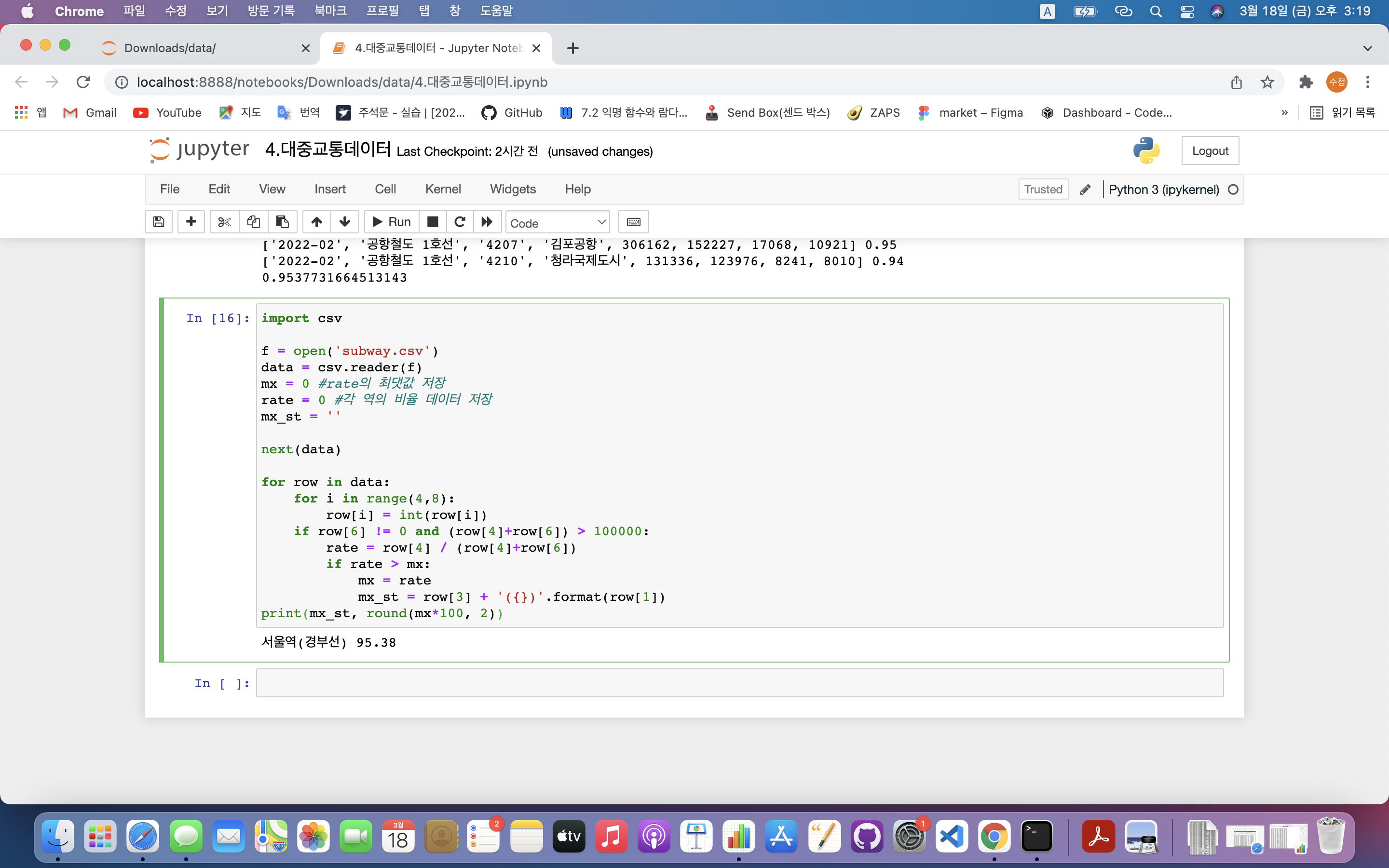
2) 유무임 승하차 인원이 가장 많은 역 찾기
rate = 유임승차인원 / 무임승차인원
1. 데이터 읽어오기
2. 모든 데이터 바탕으로 유무임 승하차 인원이 가장 많은 역 찾기
3. 각각의 인원이 가장 많은 역 출력
- 헤더 : [‘사용월’, ‘호선명’, ‘역ID’, ‘지하철역’, ‘유임 승차’, ‘유임하차’, ‘무임 승차’, ‘무임하차’]
1. 데이터 읽어오기
import csv
f = open('subway.csv')
data = csv.reader(f)
next(data)
mx = [0]*4
mx_st = ['']*4
print(mx)
print(mx_st)
2. 모든 데이터 바탕으로 유무임 승하차 인원이 가장 많은 역 찾은 후 각각의 인원이 가장 많은 역 출력
import csv
f = open('subway.csv')
data = csv.reader(f)
next(data)
mx = [0]*4
mx_st = ['']*4
label = ['유임승차', '유임하차', '무임승차', '무임하차']
for row in data:
for i in range(4,8):
row[i] = int(row[i])
if row[i] > mx[i-4]:
