데이터분석 with python
1.[데이터분석]1. 서울 기온분석하기
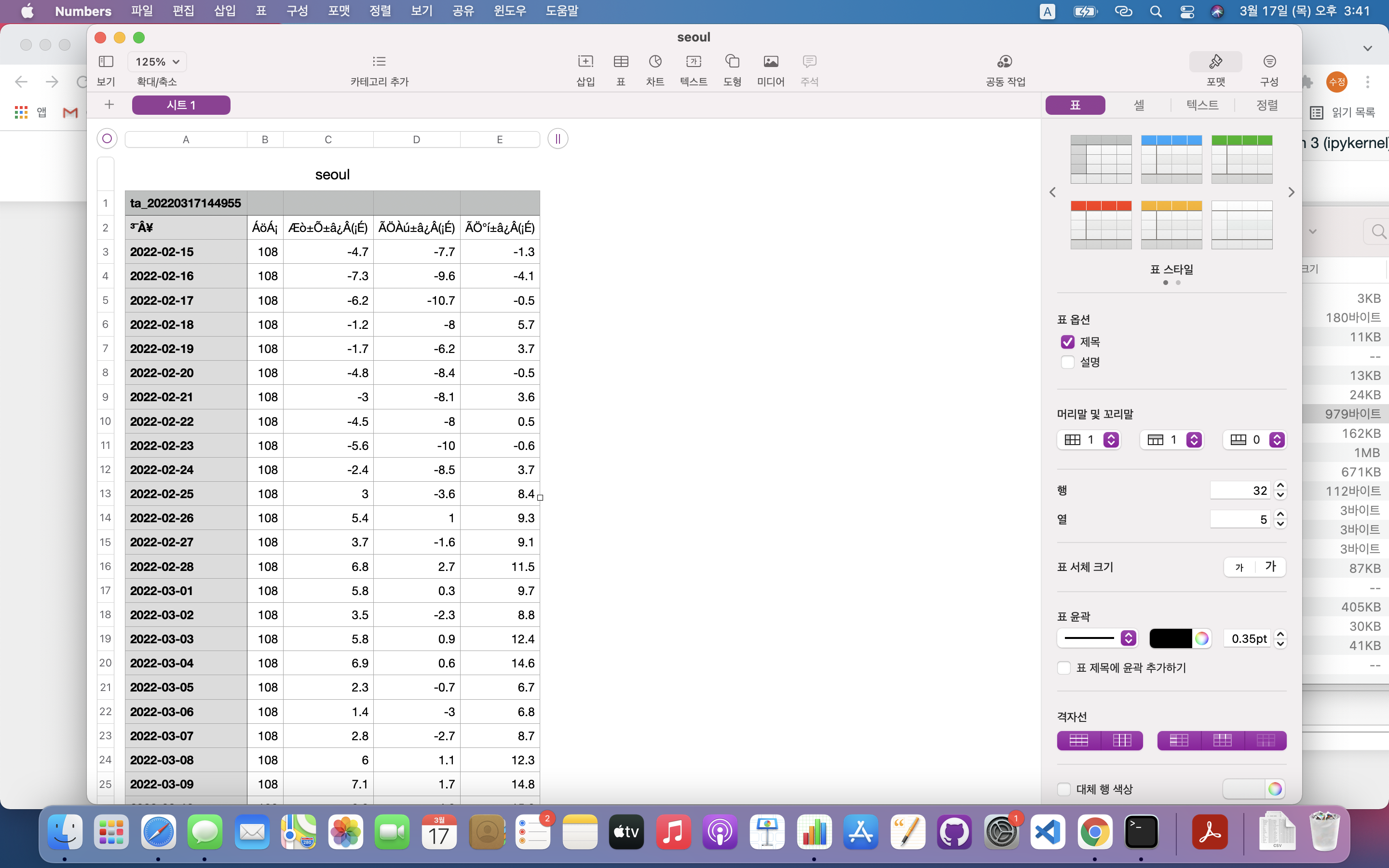
이렇게 공공데이터를 사용하면 한글깨지는 현상이 발생하였음.export할 때 utf-8로 설정해도 결국 한글이 계속 깨지는 문제가 발생하였는데...그냥 엑셀을 깔아서 하면 손쉽게 해결이 될테지만(방법은 구글링하면 잘 나옴) 귀찮기도 하고 이걸로 어떻게든 문제를 해결해보자
2.[데이터분석]2. 데이터 시각화