mx[i-4] = row[i]
mx_st[i-4] = row[3] + ' ' + row[1]
for i in range(4):
print(label[i] + " : "+ mx_st[i], mx[i] )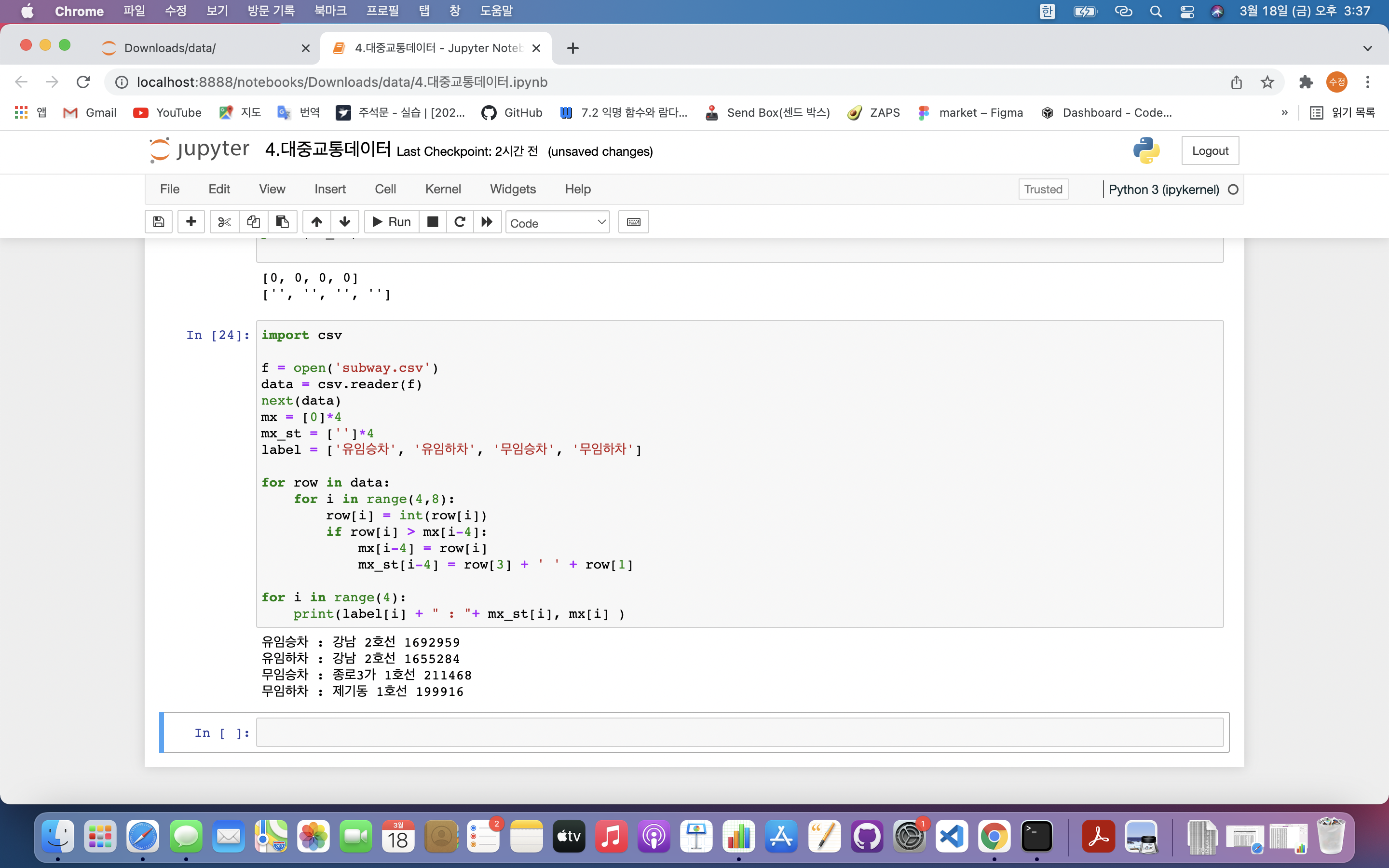
for row in data: 모든 역에 대해 반복for i in range(4,8):: 인덱스 4~7까지 반복if row[i] > mx[i-4]:: 해당 인덱스의 최댓값 구하기
3) 모든 역의 유무임 승하차 비율
import csv
import matplotlib.pyplot as plt
f = open('subway.csv')
data = csv.reader(f)
next(data)
label = ['유임승차', '유임하차', '무임승차', '무임하차']
c = ['#14CCC0', '#389993', '#FF1C6A', '#CC14AF']
plt.rc('font', family = 'AppleGothic')
for row in data:
for i in range(4,8):
row[i] = int(row[i])
plt.figure(dpi=100)
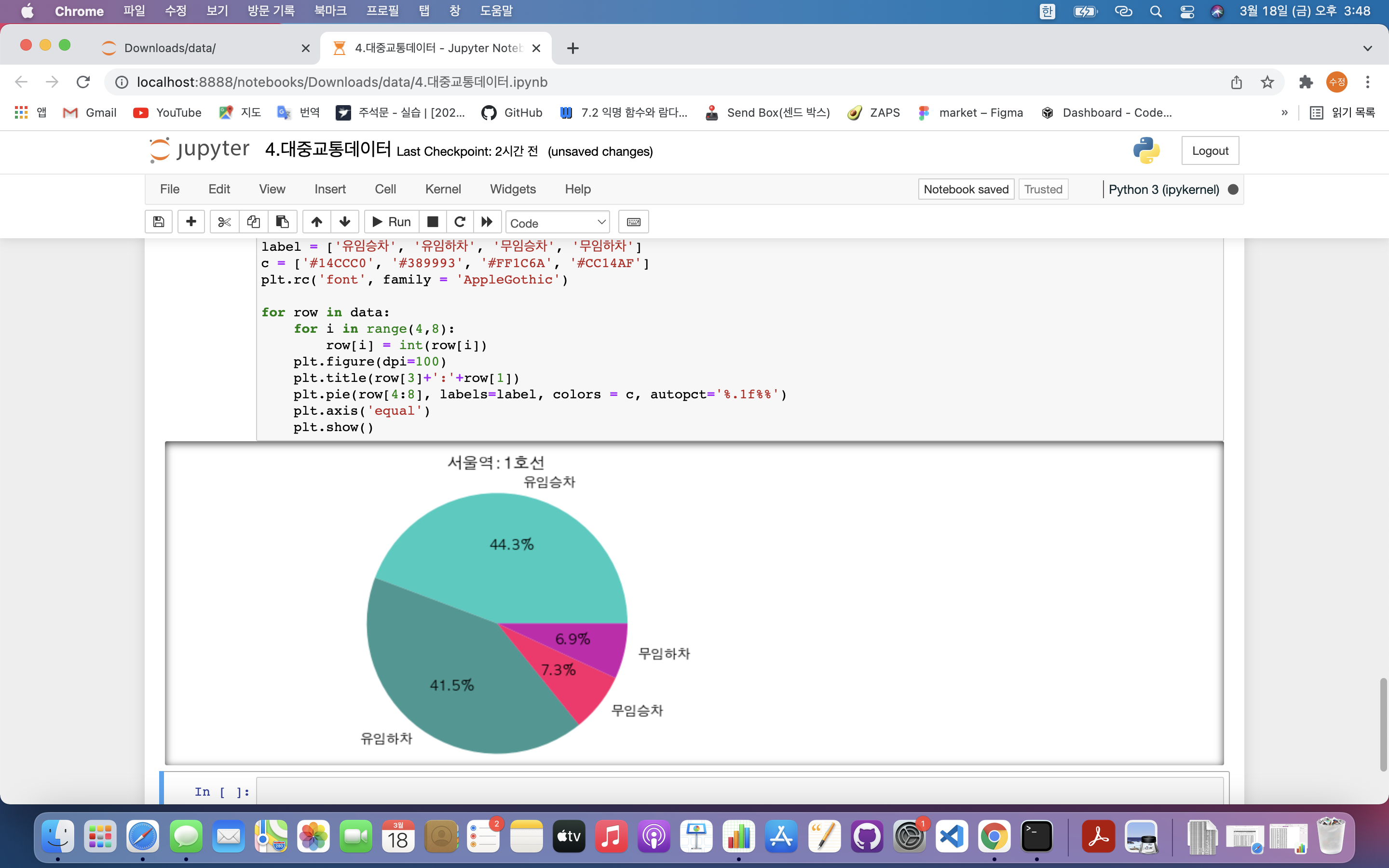
plt.title(row[3]+':'+row[1])