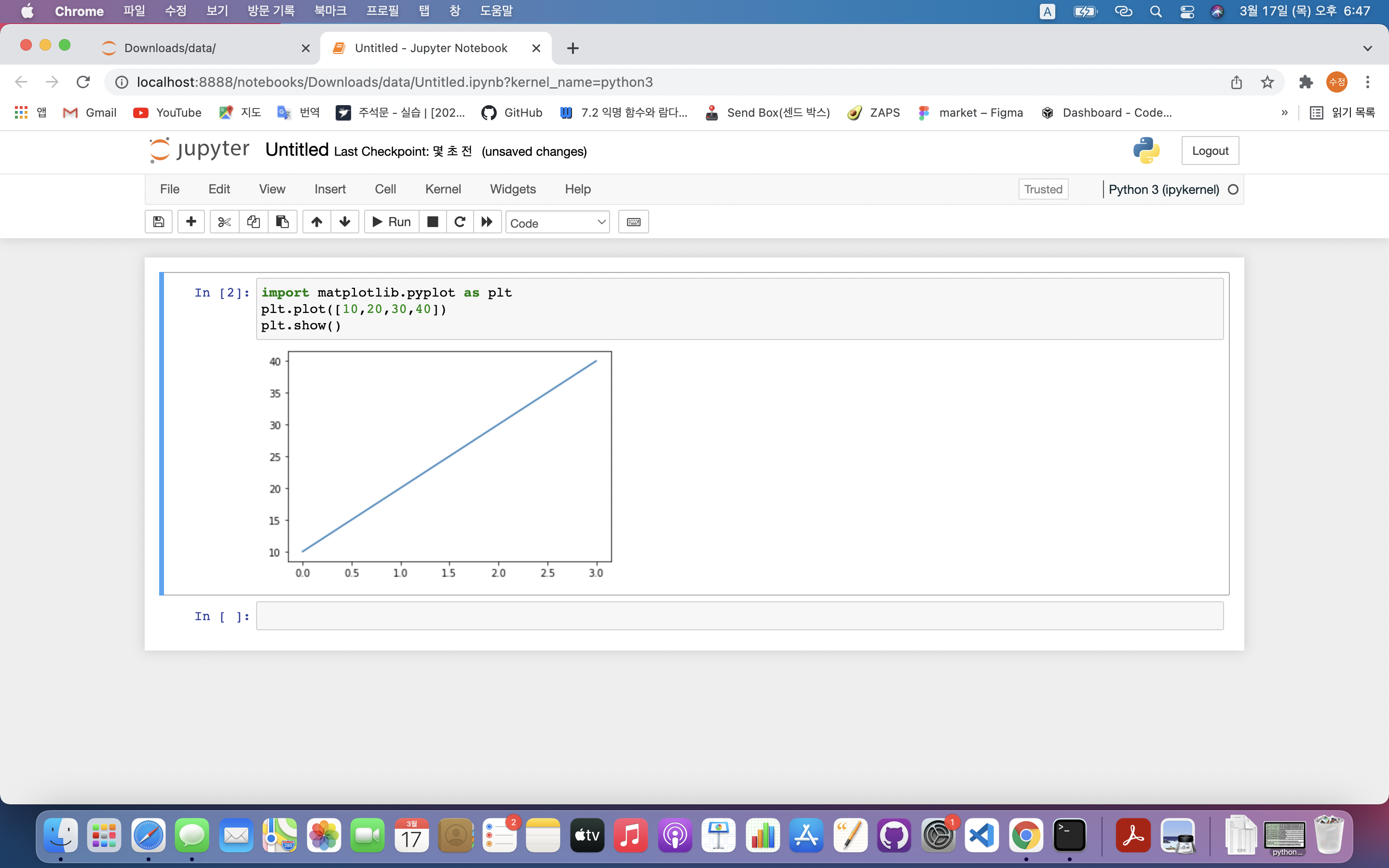
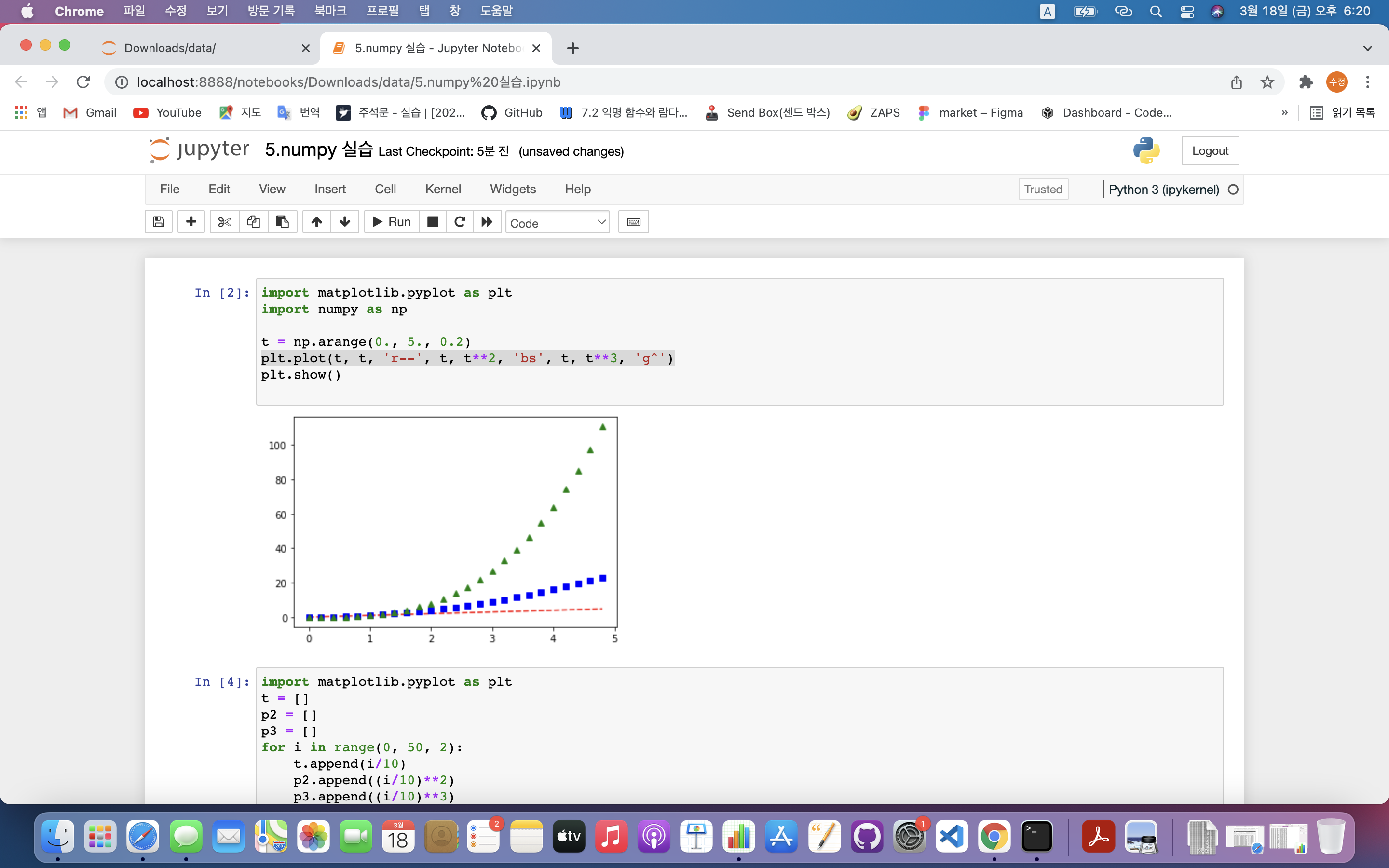
파이썬에서 2D 형태의 그래프, 이미지 등을 그릴 때 사용하는 것으로, 실제 과학 컴퓨팅 연구 분야나 인공지능 연구 분야에서도 많이 활용pyplot 모듈 사용import matplotlib.pyplot as plt 라이브러리 불러오기plt.plot(\[x축 데이터],
3.[데이터분석]3. 인구 공공데이터