plt.pie(row[4:8], labels=label, colors = c, autopct='%.1f%%')
plt.axis('equal')
plt.show()
plt.savefig(파일이름과 형식) : 이미지 파일 저장됨
<2> 지하철 시간대별 시각화
1)데이터 불러오기
import csv
f = open("time.csv")
data = csv.reader(f)
for row in data:
print(row)
- 헤더가 2개의 행으로 이루어져 있으므로 데이터 정제
import csv
f = open("time.csv")
data = csv.reader(f)
next(data)
next(data)
for row in data:
row[4:] = map(int, row[4:])
print(row)
- 데이터를 정수형으로 형변환 : map 이용
- map(함수명, 데이터) : 데이터에 일괄적으로 함수 적용
- map(int, row[4:])
1번째 인자 : int() 함수
2번째 인자 : csv 파일에서 불러온 데이터가 저장된 row 리스트의 4번째 인덱스부터 끝까지
- map(int, row[4:])
2) 출근 시간대 혼잡한 역 찾기
10번 인덱스 : 오전 7시 승차한 사람들 수
import csv
f = open("time.csv")
data = csv.reader(f)
next(data)
next(data)
result = []
for row in data:
row[4:] = map(int, row[4:])
result.append(row[10])
print(len(result))
print(result)
import csv
f = open("time.csv")
data = csv.reader(f)
next(data)
next(data)
result = []
for row in data:
row[4:] = map(int, row[4:])
result.append(row[10])
import matplotlib.pyplot as plt
plt.bar(range(len(result)), result)
plt.show()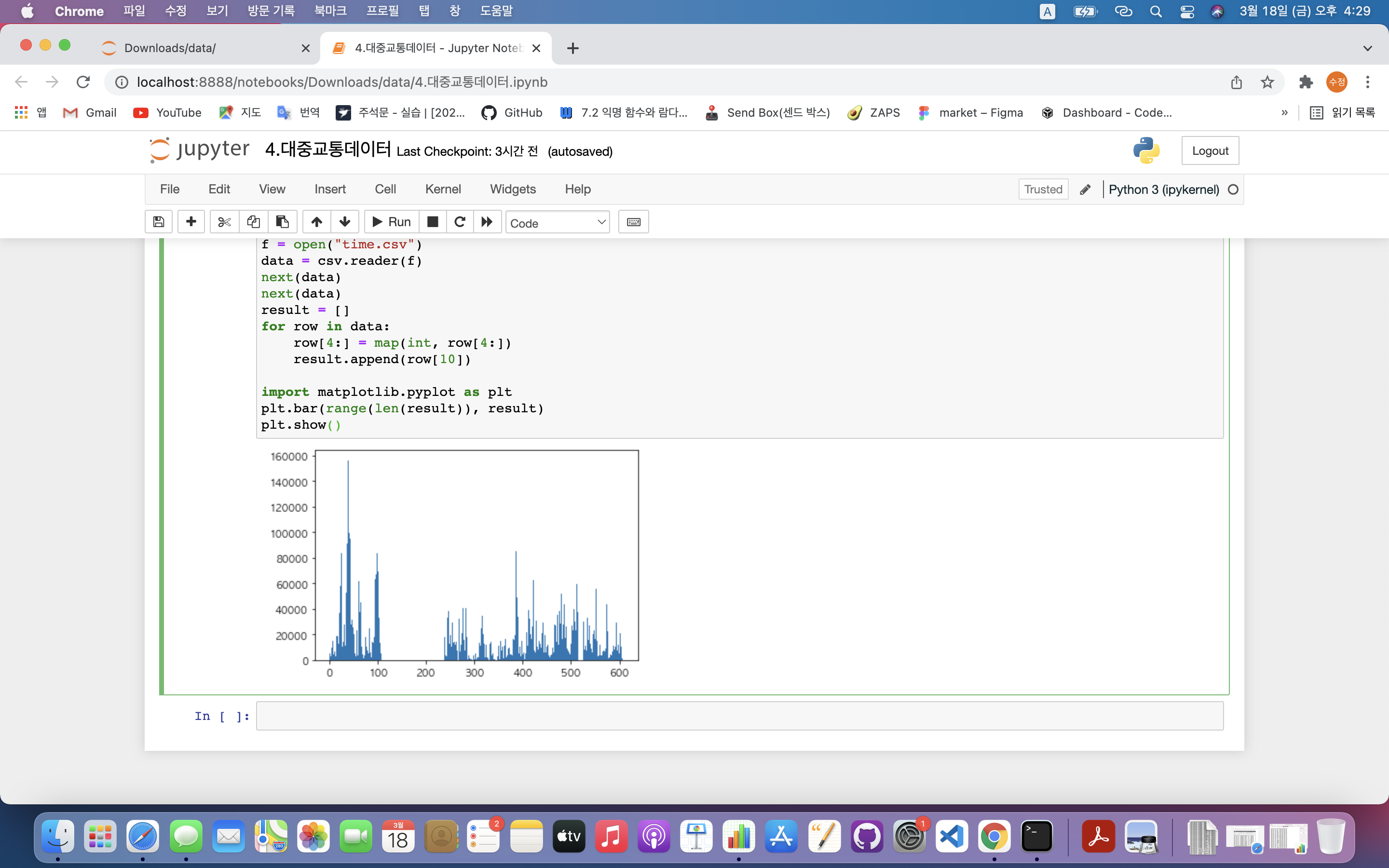
출근시간 때 가장 하차한 인원이 많은 역 찾기
import csv
import matplotlib.pyplot as plt
f = open("time.csv")
data = csv.reader(f)
next(data)
next(data)
mx = 0
mx_st = ''
for row in data:
row[4:] = map(int, row[4:])