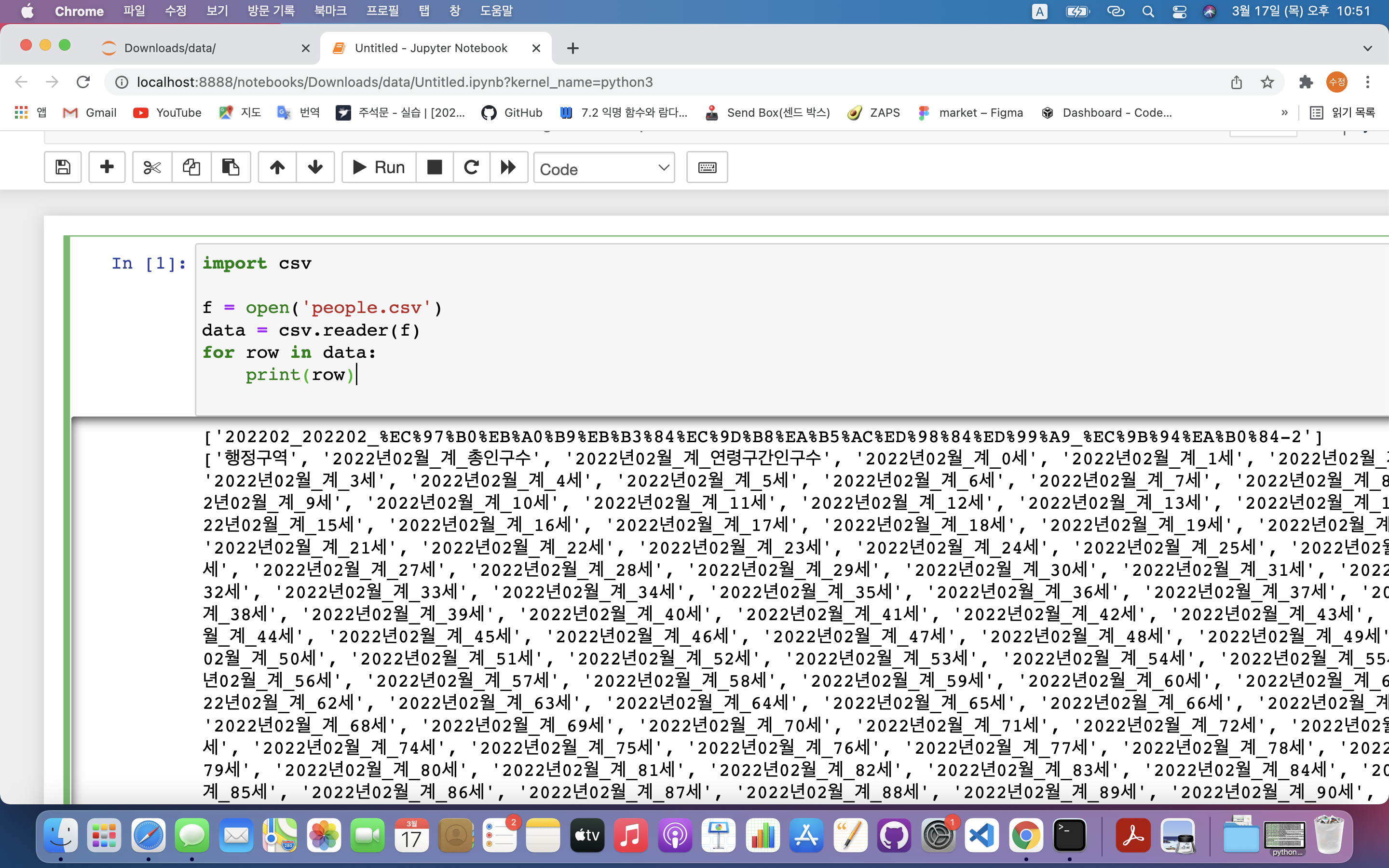
인구 데이터 파일 읽어오기전체데이터를 한줄씩 읽음우리 동네의 데이터인지 확인우리 동네의 0살 ~ 100살 이상까지의 인구수를 순서대로 저장저장된 인구수 시각화A in B 연산 이용 : A가 B에 있으면 Truerow0 : 지역명row1, row2 : 해당지역의 총 인
4.[데이터분석]4. 대중교통 데이터
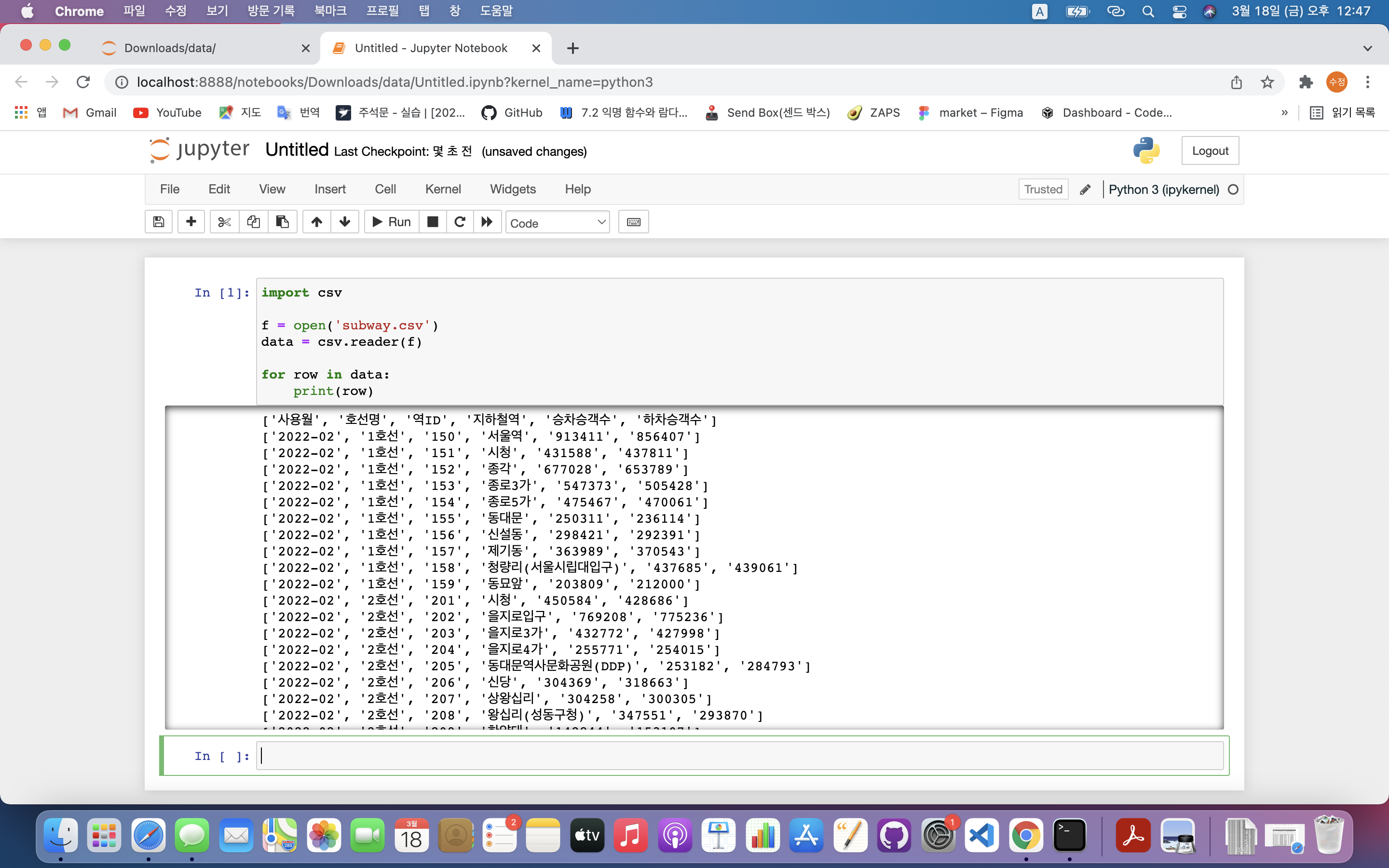