a=row[11:16:2]
if sum(a) > mx:
mx = sum(a)
mx_st = row[3] + ':' + row[1]
print(mx, mx_st) - row[11:16:2] : 11, 13, 15번 인덱스(7, 8, 9시 하차인원에 해당)
3) n시 가장 많이 타는 역 찾기
- 승차 시간과 인덱스 사이에서 패턴 찾기 : t = 4 + (t-4)*2
| 승차시간(t) | 인덱스(i) |
|---|---|
| 4 | 4 |
| 5 | 6 |
| 6 | 8 |
| 7 | 10 |
| 23 | ? |
import csv
import matplotlib.pyplot as plt
f = open("time.csv")
data = csv.reader(f)
next(data)
next(data)
mx = 0
mx_st = ''
t = int(input('몇 시?:'))
for row in data:
row[4:] = map(int, row[4:])
a=row[4+(t-4)*2]
if a > mx:
mx = a
mx_st = row[3] + ':' + row[1]
print(mx, mx_st) 
4) 시간대별 승하차가 가장 많은 역 찾기
- 승차 시간과 인덱스 사이에서 패턴 찾기 : i = j * 2 + 4
| 변수(j) | 인덱스(i) |
|---|---|
| 0 | 4 |
| 1 | 6 |
| 2 | 8 |
| 22 | 48 |
| 23 | 50 |
import csv
import matplotlib.pyplot as plt
f = open("time.csv")
data = csv.reader(f)
next(data)
next(data)
mx = [0]*24
mx_st = ['']*24
for row in data:
row[4:] = map(int, row[4:])
for j in range(24):
a=row[j*2+4]
if a > mx[j]:
mx[j] = a
mx_st[j] = row[3]
print(mx, mx_st) 
승차시간
import csv
import matplotlib.pyplot as plt
f = open("time.csv")
data = csv.reader(f)
next(data)
next(data)
mx = [0]*24
mx_st = ['']*24
for row in data:
row[4:] = map(int, row[4:])
for j in range(24):
a=row[j*2+4]
if a > mx[j]:
mx[j] = a
mx_st[j] = row[3] + ':' + str((j+4)%24) + '시'