rate = 유임승차인원 / 무임승차인원1\. 데이터 읽어오기2\. 모든 데이터 바탕으로 각 역의 비율(rate) 계산3\. 비율이 가장 높은 역 찾기4\. 비율이 가장 높은 역과 그 비율 출력데이터 정제하기필요없는 작업일시 데이터는 삭제그외 ','로 구분되어 있던 숫
5.[데이터분석]5.numpy
넘파이 리스트 vs 파이썬 리스트numpy.ndarray : N-Dimensional, n차원⭐️ rand() : 실수로 나옴⭐️ choice(n, m) : 0 ~ n-1까지의 숫자를 m번 반복하여 선택⭐️ replace=False 로 설정하여 중복값을 뽑지 못하게 설
6.[데이터분석]6. 넘파이를 이용한 프로젝트
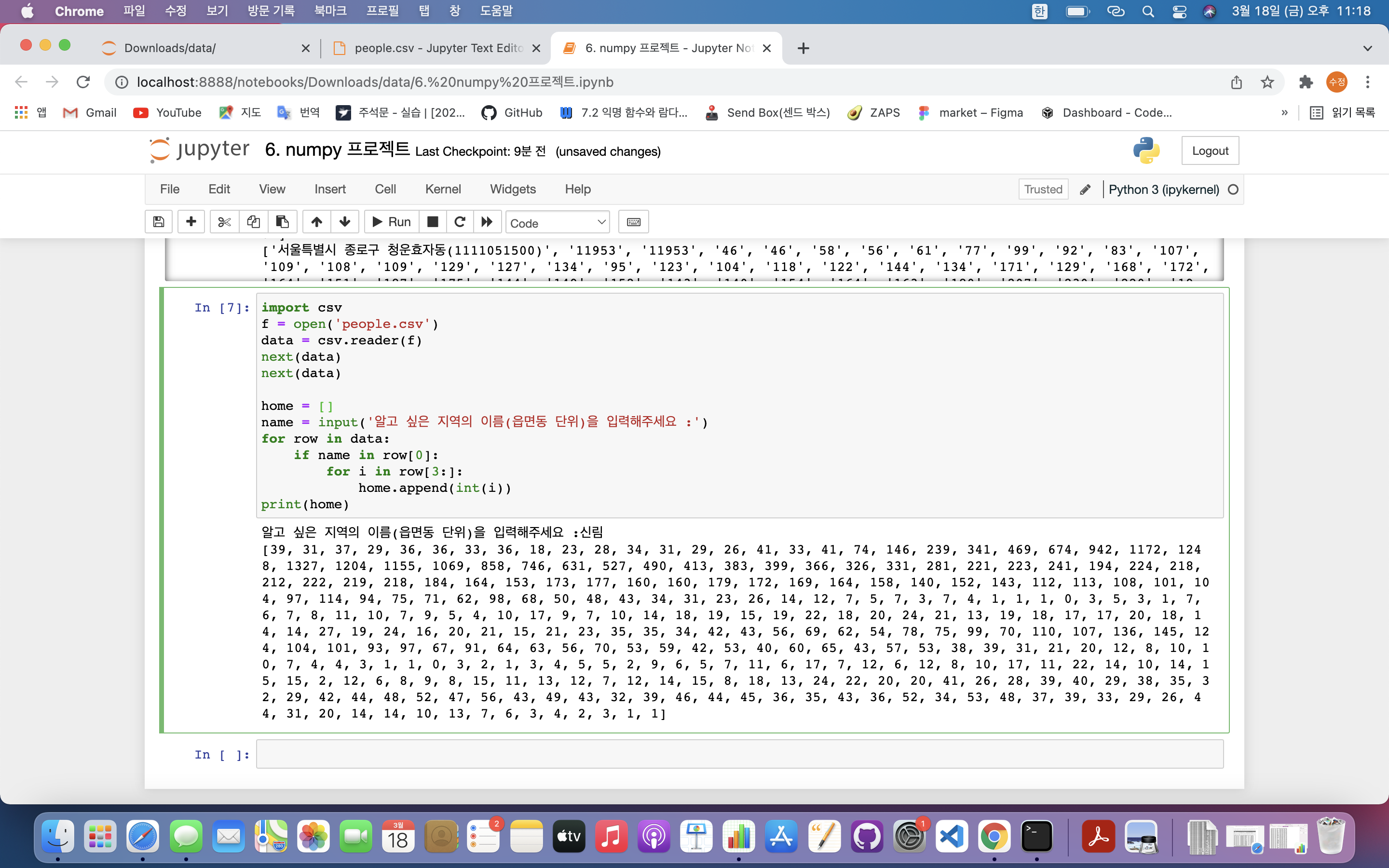
우리 동네와 연령별 인구구조가 비슷한 동네 찾기데이터 읽어오기알고 싶은 지역 이름 입력받기해당 지역 인구 구조 저장해당 지역의 인구구조와 비슷한 인구구조를 가진 지역 찾기해당 데이터 시각화불필요한 2개 행 제외하고 전 데이터 프린트넘파이 배열을 이용하여 이중 루프 해소