plt.rc('font', family='AppleGothic')
plt.bar(range(24), mx)
plt.xticks(range(24), mx_st, rotation=90)
plt.show()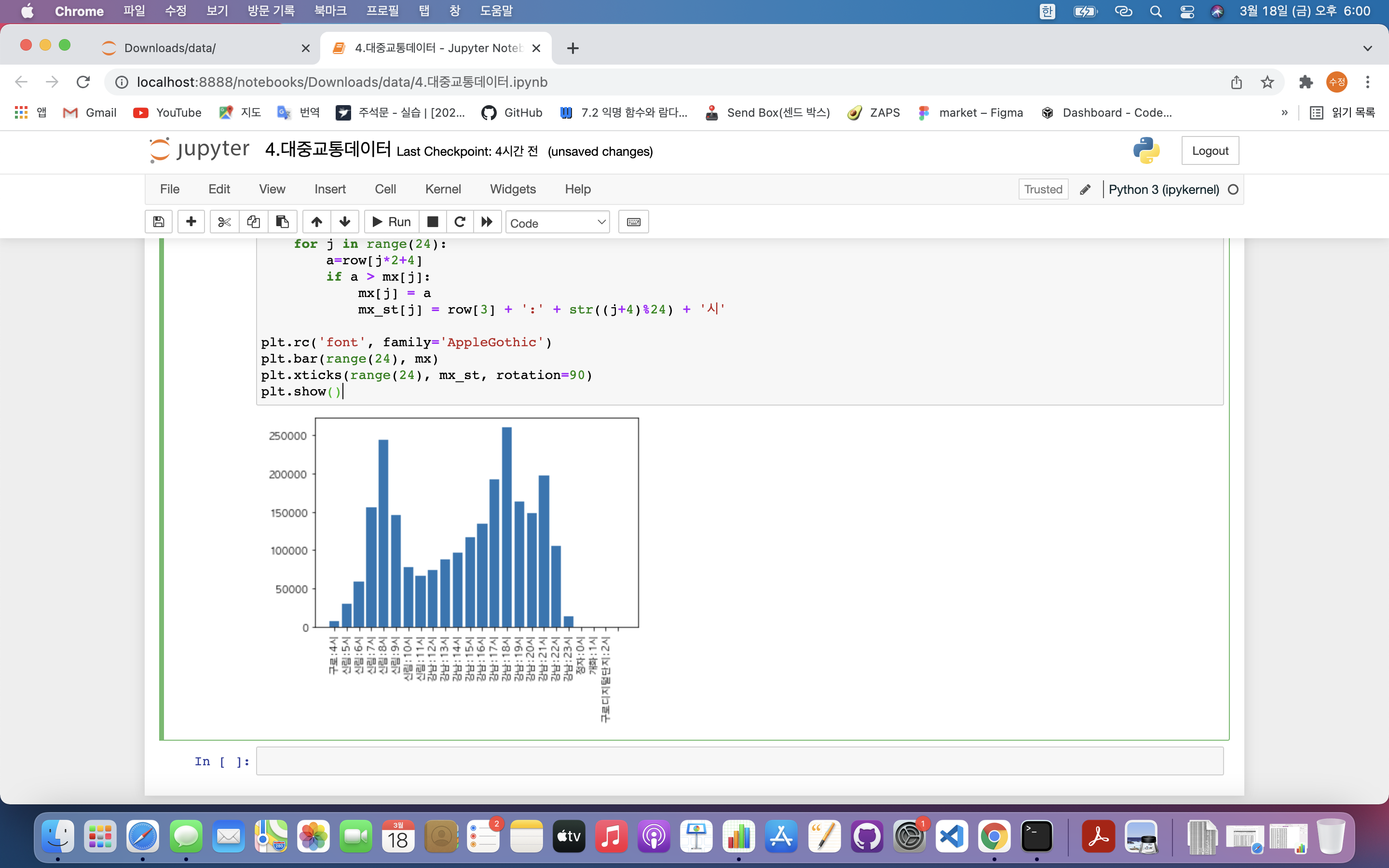
plt.xticks(range(24), mx_st, rotation=90): rotation을 통해 x 축 글자를 90도 뒤집음- str((j+4)%24) : 24시간을 표시하기 위해 24로 나눈 나머지로 표현
하차시간
import csv
import matplotlib.pyplot as plt
f = open("time.csv")
data = csv.reader(f)
next(data)
next(data)
mx = [0]*24
mx_st = ['']*24
for row in data:
row[4:] = map(int, row[4:])
for j in range(24):
a=row[j*2+5]
if a > mx[j]:
mx[j] = a
mx_st[j] = row[3] + ':' + str((j+4)%24) + '시'
plt.rc('font', family='AppleGothic')
plt.bar(range(24), mx, color='b')