7.[데이터분석]7.Pandas
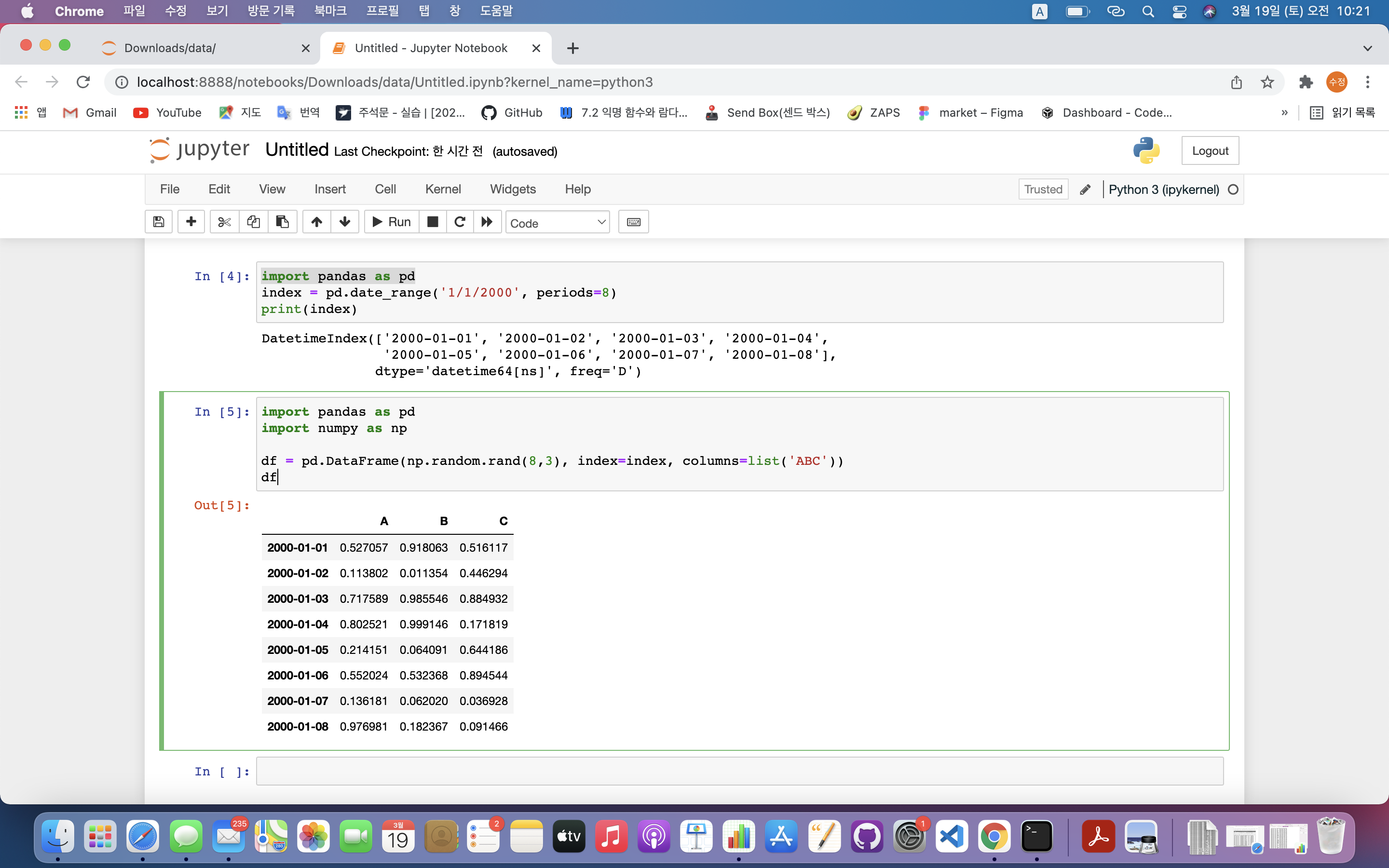
판다스의 가장 기본적인 구조날짜 형태로 된 8개 인덱스 생성8행 3열로 구성된 행렬 생성index는 선택하지 않아도 자동으로 선택됨특정 행/열 선택 시 시리즈(Series) 데이터구조 형태로 표현됨Series 형태로 표현마스크 적용 가능df\['E'] = np.sum(
8.[데이터 분석] 1. 코로나 데이터 분석 #1. 국내 코로나 확진자 수 추이