plt.xticks(range(24), mx_st, rotation=90)
plt.show()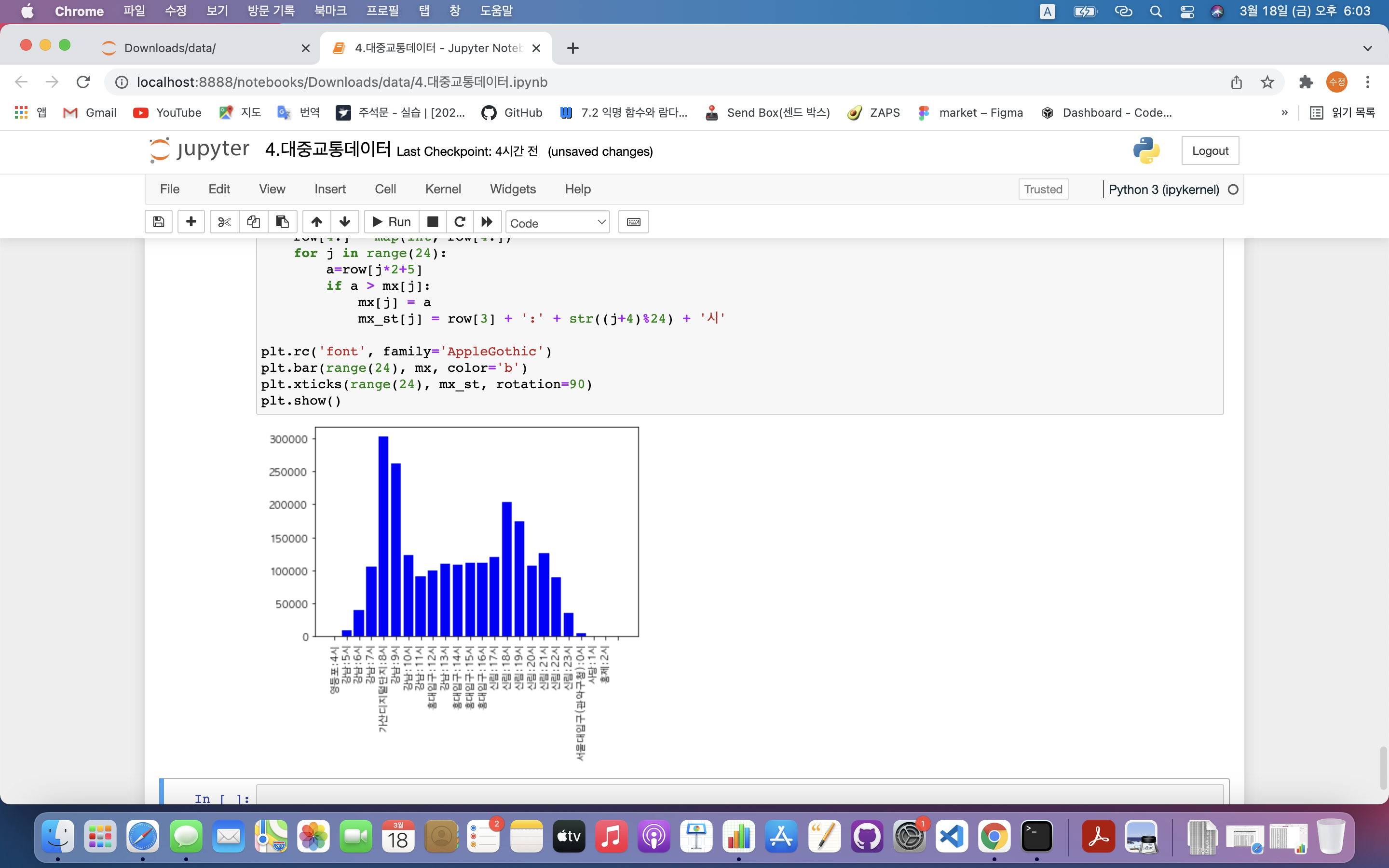
5) 모든 지하철역에서 시간대별 승하차 인원 모두 더하기
- 데이터 읽어오기
- 모든 역에 대해 시간대별 승차, 하차 인원 누적
- 시간대별 승차, 하차 인원 시각화
import csv
f = open("time.csv")
data = csv.reader(f)
next(data)
next(data)
s_in=[0] * 24
s_out=[0] * 24
for row in data:
row[4:] = map(int, row[4:])
for i in range(24):
s_in[i] += row[i*2+4]
s_out[i] += row[i*2+5]
plt.rc('font', family='AppleGothic')
plt.title('지하철 시간대별 승하차 인원 추이')
plt.plot(s_in, label='승차')
plt.plot(s_out, label='하차')
plt.legend()
plt.xticks(range(24), range(4,28))
plt.show()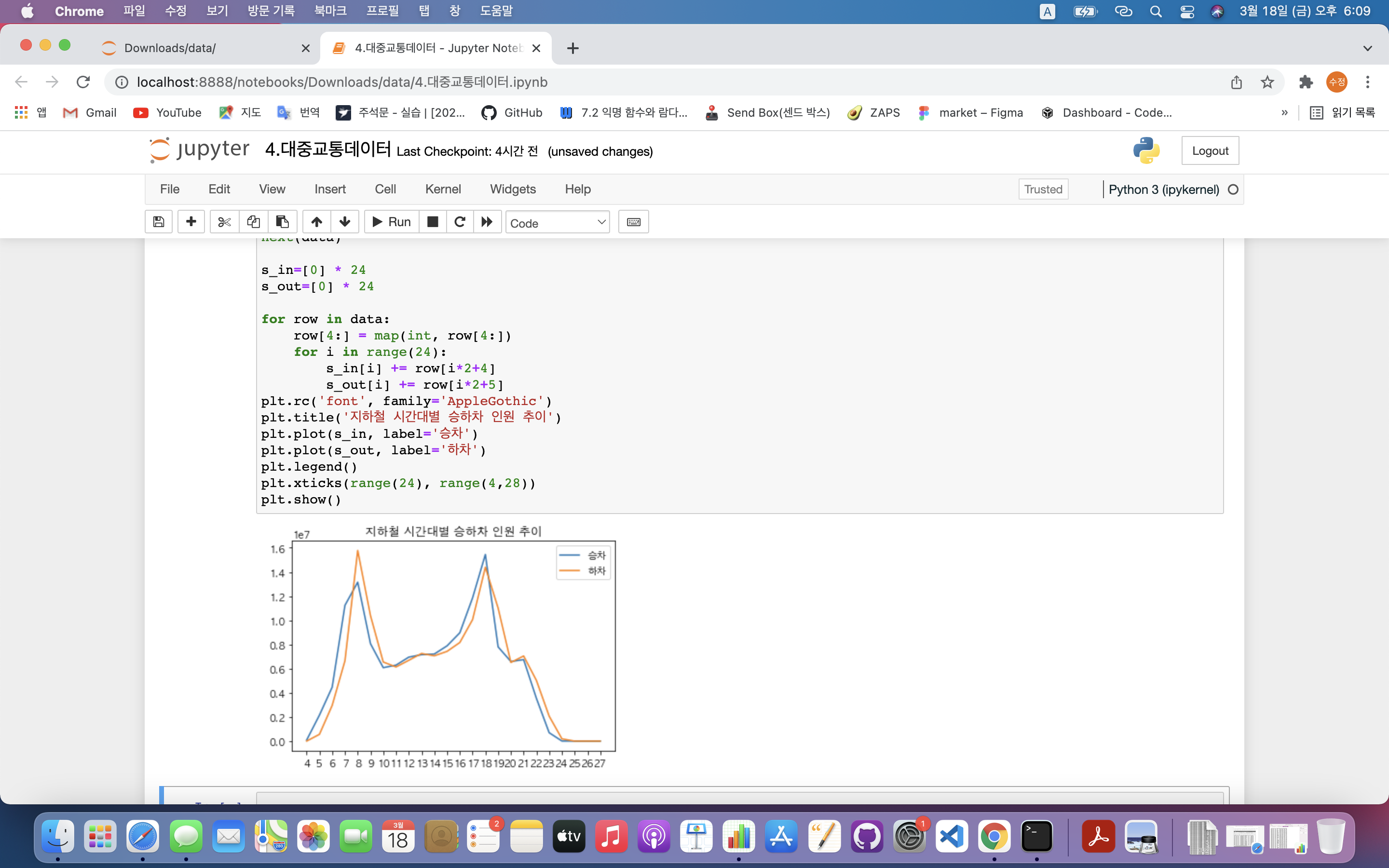

hello world!