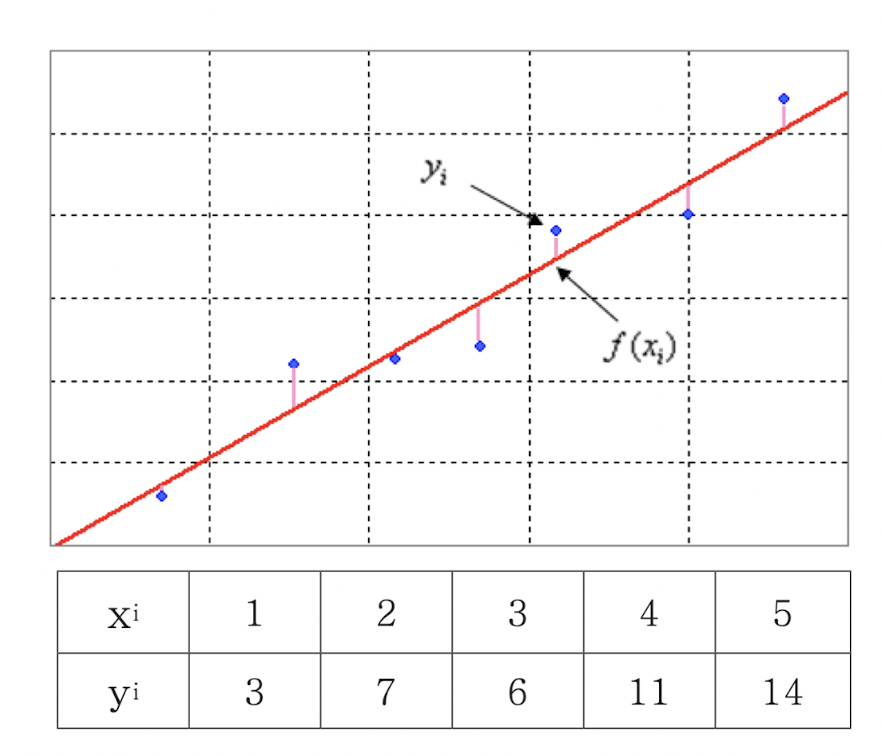
수많은 데이터가 일정한 규칙성이 있는지 알기 위해 이 데이터를 잘 분석해 가장 잘 맞는 규칙인 공식을 찾는 것 또는 가장 잘 표현하는 직선(best fitting)을 찾는 것이 점들을 지나는 가장 적합한 선형회귀(linear regression)선형 상관 관계를 나타내
9.[데이터 분석] 1. 코로나 데이터 분석 #2. 전세계 코로나 확진자 수 추이
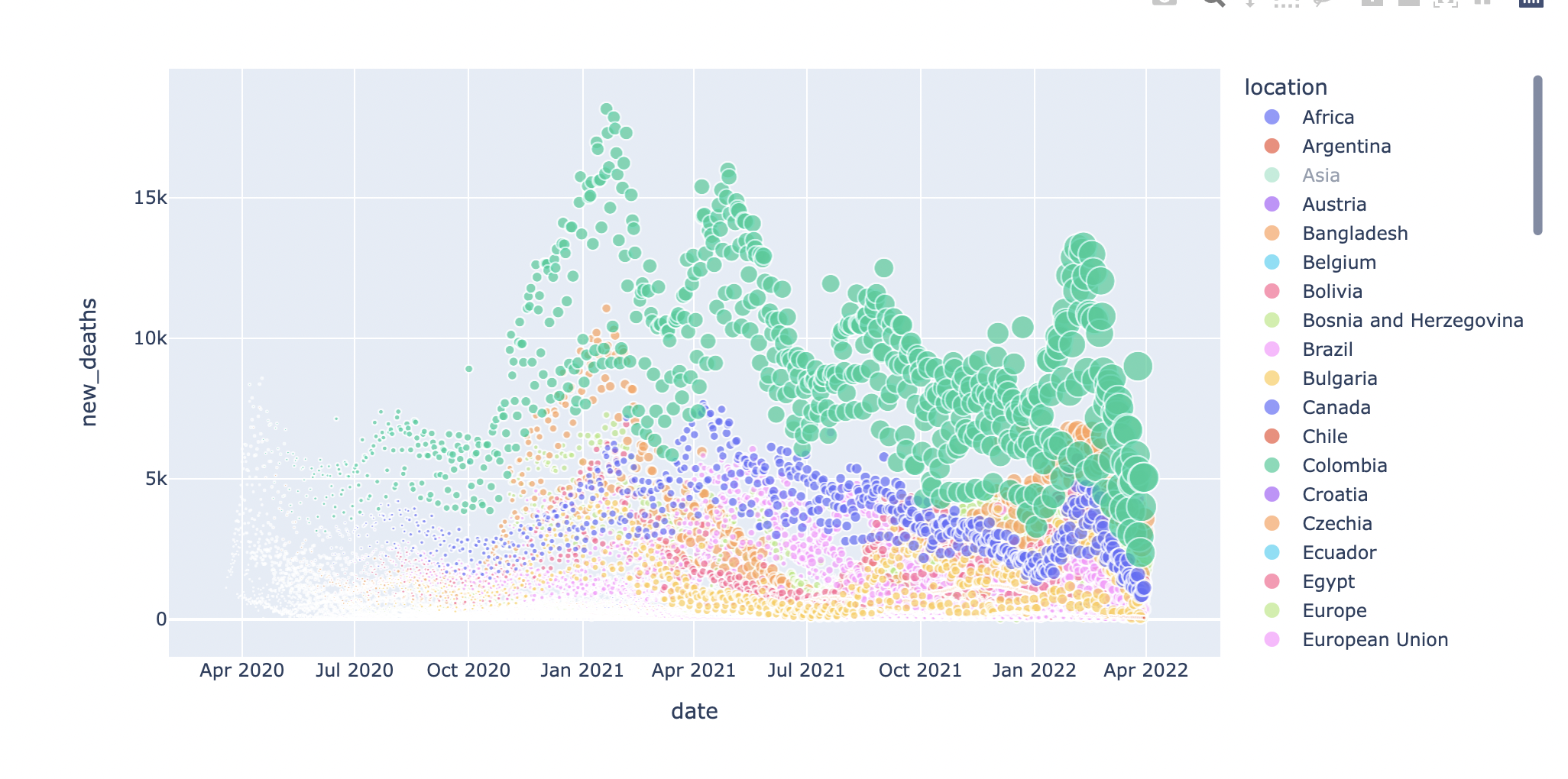
import plotly.express as px : 능동 대화형 그래프 모듈px.scatter() : 점 표시size : 데이터프레임 해당 열의 값 크기에 따라 크기 변화color : 데이터 프레임 해당 열의 값의 유형별로 색을 다르게 표시fig = px.pie(df
10.[데이터 분석] 2. 주식 데이터 분석 #1. 삼성전자 주식 예측

주식 : SMA5 이평선과 SMA30 등 이동평균선을 기준으로 크로스가 되었을 때 풀매수, 풀매도하면 됨